Open5
DB設計
スタプロのDB設計を再考する
論理モデル
ER図
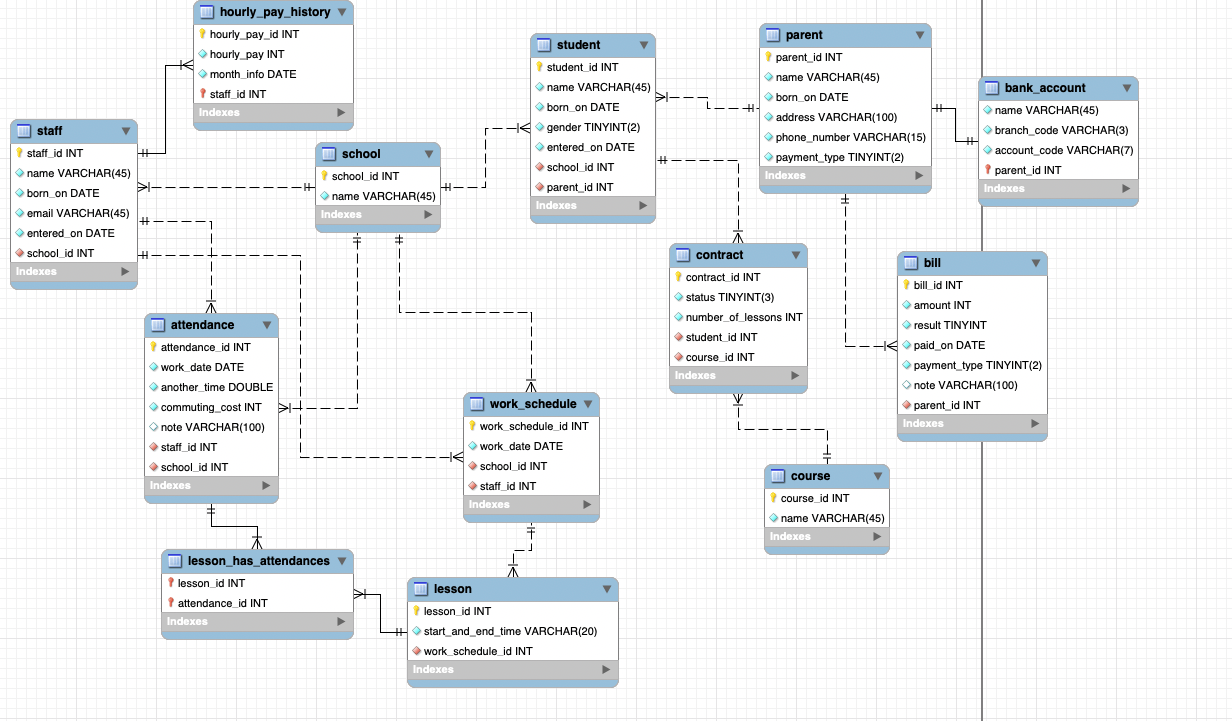
論理モデル
- エンティティ(実体)を整理する
- システムでどんなデータを扱いたいかを考える
- 弱実体、強実体を区別しておく
正規化
-
RDBにおけるテーブルとは「同じ種類のものの集合」を指す → 複数形/複数名詞でかける
-
業務上、必要になるのは第三正規形まで
-
第一正規形 セルの単一性(スカラ値)
-
第二正規形 主キーに対する関数従属(Aが決まればBが一意に定まる)を切り出す
-
第三正規形 主キー以外の関数従属(Aが決まればBが一意に定まる)を切り出す
→縦横のデータの繰り返し(冗長性)を無くす
→ 異なるレベルのエンティティを、テーブルレベルで分離できる(階層の差を反映出来る)
ER図
- ビジネスの文脈で考えた時に、追加・変更・削除が発生する可能性があるカラム→テーブル切り出しを検討
- 基本的に不変のデータ→カラムでOK
ex) ECサイト
商品カテゴリ:日用品、雑貨、家具、食品
決済方法:クレジット、電子マネー、銀行振込、着払い
- 過去のある時点でのデータ参照がしたいという要求がある場合→履歴テーブルを切り出す
アンチパターン
- 正規化ルールを知っていれば防げるものが8割
- 故に設計段階では発生しにくい。ハイプレッシャー下(急な仕様変更で納期まで時間がないとか)で発生する
↓残り2割
- ナイーブツリー(素朴な木)
深さが異なるデータモデル(例:コメントに対するリプライ)を単純な木構造で表すこと
再帰クエリが使えない環境ではアンチパターンとなり、経路列挙、入れ子集合、閉包テーブルに
置き換えるべき。
ただし、再帰クエリは現在の主要RDBMSでは対応済み
(PostgreSQL, Oracle, SQL Server, MySQL(8.0~), SQLite) - リクワイドID(とりあえずID)
全てのテーブルにプライマリキーをつけること- フレームワークの弊害
- 識別子の役割が別に存在する場合は除去(弱実体に多い)
- 考えなしに「id」と命名するのはやめよう
- クエリのテーブル結合(USING)が使いにくい
- フィア・オブ・ジ・アンノウン
NULLは、直感的に期待する振る舞いと異なることがしばしば。
NULLを恐れて、一般値をNULLに相当するものとして定義するのはNG
NULL検索は IS NULL 熟語を使う