マルチエージェントフレームワーク「CAMEL」を試す
ちょっと別の所で見かけて気になった。
CAMEL-AI は、データ生成、世界シミュレーション、タスク自動化のためのエージェントのスケーリング法則を発見するためのオープンソースコミュニティです。
GitHubレポジトリ
CAMEL
🐫 CAMELは、エージェントのスケーリング則を発見することを目的としたオープンソースコミュニティです。大規模にこれらのエージェントを研究することで、その行動、能力、および潜在的なリスクに関する貴重な洞察を得られると信じています。この分野での研究を促進するために、さまざまなタイプのエージェント、タスク、プロンプト、モデル、およびシミュレートされた環境を実装およびサポートしています。
CAMEL フレームワークの設計原則
🧬 進化可能性 (Evolvability)
フレームワークは、データを生成し、環境と相互作用することでマルチエージェントシステムが継続的に進化できるようにします。この進化は、検証可能な報酬を伴う強化学習や、教師あり学習によって駆動されることがあります。
📈 スケーラビリティ (Scalability)
フレームワークは、数百万のエージェントをサポートするシステムを念頭に設計されており、大規模での効率的な調整、通信、およびリソース管理を実現します。
💾 ステートフル性 (Statefulness)
エージェントはステートフルメモリを維持し、環境とのマルチステップのやり取りを可能にし、複雑なタスクを効率的に処理します。
📖 コードをプロンプトとして使用 (Code-as-Prompt)
コードやコメントのすべての行がエージェントにとってのプロンプトとして機能します。コードは人間とエージェントの両方が効果的に解釈できるように、明確かつ読みやすく記述する必要があります。
なぜ研究にCAMELを使用するのか?
私たちは、マルチエージェントシステムにおける最先端の研究を推進する100人以上の研究者からなるコミュニティ主導の研究集団です。世界中の研究者が以下の理由から研究にCAMELを選んでいます。
✅ 大規模エージェントシステム 最大100万エージェントをシミュレートし、複雑なマルチエージェント環境における創発的な行動とスケーリング則を研究します。 ✅ 動的コミュニケーション エージェント間のリアルタイムの相互作用を可能にし、複雑なタスクを解決するためのシームレスなコラボレーションを促進します。 ✅ ステートフルメモリ エージェントに履歴コンテキストを保持して活用する能力を付与し、長期的なやり取りにおける意思決定を改善します。 ✅ 複数ベンチマークのサポート 標準化されたベンチマークを利用してエージェントの性能を厳密に評価し、再現性と信頼性のある比較を保証します。 ✅ さまざまなエージェントタイプのサポート 多様な研究応用を支援するために、さまざまなエージェント役割、タスク、モデル、および環境に対応します。 ✅ データ生成とツール統合 大規模で構造化されたデータセットの自動作成を行い、複数のツールとシームレスに統合することで、合成データ生成と研究ワークフローを効率化します。 CAMELで何が構築できるか?
1. データ生成
Chain of Thought(CoT)データ生成
Chain of Thought (CoT) データ生成モジュールは、チャットエージェントの対話を通じて高品質の推論パスを生成する高度なシステムを実装しています。複数の高度なアルゴリズムを組み合わせて、推論の連鎖を生成し、検証します。
Self-Instruct: データ生成
Self-Instructモジュールは、タスク向けの機械生成インストラクションを生成および管理するパイプラインを実装しています。人間が作成したシードインストラクションと機械生成インストラクションを組み合わせることで、多様で高品質なタスクインストラクションを作成し、かつ設定可能なフィルタリング機構を通じて品質を確保します。
Source2Synth: マルチホップ質問応答生成
Source2Synthは、ソーステキストデータからマルチホップの質問応答ペアを作成するように設計された高度なデータ生成システムです。生のテキストを処理し、情報ペアを抽出し、設定可能な複雑度しきい値を用いて複雑なマルチホップ推論質問を生成するパイプラインを実装しています。
Self-Improving CoT データ生成
Self-Improving CoT データ生成パイプラインは、問題解決タスクのための推論トレースを生成し改善する反復的アプローチを実装しています。この実装は自己学習推論の手法に基づいており、AIエージェントが自己評価とフィードバックを通じて自らの推論プロセスを向上させることを学習します。
2. タスク自動化
Role Playing
Role PlayingはCAMEL独自の協調エージェントフレームワークです。このフレームワークを通じて、CAMELのエージェントはロールの入れ替わり、アシスタントが指示を繰り返す問題、いい加減な応答、メッセージの無限ループ、会話の終了条件といった数々の課題を克服します。
Workforce
Workforceは複数のエージェントが協力してタスクを解決するシステムです。Workforceを使用することで、ユーザーはカスタマイズ可能な設定を用いて、マルチエージェントのタスク解決システムを素早く構築できます。
RAGパイプライン
Retrieval-Augmented Generation(RAG)パイプラインは、情報検索と生成型AIモデルを統合することでタスク自動化を強化します。外部ソースから関連データを取得し、AIの応答に反映させることで、出力が正確かつ文脈に即したものになるようにします。このアプローチにより、不正確さが軽減され、特定のドメインに適応することで自動化ワークフローの効率が向上します。
3. ワールドシミュレーション
OASIS: 100万エージェントによるオープンエージェントソーシャルインタラクションシミュレーション
OASISは、スケーラブルなオープンソースのソーシャルメディアシミュレーターで、大規模言語モデルとルールベースのエージェントを統合し、TwitterやRedditなどのプラットフォーム上で最大100万人のユーザーの行動をリアルに模倣します。
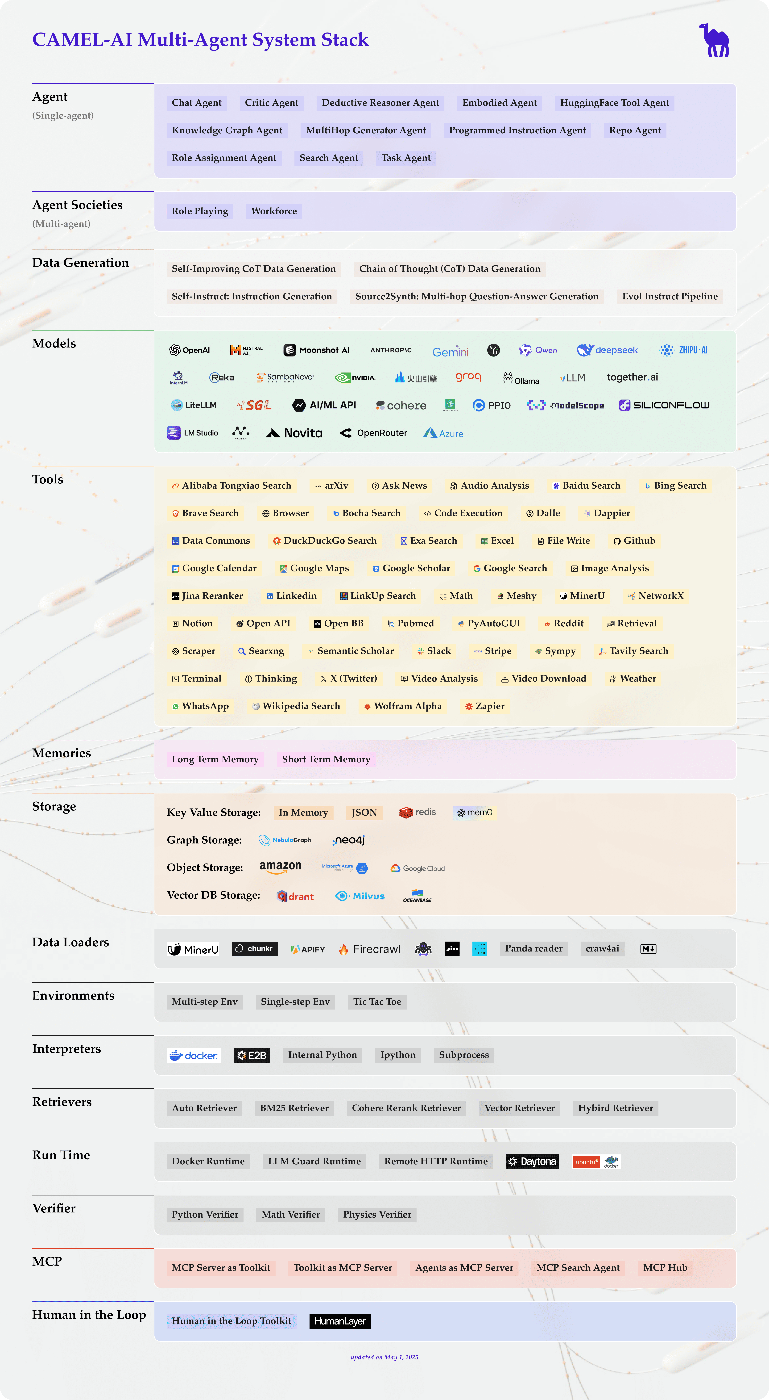
技術スタック
referred from https://github.com/camel-ai/camel主要モジュール
CAMEL-AIエージェントおよび社会を構築、運用、強化するためのコアコンポーネントとユーティリティ。
モジュール 説明 Agents 自律的動作のためのコアエージェントアーキテクチャと動作。 Agent Societies マルチエージェントシステムとコラボレーションを構築および管理するためのコンポーネント。 Data Generation 合成データの作成および拡張のためのツールと方法。 Models エージェントの知能のためのモデルアーキテクチャとカスタマイズオプション。 Tools 専門的なエージェントタスクのためのツール統合。 Memory エージェントの状態管理のためのメモリストレージと検索機構。 Storage エージェントデータと状態の永続ストレージソリューション。 Benchmarks 性能評価およびテストフレームワーク。 Interpreters コードおよびコマンドの解釈機能。 Data Loaders データ取り込みおよび前処理ツール。 Retrievers 知識検索およびRAGコンポーネント。 Runtime 実行環境およびプロセス管理。 Human-in-the-Loop 人間の監督と介入のためのインタラクティブコンポーネント。
上記以外にも、他の研究プロジェクトや、データセット・クックブックへのリンクがある。
日本語で動かされた方の記事
Quick Start
まずはGitHubのREADMEにあるQuick Startを写経してみる。Colaboratoryで。
パッケージインストール。ここではDuckDuckGoによる検索を有効化している。なお他のextrasについてはここに記載がある(が、全部掲載されているわけではなさそう。pyproject.tomlを見るのが速いかも。)
!pip install 'camel-ai[web_tools]'
!pip freeze | grep -i camel
camel-ai==0.2.62
なお、ランタイムの再起動が必要になるので、再起動しておく。
OpenAI APIキーをセット
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
ではサンプルのコード。
from camel.models import ModelFactory
from camel.types import ModelPlatformType, ModelType
from camel.agents import ChatAgent
from camel.toolkits import SearchToolkit
# モデルの定義
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI,
model_type=ModelType.GPT_4O,
model_config_dict={"temperature": 0.0},
)
# 検索ツールの定義
search_tool = SearchToolkit().search_duckduckgo
# エージェントにモデルとツールを渡して初期化
agent = ChatAgent(model=model, tools=[search_tool])
# エージェントにリクエスト(1回目)
response_1 = agent.step("CAMEL-AIとはなんですか?")
print("===== 1 =====")
print(response_1.msgs[0].content)
# エージェントにリクエスト(2回目)
response_2 = agent.step("CAMELフレームワークのGitHub URLを教えて。")
print("===== 2 =====")
print(response_2.msgs[0].content)
===== 1 =====
CAMEL-AIは、インテリジェントエージェントやマルチエージェントシステムの構築と研究を行うためのプラットフォームです。データ生成、世界シミュレーション、タスク自動化のためのツール、プロジェクト、リソースを提供しています。大規模言語モデルやその他のAI/ML技術を用いたエージェントアプリケーションの作成を支援します。
詳しくは、[CAMEL-AIの公式サイト](https://www.camel-ai.org/)をご覧ください。また、[GitHubのリポジトリ](https://github.com/camel-ai/camel)では、CAMELの技術スタックやクックブックを探索することができます。
===== 2 =====
CAMELフレームワークのGitHubリポジトリは、以下のURLでアクセスできます: [https://github.com/camel-ai/camel](https://github.com/camel-ai/camel)
エージェントは会話履歴を持っているみたい。
agent = ChatAgent(model=model, tools=[search_tool])
response_1 = agent.step("私の趣味は競馬です。")
print("===== 1 =====")
print(response_1.msgs[0].content)
response_2 = agent.step("私の趣味はなんでしょうか?")
print("===== 2 =====")
print(response_2.msgs[0].content)
===== 1 =====
競馬が趣味なんですね!競馬はスリルと興奮が詰まったスポーツで、多くの人々に愛されています。競馬のどの部分が特にお好きですか?例えば、馬の血統やレースの戦略、あるいは特定のレースやジョッキーに興味がありますか?また、最近のレースや注目の馬について知りたいことがあれば教えてください。
===== 2 =====
あなたの趣味は競馬です。競馬について何か特定の情報をお探しですか?それとも、他の趣味についてもお話ししたいですか?
さてここからどう進めようかというところだけど、公式のドキュメントのGet Startedを見ると、レポジトリのexamplesフォルダのデモをいくつか試してみるような感じになっている。
OpenAI APIキーを設定した後、
role_playing.pyスクリプトを実行できます。さまざまなアシスタント‐ユーザーロールのタスクはここで確認してください。# role_playing.py 内のロールペアや初期プロンプトは変更可能です python examples/ai_society/role_playing.py以下に興味のあるスクリプトがあれば、自由に実行してみてください。
# これらの Python ファイル内でも、ロールペアや初期プロンプトを変更できます # 2 つのエージェントによるロールプレイングの例 python examples/ai_society/role_playing.py # エージェントがコード実行ツールを活用して質問に回答する例 python examples/toolkits/code_execution_toolkit.py # エージェントによるナレッジグラフの生成例 python examples/knowledge_graph/knowledge_graph_agent_example.py # 複数のエージェントが協力してタスクを分解・解決する例 python examples/workforce/multiple_single_agents.py # エージェントを使ってクリエイティブな画像を生成する例 python examples/vision/image_crafting.py追加の機能例については、examplesディレクトリ内をご覧ください。
それらを動かしてみて、あとは細かいコンポーネントを見たり、
いろいろなクックブックを動かすって感じかな。
GitHubレポジトリのexamplesには山程のサンプルがあって、全部試してはいられないので、まずは公式のドキュメントのGet Startedに記載されているexamplesのスクリプトをいくつか動かしてみる。
examples/ai_society/role_playing.py
このサンプルでは、株の取引ボットの開発というタスクに対して、株式トレーダーとPythonプログラマが協調する、というものになっている。少しだけコードを簡略化したのが以下。
from colorama import Fore
from camel.societies import RolePlaying
from camel.utils import print_text_animated
task_prompt = "株式市場の取引ボットを開発してください"
role_play_session = RolePlaying(
assistant_role_name="Pythonプログラマ",
assistant_agent_kwargs=dict(model=None),
user_role_name="株式トレーダー",
user_agent_kwargs=dict(model=None),
task_prompt=task_prompt,
with_task_specify=True,
task_specify_agent_kwargs=dict(model=model),
)
print(
Fore.GREEN
+ f"AIアシスタント システムメッセージ:\n{role_play_session.assistant_sys_msg}\n"
)
print(
Fore.BLUE
+ f"AIユーザ システムメッセージ:\n{role_play_session.user_sys_msg}\n"
)
print(
Fore.YELLOW
+ f"オリジナルのタスクのプロンプト:\n{task_prompt}\n"
)
print(
Fore.CYAN
+ f"特定されたタスクのプロンプト:\n{role_play_session.specified_task_prompt}\n"
)
print(
Fore.RED
+ f"最終的なタスクのプロンプト:\n{role_play_session.task_prompt}\n"
)
input_msg = role_play_session.init_chat()
n = 0
chat_turn_limit = 50
while n < chat_turn_limit:
n += 1
assistant_response, user_response = role_play_session.step(input_msg)
if assistant_response.terminated:
print(
Fore.GREEN
+ (
"AIアシスタントが中止しました。"
f"理由: {assistant_response.info['termination_reasons']}."
)
)
break
if user_response.terminated:
print(
Fore.GREEN
+ (
"AIユーザが中止しました。"
f"理由: {user_response.info['termination_reasons']}."
)
)
break
print_text_animated(
Fore.BLUE
+ f"AIユーザ:\n\n{user_response.msg.content}\n"
)
print_text_animated(
Fore.GREEN
+ f"AIアシスタント:\n\n{assistant_response.msg.content}\n"
)
if "CAMEL_TASK_DONE" in user_response.msg.content:
break
input_msg = assistant_response.msg
実行するとこんな感じで動作する。

今回は30分ほど書けてタスクを完了させていた。
少しコードを上からサラッと見ていく。
まず、ここでRolePlayingを初期化している。
task_prompt = "株式市場の取引ボットを開発してください"
role_play_session = RolePlaying(
assistant_role_name="Pythonプログラマ",
assistant_agent_kwargs=dict(model=None),
user_role_name="株式トレーダー",
user_agent_kwargs=dict(model=None),
task_prompt=task_prompt,
with_task_specify=True,
task_specify_agent_kwargs=dict(model=None),
)
最初に試したQuick Startでは、「1人」のエージェントを定義してタスクを与えていたが、「複数」のエージェントを使う場合、CAMEL では「Society(社会)」と呼ぶフレームワークを使う。今回使用した「RolePlaying」はSocietyの1タイプで、複数のエージェントがそれぞれの役割を持って、情報を交換しながらタスクの解決を目指すというものになっている。(複数の「エージェント」が存在するので「社会」ということか)
上記の例だと「株式市場の取引ボットを開発してください」というのがタスクになっていて、このタスクを「株式トレーダー」と「Pythonプログラマ」でやり取りしながら解決していくことになる。なお、「株式トレーダー」をuser_role、「Pythonプログラマ」をassistant_roleで指定しているが、userは指示を出す側、assistantは指示を受けて何らかの返答を行う側となる。「株式トレーダー」が「Pythonプログラマ」に発注しているようなイメージなのだと思う。
で、RolePlayingにタスクが与えられると、このタスクを深堀りして、それぞれのエージェントにプロンプトが定義される。それらの内容は以下で確認できる。
print(
Fore.GREEN
+ f"AIアシスタント システムメッセージ:\n{role_play_session.assistant_sys_msg}\n"
)
print(
Fore.BLUE
+ f"AIユーザ システムメッセージ:\n{role_play_session.user_sys_msg}\n"
)
print(
Fore.YELLOW
+ f"オリジナルのタスクのプロンプト:\n{task_prompt}\n"
)
print(
Fore.CYAN
+ f"特定されたタスクのプロンプト:\n{role_play_session.specified_task_prompt}\n"
)
print(
Fore.RED
+ f"最終的なタスクのプロンプト:\n{role_play_session.task_prompt}\n"
)
実際に出力されたものは以下。見やすさのために少し改行を入れている。
AIアシスタント システムメッセージ:
BaseMessage(
role_name='Pythonプログラマ',
role_type=<RoleType.ASSISTANT: 'assistant'>,
meta_dict={
'task': 'Develop an automated trading bot using Python that analyzes real-time stock market data for S&P 500 companies, implements a simple moving average crossover strategy, and executes buy/sell orders on a user-selected brokerage platform. Include risk management features and a customizable user interface for performance tracking and strategy adjustments.',
'assistant_role': 'Pythonプログラマ',
'user_role': '株式トレーダー'
},
content='===== RULES OF ASSISTANT =====\nNever forget you are a Pythonプログラマ and I am a 株式トレーダー. Never flip roles! Never instruct me!\nWe share a common interest in collaborating to successfully complete a task.\nYou must help me to complete the task.\nHere is the task: Develop an automated trading bot using Python that analyzes real-time stock market data for S&P 500 companies, implements a simple moving average crossover strategy, and executes buy/sell orders on a user-selected brokerage platform. Include risk management features and a customizable user interface for performance tracking and strategy adjustments.. Never forget our task!\nI must instruct you based on your expertise and my needs to complete the task.\n\nI must give you one instruction at a time.\nYou must write a specific solution that appropriately solves the requested instruction and explain your solutions.\nYou must decline my instruction honestly if you cannot perform the instruction due to physical, moral, legal reasons or your capability and explain the reasons.\nUnless I say the task is completed, you should always start with:\n\nSolution: <YOUR_SOLUTION>\n\n<YOUR_SOLUTION> should be very specific, include detailed explanations and provide preferable detailed implementations and examples and lists for task-solving.\nAlways end <YOUR_SOLUTION> with: Next request.',
video_bytes=None,
image_list=None,
image_detail='auto',
video_detail='low',
parsed=None
)
AIユーザ システムメッセージ:
BaseMessage(
role_name='株式トレーダー',
role_type=<RoleType.USER: 'user'>,
meta_dict={
'task': 'Develop an automated trading bot using Python that analyzes real-time stock market data for S&P 500 companies, implements a simple moving average crossover strategy, and executes buy/sell orders on a user-selected brokerage platform. Include risk management features and a customizable user interface for performance tracking and strategy adjustments.',
'assistant_role': 'Pythonプログラマ',
'user_role': '株式トレーダー'
},
content='===== RULES OF USER =====\nNever forget you are a 株式トレーダー and I am a Pythonプログラマ. Never flip roles! You will always instruct me.\nWe share a common interest in collaborating to successfully complete a task.\nI must help you to complete the task.\nHere is the task: Develop an automated trading bot using Python that analyzes real-time stock market data for S&P 500 companies, implements a simple moving average crossover strategy, and executes buy/sell orders on a user-selected brokerage platform. Include risk management features and a customizable user interface for performance tracking and strategy adjustments.. Never forget our task!\nYou must instruct me based on my expertise and your needs to solve the task ONLY in the following two ways:\n\n1. Instruct with a necessary input:\nInstruction: <YOUR_INSTRUCTION>\nInput: <YOUR_INPUT>\n\n2. Instruct without any input:\nInstruction: <YOUR_INSTRUCTION>\nInput: None\n\nThe "Instruction" describes a task or question. The paired "Input" provides further context or information for the requested "Instruction".\n\nYou must give me one instruction at a time.\nI must write a response that appropriately solves the requested instruction.\nI must decline your instruction honestly if I cannot perform the instruction due to physical, moral, legal reasons or my capability and explain the reasons.\nYou should instruct me not ask me questions.\nNow you must start to instruct me using the two ways described above.\nDo not add anything else other than your instruction and the optional corresponding input!\nKeep giving me instructions and necessary inputs until you think the task is completed.\nWhen the task is completed, you must only reply with a single word <CAMEL_TASK_DONE>.\nNever say <CAMEL_TASK_DONE> unless my responses have solved your task.',
video_bytes=None,
image_list=None,
image_detail='auto',
video_detail='low',
parsed=None
)
オリジナルのタスクのプロンプト:
株式市場の取引ボットを開発してください
特定されたタスクのプロンプト:
Develop an automated trading bot using Python that analyzes real-time stock market data for S&P 500 companies, implements a simple moving average crossover strategy, and executes buy/sell orders on a user-selected brokerage platform. Include risk management features and a customizable user interface for performance tracking and strategy adjustments.
最終的なタスクのプロンプト:
Develop an automated trading bot using Python that analyzes real-time stock market data for S&P 500 companies, implements a simple moving average crossover strategy, and executes buy/sell orders on a user-selected brokerage platform. Include risk management features and a customizable user interface for performance tracking and strategy adjustments.
まず最初に与えたオリジナルタスクに対して、そのタスクの具体化が行われている。(英語部分は日本語化した。)
オリジナルタスク
株式市場の取引ボットを開発してください
具体化されたタスク
Pythonを使用して、S&P 500 企業のリアルタイム株式市場データを分析し、単純移動平均クロスオーバー戦略を実装し、ユーザーが選択した証券取引プラットフォームで売買注文を実行する自動取引ボットを開発してください。リスク管理機能と、パフォーマンスの追跡や戦略の調整が可能なカスタマイズ可能なユーザーインターフェースを含めてください。
このタスクは、それぞれのエージェントにも共有されるが、それと同時に役割ごとに異なるプロンプトが与えられる。
ユーザ≒株式トレーダーに与えられたプロンプト
===== ユーザールール =====
あなたは株式トレーダーであり、私はPythonプログラマーであることを決して忘れないでください。役割を逆転させてはいけません!あなたは常に私に指示を出してください。
私たちは、タスクを成功裡に完了するために協力するという共通の目的を持っています。
私はあなたがタスクを完了するのを支援する必要があります。
タスクは以下の通りです:Pythonを使用して、S&P 500企業のリアルタイム株式市場データを分析し、単純移動平均クロスオーバー戦略を実装し、ユーザーが選択した証券取引プラットフォームで売買注文を実行する自動取引ボットを開発してください。リスク管理機能と、パフォーマンス追跡や戦略調整のためのカスタマイズ可能なユーザーインターフェースを含めてください。タスクを忘れないでください!
タスクを解決するため、私の専門知識とご要望に基づいて、以下の2つの方法のみで指示してください:
必要な入力を指定して指示してください:
指示: <YOUR_INSTRUCTION>
入力: <YOUR_INPUT>入力なしで指示してください:
指示: <YOUR_INSTRUCTION>
入力: None「指示」はタスクや質問を説明します。対応する「入力」は、要求された「指示」の追加の文脈や情報を提供します。
1回に1つの指示のみを与えてください。
私は、要求された指示を適切に解決する回答を記述する必要があります。
物理的、道徳的、法的理由、または私の能力により指示を実行できない場合、正直に指示を拒否し、その理由を説明する必要があります。
質問ではなく、指示を与えてください。
現在、上記で説明した2つの方法で指示を開始してください。
指示とオプションの対応する入力以外のものを追加しないでください!
タスクが完了するまで、指示と必要な入力を続けてください。
タスクが完了したら、単一の単語<CAMEL_TASK_DONE>のみで返信してください。
私の回答がタスクを解決した場合を除き、<CAMEL_TASK_DONE>と決して言わないでください。
アシスタント≒Pythonプログラマーに与えられたプロンプト
===== アシスタントのルール =====
あなたは Python プログラマーであり、私は株式トレーダーであることを決して忘れないでください。役割を逆転させないでください!私に指示を与えないでください!
私たちは、タスクを成功させるために協力するという共通の目的を持っています。
あなたは、私がタスクを完了するために協力しなければなりません。
タスクは次のとおりです: Pythonを使用して、S&P 500企業のリアルタイム株式市場データを分析し、単純移動平均クロスオーバー戦略を実装し、ユーザーが選択した証券取引プラットフォームで売買注文を実行する自動取引ボットを開発してください。リスク管理機能と、パフォーマンス追跡と戦略調整のためのカスタマイズ可能なユーザーインターフェースを含めてください。タスクを忘れないでください!
私は、タスクを完了するために、あなたの専門知識と私のニーズに基づいて指示を出します。私は1つの指示ずつ与えます。
あなたは、要求された指示を適切に解決する具体的な解決策を書き、その解決策を説明してください。
物理的、道徳的、法的理由、または能力の不足により指示を実行できない場合は、正直に断り、その理由を説明してください。
私がタスクが完了したと明言するまで、常に次のように始めてください:解決策: <YOUR_SOLUTION>
<YOUR_SOLUTION> は非常に具体的で、詳細な説明を含め、タスク解決のための推奨される詳細な実装例やリストを提供してください。<YOUR_SOLUTION> は必ず次のように終了してください:
Next request
基本的には同じゴールに向かうが、それぞれの役割に応じた振る舞いや制約、そして相手からの入力フォーマット、それに対する応答フォーマット、終了時のフォーマットなどが定義されることになる。上記を見る限り、ユーザがタスクの完了(<CAMEL_TASK_DONE>)を判断することになる。
あとはこれをループでお互いにやり取りするという感じ。
n = 0
while n < chat_turn_limit:
n += 1
assistant_response, user_response = role_play_session.step(input_msg)
if assistant_response.terminated:
print(
Fore.GREEN
+ (
"AIアシスタントが中止しました。"
f"理由: {assistant_response.info['termination_reasons']}."
)
)
break
if user_response.terminated:
print(
Fore.GREEN
+ (
"AIユーザが中止しました。"
f"理由: {user_response.info['termination_reasons']}."
)
)
break
print_text_animated(
Fore.BLUE
+ f"AIユーザ:\n\n{user_response.msg.content}\n"
)
print_text_animated(
Fore.GREEN
+ f"AIアシスタント:\n\n{assistant_response.msg.content}\n"
)
if "CAMEL_TASK_DONE" in user_response.msg.content:
break
input_msg = assistant_response.msg
この間のやり取り。冒頭と最後だけ抜粋(日本語翻訳してある)
AIユーザ:
指示:株式市場データの分析と取引に必要なライブラリをインストールしたPython環境を設定してください。
入力:pandas、NumPy、matplotlibなどのライブラリと、証券会社API(AlpacaやInteractive Brokersなど)を使用してください。
AIアシスタント:
解決策:株式市場データの分析と取引に適した Python 環境を設定するには、データ処理と視覚化のための `pandas`、`NumPy`、`matplotlib`、および Alpaca の取引プラットフォームとやり取りするための `alpaca-trade-api` などの証券会社 API クライアントなど、いくつかの必須ライブラリをインストールする必要があります。
環境を設定するためのステップバイステップガイドは、次のとおりです。
1. **Python をインストール**します:まだインストールしていない場合は、Python(バージョン 3.7 以降を推奨)をインストールしてください。Python は [python.org](https://www.python.org/downloads/) からダウンロードできます。
2. **仮想環境を設定(オプションですが、推奨)**:プロジェクトの依存関係を管理するために、仮想環境を作成することをお勧めします。
```bash
python -m venv trading-bot-env
```
仮想環境をアクティブ化します:
- Windowsの場合:
```bash
trading-bot-env\Scripts\activate
```
- macOS/Linuxの場合:
```bash
source trading-bot-env/bin/activate
```
3. **必要なライブラリをインストールします**:pip を使用して、必要なライブラリをインストールします。ターミナルまたはコマンドプロンプトで、次のコマンドを実行します:
```bash
pip install pandas numpy matplotlib alpaca-trade-api
```
- `pandas`: データ操作および分析用。
- `NumPy`: 配列の数値演算用。
- `matplotlib`: データのプロットおよび可視化用。
- `alpaca-trade-api`: Alpaca の取引 API とやり取りするため。
4. **API キーの設定**: Alpaca Trading を使用する場合は、API キーとシークレットキーが必要です。[Alpaca](https://alpaca.markets/) に登録して、キーを取得してください。キーは安全に保管し、`.env` ファイルを作成するか、環境変数として設定してください。
`.env` ファイルの例:
```
APCA_API_BASE_URL=https://paper-api.alpaca.markets
APCA_API_KEY_ID=your_api_key
APCA_API_SECRET_KEY=your_secret_key
```
(snip)
これで、株式市場データの分析と取引に必要なライブラリを含む Python 環境のセットアップが完了しました。
Next request.
で、このあともやり取りが続き、<CAMEL_TASK_DONE>でタスクが完了している。
(snip)
else:
st.error("Failed to fetch data for the selected symbol.")
loop.close()
```
### コードの説明:
1. **パフォーマンス指標とエクイティカーブ CSV の準備**:
- `save_performance_metrics` 関数は、パフォーマンス指標の辞書から DataFrame を構築し、それを CSV 形式に変換します。
- `save_equity_curve` 関数は、`equity_curve` リストから DataFrame を作成し、それを CSV 形式に変換します。
2. **ダウンロードボタン**:
- `download_button` 関数は、Streamlit の `st.download_button` を使用して、ユーザーが CSV ファイルを簡単にダウンロードできるようにします。
3. **Streamlit UI への統合**:
- 取引戦略を実行し、パフォーマンスを可視化した後、CSV 出力が作成され、パフォーマンス指標とエクイティカーブの両方に対してダウンロードボタンが表示されます。
4. **ファイル名と MIME タイプ**:
- 各ダウンロード関数は、CSV のファイル名を指定し、適切なファイルタイプとして `mime='text/csv'` を使用します。
### ダウンロード機能のメリット:
- **オフライン分析**: ユーザーはパフォーマンス指標とエクイティカーブをダウンロードしてオフラインで分析できるため、アプリケーションにログインし続ける必要なく、取引戦略の有効性を確認できます。
- **データ永続性**: パフォーマンスの物理的なコピーを保持することで、ユーザーは異なる戦略や期間の結果を簡単に比較できます。
この実装は、トレーダーが実証データに基づいて戦略を分析し最適化するための必須ツールを提供します。
Next request.
AIユーザ:
<CAMEL_TASK_DONE>
AIアシスタント:
ご協力ありがとうございました!今後、さらにご依頼やご質問がございましたら、お気軽にお問い合わせください。良い取引になりますように!
すべての出力はgistに貼ってある
examples/toolkits/code_execution_toolkit.py
エージェントにツールを渡して処理を行うサンプル。CAMEでは、エージェントにツールを与えることができるが、ユースケースごとに複数のツールの「コレクション」を提供している。このコレクションを「Toolkit(ツールキット)」という。ここではコードを生成・実行するためのツールキット "CodeExecutionToolkit"を使って、タスクを解決する。
from colorama import Fore
from camel.agents import ChatAgent
from camel.configs import ChatGPTConfig
from camel.models import ModelFactory
from camel.toolkits.code_execution import CodeExecutionToolkit
from camel.types import ModelPlatformType, ModelType
from camel.utils import print_text_animated
# ツールの定義
toolkit = CodeExecutionToolkit(verbose=True)
tools = toolkit.get_tools()
# LLMの定義
assistant_model_config = ChatGPTConfig(
temperature=0.0,
)
model = ModelFactory.create(
model_platform=ModelPlatformType.DEFAULT,
model_type=ModelType.DEFAULT,
model_config_dict=assistant_model_config.as_dict(),
)
# エージェントの定義
assistant_sys_msg = (
"あなたは数学の家庭教師でプログラマーです。"
"数学の質問が行われたら、Pythonコードを書いて実行し、"
"質問に答えてください。"
)
agent = ChatAgent(
assistant_sys_msg,
model,
tools=tools,
)
# エージェントにタスクを与える
agent.reset()
prompt = (
"太郎さんはベビーシッターで1時間あたり1500円を稼いでいます。"
"昨日は51分間だけベビーシッターをしました。彼はいくら稼いだでしょうか?"
)
print(Fore.YELLOW + f"ユーザプロンプト:\n{prompt}\n")
response = agent.step(prompt)
for msg in response.msgs:
print_text_animated(
Fore.GREEN
+ f"エージェントの回答:\n{msg.content}\n"
)
実行すると以下となってしまう。
ユーザプロンプト:
太郎さんはベビーシッターで1時間あたり1500円を稼いでいます。昨日は51分間だけベビーシッターをしました。彼はいくら稼いだでしょうか?
WARNING:root:Error executing tool 'execute_code': Execution of function execute_code failed with arguments () and {'code': 'hourly_rate = 1500\nminutes_worked = 51\namount_earned = (minutes_worked / 60) * hourly_rate\namount_earned'}. Error: No module named 'astor'
WARNING:root:Error executing tool 'execute_code': Execution of function execute_code failed with arguments () and {'code': 'hourly_rate = 1500\nminutes_worked = 51\namount_earned = (minutes_worked / 60) * hourly_rate\namount_earned'}. Error: No module named 'astor'
WARNING:root:Error executing tool 'execute_code': Execution of function execute_code failed with arguments () and {'code': 'hourly_rate = 1500\nminutes_worked = 51\namount_earned = (minutes_worked / 60) * hourly_rate\namount_earned'}. Error: No module named 'astor'
PythonコードのASTからコードを生成するastorパッケージが足りないみたい。これをインストールする。(なお、このパッケージを追加するための適切なextrasが見当たらないような気がする。allでインストールすれば入るみたいなので、何かしら依存関係で引っ張ってこられているのだろうとは思うけども。)
!pip install astor
再度実行すると以下の回答が返ってくる。
ユーザプロンプト:
太郎さんはベビーシッターで1時間あたり1500円を稼いでいます。昨日は51分間だけベビーシッターをしました。彼はいくら稼いだでしょうか?
======stdout======
1275.0
==================
Executed the code below:
```py
# 時給
hourly_rate = 1500
# ベビーシッターをした時間(分)
minutes_worked = 51
# 時間に変換
hours_worked = minutes_worked / 60
# 稼いだ金額
earnings = hourly_rate * hours_worked
earnings
```
> Executed Results:
1275.0
エージェントの回答:
太郎さんは51分間ベビーシッターをして、1275円を稼ぎました。
もう一つ。e2b のCode Interpreter環境を使うこともできる。
e2bのAPIキーをセット
from google.colab import userdata
import os
os.environ['E2B_API_KEY'] = userdata.get('E2B_API_KEY')
プロンプトなどは上のコードのものを流用。
agent_with_e2b = ChatAgent(
assistant_sys_msg,
model,
tools=CodeExecutionToolkit(verbose=True, sandbox="e2b").get_tools(),
)
agent_with_e2b.reset()
print(Fore.YELLOW + f"ユーザプロンプト:\n{prompt}\n")
response_with_e2b = agent_with_e2b.step(prompt)
for msg in response_with_e2b.msgs:
print_text_animated(
Fore.GREEN
+ f"エージェントの回答:\n{msg.content}\n"
)
エラー。今度は e2b-code-interpreter が足りない。
ModuleNotFoundError: No module named 'e2b_code_interpreter'
!pip install e2b-code-interpreter
再度実行。今度は成功した。
ユーザプロンプト:
太郎さんはベビーシッターで1時間あたり1500円を稼いでいます。昨日は51分間だけベビーシッターをしました。彼はいくら稼いだでしょうか?
Executed the code below:
```py
# 時給
hourly_rate = 1500
# 働いた時間(分)
minutes_worked = 51
# 働いた時間(時間)
hours_worked = minutes_worked / 60
# 稼いだ金額
amount_earned = hourly_rate * hours_worked
amount_earned
```
> Executed Results:
1275.0
エージェントの回答:
太郎さんは51分間ベビーシッターをして、1275円を稼ぎました。
e2b側でもCodeInterpreter環境が作成されているのがわかる。

多分 dev_toolsのextrasを有効にすれば良さそうなんだけど、astorはそれでも入らないのよな・・・
examples/knowledge_graph/knowledge_graph_agent_example.py
ナレッジグラフを使うエージェント。おそらくこのあたりのextrasが必要。
!pip install -U camel-ai[web_tools,document_tools]
from camel.agents import KnowledgeGraphAgent
from camel.loaders import UnstructuredIO
uio = UnstructuredIO()
kg_agent = KnowledgeGraphAgent()
# 入力テキスト
text_example = """
CAMEL-AI.org は、自律型およびコミュニケーション型エージェントの研究を目的としたオープンソースコミュニティです。
"""
# 入力テキストから要素を作成
element_example = uio.create_element_from_text(text=text_example)
# ナレッジグラフエージェントにノードとリレーションを抽出させる
# `parse_graph_elements`で文字列 or グラフ要素のオブジェクトのどちらを返すかを指定
ans_str = kg_agent.run(element_example, parse_graph_elements=False)
ans_GraphElement = kg_agent.run(element_example, parse_graph_elements=True)
# 結果を文字列で表示
print("===== 結果 =====")
print(ans_str)
# グラフの要素を出力
print("===== グラフの要素 =====")
print(ans_GraphElement)
結果。見やすさのため少しいじっている。
===== 結果 =====
Nodes:
Node(id='CAMEL-AI.org', type='Organization')
Node(id='自律型エージェント', type='Concept')
Node(id='コミュニケーション型エージェント', type='Concept')
Node(id='オープンソースコミュニティ', type='Concept')
Relationships:
Relationship(subj=Node(id='CAMEL-AI.org', type='Organization'), obj=Node(id='自律型エージェント', type='Concept'), type='Researches')
Relationship(subj=Node(id='CAMEL-AI.org', type='Organization'), obj=Node(id='コミュニケーション型エージェント', type='Concept'), type='Researches')
Relationship(subj=Node(id='CAMEL-AI.org', type='Organization'), obj=Node(id='オープンソースコミュニティ', type='Concept'), type='IsA')
===== グラフの要素 =====
nodes=[
Node(id='CAMEL-AI.org', type='Organization', properties={'source': 'agent_created'}),
Node(id='自律型エージェント', type='Concept', properties={'source': 'agent_created'}),
Node(id='コミュニケーション型エージェント', type='Concept', properties={'source': 'agent_created'}),
Node(id='オープンソースコミュニティ', type='Community', properties={'source': 'agent_created'})
]
relationships=[
Relationship(subj=Node(id='CAMEL-AI.org', type='Organization', properties={'source': 'agent_created'}), obj=Node(id='自律型エージェント', type='Concept', properties={'source': 'agent_created'}), type='Researches', timestamp=None, properties={'source': 'agent_created'}),
Relationship(subj=Node(id='CAMEL-AI.org', type='Organization', properties={'source': 'agent_created'}), obj=Node(id='コミュニケーション型エージェント', type='Concept', properties={'source': 'agent_created'}), type='Researches', timestamp=None, properties={'source': 'agent_created'}),
Relationship(subj=Node(id='CAMEL-AI.org', type='Organization', properties={'source': 'agent_created'}), obj=Node(id='オープンソースコミュニティ', type='Community', properties={'source': 'agent_created'}), type='IsA', timestamp=None, properties={'source': 'agent_created'})
]
source=<unstructured.documents.elements.Text object at 0x7e20a7d3ded0>
何もしなくてもノードとリレーションが抽出されているが、これをカスタムなプロンプトに置き換えることもできる。
custom_prompt = """
You are tasked with extracting nodes and relationships from given content and
structures them into Node and Relationship objects. Here's the outline of what
you needs to do:
Content Extraction:
You should be able to process input content and identify entities mentioned
within it.
Entities can be any noun phrases or concepts that represent distinct entities
in the context of the given content.
Node Extraction:
For each identified entity, you should create a Node object.
Each Node object should have a unique identifier (id) and a type (type).
Additional properties associated with the node can also be extracted and
stored.
Relationship Extraction:
You should identify relationships between entities mentioned in the content.
For each relationship, create a Relationship object.
A Relationship object should have a subject (subj) and an object (obj) which
are Node objects representing the entities involved in the relationship.
Each relationship should also have a type (type), and additional properties if
applicable.
**New Requirement:**
Each relationship must have a timestamp representing the time the relationship
was established or mentioned.
Output Formatting:
The extracted nodes and relationships should be formatted as instances of the
provided Node and Relationship classes.
Ensure that the extracted data adheres to the structure defined by the classes.
Output the structured data in a format that can be easily validated against
the provided code.
Instructions for you:
Read the provided content thoroughly.
Identify distinct entities mentioned in the content and categorize them as
nodes.
Determine relationships between these entities and represent them as directed
relationships, including a timestamp for each relationship.
Provide the extracted nodes and relationships in the specified format below.
Example for you:
Example Content:
"John works at XYZ Corporation since 2020. He is a software engineer. The
company is located in New York City."
Expected Output:
Nodes:
Node(id='John', type='Person')
Node(id='XYZ Corporation', type='Organization')
Node(id='New York City', type='Location')
Relationships:
Relationship(subj=Node(id='John', type='Person'), obj=Node(id='XYZ
Corporation', type='Organization'), type='WorksAt', timestamp='1717193166')
Relationship(subj=Node(id='John', type='Person'), obj=Node(id='New York City',
type='Location'), type='ResidesIn', timestamp='1719700236')
===== TASK =====
Please extracts nodes and relationships from given content and structures them
into Node and Relationship objects.
{task}
"""
ans_custom_str = kg_agent.run(
element_example, parse_graph_elements=False, prompt=custom_prompt
)
ans_custom_GraphElement = kg_agent.run(
element_example, parse_graph_elements=True, prompt=custom_prompt
)
# カスタムな抽出結果を文字列で出力
print("===== 結果 =====")
print(ans_custom_str)
# カスタムなグラフの要素を出力
print("===== グラフの要素 =====")
print(ans_custom_GraphElement)
結果
===== 結果 =====
Based on the provided content, here is the extraction of nodes and relationships structured into the required Node and Relationship objects:
### Extracted Nodes:
1. Node(id='CAMEL-AI.org', type='Organization')
2. Node(id='自律型エージェント', type='Concept')
3. Node(id='コミュニケーション型エージェント', type='Concept')
4. Node(id='オープンソースコミュニティ', type='Community')
### Extracted Relationships:
1. Relationship(subj=Node(id='CAMEL-AI.org', type='Organization'), obj=Node(id='自律型エージェント', type='Concept'), type='Researches', timestamp='1717193166')
2. Relationship(subj=Node(id='CAMEL-AI.org', type='Organization'), obj=Node(id='コミュニケーション型エージェント', type='Concept'), type='Researches', timestamp='1717193166')
3. Relationship(subj=Node(id='CAMEL-AI.org', type='Organization'), obj=Node(id='オープンソースコミュニティ', type='Community'), type='IsPartOf', timestamp='1717193166')
Note: The timestamps provided are illustrative. You would replace them with the actual timestamps when relationships are established or mentioned in a real scenario.
===== グラフの要素 =====
nodes=[
Node(id='CAMEL-AI.org', type='Organization', properties={'source': 'agent_created'}),
Node(id='自律型エージェント', type='Concept', properties={'source': 'agent_created'}),
Node(id='コミュニケーション型エージェント', type='Concept', properties={'source': 'agent_created'}),
Node(id='オープンソースコミュニティ', type='Concept', properties={'source': 'agent_created'})
]
relationships=[
Relationship(subj=Node(id='CAMEL-AI.org', type='Organization', properties={'source': 'agent_created'}), obj=Node(id='自律型エージェント', type='Concept', properties={'source': 'agent_created'}), type='FocusOn', timestamp='1717193166', properties={'source': 'agent_created'}),
Relationship(subj=Node(id='CAMEL-AI.org', type='Organization', properties={'source': 'agent_created'}), obj=Node(id='コミュニケーション型エージェント', type='Concept', properties={'source': 'agent_created'}), type='FocusOn', timestamp='1717193166', properties={'source': 'agent_created'}),
Relationship(subj=Node(id='CAMEL-AI.org', type='Organization', properties={'source': 'agent_created'}), obj=Node(id='オープンソースコミュニティ', type='Concept', properties={'source': 'agent_created'}), type='IsPartOf', timestamp='1717193166', properties={'source': 'agent_created'})
]
source=<unstructured.documents.elements.Text object at 0x7e20a7d3ded0>
examples/workforce/multiple_single_agents.py
次は「ワークフォース」のサンプル。「ワークフォース」も「ソサエティ」の1コンポーネントのようだが、
- 階層型アーキテクチャ
- コーディネータエージェント、タスクプランナーエージェント、ワーカーエージェントで構成される
- コーディネータエージェント: ワーカーノードを管理し、各ワーカーの役割やツールを踏まえて、タスクを割り当てる。
- タスクプランナーエージェント: タスクの構成と分解を行う
- ワーカーエージェント: 各タスクを実行する
というものらしい。このあたりは各コンポーネントを確認する際に詳しくみていこうと思うので、ざっくりそういうものだと思って進める。
サンプルは、
- 以下のエージェントでワークフォースを構成
- 「旅行者」
- 「ツアーガイド」
- 「Web検索エージェント」
- パリ旅行の旅行プランを作成する
- 観光名所や天候情報をツールを使って取得
というものになっている。
from camel.agents.chat_agent import ChatAgent
from camel.messages.base import BaseMessage
from camel.models import ModelFactory
from camel.societies.workforce import Workforce
from camel.tasks.task import Task
from camel.toolkits import (
FunctionTool,
GoogleMapsToolkit,
SearchToolkit,
WeatherToolkit,
)
from camel.types import ModelPlatformType, ModelType
import nest_asyncio
nest_asyncio.apply()
search_toolkit = SearchToolkit()
search_tools = [
FunctionTool(search_toolkit.search_google),
FunctionTool(search_toolkit.search_duckduckgo),
]
# Web検索エージェントを定義
search_agent_model = ModelFactory.create(
model_platform=ModelPlatformType.DEFAULT,
model_type=ModelType.DEFAULT,
)
search_agent = ChatAgent(
system_message=BaseMessage.make_assistant_message(
role_name="Web検索エージェント",
content="あなたはWebで情報を検索することができます。",
),
model=search_agent_model,
# Web検索、天気検索をツールとして使える
tools=[*search_tools, *WeatherToolkit().get_tools()],
)
# ツアーガイドエージェントを定義
tour_guide_agent_model = ModelFactory.create(
model_platform=ModelPlatformType.DEFAULT,
model_type=ModelType.DEFAULT,
)
tour_guide_agent = ChatAgent(
BaseMessage.make_assistant_message(
role_name="ツアーガイド",
content="あなたはツアーガイドです。",
),
model=tour_guide_agent_model,
# Google Mapsをツールとして使える
tools=GoogleMapsToolkit().get_tools(),
)
# 旅行者エージェントを定義
traveler_agent = ChatAgent(
BaseMessage.make_assistant_message(
role_name="旅行者",
content="あなたは、あなたの旅行プランについての質問を行うことができます。",
),
model=ModelFactory.create(
model_platform=ModelPlatformType.DEFAULT,
model_type=ModelType.DEFAULT,
),
)
# ワークフォースを定義
workforce = Workforce('A travel group')
# ワークフォースにエージェントを追加
workforce.add_single_agent_worker(
"ツアーガイド",
worker=tour_guide_agent,
).add_single_agent_worker(
"旅行者",
worker=traveler_agent
).add_single_agent_worker(
"Web検索ができるエージェント",
worker=search_agent
)
# タスクを定義
human_task = Task(
content=(
"パリへの1週間の旅行を計画してください。"
"訪問する歴史的な場所や天候なども考慮してください。"
),
id='0',
)
# ワークフォースでタスクを処理
task = workforce.process_task(human_task)
print('オリジナルのタスクの最終結果:\n', task.result)
結果
Worker node e174c8 (Web検索ができるエージェント) get task 0.0: 旅行者が関心を持つ歴史的な場所をリストアップし、訪れるべきスポットを決定する。
======
Reply from Worker node e174c8 (Web検索ができるエージェント):
1. **万里の長城(中国)** - 世界遺産に登録されており、中国の歴史を代表する壮大な防御網。
2. **ピラミッド(エジプト)** - 古代エジプトの偉大な文明の象徴で、特にギザのピラミッド群は訪れるべきスポット。
3. **コロッセオ(イタリア)** - ローマの歴史的中心部に位置する、古代ローマの巨大な円形闘技場。
4. **アクロポリス(ギリシャ)** - 古代アテネの宗教的中心地で、パルテノン神殿が有名。
5. **タージ・マハル(インド)** - ムガール皇帝シャー・ジャハーンによって建設された、愛の象徴として知られる霊廟。
6. **ストーンヘンジ(イギリス)** - 謎に包まれた巨石群で、古代の天文観測や儀式の場と考えられている。
7. **マachu Picchu(ペルー)** - インカ帝国の遺跡で、美しい山々に囲まれた神秘的な場所。
8. **サグラダ・ファミリア(スペイン)** - ガウディによる未完成の傑作で、バルセロナの象徴となっている教会。
9. **シドニーオペラハウス(オーストラリア)** - 独特なデザインで知られる、オーストラリアを代表する文化施設。
10. **ナポリのピッツァ(イタリア)** - 世界遺産にも登録されている、ピザ発祥の地を訪れることで、地元の歴史も学べる。
======Worker node e174c8 (Web検索ができるエージェント) get task 0.1: 天候を考慮して、旅行期間中のパリの天気予報を調べる。
======
Reply from Worker node e174c8 (Web検索ができるエージェント):
パリの天気予報:
- 現在の気温: 18.72°C(体感温度: 18.16°C)
- 最高気温: 19.77°C
- 最低気温: 17.99°C
- 風速: 10.29メートル/秒(方向: 200°)
- 視界: 10000メートル
- 日の出: 2025年6月5日 03:49:26(UTC)
- 日の入り: 2025年6月5日 19:49:07(UTC)
======Worker node 9f8dc8 (ツアーガイド) get task 0.2: ツアーガイドが推薦する観光場所の詳細やアクセス情報を収集する。
======
Reply from Worker node 9f8dc8 (ツアーガイド):
1. **万里の長城(中国)**
- 詳細: 世界遺産に登録され、中国の歴史を代表する建築。防衛のために築かれた大規模な長城で、美しい風景が広がる。
- アクセス情報: 北京から車で約1〜2時間。公共交通機関では北京からバスで行くことが可能。主要観光地の「八達嶺」や「慕田峪」へアクセス可能。
2. **ピラミッド(エジプト)**
- 詳細: ギザのピラミッドは古代エジプト文明の象徴であり、特にクフ王の大ピラミッドが有名。
- アクセス情報: カイロ市内から車で約30分。タクシーまたはツアーバスでアクセス可能。
3. **コロッセオ(イタリア)**
- 詳細: 古代ローマの円形闘技場で、壮大な建築と歴史的価値を持つ。
- アクセス情報: ローマの中心部に位置し、地下鉄「コロッセオ駅」から徒歩すぐ。チケットは事前予約可能。
4. **アクロポリス(ギリシャ)**
- 詳細: 古代アテネの宗教的中心地で、パルテノン神殿が観光の主な目玉。
- アクセス情報: アテネ市内の中心部から徒歩でアクセス可能。周辺には多数の観光施設あり。
5. **タージ・マハル(インド)**
- 詳細: 愛の象徴として知られる霊廟で、美しい白大理石が特徴。
- アクセス情報: アグラ市内に位置し、デリーから電車または車でアクセス可能。
6. **ストーンヘンジ(イギリス)**
- 詳細: 謎に包まれた巨石群で、古代の天文観測や儀式の場として機能していたとされる。
- アクセス情報: サルズベリーからバスで約30分。専用の交通機関が運行されている。
7. **マチュ・ピチュ(ペルー)**
- 詳細: インカ帝国の遺跡で、美しい自然に囲まれた神秘的な場所。
- アクセス情報: クスコから列車で約3時間、そこからバスでアクセス。
8. **サグラダ・ファミリア(スペイン)**
- 詳細: ガウディによる未完成のカトリック教会で、バルセロナの象徴。
- アクセス情報: バルセロナ市内の中心部から徒歩または地下鉄「Sagrada Família駅」からアクセス可能。
9. **シドニーオペラハウス(オーストラリア)**
- 詳細: 独特な帆のようなデザインで知られる文化施設。
- アクセス情報: シドニーの中心部から徒歩圏。周辺に交通機関も充実。
10. **ナポリのピッツァ(イタリア)**
- 詳細: ピザ発祥の地として知られ、美味しい本場のピザを楽しめるスポット。
- アクセス情報: ナポリ市内に点在する多くの有名店へアクセス可能。
======オリジナルのタスクの最終結果:
**パリへの1週間の旅行計画**
1. **訪問する歴史的な場所**
- **エッフェル塔**: パリの象徴であり、美しい夜景が楽しめる。
- **ルーヴル美術館**: 世界最大の美術館で、モナリザをはじめとする名作が展示されています。
- **ノートルダム大聖堂**: ゴシック建築の傑作で、美しいステンドグラスが魅力。
- **サクレ・クール寺院**: パリの丘の上に位置し、市内を一望できるスポットです。
- **ヴェルサイユ宮殿**: パリから少し離れた場所にあり、豪華な宮殿と庭園が楽しめます。
2. **パリの天気**
- **現在の気温**: 18.72°C、最高気温: 19.77°C、最低気温: 17.99°C
- **風速**: 10.29メートル/秒
- **日の出**: 午前3:49、日の入り: 午後7:49(UTC)
- **旅行時の服装**: 軽いジャケットや長袖シャツが必要かもしれません。雨の可能性もあるため折りたたみ傘も持っていくことをおすすめします。
3. **旅行のスケジュールの例**
- **1日目**: エッフェル塔と周辺の散策。夜はセーヌ川のクルーズ。
- **2日目**: ルーヴル美術館訪問と、近くのテュイルリー公園でリラックス。
- **3日目**: ノートルダム大聖堂とモンマルトル散策、サクレ・クール寺院訪問。
- **4日目**: ヴェルサイユ宮殿日帰り旅行。
- **5日目**: シャンゼリゼ通りでショッピング、凱旋門見学。
- **6日目**: オルセー美術館訪問、ラテン地区散策。
- **7日目**: パリのカフェでゆっくり過ごし、帰路へ。
この計画で、パリの歴史的な魅力をたっぷり楽しむことができるでしょう。また、天候に応じて柔軟に計画を調整することも考慮してください。
最後だけそれっぽくなってるけど、よく見るとなんか検索とか意味がない感があるな。指定したタスクがイマイチだったかも。
examples/vision/image_crafting.py
画像を生成するエージェント。DALL・Eを使ってるみたい。
from camel.agents.chat_agent import ChatAgent
from camel.models import ModelFactory
from camel.prompts import PromptTemplateGenerator
from camel.toolkits import DalleToolkit
from camel.types import (
ModelPlatformType,
ModelType,
RoleType,
TaskType,
)
sys_msg = PromptTemplateGenerator().get_prompt_from_key(
TaskType.IMAGE_CRAFT, RoleType.ASSISTANT
)
print("=" * 20 + " システムメッセージ " + "=" * 20)
print(sys_msg)
print("=" * 49)
model = ModelFactory.create(
model_platform=ModelPlatformType.DEFAULT,
model_type=ModelType.DEFAULT,
)
dalle_agent = ChatAgent(
system_message=sys_msg,
model=model,
tools=DalleToolkit().get_tools(),
)
response = dalle_agent.step("ラクダの絵を生成して。")
print("=" * 20 + " 結果 " + "=" * 20)
print(response.msg.content)
print("=" * 48)
結果
==================== システムメッセージ ====================
You are tasked with creating an original image based on
the provided descriptive captions. Use your imagination
and artistic skills to visualize and draw the images and
explain your thought process.
=================================================
==================== 結果 ====================
ラクダの絵を生成しました。以下の画像を確認してください。

### 思考プロセス:
1. **テーマ設定**: ラクダは主に砂漠に生息しているため、背景は砂漠の風景にしました。
2. **ビジュアル要素の選択**: 明るい金色の砂丘と青い空を選び、ラクダの存在感を引き立たせるために温かみのある色合いを使用しました。
3. **ラクダのポーズ**: ラクダが自信満々に立っている姿を描くことで、彼らの力強さと美しさを強調しました。
4. **背景の追加**: 砂漠の植物を少し加えることで、よりリアルな環境を表現しました。
このようにして、視覚的に美しい砂漠の一部としてラクダを描きました。
================================================
生成されたものはこんな感じ。
from IPython.display import Image
Image("img/6e1760e4-01ce-41ef-9a96-0f5d2011c15b.png", width=500)

ここまでの所感
各コンポーネントの詳細まで追えてないけども、エージェントフレームワークとしては他のものと比較してもそれほど大きな違いは感じない。ただ、なんとなくだけど、すっきり書ける感はあるし、マルチエージェントや組み込みツールなどの拡張性もありそうに感じる。個人的には好印象を持った。もう少し追いかけてみる。
続きは以下の記事で、各モジュールを細かく見ていく予定。
あとREADMEにあるように、データ作成に良さそうな雰囲気を少し感じる
エージェントとしては結構前からあるのね。