「xUnit Patterns」を読む
- 「xUnit Test Patterns」と呼ばれる本の要約が書かれている
- テストに関する基礎的な考え方を得られそう
- 会社の先輩がおすすめしていたので読んでみる
※引用する文はDeepLを使用して翻訳しております
この章では、この本全体の大部分の資料について、簡略に紹介します。この章は、特定のパターンや匂いに飛び込む前に、資料をざっと見て回るのに使うことができます。また、より詳しい説明の章を読む前のウォームアップとしてもお使いいただけます。
まずはここから読むとよさそう。
Test Smells
問題の兆候を示すもの。エンジニアがコードを読んだり、テストを実行して失敗したときに感じる「違和感」のようなものを指す。
この記事だとそれは「Code Smell」と「Behavior Smell」に分類される。
前者はそのままの意味で、テストコードを読んでいるときに気づく臭いのこと。意図が伝わらなかったり、コードが読みにくかったりといったいわゆる一般的なコーディングレベルのアンチパターン。
後者はテストが失敗することによって感じる臭い。なので無視することができず、感じたときには対処しなければならない。
両者が1個以上あることによってもう一つの臭い「Project Smell」が発生することがある。これはプロジェクト全体において何かが根本的に間違っているかもしれないという類の臭い。
Behavior Smellとして主に上がってくるのはFragile Testで、その根本的な原因は4つある。
- Test内で利用しているAPIのインタフェースが変更されること
- Testで利用しているAPIの内部のコードが変更されること
- Testで利用しているデータ(DBなど)が変更されること
- Test周辺の環境(実行環境やフロントエンド文脈だとデバイスサイズとか)が変更されること
この辺りの分類は興味深かった。自身のプロジェクトでもFragileなTestは多く存在するが、対象となる原因を潰していけばFragile Testを潰せる。問題への解像度が上がった気がしている。
完全に自動化されたテスト (テスト自動化の目標 (ページ X)を参照ください) を持つことの本当の価値は、テストを頻繁に実行できることです。テスト駆動開発を行うアジャイル開発者は、数分おきに (少なくともその一部だけでも) テストを実行します。このような動作は、フィードバックループを短くし、コードに混入する欠陥のコストを削減するために推奨されるものです。
自動化テストはフィードバックのサイクルを短く簡潔にすることで生産性を向上させる。
この辺りにWhy We Should Write Test?みたいなトピックが書かれている。
- テストは品質向上に役立つものでなければならない
- 仕様としてのテスト
- バグ退治
- 不具合の局所化
- テストは、SUT を理解するために役立つものでなければなりません
- ドキュメンテーションとしてのテスト
- テストはリスクを減らす (そして導入しない) べきものである
- セーフティネットとしてのテスト
- 害を与えない
- テストは簡単に実行できるものでなければならない
- 完全自動化されたテスト
- 自己チェックテスト (Self-Checking Test)
- 再現性のあるテスト
- テストは書きやすく、保守しやすいものであるべき
- シンプルなテスト
- 表現力豊かなテスト
- 利害関係の分離
- システムが進化しても、テストは最小限のメンテナンスで済むようにしなければなりません
- 堅牢なテスト
テストは品質向上に役立つものでなければならない
この辺りの記述が、「なぜテストを書くのか」に対する答えになりそう。
仕様としてのテスト
SUTがどのような振る舞いを保証しているのかがテストには書かれる。コードだけを実際に読むよりも合わせてテストも読んだ方がSUTに対する理解が早く、誤解も少ない。
バグ退治
テストがあることによって開発者が見逃していたバグを見つけることができる。これはテストを自動化することによってさらに効果を発揮する。コードがリリースされる前段階でテストが走るので、バグの混入したソフトウェアをリリースしてしまう可能性を減らすことができる。テストはある種のバグ予防となる。
不具合の局所化
もし、顧客テストが失敗しているのに、単体テストが失敗していなければ、それは単体テストの欠落の兆候です (X ページの製品バグを参照)。
この節は単体テストにおける話かな。単体テストがあることで不具合の原因箇所が特定しやすくなる。引用の通り、EtoEのような複数コンポーネントを用いたテストが落ちていて単体テストが落ちていないのならば、テストカバレッジが足りないという意味を持つ。
引用しつつ適当なメモ
様々なシナリオを詳細に考え、テストに反映させることは、要件が曖昧な部分や自己矛盾している部分を特定するのに役立ちます。これにより、仕様の品質を向上させることができ、ひいては仕様化されたソフトウェアの品質を向上させることができるのです。
この辺りはTDDのトピックにもあった内容だな。
もし、顧客テストが失敗しているのに、単体テストが失敗していなければ、それは単体テストの欠落の兆候です (X ページの製品バグを参照)。
EtoEテストが落ちているのに単体テストが落ちていないのなら、、、という意。
逆だと原因を突き止めるのが難しい。
自動テストがなければ、"もし...なら結果はどうなるのか?" という質問に答えるためにSUTコードを徹底的に調べる必要があります。自動化されたテストでは、対応するテストをドキュメントとして使用するだけで、 結果がどうなるべきかを教えてくれるはずです
SUTとテストってセットで読むと理解が捗るなというのは常々思っていた。ドキュメントとしての側面はあるよなぁ。
レガシーコードに取り組むとき、私は緊張します。定義上、レガシーコードには自動化されたリグレッションテストのスイートがないのです。このコードに変更を加えることは危険です。なぜなら、何を壊すかわからないし、何かを壊したかどうかを知る術がないからです。
リグレッション・テスト・スイートがあるコードで作業する場合は、もっと素早く作業することができます。ソフトウェアを変更する際に、より実験的なスタイルを採用することができるのです。「これを変えたらどうなるんだろう? 面白い!」。だから、このパラメータはそのためのものなんだ"テストは、チャンスを逃さないための「セーフティネット」として機能するのです
レガシーなコードにおいて、テストはセーフティーネットとして機能するという話。10年選手のプロダクトを触ってきたので身に沁みる。
総じてプロダクションコードを書く時に気をつけることとあまり差異がないように見られた。関心の分離とか単一責任の原則とか、汎用的なコーディングの原則がテストコードの記述にも応用できる。ということがわかった。唯一適用できないというか考える余地がある部分はDRY原則だろうか?
DRY 原則 (Don't Repeat Yourself) は、プロダクションコードに適用するのと同じようにテストコードにも適用すべきです。 しかし、これには逆効果があります。私たちはテストに意図を持たせたいので、コアとなるテストロジックを各テストメソッドに残し、一箇所で確認できるようにするのがベストですが、これは多くのサポートコードをテストユーティリティメソッドに移動し、変更によって影響を受けた場合に一箇所で修正する必要があることを妨げるものではありません。
ここではどのようにテストを書くのか、というHowの部分について触れている。といっても「原則」という命名なので、かなり抽象度は高い。より詳細のものは「パターン」という名前で後ほど説明されるっぽい。
まずテストを書く
いわゆるTDDのこと。
- ユニットテストがデバッグの労力を大幅に削減する。この省略されたコストが「テストを自動化するコスト」と相殺される
- テストを最初に書くので必然的にテスタブルな設計になる
ちなみに、TDDを習得するとそうでない方法でコードを書くことに違和感を覚えるらしい。
Front Door First
対義語っぽい部分の解説をみるとわかりやすそう。
Back Door Manipurationは
バックドア(データベースへの直接アクセスなど)を経由して、テストフィクスチャをセットアップしたり、結果を検証するのです。
なので、Front Door Firstなアプローチは「データベースなどを経由せず、モックなりを用いてテストを行うことを優先する」という解釈ができそう。
挙動検証 (X ページ)やモックオブジェクト (X ページ) を使いすぎると、 「オーバースペックなソフトウェア 」 (脆弱なテスト参照)になり、 テストがよりもろくなり、開発者が望ましいリファクタリングをする気が失せるかもしれません。
モックも使わない。
すべての選択肢が同じように有効である場合、テスト対象のシステム (SUT) をテストするためにラウンドトリップテストを使用すべきです。そのためには、オブジェクトをその公開インターフェースを通してテストし、状態検証 (ページ X)を使用して、正しく動作したかどうかを判断します。
要するにパブリックなインタフェースのみを介したテストを書くべき、という話か。
確かにモックを使うとテストが脆くなる(読みにくくなったり壊れやすくなったりして保守コストが高くなる)のは容易に想像できる。
意図を伝える
多くのコード(約 10 行以上) や条件付きテストロジック (ページ X)を含むテストは、たいてい「よくわからないテスト」 (ページ X) です。 これらのテストは、すべての詳細から「全体像」を推測する必要があるため、理解するのが非常に困難です。
テストコードに条件分岐があるのはおかしいな。この辺りは普遍的な「コードの読みやすさの話」でもある。
より具体的な方法としてテストユーティリティメソッドとかを用いるといった方法がある。
SUTを変更しない
ここはあまり理解できなかった。テスト対象となるコードを修正することなのか、テスト対象そのものを変えるということを指すのか...
おそらくTest Doubleなどでアプリケーションの一部を置き換えたりすることを「SUTを変更する」と指していそう。
そしてこの場合はプロダクションで利用されるコードを実際にテストしていない可能性があることを指すので、テストを書いていることにならないかもしれないという話にみえた。
テストは独立させる
もしテストが相互に依存し、さらに悪いことには順序に依存するならば、テストの失敗が提供する有用なフィードバックを奪ってしまうことになります。
両方のテストが失敗したとき、それが両方のテストが何らかの形で依存しているコードの問題なのか、 それとも最初のテストだけが依存しているコードの問題なのかをどうやって見分けるのでしょうか。両方のテストが失敗した場合、私たちはそれを知ることができません。ここではたった2つのテストについて話しているに過ぎません。何十、何百ものテストがある場合、これがどれほど悪化するか想像してみてください。
テスト間で依存関係を持たないべき、という話。
Back Door Manipurationだと1コのテストでDBが更新された影響で他のテストが落ちてしまう。みたいなのが身近な例。
SUTを分離する
ほとんどのソフトウェアは、自社または他社が開発した他のソフトウェアの上に構築されています。私たちのソフトウェアが他のソフトウェアに依存しており、そのソフトウェアが時間とともに変化する可能性がある場合、他のソフトウェアの動作が変化したために、テストが突然失敗し始めることがあります。私はこの問題をContext Sensitivity (Fragile Test 参照) と呼び、Fragile Test の一種と呼んでいます。
利用している外部パッケージに依存するようなテストは極力書かない。
テストの重複を最小にする
残念ながら、同じ機能を検証するテストは、同じタイミングで失敗することがほとんどです。また、SUTの機能が変更された場合にも、同じようにメンテナンスが必要になる傾向があります。同じ機能を複数のテストで検証することは、テストのメンテナンスコストを増加させ、品質をあまり向上させない可能性が高くなります。
似たようなテストを書きすぎないようにするべき。パターンを完全に網羅したテストを書くのは不可能なので、書くべきテストを選択する訓練を積んでいかないといけない。
テストロジックをプロダクションコードから排除する
テスト対象となるメソッドなどに対して、フックを仕込むことでテストしやすい状態に持ち込もうとしたくなる場合がある。
このようなフックは、一般的にif testing then... のような形式をとります。
しかしテスト時のみ挙動が違うということは、本番稼働時の挙動を検証できていることにならない。
またフックが原因でバグを起こしてしまう可能性もある。
テスト自動化のHowについてより詳細に書かれている。テストの種類(e.g. コンポーネントテスト)の説明が書かれているが、世に出回っているテスト用語はさまざまなバリエーションがあるのでここでは斜め読みしておく。
テスト容易性をどのように確保していくか?というトピックは面白そうなのできちんと読んでいく。
最後にテストする
これはアンチパターンとして紹介されているのだろう。
既存のアプリケーションにユニットテストを後付けしようとした人は、おそらく多くの痛みを経験したことでしょう。これは、私たちができるテストの自動化の中で最も困難なものであり、生産性も最も低いものです。
自動ユニットテストの最初の試みとして、レガシーソフトウェアのテスト改修に取り組むことは、最も決意の固い開発者やプロジェクトマネージャでさえ、確実にやる気をなくさせるので、一番やりたくないことです。
テスト容易性のためのデザイン
テスタビリティの高い設計を前提にデザインしていく。クリーンアーキテクチャに書かれていたようなDependency Injectionなどを用いてインタフェース依存な実装を行なって、Back Door Manipurationをさせないような構造にしていくことが重要。
テスト駆動型テスタビリティ
テスト駆動型で開発していけば必然とテスタビリティの高い設計になる。
制御点・観測点
制御点:任意のSUTを動作させるためのインタフェース
観測点:テスト後の状態を取得する対象(メソッド返り値だったりDBの値だったりする)
一般的には制御点と観測点の両方がSUTのパブリックなインタフェースを用いて行われるのが妥当。この方式を「ラウンドトリップテスト」と呼ぶ。
対義語として「レイヤークロッシングテスト」というものがある。観測点が何らかのテストダブルになることを指す。
この方法はテストが実装を知り過ぎてしまう問題(Overspecified Software)を引き起こす可能性が高いので推奨されない。
レイヤークロッシングテストを避けるためにDependency Injectionを用いたりして実装しようといったことが書かれている。
レイヤーをまたがるテストを書きたい場合、SUT が依存するコンポーネントのうち、独立してテストしたいものに対して、代替可能な依存関係の仕組みを組み込んでおく必要があります。主な候補としては、Dependency Injectionのバリエーションや、Object FactoryやService Locator などの依存関係ルックアップの形式があります。
そういえばテスト自動化の哲学について読んでいなかった。
テストは最初か最後か?
ソフトウェアが「既に完成している」後に、自動化されたユニットテストを書くという規律を持つだけでも、それが簡単であろうとなかろうと大変なことなのです。テストしやすいように設計したとしても、プロダクションコードを修正することなく、簡単かつ自然にテストを書くことができる可能性は低い。テストが先に書かれていれば、システムの設計は本質的にテスト可能である。
最初に書いてしまった方がテスタブルな設計になるので、著者的には最初に書くことを推している。
また、最初にテストを書くメリットとして、プロダクションコードがよりミニマルになることを挙げている。考えうるテストケース(例)を列挙してからそれを満たすコードのみを書くので、不必要なコードを書いてしまう可能性が低い。
テストが事例か?
私が最初に、ソフトウェアが書かれる前にそのソフトウェアの自動テストを書くというコンセプトについて話したとき、一部のリスナーは不思議そうな顔をしたものです。"存在しないソフトウェアのために、どうやってテストを書けるんだ?" と。このような場合、私はBrian Marrickに倣って、議論を組み替えて「例」と「例駆動開発」について話しています。人によっては、「テスト」よりも「例」の方が、コードの前に書くことをイメージしやすいようです。
「テスト」ではなく「例」に言い換えるとTDDは書きやすいらしい。
テスト・バイ・テストか、一斉テストか?
TDDではテストとコードを交互にきめ細かく書いていくことを推奨している。これは書いたテストの記憶が新鮮なので、デバッガを使わずとも原因が解明できるという利点があるから。
一方でテストを羅列してからコードを書いていく派閥もある。これは早期に解決モードに吸い込まれるのを避け、クライアント・テスターのような思考ができるという利点があるから。
妥協案としてはテストを羅列してから、1つのテストケースずつコーディングを行なっていくこと。
アウトサイドインかインサイドアウトか?
アウトサイドイン: ソフトウェアを外側から内側へ設計するということ。ブラックボックス的な顧客テストを考え、その後に各詳細の単体テストを考える手法。
インサイドアウトは逆の意味を持つ。
設計はアウトサイドイン、実装はインサイドアウトで行うことを好む人がいる。この場合は内側のソフトウェアを書く時に外側のソフトウェアの必要性を予測する必要がある。多くの外側のテストはStubやMockが不要になる。
アウトサイドインで設計・実装を行うと、依存性の問題に対処する必要がある。まだ書いていないソフトウェアをStubなどで代用する必要があるから。
インサイドアウトで設計・実装を行うとStubを減らし、欠陥の特定が容易になる一方でテストのメンテナンスコストが高くなる。
状態の検証か振る舞いの検証か?
コードをアウトサイドインで書くと、状態だけではなく振る舞いを検証する必要がある(なぜ...?)
振る舞い主義(behaviorist)の人は状態だけではなく、オブジェクトが依存関係に対して行う呼び出しを指定する必要がある。
behavioristはリファクタリングを難しくする代わりに、MockやSpyを多用してソフトウェアの各ユニットを分離してテストを行う。
フィクスチャーの設計は前倒しで行うか、テストごとに行うか?
従来ではテストシナリオを考慮したDBを用意してから、それを用いてテストを行うのが一般的だった。
今は各テストごとにDB内容を修正する手法「フレッシュフィクスチャー」が一般的。
筆者の哲学
- TDD
- 基本的にテストは一つずつ書くが、思いつく限りのテストをスケルトンとしてリストアップすることもある
- 次のレイヤーの中でどのようなテストが必要が明確にできるので、アウトサイドイン推し
- 状態検証がメインだが、必要に応じて振る舞いのテストを行う
- 個々のテストによってフィクスチャーを設計する派
DBに限らず永続的なフィクスチャをSUTに含めた場合のプラクティスが書かれている。自身はまだ永続的なフィクスチャを持つテストをきちんと書いたことはないので割愛。
SUTの実行結果における検証方法について記載されている。
テストコードの重複を減らす
テストコードの重複は、プロダクションコードの重複ほど悪くないと主張する人もいるでしょう。
自身も同意で、理由としては任意の「テストコードが落ちる→修正する→別のテストが落ちる」という状況の時の認知負荷及び対応時間が、その時行なったプロダクションコードの修正よりも大きくなるケースがほとんどであったからだ。
しかし保守コストを低減したり、壊れにくくなるのであれば重複を排除することは有用だ。
詳細は省略するか下記のようなことを行うことで重複を排除することができる。
- オブジェクトの個々の値を検証するのではなく、オブジェクトそのものを検証する
- 同じ検証は1つのメソッドにまとめる
- フィクスチャ以外が同等なのであればSUTへの呼び出しと検証は同じメソッドにまとめる
条件付きテストロジックの回避
自身はテスト記述時にif構文を用いたことがない。forのようなループ処理も同様(Table Driven Testは書いたことがある)。
なので省略。
逆方向の作業(アウトサイドイン)
テストの最終行から書いていく。という話。アサーションの引数が書かれるので次にそれらの初期化を行う。...といったように逆から書いていくアプローチのこと。
テストダブルの話。
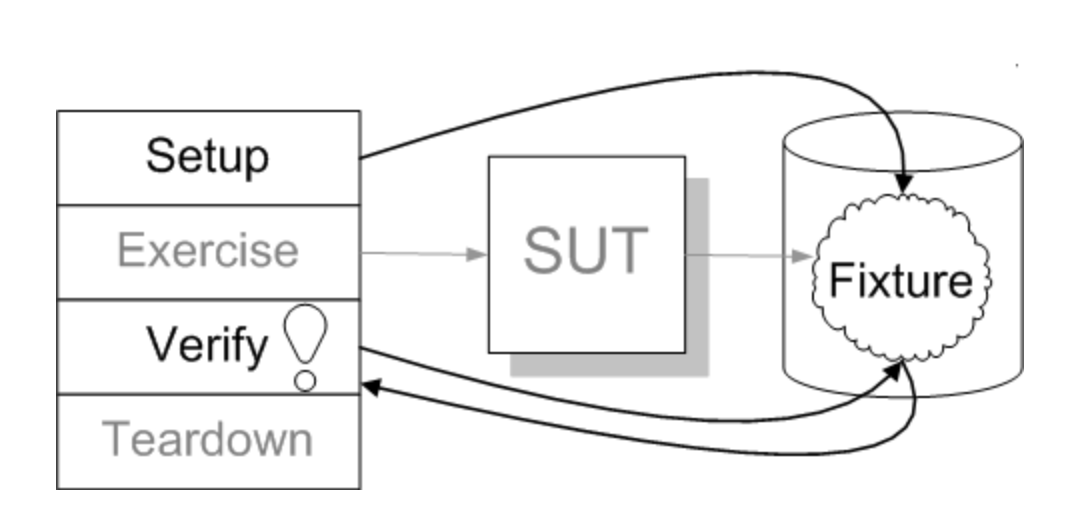
こんな感じで、バックドアを介するようなテストを書くことで間接入力を検証することができるが、下記の点で現実的でない。
- SUTが望ましい間接入力を発生させることができないので、テストしきれているとは言い難い
- テスト用にDBを用意するコストに見合わない
- 許容できない副作用が発生する可能性がある
ということで、テストタブルを用いると上記の問題がおおよそ解決できる。
間接出力も同様の理由でテストダブルの利用を推奨している。
以降は先述の記事と同じ内容が記載されている。
データベースを使ったテストについて書かれている。
データベースを使わないでテストする方法があるのなら、データベースを使わないでテストしましょう!
DBを利用せざるを得ない設計は複雑になるし、テストも複雑になる。さらにテストの実行速度がかなり遅くなる。
データベースの問題点
データベースはテスト自動化を困難にする多くの問題を起こしている。ほとんどはフィクスチャが永続的であるという事実に関連している。
永続的なフィクスチャ
オンメモリで完結するテストと比較すると圧倒的に遅くなる傾向がある。また実行タイミングで結果が異なってしまうテストや可読性の低いテストを記述してしまう可能性が高くなってしまう。
実行後のデータベースが他のテストに影響しないように注意を払わなければならない。この辺りの問題はアプリケーションが大きくなるにつれてメンテナンスコストが上がっていく。
フィクスチャの共有
フィクスチャを共有すると他のテストやフィクスチャ設定ロジックに依存することになり、単独で実行ができない可能性がある。
一般的なフィクスチャ
謎なので後で読もう
データベースを使わないテスト
レイヤードアーキテクチャを用いるとDBを使わずにビジネスロジックをテストすることができる。データアクセス層をテストダブルに置き換えることで分離をおこなう。
レイヤリングが不十分でテストダブルが利用できない場合はフェイクデータベースやインメモリデータベースを利用する。これによってDBを用意する場合と比べて高速にテストを行うことが可能。
ストアドプロシージャのテスト
書いたことないので割愛
テストを自動化するためのロードマップについて書かれている。
テスト自動化の難易度
一般的なテストの種類が簡単な順に紹介されている
- シンプルなエンティティオブジェクト
- ここはどのコンポーネントおよびレイヤーにも依存しないような、クリーンアーキテクチャ文脈で言うエンティティを指すのだろう
-ステートレスサービスオブジェクト - クリーンアーキテクチャ文脈だとユースケースを指す
-ステートフルサービスオブジェクト - いうまでもなくステートフル
- ここはどのコンポーネントおよびレイヤーにも依存しないような、クリーンアーキテクチャ文脈で言うエンティティを指すのだろう
- テストしにくいコード
- UIだったりDBのロジックだったりマルチスレッドなソフトウェアだったり
- オブジェクト指向のレガシーなソフトウェア
- オブジェクト指向じゃないレガシーなソフトウェア
大半がテストを後付けしようとするので、最後の2種類に対してのアプローチの機会が多い。後付けするなら、それをやったことのある方に助けを求めることと、レガシーコード関連の書籍を読むこと。