LlamaIndexモジュールガイドを試してみる: Indexing
Document/Nodeのリストに対してインデックスを作成すると検索クエリが実行できる。インデックスはRAGのユースケースにおいてLlamaIndexのコアの部分になる。
- インデックスはDocument、Nodeのどちらからでも作成できる。
- ハイレベルAPIでは、DocumentからQuery EngineやChat Engineを作成する。
- 低レベルAPIでは、インデックスはNodeから作成され、Retrieverインタフェースでアクセスする。
インデックスには複数の種類がある。
- VectorStoreIndex
- Summary Index
- Tree Index
- Keyword Table Index
- Knowledge Graph Index
- SQL Index
- Document Summary Index
最も一般的に使用されるのは、VectorStoreIndexになる。
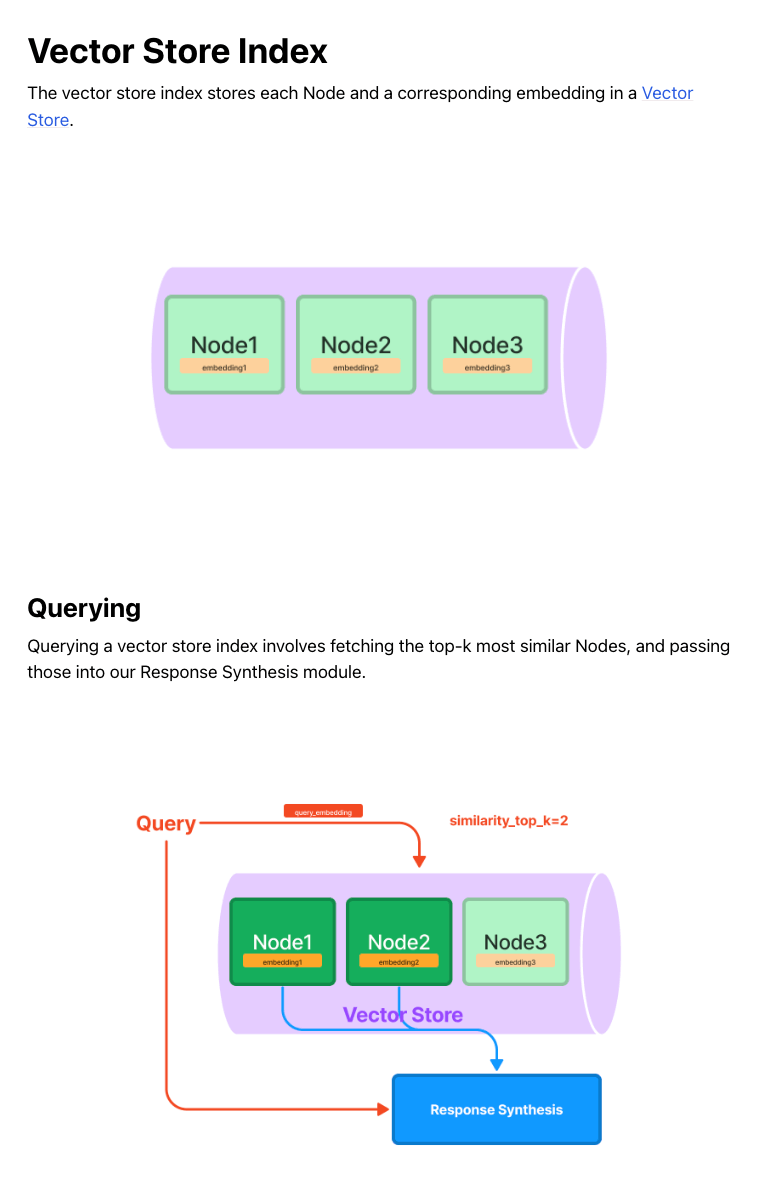
Vector Store Index
ベクトル検索用のインデックス。
from_documentsを使うと、Documentからインデックスを作成できる。この場合は内部でNodeに分解され、Embeddings変換が行われた上で、インデックスが作成される。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
reader = SimpleDirectoryReader(input_dir="./data", recursive=True)
documents = reader.load_data()
index = VectorStoreIndex.from_documents(documents, show_progress=True)
Nodeからドキュメントを作成する場合は、NodeParser/TextSplitterを使うなり、Ingestion Pipelineを使うなりして、作成したNodeを直接VectorStoreIndexに渡してやる。こちらの方がチャンクをどう分割するか、Embeddingのモデルに何を使うか等の細かい設定ができるのだと思う。
以下はIngestion Pipelineを使った場合。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index.text_splitter import SentenceSplitter
from llama_index.embeddings import OpenAIEmbedding
from llama_index.ingestion import IngestionPipeline, IngestionCache
reader = SimpleDirectoryReader(input_dir="./data", recursive=True)
documents = reader.load_data()
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=400, chunk_overlap=50),
OpenAIEmbedding(),
]
)
nodes = pipeline.run(documents=documents)
index = VectorStoreIndex(nodes)
当然それぞれをスタンドアローンで順番に処理することもできるが、前回少し触れたので割愛。
上に書いた通り、retrieverインタフェース経由で検索ができる。
retriever = index.as_retriever(similarity_top_k=5)
result = retriever.retrieve("有馬記念を勝ったのはなんという馬?")
for i in result:
print("Score: {}\nDocument: {}\nText: {}\n".format(i.get_score(), i.metadata["file_name"], i.get_text().replace("\n","")))
Score: 0.8572101040131012
Document: ドウデュース.txt
Text: 2023年最終戦として有馬記念へ出走。鞍上には武豊が復帰した。鞍上横山和生と本レースがラストランとなっており、レースを牽引して尚直線粘るタイトルホルダーと、二番手から先に仕掛けていた鞍上クリストフ・ルメールのスターズオンアースを抜き去り、先頭でゴール板を駆け抜けて見事復活の勝利を挙げた。武豊は2017年のキタサンブラック以来、6年ぶりの制覇となった。また、54歳9カ月10日での有馬記念勝利は最年長勝利記録であり、同時に自身が持つJRA・GI最年長勝利記録(54歳19日)を更新。ドリームジャーニーやオルフェーヴル、ブラストワンピースに騎乗し歴代最多の有馬記念4勝を挙げている池添謙一に並ぶ勝利数となった。
Score: 0.8510514084579371
Document: イクイノックス.txt
Text: ジャパンカップの親子制覇は史上7度目である。天皇賞(秋)・ジャパンカップを連勝するのは史上5頭目で、宝塚記念を含む3連勝はテイエムオペラオー以来23年ぶり2頭目となる。2着にリバティアイランドが入ったため、馬連のオッズが1.8倍となり、2005年の秋華賞を制したエアメサイアと2着馬のラインクラフトと並び、馬連の低額配当タイの記録となった。GI6連勝はグレード制が導入された1984年以降では、テイエムオペラオー、ロードカナロアのGI競走の連勝記録に並んだ。芝平地の古馬GⅠ6勝は日本馬歴代最多タイ。木村哲也調教師は本競走初制覇。また、クリストフ・ルメールは武豊と並ぶジャパンカップ最多4勝目。そのほかにも、3着に5番人気のスターズオンアースが入ったため、3連単のオッズが11.
Score: 0.8505816608886128
Document: イクイノックス.txt
Text: 鞍上のルメールは「直線は勝ち馬をマークして外に出して追いだしたら、(相手が)伸び返す形になってしまったかな」と振り返った。次走として天皇賞(秋)に出走することを表明した。東京優駿出走後の左前脚のダメージについては、経過は良好とした。10月30日、予定通り天皇賞(秋)に出走。1番人気に推され、好スタートを切ると、前半1000メートルを57秒4で通過するというハイペースで大逃げを図ったパンサラッサを追う形で馬群の中団を追走。最後の直線に入って鞍上のルメールがムチを入れると、逃げ粘るパンサラッサをゴール寸前で後方(ルメール曰く、パンサラッサとの差は約15馬身はあった)からやはりメンバー最速の上がり3ハロン32秒7という末脚を発揮し差し切って勝利。GI初勝利を飾った。
Score: 0.8487167372030009
Document: イクイノックス.txt
Text: 父のキタサンブラックは現役時代に宝塚記念を勝利することがなかったが、産駒である本馬がリベンジを果たすことに成功した。これにより、史上16頭目の有馬記念と宝塚記念の秋春グランプリ制覇を成し遂げたほか、史上21頭目となるJRA獲得賞金10億円を突破した。キャリア8戦目での10億円突破は史上最速。また、騎乗したルメールはJRA・GI通算45勝目、木村調教師は同GI5勝目を挙げた。 次走として連覇のかかる天皇賞(秋)に出走すると表明した。10月12日、ロンジンワールドベストレースホースランキング(2023年1月1日から10月8日までの世界の主要レースを対象)が発表され、イクイノックスはレーティングは129ポンドで変わらず世界第1位となった。10月29日、予定通り天皇賞(秋)に出走。
Score: 0.8479126950188658
Document: イクイノックス.txt
Text: 688票を集め3位となった。12月25日、予定通り有馬記念に出走。単勝2.3倍の1番人気に推された。レースがスタートすると、タイトルホルダーを先頭にそれを追う形で馬群中団のやや後方を追走。3コーナー手前の辺りで外めにつけて動き始め、4コーナーを回って持ったまま上昇。最後の直線に入ってムチを入れると加速していき、他馬の追随を許さず優勝。3歳馬の有馬記念制覇は前年のエフフォーリア以来2年連続、史上21頭目。3歳馬の天皇賞(秋)、有馬記念制覇は前年のエフフォーリア以来2年連続、史上3頭目。キャリア6戦での有馬記念制覇は史上最短。キタサンブラックとの父子制覇を達成した。なお、2着に菊花賞2着のボルドグフーシュが入り、3歳馬がワンツーフィニッシュを飾った。
query_engine経由だとインデックスの検索結果を元にLLMに生成させた回答が返ってくる。
query_engine = index.as_query_engine()
result = query_engine.query("有馬記念を勝ったのはなんという馬?")
print(result)
間違っとるやないかい。
スターズオンアース
retrieverやquery egineについては別の章でやるので割愛。
で作成したインタフェースはオンメモリ上に保存されている。これをベクトルデータベースに保存する。ベクトルデータベースにQdrantを使った場合の例。
from llama_index import VectorStoreIndex, SimpleDirectoryReader, StorageContext
from llama_index.text_splitter import SentenceSplitter
from llama_index.embeddings import OpenAIEmbedding
from llama_index.ingestion import IngestionPipeline, IngestionCache
from llama_index.vector_stores.qdrant import QdrantVectorStore
import qdrant_client
client = qdrant_client.QdrantClient(location=":memory:")
vector_store = QdrantVectorStore(client=client, collection_name="test_store")
storage_context = StorageContext.from_defaults(
vector_store=vector_store
)
reader = SimpleDirectoryReader(input_dir="./data", recursive=True)
documents = reader.load_data()
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=400, chunk_overlap=50),
OpenAIEmbedding(),
]
)
nodes = pipeline.run(documents=documents)
index = VectorStoreIndex(nodes, storage_context=storage_context)
上記の例では、Storage Contextを使っている。Service Contextと似たような位置付けで、こちらはベクトルインデックスだけでなく、他のオブジェクトも含めて保存に特化したコンテキストみたい。
これ以外にも、
- Ingestion Pipelineでvector_storeを設定する
- Storage Contextを使ってベクトルストアを定義して、from_documentsでそのStorage Contextを使う
などのやり方がある。
このあたりも別の賞でやるので割愛。
VectorStoreIndex以外にもいろいろなインデックスがある。以下にそれぞれの図がまとまっていてイメージはしやすい。
例えば、VectorStoreIndexは以下のようなイメージ。
© 2023 Jerry Liu. LlamaIndex is released under the MIT license
これ以外のインデックスを少し見てみる。
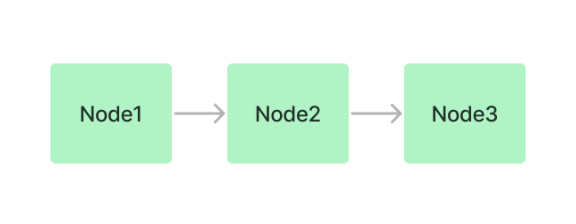
SummaryIndex
SummaryIndexは以前はListIndexという名称で、ノードをシーケンシャルなチェーンとして保持する。
© 2023 Jerry Liu. LlamaIndex is released under the MIT license
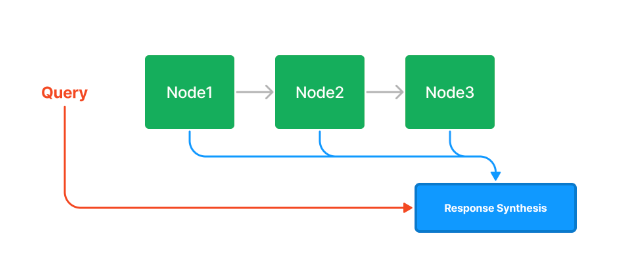
クエリ時には全てのノードを読み込んでレスポンス生成モジュールにわたす。
© 2023 Jerry Liu. LlamaIndex is released under the MIT license
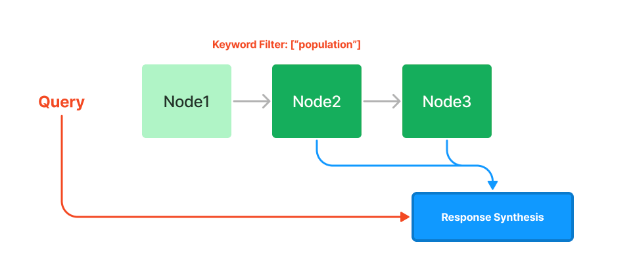
また、キーワードでフィルタしたり、embeddingsを使ったtop-k近似検索もできる。
© 2023 Jerry Liu. LlamaIndex is released under the MIT license
サンプルはこんな感じ。処理の流れを見るためにDEBUGログを有効化している
import logging
import sys
from llama_index import SimpleDirectoryReader, SummaryIndex
from llama_index.text_splitter import SentenceSplitter
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG, force=True)
reader = SimpleDirectoryReader(input_dir="./data", recursive=True)
documents = reader.load_data()
index = SummaryIndex.from_documents(documents)
チャンク分割されているのがわかる。
DEBUG:llama_index.readers.file.base:> [SimpleDirectoryReader] Total files added: 2
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。
202...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: == 戦績 ==
=== 2歳(2021年) ===
デビュー前に木村の自厩舎所属騎手に対...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: でもダービーはビッグチャンスだと思う」と振り返った。
続いて、5月29日に行われた東京優駿(日...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 改めてこれからもGI取れると思います」とコメントした。
...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 本馬にとっては初の海外戦となる。後日ドバイシーマクラシックの招待を受け、これを受諾。正式に出走...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 宝塚記念のファン投票は5月18日に始まり、その直後から多数の票を集め、第1回、第2回中間発表で...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: ジャックドールによる前半1000m通過57秒7という数字は、前年(2022年)のパンサラッサの...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: この秋はイクイノックスのピークに持っていけると思う」とさらに強くなる可能性があるとした。
天皇...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 前半1000mを57秒6で通過する大逃げを図ったパンサラッサを追う形で3番手から追走。慌てるこ...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 鞍上のルメールはレース後のインタビューで「この馬の走りは信じられません。ペースが速かったけど、...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 引退後は社台スタリオンステーションで種牡馬として供用される。
同年12月16日の中山競馬終了後...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: イクイノックスの引退が発表された11月30日に、JRAはジャパンカップにおけるイクイノックスの...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: == 競走成績 ==
以下の内容は、JBISサーチ、netkeiba.com、エミレーツ競馬協...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: == 血統表 ==
母シャトーブランシュは2015年のマーメイドステークスの勝ち馬。
父の父ブ...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 単勝オッズ2.2倍の1番人気に推された。道中は勝ち馬アスクビクターモアを見る形で追走。残り80...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 6月10日に国際競馬統括機関連盟が発表した「ロンジンワールドベストレースホースランキング」にお...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: しかし出馬投票後の同月24日、調教後に左前肢跛行を発症しドバイターフへの出走を取り消した。友道...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 馬番5番での優勝は、1970年のスピードシンボリ、1972年のイシノヒカルに次いで、51年ぶり...
ではクエリ。
query_engine = index.as_query_engine()
result = query_engine.query("有馬記念を勝利したのはなんという馬?")
print(result)
回答
ドウデュース
実際に行われているクエリはこんな感じ。
System: You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like 'Based on the context, ...' or 'The context information ...' or anything along those lines.
User: Context information is below.
---------------------
file_path: data/イクイノックス.txt
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。
(snip)
file_path: data/イクイノックス.txt
== 戦績 ==
=== 2歳(2021年) ===
デビュー前に木村の自厩舎所属騎手に対するパワーハラスメントの一件で略式命令を受けたため、JRAから調教停止処分を受けた事に伴い、2021年7月29日から10月31日まで岩戸孝樹厩舎に一時転厩している。従って後述の新馬戦は岩戸厩舎所属馬としてデビューしている。
(snip)
file_path: data/イクイノックス.txt
でもダービーはビッグチャンスだと思う」と振り返った。
(snip)
file_path: data/イクイノックス.txt
改めてこれからもGI取れると思います」とコメントした。
(snip)
---------------------
Given the context information and not prior knowledge, answer the query.
Query: 有馬記念を勝利したのはなんという馬?
Answer:
User: You are an expert Q&A system that strictly operates in two modes when refining existing answers:
1. **Rewrite** an original answer using the new context.
2. **Repeat** the original answer if the new context isn't useful.
Never reference the original answer or context directly in your answer.
When in doubt, just repeat the original answer.
New Context: data/イクイノックス.txt
本馬にとっては初の海外戦となる。後日ドバイシーマクラシックの招待を受け、これを受諾。正式に出走することとなった。鞍上は主戦騎手であるクリストフ・ルメールが引き続き務める。
(snip)
file_path: data/イクイノックス.txt
宝塚記念のファン投票は5月18日に始まり、その直後から多数の票を集め、第1回、第2回中間発表で最多の票数を獲得し、最終発表ではファン投票が始まって以来歴代最多となる216,379票を獲得しファン投票1位の座を勝ち取った。
(snip)
file_path: data/イクイノックス.txt
ジャックドールによる前半1000m通過57秒7という数字は、前年(2022年)のパンサラッサの大逃げによる同57秒4とコンマ3秒しか違わず、前年度と同じように全体的にタフな流れであった。(snip)
Query: 有馬記念を勝利したのはなんという馬?
Original Answer: イクイノックス
New Answer:
User: You are an expert Q&A system that strictly operates in two modes when refining existing answers:
1. **Rewrite** an original answer using the new context.
2. **Repeat** the original answer if the new context isn't useful.
Never reference the original answer or context directly in your answer.
When in doubt, just repeat the original answer.
New Context: data/イクイノックス.txt
この秋はイクイノックスのピークに持っていけると思う」とさらに強くなる可能性があるとした。(snip)
file_path: data/イクイノックス.txt
前半1000mを57秒6で通過する大逃げを図ったパンサラッサを追う形で3番手から追走。慌てることなく前を追いかけ、坂の途中で先頭に立つと、2着の三冠牝馬リバティアイランドに4馬身差をつけて完勝。(snip)
file_path: data/イクイノックス.txt
鞍上のルメールはレース後のインタビューで「この馬の走りは信じられません。ペースが速かったけど、直線はすぐに反応して、自分でもびっくりした。アクセレーション(加速)がすごかったです。(snip)
file_path: data/イクイノックス.txt
引退後は社台スタリオンステーションで種牡馬として供用される。(snip)
Query: 有馬記念を勝利したのはなんという馬?
Original Answer: イクイノックス
New Answer:
User: You are an expert Q&A system that strictly operates in two modes when refining existing answers:
1. **Rewrite** an original answer using the new context.
2. **Repeat** the original answer if the new context isn't useful.
Never reference the original answer or context directly in your answer.
When in doubt, just repeat the original answer.
New Context: 種牡馬時代 ==
file_path: data/イクイノックス.txt
イクイノックスの引退が発表された11月30日に、JRAはジャパンカップにおけるイクイノックスのレーティングを133ポンドと発表した。(snip)
file_path: data/イクイノックス.txt
== 競走成績 ==
以下の内容は、JBISサーチ、netkeiba.com、エミレーツ競馬協会およびTotal Performance Dataの情報に基づく。(snip)
file_path: data/イクイノックス.txt
== 血統表 ==
母シャトーブランシュは2015年のマーメイドステークスの勝ち馬。(snip)
file_path: data/ドウデュース.txt
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。(snip)
file_path: data/ドウデュース.txt
単勝オッズ2.2倍の1番人気に推された。道中は勝ち馬アスクビクターモアを見る形で追走。残り800メートル過ぎに後方からロジハービンが一気に進出したため、いったんポジションを下げる。(snip)
Query: 有馬記念を勝利したのはなんという馬?
Original Answer: イクイノックス
New Answer:
最初にQAテンプレート、その後はRefineテンプレートを繰り返して、nodeを順番に全部読んで都度回答が正しいかを確認していくという形っぽい。なるほど、シーケンシャルというのはこういうことか。
所感
- 全部のNodeを渡すというのは検索精度の問題で漏れてしまうというのを避けれるというメリットが有りそう。
- その代わりLLMへの問い合わせ回数は多くなりそうだし、最終的なレスポンス時間も長くなりそう。
- プロンプトで指示しているとはいえ、最初と最後では、最後のほうが重要になりそう。つまり、コンテキストの並び順にも影響されそう。
Tree Index
Tree IndexはNodeの関係性から階層構造を作る。いわゆるNodeは末端部分で、親となるNodeは複数のNodeのサマリーとなるらしい。なのでトップレベルのNodeは(階層構造が2段階以上になれば)サマリーのサマリーという形になる。
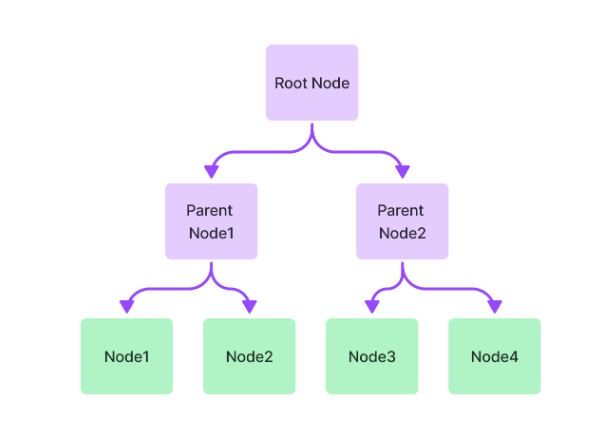
© 2023 Jerry Liu. LlamaIndex is released under the MIT license
クエリ時は、ルートNodeから末端に向かって辿っていく。デフォルトでは親から辿られる子Nodeは1つだけどもchild_branch_factorで各階層レベルごとに辿るべき子Nodeのカズを設定できる。
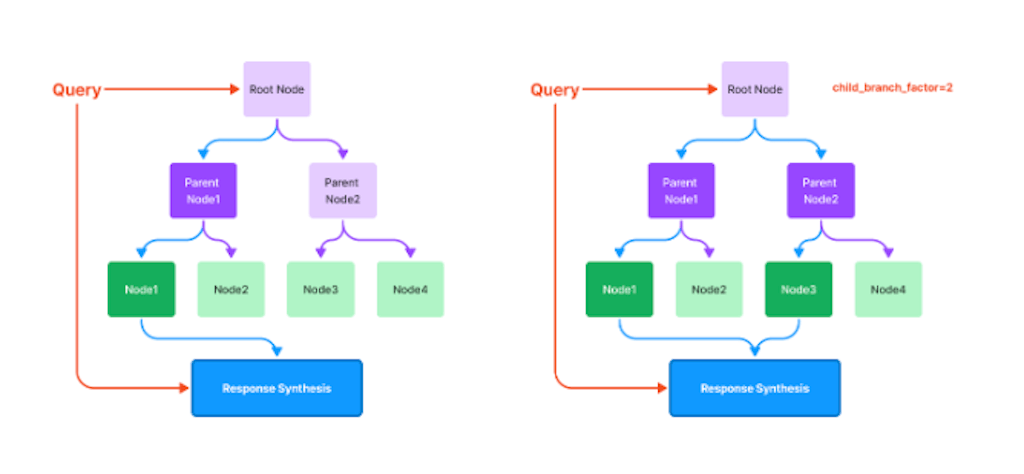
© 2023 Jerry Liu. LlamaIndex is released under the MIT license
親子Nodeの関係性が作られる&親Nodeはサマリとなる、という動きを確認するために、今回は低レベルAPIでNodeを作ってからインデックスを作成してみた。
import logging
import sys
from llama_index import SimpleDirectoryReader, TreeIndex
from llama_index.text_splitter import SentenceSplitter
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG, force=True)
reader = SimpleDirectoryReader(input_dir="./data", recursive=True)
documents = reader.load_data()
node_parser = SentenceSplitter(chunk_size=400, chunk_overlap=50)
nodes = node_parser.get_nodes_from_documents(
documents, show_progress=True
)
index = TreeIndex(nodes)
ログを見てみる
まず最初にDocumentが全部Nodeに分割される。
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。
202...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: == 血統・デビュー前 ==
キタサンブラックの初年度産駒である。GIを7勝し、演歌歌手・北島...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: == 戦績 ==
=== 2歳(2021年) ===
デビュー前に木村の自厩舎所属騎手に対...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 本馬が見せた末脚は、長距離向きと見ていたノーザンファームの桑田を驚かせた。
木村厩舎に戻って初...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: レースでは大外枠から中団につけ、勝負どころで好位の3番手につけ最後の直線へ。抜群の手応えで一度...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 鞍上のルメールは「直線は勝ち馬をマークして外に出して追いだしたら、(相手が)伸び返す形になって...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: GI初勝利を飾った。天皇賞(秋)の3歳馬の勝利は前年のエフフォーリア以来2年連続、史上5頭目。...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 688票を集め3位となった。
12月25日、予定通り有馬記念に出走。単勝2.3倍の1番人気に...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: これは1994年ナリタブライアン(1着)→ヒシアマゾン(2着)以来28年ぶりで、1984年以降...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 本馬にとっては初の海外戦となる。後日ドバイシーマクラシックの招待を受け、これを受諾。正式に出走...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: また、キタサンブラック産駒は海外GI初制覇を達成した。レースの後にルメールは「彼が最高な馬なの...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 次走として宝塚記念に出走すると表明した。鞍上は引き続きクリストフ・ルメールが務める。秋は外国遠...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 父のキタサンブラックは現役時代に宝塚記念を勝利することがなかったが、産駒である本馬がリベンジを...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 10月29日、予定通り天皇賞(秋)に出走。好スタートを切ると前半1000mを57秒7で逃げるジ...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: イクイノックスが直線半ばで先頭に立ったのと対照的に、直後にいたドウデュース(7着)やヒシイグア...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: また走破タイム1分55秒2は、1999年にクリスタルハウスがチリで記録した1分55秒4を上回り...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: さらに、ドバイシーマクラシックの分(約4億6000万円)も含めると総獲得賞金は17億1158万...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 前半57秒7で行って後半は57秒5でしょ。ありえないですよ。常識から外れています」と驚愕してい...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 前半1000mを57秒6で通過する大逃げを図ったパンサラッサを追う形で3番手から追走。慌てるこ...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: ジャパンカップの親子制覇は史上7度目である。天皇賞(秋)・ジャパンカップを連勝するのは史上5頭...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: そのほかにも、3着に5番人気のスターズオンアースが入ったため、3連単のオッズが11.3倍となっ...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: アクセレーション(加速)がすごかったです。1番枠にリバティアイランドがいての2番枠。タイトルホ...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: イクイノックスの今後について、同馬を所有するシルクレーシングの米本昌史代表は「まずは馬の様子を...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 米本代表によれば、秋の天皇賞、ジャパンカップの連戦の疲労もあり、有馬記念を中3週で万全の態勢で...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: 初年度種付料は2000万円に設定され、ノーザンファーム代表の吉田勝己によれば、GI競走9勝を挙...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: また、日本調教馬としても、1999年に凱旋門賞2着で134ポンドを与えられたエルコンドルパサー...
DEBUG:llama_index.node_parser.node_utils:> Adding chunk: == 種牡馬時代 ==
(snip)
その後、複数のチャンクからサマリーが作成される
User: Write a summary of the following. Try to use only the information provided. Try to include as many key details as possible.
file_path: data/イクイノックス.txt
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。(snip)
file_path: data/イクイノックス.txt
== 血統・デビュー前 ==
キタサンブラックの初年度産駒である。(snip)
file_path: data/イクイノックス.txt
== 戦績 ==(snip)
file_path: data/イクイノックス.txt
本馬が見せた末脚は、長距離向きと見ていたノーザンファームの桑田を驚かせた。(snip)
file_path: data/イクイノックス.txt
レースでは大外枠から中団につけ、勝負どころで好位の3番手につけ最後の直線へ。抜群の手応えで一度は他馬を突き放したが、最後は外から同厩舎のジオグリフに差され2着に敗れた。(snip)
file_path: data/イクイノックス.txt
鞍上のルメールは「直線は勝ち馬をマークして外に出して追いだしたら、(相手が)伸び返す形になってしまったかな」と振り返った。(snip)
(snip)
SUMMARY:
最終的には以下のようなサマリーがそれぞれ作成されているのがわかる。
DEBUG:llama_index.indices.common_tree.base:> 0/10, summary: イクイノックス is a Japanese racehorse who was born on...
DEBUG:llama_index.indices.common_tree.base:> 10/10, summary: The file "イクイノックス.txt" contains information abo...
DEBUG:llama_index.indices.common_tree.base:> 20/10, summary: The horse named イクイノックス won the 2023 Japan Cup,...
DEBUG:llama_index.indices.common_tree.base:> 30/10, summary: The file path is "data/イクイノックス.txt". The horse ...
DEBUG:llama_index.indices.common_tree.base:> 40/2, summary: The file path is data/ドウデュース.txt. The horse num...
このノードの関係やそれぞれのノードがドノようなテキストを持っているかを確認したいなと思ってたらここにまとまってた
テキストを見たいので少しいじってみた
for k,v in index.docstore.docs.items():
node = v
document_id = k
# 子ノードのdoc_idを取得
children_doc_ids = index.index_struct.get_children(node)
# 末端(リーフノード)は飛ばす
if len(children_doc_ids) == 0:
continue
print(f"parent_doc_id: {document_id}\ntext: {node.text}")
# 子ノードの情報を取得
for node_num, children_doc_id in children_doc_ids.items():
# ノード情報の取得
children_node = index.docstore.get_node(children_doc_id)
children_node_text = children_node.text.replace("\n","")[:50] + "..."
# ファイル名のメタ情報を取得
file_name = children_node.metadata.get("file_name")
print("\t" + f"child_doc_id: {children_doc_id}\n\ttext: {children_node_text}\n\tsource: [{file_name}]")
parent_doc_id: 41d61ebd-cfdd-468b-8199-87280326763f
text: イクイノックス is a Japanese racehorse who was born on March 23, 2019. In 2022, he became the first GI champion as a progeny of Kita-San Black, and in 2023, he achieved victory in the Autumn-Spring Grand Prix. His name means "the time when the length of day and night is almost equal." He was awarded the JRA Award for Horse of the Year and Best 3-Year-Old Colt in 2022. His notable victories include consecutive wins in the Emperor's Cup (Autumn) in 2022 and 2023, (snip)
child_doc_id: 4d68ecef-beb5-443d-bf35-36d0e9dcb92a
text: イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。2022年にキ...
source: [イクイノックス.txt]
child_doc_id: 2a9f66e4-135a-42c3-ad7f-6ffcab179041
text: == 血統・デビュー前 ==キタサンブラックの初年度産駒である。GIを7勝し、演歌歌手・北島三郎が実...
source: [イクイノックス.txt]
child_doc_id: 4e0524b0-3278-46e8-abd2-3552facd4f6f
text: == 戦績 ===== 2歳(2021年) ===デビュー前に木村の自厩舎所属騎手に対するパワーハラ...
source: [イクイノックス.txt]
child_doc_id: aababd5a-d76a-4d16-a187-901ae8b35cb7
text: 本馬が見せた末脚は、長距離向きと見ていたノーザンファームの桑田を驚かせた。木村厩舎に戻って初戦となる...
source: [イクイノックス.txt]
child_doc_id: 0d671fb6-5c5c-40a5-9e15-e20f4ce09101
text: レースでは大外枠から中団につけ、勝負どころで好位の3番手につけ最後の直線へ。抜群の手応えで一度は他馬...
source: [イクイノックス.txt]
child_doc_id: 1db1c0cf-ce83-4be1-89ef-48b79a5e1aeb
text: 鞍上のルメールは「直線は勝ち馬をマークして外に出して追いだしたら、(相手が)伸び返す形になってしまっ...
source: [イクイノックス.txt]
child_doc_id: dc0445fa-3a7e-4fe2-b6fd-6e81881d41fc
text: GI初勝利を飾った。天皇賞(秋)の3歳馬の勝利は前年のエフフォーリア以来2年連続、史上5頭目。キャリ...
source: [イクイノックス.txt]
child_doc_id: 918b3ca8-6733-430b-8c2b-7cf0f5a255b0
text: 688票を集め3位となった。12月25日、予定通り有馬記念に出走。単勝2.3倍の1番人気に推された。...
source: [イクイノックス.txt]
child_doc_id: 86bdace6-01be-4c25-9453-214e9b5d182d
text: これは1994年ナリタブライアン(1着)→ヒシアマゾン(2着)以来28年ぶりで、1984年以降では2...
source: [イクイノックス.txt]
child_doc_id: dbe3046e-1606-4970-8f34-4eaab8a75a76
text: 本馬にとっては初の海外戦となる。後日ドバイシーマクラシックの招待を受け、これを受諾。正式に出走するこ...
source: [イクイノックス.txt]
parent_doc_id: 7f981040-f598-461f-b040-43edc36b2692
text: The file "イクイノックス.txt" contains information about the racehorse named イクイノックス. The horse is a progeny of the famous racehorse キタサンブラック and achieved its first overseas Group 1 victory. The jockey, クリストフ・ルメール, expressed his gratitude to イクイノックス for giving him the opportunity to win the race. イクイノックス was ranked first in the Longines World's Best Racehorse Rankings with a rating of 129 pounds. This made it the third Japanese-trained horse to achieve this feat. イクイノックス announced that it would participate in the 宝塚記念 and the ジャパンカップ as its next races.(snip)
child_doc_id: b4df9908-b4d7-43d7-9412-0bbd7f25300a
text: また、キタサンブラック産駒は海外GI初制覇を達成した。レースの後にルメールは「彼が最高な馬なのは知っ...
source: [イクイノックス.txt]
child_doc_id: 41a269c8-cc7e-44df-9f6f-ea46c2449ca6
text: 次走として宝塚記念に出走すると表明した。鞍上は引き続きクリストフ・ルメールが務める。秋は外国遠征のプ...
source: [イクイノックス.txt]
child_doc_id: 8c292941-42b2-4538-9a6b-e9e60007fb15
text: 父のキタサンブラックは現役時代に宝塚記念を勝利することがなかったが、産駒である本馬がリベンジを果たす...
source: [イクイノックス.txt]
child_doc_id: 61fb1baa-dd43-4083-83a7-fcb1106f6a28
text: 10月29日、予定通り天皇賞(秋)に出走。好スタートを切ると前半1000mを57秒7で逃げるジャック...
source: [イクイノックス.txt]
child_doc_id: 457de7ab-b907-423b-b1da-22a6c01c9ff9
text: イクイノックスが直線半ばで先頭に立ったのと対照的に、直後にいたドウデュース(7着)やヒシイグアス(9...
source: [イクイノックス.txt]
child_doc_id: 32c98c09-448f-4dcc-9ff6-df70edeafafb
text: また走破タイム1分55秒2は、1999年にクリスタルハウスがチリで記録した1分55秒4を上回り、広く...
source: [イクイノックス.txt]
child_doc_id: 18db3747-b4b7-4c75-88f5-5323f2a05386
text: さらに、ドバイシーマクラシックの分(約4億6000万円)も含めると総獲得賞金は17億1158万210...
source: [イクイノックス.txt]
child_doc_id: 5aee09bd-0f50-47b9-bfb7-c84bcfbd924f
text: 前半57秒7で行って後半は57秒5でしょ。ありえないですよ。常識から外れています」と驚愕している。元...
source: [イクイノックス.txt]
child_doc_id: 4e97e827-4fe8-4bcf-9257-1b5acfd591a4
text: 前半1000mを57秒6で通過する大逃げを図ったパンサラッサを追う形で3番手から追走。慌てることなく...
source: [イクイノックス.txt]
child_doc_id: 2e948fb3-5ab9-41c8-a395-af2b66584d67
text: ジャパンカップの親子制覇は史上7度目である。天皇賞(秋)・ジャパンカップを連勝するのは史上5頭目で、...
source: [イクイノックス.txt]
parent_doc_id: 09db473d-d077-4f88-84b6-a97e7573b117
text: The horse named イクイノックス won the 2023 Japan Cup, setting a record for the lowest payout in the history of JRA-GI races. The jockey, Christophe Lemaire, was surprised by the horse's acceleration and described it as a "super horse." The owner, Silk Racing, mentioned that they will consider the horse's future plans, including the possibility of participating in the Arima Kinen. However, it was later announced that イクイノックス would retire after the Japan Cup and become a stallion at Shadai Stallion Station. (snip)
child_doc_id: 882b4f6d-1dfb-457f-8228-b158ddb56e53
text: そのほかにも、3着に5番人気のスターズオンアースが入ったため、3連単のオッズが11.3倍となったのは...
source: [イクイノックス.txt]
child_doc_id: 807be298-f204-400b-87f3-fa4f2cf0e59d
text: アクセレーション(加速)がすごかったです。1番枠にリバティアイランドがいての2番枠。タイトルホルダー...
source: [イクイノックス.txt]
child_doc_id: b5590ba3-283c-41f7-91e0-ffd07493344f
text: イクイノックスの今後について、同馬を所有するシルクレーシングの米本昌史代表は「まずは馬の様子を見て無...
source: [イクイノックス.txt]
child_doc_id: 65d3d1b8-d94d-42d0-809c-d718e0b31ff4
text: 米本代表によれば、秋の天皇賞、ジャパンカップの連戦の疲労もあり、有馬記念を中3週で万全の態勢での出走...
source: [イクイノックス.txt]
child_doc_id: f23bfc15-bef8-4514-866a-f579d26ce840
text: 初年度種付料は2000万円に設定され、ノーザンファーム代表の吉田勝己によれば、GI競走9勝を挙げたア...
source: [イクイノックス.txt]
child_doc_id: 070e98dc-a9a9-4f33-97a1-1223c2182ff8
text: また、日本調教馬としても、1999年に凱旋門賞2着で134ポンドを与えられたエルコンドルパサーに次ぐ...
source: [イクイノックス.txt]
child_doc_id: 61a02e23-46e0-4bb3-8d49-2e7ceb5ee869
text: == 種牡馬時代 ===== 供用 ===競走馬引退後は、北海道安平町の社台スタリオンステーションに...
source: [イクイノックス.txt]
child_doc_id: 8eb35df1-32fa-4753-818f-a5e9d9d0b242
text: == 競走成績 ==以下の内容は、JBISサーチ、netkeiba.com、エミレーツ競馬協会および...
source: [イクイノックス.txt]
child_doc_id: f8629fa2-ada9-455a-9d01-8436ebf6f36c
text: 調教師として、いつかあんな馬に巡り合いたいと思う、偉大な馬です」と賛辞した。社台スタリオンステーショ...
source: [イクイノックス.txt]
child_doc_id: 6c5ba1a5-1456-40c1-aebf-24cf235444a7
text: 様々な血脈をバランス良く織り重ねたような構成で、全てを良いとこ取りしたような馬なのだと思います」と答...
source: [イクイノックス.txt]
parent_doc_id: eea4c74c-e0d4-4bb0-86c6-4ae8d1a9226e
text: The file path is "data/イクイノックス.txt". The horse named イクイノックス is being praised for standing out. The horse's pedigree includes a mother named シャトーブランシュ who won the 2015 Mermaid Stakes and a father's father named ブラックタイド who is the full brother of the 2005 Triple Crown winner ディープインパクト. The horse has a half-brother named ヴァイスメテオール who won the ラジオNIKKEI賞 and a relative named ブランディス who won the 中山大障害 and 中山グランドジャンプ.
child_doc_id: 7a365625-6ed6-4084-aba8-ff8238b7458b
text: この3頭が際立っている」と賞賛している。== 血統表 ==母シャトーブランシュは2015年のマーメイ...
source: [イクイノックス.txt]
child_doc_id: 66d9e15b-df11-4b51-85a2-51b77fe11d19
text: ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍は20...
source: [ドウデュース.txt]
child_doc_id: f12cfc1f-f591-40e8-9ca8-a1d5508fa55c
text: 1番人気に推されると、レースは直線でガイアフォースとの追い比べをクビ差制してデビュー勝ちを果たした。...
source: [ドウデュース.txt]
child_doc_id: 4c3c7c85-084d-43c6-8c40-105d93e8e2f7
text: また馬主である松島及びキーファーズにとっては初の単独所有馬によるGI勝利、並びに国内GI初制覇となっ...
source: [ドウデュース.txt]
child_doc_id: 2b3fd7f9-dc8f-4e19-9b30-cf4307cb1030
text: 1倍に次ぐ皐月賞1番人気の低支持率オッズであった。レースでは道中後方からじっくり運び、最後の直線は外...
source: [ドウデュース.txt]
child_doc_id: 3672cf47-5eed-406c-afce-e9b8915f5e7b
text: 鞍上の武は、歴代最多を更新する2013年のキズナ以来となるダービー6勝目、かつ歴代最年長、史上初の5...
source: [ドウデュース.txt]
child_doc_id: 2c11a5e1-681b-4f24-8626-559be90eecd0
text: 次走として凱旋門賞への出走を表明した。ドウデュースののんびりとした性格上、フランスへ赴いた場合に放牧...
source: [ドウデュース.txt]
child_doc_id: 2633dba9-3d74-43af-ac25-e0b3187e1a0e
text: まずまずのスタートを決めると、道中は馬群を見て最後方グループで待機し、向正面から外へ出て徐々に捲りを...
source: [ドウデュース.txt]
child_doc_id: a962b136-4407-432c-8de0-14f93d70572a
text: その後夏は治療と休養にあて、秋初戦として10月29日に東京競馬場で開催される天皇賞(秋)に出走。当日...
source: [ドウデュース.txt]
child_doc_id: b97c2970-76e5-4034-899f-c8deb9efe4c9
text: 2023年最終戦として有馬記念へ出走。鞍上には武豊が復帰した。鞍上横山和生と本レースがラストランとな...
source: [ドウデュース.txt]
parent_doc_id: 695a289c-da57-44fb-8a39-6f4a8d40e478
text: The file path is data/ドウデュース.txt. The horse number 5 won the race, marking the third victory in 51 years after Speed Symboli in 1970 and Ishino Hikaru in 1972. This is the ninth time a Derby horse has won the Arima Kinen in the past 10 years, and the fourth time in 30 years for a non-triple crown horse. The horse achieved a parent-child victory with its father, Hearts Cry, making it the sixth time in history.(snip)
child_doc_id: aaea6b38-d869-4b44-a725-b58dc7ba9f20
text: 馬番5番での優勝は、1970年のスピードシンボリ、1972年のイシノヒカルに次いで、51年ぶり3度目...
source: [ドウデュース.txt]
child_doc_id: 8ebbdf84-8bac-4645-b267-ea4a104073a4
text: == 血統表 ==母ダストアンドダイヤモンズはアメリカで重賞2勝を挙げ、2012年のGI・ブリーダー...
source: [ドウデュース.txt]
ではクエリしてみる。
query_engine = index.as_query_engine()
result = query_engine.query("有馬記念を勝利したのはなんという馬?")
print(result)
最初に親ノードのサマリが渡されて、どのサマリ=親ノードが最も質問に近いかとその理由を回答するように指示する。
User: Some choices are given below. It is provided in a numbered list (1 to 5), where each item in the list corresponds to a summary.
---------------------
(1) イクイノックス is a Japanese racehorse who was born on March 23, 2019. In 2022, he became the first GI champion as a progeny of Kita-San Black, and in 2023, he achieved victory in the Autumn-Spring Grand Prix. His name means "the time when the length of day and night is almost equal."(snip)
(2) The file "イクイノックス.txt" contains information about the racehorse named イクイノックス. The horse is a progeny of the famous racehorse キタサンブラック and achieved its first overseas Group 1 victory.(snip)
(snip)
(5) The file path is data/ドウデュース.txt. The horse number 5 won the race, marking the third victory in 51 years after Speed Symboli in 1970 and Ishino Hikaru in 1972. This is the ninth time a Derby horse has won the Arima Kinen in the past 10 years, and the fourth time in 30 years for a non-triple crown horse.(snip)
---------------------
Using only the choices above and not prior knowledge, return the choice that is most relevant to the question: \'有馬記念を勝利したのはなんという馬?\'
Provide choice in the following format: \'ANSWER: <number>\' and explain why this summary was selected in relation to the question.
LLMからの回答は以下
ANSWER: 3
Summary 3 mentions that イクイノックス won the 2023 Japan Cup, which is relevant to the question asking which horse won the 有馬記念.
回答された親Nodeから子ノードをリストアップし、最初と同様に、どの子ノードが最も質問に近いかとその理由を回答するように指示する。
User: Some choices are given below. It is provided in a numbered list (1 to 10), where each item in the list corresponds to a summary.
---------------------
(1) そのほかにも、3着に5番人気のスターズオンアースが入ったため、3連単のオッズが11.3倍となったのは、第40回を制したアーモンドアイと2着馬コントレイル、3着馬デアリングタクトの13.4倍を更新し、歴代JRA・GIにおける最低額配当となった他、イクイノックス、リバティアイランドのワイドのオッズが1.3倍となり、2000年の天皇賞(春)を制したテイエムオペラオーと2着馬ラスカルスズカ、3着馬ナリタトップロードなどと並び、ワイドの低額配当タイの記録となった。 (snip)
(2) アクセレーション(加速)がすごかったです。1番枠にリバティアイランドがいての2番枠。タイトルホルダーとパンサラッサの後ろにつけたかったけど、イクイノックスはいいスタートを切りました。後ろにつけて、そこから勝つ自信がありました。イメージ通りです。スーパーホースですね。(snip)
(snip)
(9) 調教師として、いつかあんな馬に巡り合いたいと思う、偉大な馬です」と賛辞した。 社台スタリオンステーションのスタッフは、netkeibaTVのインタビュー内にて「日本の馬産ならではの特徴が生んだ名馬なのだと考えています。(snip)
(10) 様々な血脈をバランス良く織り重ねたような構成で、全てを良いとこ取りしたような馬なのだと思います」と答えている。 イギリスのタイムフォーム社は、独自方式の「タイムフォームレーティング」にて、ジャパンカップにおけるイクイノックスを日本歴代首位のレーティング136と算定した。(snip)
---------------------
Using only the choices above and not prior knowledge, return the choice that is most relevant to the question: '有馬記念を勝利したのはなんという馬?'
Provide choice in the following format: 'ANSWER: <number>' and explain why this summary was selected in relation to the question.
LLMからの回答
ANSWER: 4
Summary (4) states that the horse, Ikuminokusu, has decided to retire after the Japan Cup and will not participate in the Arima Kinen. This information directly answers the question by stating that Ikuminokusu did not win the Arima Kinen.
それを元に最終回等を生成するように指示
SYSTEM: You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like 'Based on the context, ...' or 'The context information ...' or anything along those lines.
User: Context information is below.
---------------------
file_path: data/イクイノックス.txt
米本代表によれば、秋の天皇賞、ジャパンカップの連戦の疲労もあり、有馬記念を中3週で万全の態勢での出走が難しいとの判断に加え、社台スタリオンステーションから種牡馬入りのオファーがあったことも考慮し、引退・種牡馬入りを決定したと会見で公表している。引退後は社台スタリオンステーションで種牡馬として供用される。(snip)
---------------------
Given the context information and not prior knowledge, answer the query.
Query: 有馬記念を勝利したのはなんという馬?
Answer:
イクイノックス
所感
- SummaryIndexよりも処理回数は少なくて済む
- ただし親子関係がうまく辿れないとかサマリーが正しくないとかで辿れない場合もありそう。child_branch_factorを多少増やしたほうが良いかも。
- サマリーを使う時点である程度のコンテキストが失われるのは致し方ないところ。
Keyword Table Index
Keyword Table Indexは、事前にNodeからキーワードを抽出して紐づけておく。
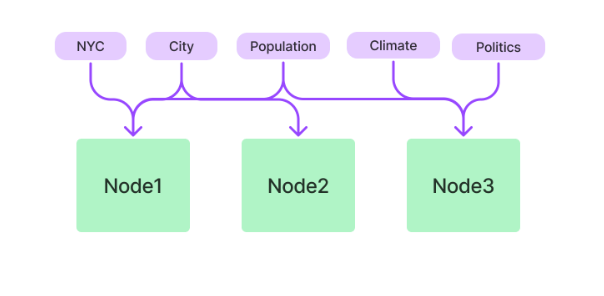
© 2023 Jerry Liu. LlamaIndex is released under the MIT license
クエリ時は、クエリから抽出したキーワードと元に該当するNodeを選択、そのNodeをもとにLLMの回答を生成する。
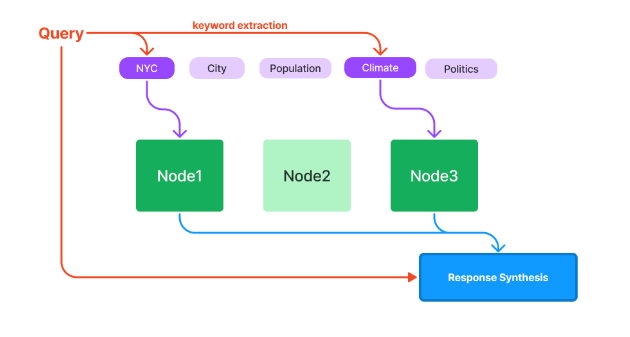
© 2023 Jerry Liu. LlamaIndex is released under the MIT license
import logging
import sys
from llama_index import SimpleDirectoryReader, KeywordTableIndex
from llama_index.text_splitter import SentenceSplitter
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG, force=True)
reader = SimpleDirectoryReader(input_dir="./data", recursive=True)
documents = reader.load_data()
node_parser = SentenceSplitter(chunk_size=400, chunk_overlap=50)
nodes = node_parser.get_nodes_from_documents(
documents, show_progress=True
)
index = KeywordTableIndex(nodes)
こんな感じで各Nodeごとにキーワードの抽出が指示される。
User: Some text is provided below. Given the text, extract up to 10 keywords from the text. Avoid stopwords.---------------------
file_path: data/イクイノックス.txt
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。
2022年にキタサンブラック産駒として初のGI制覇を果たし、2023年には秋春グランプリ制覇を達成した。馬名の意味は「昼と夜の長さがほぼ等しくなる時」。2022年度のJRA賞年度代表馬、最優秀3歳牡馬である。
主な勝ち鞍は2022年・2023年の天皇賞(秋)連覇、2022年の有馬記念、2023年のドバイシーマクラシック、宝塚記念、ジャパンカップ。
---------------------
Provide keywords in the following comma-separated format: 'KEYWORDS: <keywords>'
キーワードとドキュメントのマッピングテーブルは以下のようにして確認できた。
for k, doc_ids in index.index_struct.table.items():
print(f"Keyword: {k}\n\tDocuments:")
for doc_id in doc_ids:
print(f"\t\tdoc_id: {doc_id}")
print("\t\ttext: {}...".format(index.docstore.docs[doc_id].text.replace("\n","")[:50]))
Keyword: 秋春グランプリ制覇
Documents:
doc_id: 8825ec1a-1762-461c-898b-8bdbac2b9327
text: イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。2022年にキ...
doc_id: 926bc42a-8252-48bb-8b5c-9d07280147c9
text: 父のキタサンブラックは現役時代に宝塚記念を勝利することがなかったが、産駒である本馬がリベンジを果たす...
Keyword: 馬名
Documents:
doc_id: 8825ec1a-1762-461c-898b-8bdbac2b9327
text: イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。2022年にキ...
Keyword: キタサンブラック
Documents:
doc_id: ea9bf0fe-986a-45b2-a76c-c5c6f07c3dbd
text: == 血統・デビュー前 ==キタサンブラックの初年度産駒である。GIを7勝し、演歌歌手・北島三郎が実...
doc_id: fefdc028-03e3-4416-a154-6cab4e516b4d
text: 2023年最終戦として有馬記念へ出走。鞍上には武豊が復帰した。鞍上横山和生と本レースがラストランとな...
doc_id: 138c1892-fcff-4b8f-894e-da784d402975
text: 初年度種付料は2000万円に設定され、ノーザンファーム代表の吉田勝己によれば、GI競走9勝を挙げたア...
doc_id: 85f63993-5597-4491-b31e-1c28f1a0bda3
text: 688票を集め3位となった。12月25日、予定通り有馬記念に出走。単勝2.3倍の1番人気に推された。...
doc_id: 926bc42a-8252-48bb-8b5c-9d07280147c9
text: 父のキタサンブラックは現役時代に宝塚記念を勝利することがなかったが、産駒である本馬がリベンジを果たす...
doc_id: 8825ec1a-1762-461c-898b-8bdbac2b9327
text: イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。2022年にキ...
doc_id: 074d48cb-5cbe-4dc9-ab25-69cd9749da67
text: == 種牡馬時代 ===== 供用 ===競走馬引退後は、北海道安平町の社台スタリオンステーションに...
キーワードが抽出され、そこに複数のNodeが紐づいているのがわかる。
ではクエリ
query_engine = index.as_query_engine()
result = query_engine.query("有馬記念を勝利したのはなんという馬?")
print(result)
イクイノックス
ログを見てみる。
まず、クエリからキーワードが抽出される。
User: A question is provided below. Given the question, extract up to 10 keywords from the text. Focus on extracting the keywords that we can use to best lookup answers to the question. Avoid stopwords.
---------------------
有馬記念を勝利したのはなんという馬?
---------------------
Provide keywords in the following comma-separated format: 'KEYWORDS: <keywords>'
以下のキーワードが抽出された。
INFO:llama_index.indices.keyword_table.retrievers:query keywords: ['勝利', '有馬記念', '馬']
キーワードに紐づいたNodeが検索される。
DEBUG:llama_index.indices.keyword_table.retrievers:> Querying with idx: 67210e3d-dfdc-40b2-a098-328743b5401d: 様々な血脈をバランス良く織り重ねたような構成で、全てを良いとこ取りしたような馬なのだと思います...
DEBUG:llama_index.indices.keyword_table.retrievers:> Querying with idx: 1fae595b-4e78-4ff2-8a47-688a21d62d76: イクイノックスの今後について、同馬を所有するシルクレーシングの米本昌史代表は「まずは馬の様子を...
DEBUG:llama_index.indices.keyword_table.retrievers:> Querying with idx: 7d52e50f-71bb-4e67-b8bc-515d4b6ae5e8: == 血統表 ==
母ダストアンドダイヤモンズはアメリカで重賞2勝を挙げ、2012年のGI・ブ...
DEBUG:llama_index.indices.keyword_table.retrievers:> Querying with idx: 8e1658bd-a5f6-47c4-8c97-b3ea6fc4a950: 鞍上の武は、歴代最多を更新する2013年のキズナ以来となるダービー6勝目、かつ歴代最年長、史上...
DEBUG:llama_index.indices.keyword_table.retrievers:> Querying with idx: fefdc028-03e3-4416-a154-6cab4e516b4d: 2023年最終戦として有馬記念へ出走。鞍上には武豊が復帰した。
鞍上横山和生と本レースがラスト...
DEBUG:llama_index.indices.keyword_table.retrievers:> Querying with idx: 118024ff-4ecc-4b6f-abab-49e19d1dd8bf: 米本代表によれば、秋の天皇賞、ジャパンカップの連戦の疲労もあり、有馬記念を中3週で万全の態勢で...
DEBUG:llama_index.indices.keyword_table.retrievers:> Querying with idx: e82e270c-3d73-40ab-9dc3-46a3e834757e: GI初勝利を飾った。天皇賞(秋)の3歳馬の勝利は前年のエフフォーリア以来2年連続、史上5頭目。...
DEBUG:llama_index.indices.keyword_table.retrievers:> Querying with idx: 85f63993-5597-4491-b31e-1c28f1a0bda3: 688票を集め3位となった。
12月25日、予定通り有馬記念に出走。単勝2.3倍の1番人気に...
DEBUG:llama_index.indices.keyword_table.retrievers:> Querying with idx: 138c1892-fcff-4b8f-894e-da784d402975: 初年度種付料は2000万円に設定され、ノーザンファーム代表の吉田勝己によれば、GI競走9勝を挙...
DEBUG:llama_index.indices.keyword_table.retrievers:> Querying with idx: 1df49bcc-0d29-4ae2-a979-d62bbc0325fb: ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍...
上記を元にLLMに回答生成が指示される。
System: You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like 'Based on the context, ...' or 'The context information ...' or anything along those lines.
User: Context information is below.
---------------------
file_path: data/イクイノックス.txt
様々な血脈をバランス良く織り重ねたような構成で、全てを良いとこ取りしたような馬なのだと思います」と答えている。(snip)
file_path: data/イクイノックス.txt
イクイノックスの今後について、同馬を所有するシルクレーシングの米本昌史代表は「まずは馬の様子を見て無事を確認して。いろいろな評価をいただけると思うので、これから考えたい」とし、(snip)
file_path: data/ドウデュース.txt
== 血統表 ==
母ダストアンドダイヤモンズはアメリカで重賞2勝を挙げ、2012年のGI・ブリーダーズカップ・フィリー&メアスプリント2着の実績を持つ。(snip)
file_path: data/ドウデュース.txt
鞍上の武は、歴代最多を更新する2013年のキズナ以来となるダービー6勝目、かつ歴代最年長、史上初の50代でのダービージョッキーの名誉となった。(snip)
file_path: data/ドウデュース.txt
2023年最終戦として有馬記念へ出走。鞍上には武豊が復帰した。(snip)
file_path: data/イクイノックス.txt
米本代表によれば、秋の天皇賞、ジャパンカップの連戦の疲労もあり、有馬記念を中3週で万全の態勢での出走が難しいとの判断に加え、社台スタリオンステーションから種牡馬入りのオファーがあったことも考慮し、(snip)
file_path: data/イクイノックス.txt
GI初勝利を飾った。天皇賞(秋)の3歳馬の勝利は前年のエフフォーリア以来2年連続、史上5頭目。キャリア5戦での天皇賞(秋)制覇は史上最短、前年のホープフルステークスから続いていた平地GI競走の1番人気の連敗記録を16連敗で止めるなど、(snip)
(snip)
---------------------
Given the context information and not prior knowledge, answer the query.
Query: 有馬記念を勝利したのはなんという馬?
Answer:
所感
- キーワード全文検索っぽさがある、ということはセマンティックさが薄れることが予想される
- 反面、固有名詞などで拾える可能性は増えそう。形態素解析の辞書などにないキーワードでも拾えそうな気はする。
- 単体で使うのはちょっと厳しそうな気がする。定量的にやってないのでわからないけど。
あと今回は触れてないけども、クエリにはモードが3つあるらしい。
- default
- LLMでキーワードを抽出する
- キーワード抽出プロンプトは、クエリとNodeで同じものを使用する。
- simple
- キーワード抽出にLLMを使わずに正規表現を使う
- rake
- RAKEを使用してキーワード抽出を行う。これかな?
Knowledge Graph Index
ナレッジグラフを使ったインデックス。ナレッジグラフについては以下を参照。
とりあえず以下だけまずわかっておけば良さそう。


インデックス作成はこんな感じで。
import logging
import sys
from llama_index import SimpleDirectoryReader, KnowledgeGraphIndex, ServiceContext
from llama_index.text_splitter import SentenceSplitter
from llama_index.graph_stores import SimpleGraphStore
from llama_index.storage.storage_context import StorageContext
from llama_index.llms import OpenAI
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG, force=True)
reader = SimpleDirectoryReader(input_dir="./data", recursive=True)
documents = reader.load_data()
llm = OpenAI(temperature=0, model="gpt-3.5-turbo")
service_context = ServiceContext.from_defaults(llm=llm, chunk_size=512)
graph_store = SimpleGraphStore()
storage_context = StorageContext.from_defaults(graph_store=graph_store)
index = KnowledgeGraphIndex.from_documents(
documents,
max_triplets_per_chunk=2,
storage_context=storage_context,
service_context=service_context,
)
ログを見てみる。
こんな感じで、Nodeごとにトリプルを生成させている。
User: Some text is provided below. Given the text, extract up to 2 knowledge triplets in the form of (subject, predicate, object). Avoid stopwords.
---------------------
Example:Text: Alice is Bob's mother.Triplets:
(Alice, is mother of, Bob)
Text: Philz is a coffee shop founded in Berkeley in 1982.
Triplets:
(Philz, is, coffee shop)
(Philz, founded in, Berkeley)
(Philz, founded in, 1982)
---------------------
Text: file_path: data/イクイノックス.txt
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。
2022年にキタサンブラック産駒として初のGI制覇を果たし、2023年には秋春グランプリ制覇を達成した。馬名の意味は「昼と夜の長さがほぼ等しくなる時」。2022年度のJRA賞年度代表馬、最優秀3歳牡馬である。
主な勝ち鞍は2022年・2023年の天皇賞(秋)連覇、2022年の有馬記念、2023年のドバイシーマクラシック、宝塚記念、ジャパンカップ。
Triplets:
こういうトリプルが生成される。
DEBUG:llama_index.indices.knowledge_graph.base:> Extracted triplets: [
('イクイノックス', 'は', '日本の競走馬'),
('イクイノックス', '制覇を果たし', '2022年にキタサンブラック産駒として初のGI'),
('イクイノックス', '制覇を達成した', '2023年には秋春グランプリ'),
('イクイノックス', 'は', '馬名の意味'),
('イクイノックス', 'は', '2022年度のJRA賞年度代表馬'),
('イクイノックス', 'は', '最優秀3歳牡馬'),
('イクイノックス', 'は', '主な勝ち鞍'),
('イクイノックス', '連覇', '2022年・2023年の天皇賞(秋)'),
('イクイノックス', 'は', '2022年の有馬記念'),
('イクイノックス', 'は', '2023年のドバイシーマクラシック'),
('イクイノックス', 'は', '宝塚記念'),
('イクイノックス', 'は', 'ジャパンカップ')
]
上記に基づいて、どのようなグラフが生成されているかは以下のように確認できる。
!pip install pyvis
from pyvis.network import Network
from IPython.display import HTML
g = index.get_networkx_graph(limit=1000) # 全ノードを表示するためにlimitを上げた
net = Network(notebook=True, cdn_resources="in_line", directed=True, height='1000px') # Colaboratoryセル内で表示できる最大ぐらいまでheigthを広げた
net.from_nx(g)
net.save_graph("graph.html")
HTML(filename="graph.html")
こんな感じで表示される。
拡大するとこんな感じで、トリプルがどんどん広がっているのがわかる。
ではクエリを実行してみる。
query_engine = index.as_query_engine(
include_text=False, response_mode="tree_summarize"
)
response = query_engine.query(
"ドウデュースがイクイノックスに勝ったのはどのレース?",
)
print(response)
ドウデュースがイクイノックスに勝ったレースは日本ダービーです。
ログを見てみる。
まず最初にクエリからキーワードを抽出させている。
User: A question is provided below. Given the question, extract up to 10 keywords from the text. Focus on extracting the keywords that we can use to best lookup answers to the question. Avoid stopwords.
---------------------
ドウデュースがイクイノックスに勝ったのはどのレース?
---------------------
Provide keywords in the following comma-separated format: 'KEYWORDS: <keywords>'
「ドウデュース」「勝った」「レース」「イクイノックス」をキーワードとしてインデックスを検索、そこから紐づいているノードを辿っていると思われる。
DEBUG:llama_index.indices.knowledge_graph.retrievers:rel_map: {
'ドウデュース': [
['ドウデュース', 'は', '競走馬'],
['ドウデュース', '主な勝ち鞍は', '朝日杯フューチュリティステークス'],
['ドウデュース', '主な勝ち鞍は', '東京優駿'],
['東京優駿', '出走する', 'ダノンベルーガ'],
['東京優駿', '推される', '2番人気'],
['東京優駿', '進める', '後方3番手'],
['東京優駿', '追い込む', '上がり3ハロン33秒6'],
['東京優駿', '敗れる', '2着'],
['東京優駿', '出走', '5月29日'],
['ドウデュース', '主な勝ち鞍は', '有馬記念'],
['ドウデュース', '馬名の意味は', 'する+テニス用語'],
['ドウデュース', '馬名の意味は', '勝利目前の意味'],
['ドウデュース', 'は', 'JRA賞最優秀2歳牡馬'],
['ドウデュース', '誕生は', '北海道安平町のノーザンファーム'],
['ドウデュース', '所有馬となり', '株式会社キーファーズ'],
['ドウデュース', '育成の後', 'ノーザンファーム空港牧場'],
['ドウデュース', '入厩した', '栗東トレーニングセンターの友道康夫厩舎'],
['ドウデュース', '誕生', '2019年5月7日'],
['ドウデュース', '入厩した', '友道康夫厩舎'],
['ドウデュース', '勝利した', '日本ダービー'],
['ドウデュース', '位置づけられた', '第15位タイ'],
['ドウデュース', '勝利した', '日本ダービー'],
['ドウデュース', '出走する', '凱旋門賞']
]
}
DEBUG:llama_index.indices.knowledge_graph.retrievers:rel_map: {
'勝った': []
}
DEBUG:llama_index.indices.knowledge_graph.retrievers:rel_map: {
'レース': [
['レース', '優勝した', '2着に6馬身差をつけ'],
['レース', '終わった', '7着']
]
}
DEBUG:llama_index.indices.knowledge_graph.retrievers:rel_map: {
'イクイノックス': [
['イクイノックス', 'は', '日本の競走馬'],
['イクイノックス', '制覇を果たし', '2022年にキタサンブラック産駒として初のGI'],
['イクイノックス', '制覇を達成した', '2023年には秋春グランプリ'],
['イクイノックス', 'は', '馬名の意味'], ['イクイノックス', 'は', '2022年度のJRA賞年度代表馬'],
['イクイノックス', 'は', '最優秀3歳牡馬'],
['イクイノックス', 'は', '主な勝ち鞍'],
['イクイノックス', '連覇', '2022年・2023年の天皇賞(秋)'],
['イクイノックス', 'は', '2022年の有馬記念'],
['イクイノックス', 'は', '2023年のドバイシーマクラシック'],
['イクイノックス', 'は', '宝塚記念'],
['イクイノックス', 'は', 'ジャパンカップ'],
['ジャパンカップ', '出走する', '次走'],
['ジャパンカップ', 'おけるイクイノックスのレーティング', '133ポンド'],
['イクイノックス', '出走', '皐月賞'],
['皐月賞', '出走', 'ドウデュース'],
['イクイノックス', '出走', '東京優駿'],
['東京優駿', '出走する', 'ダノンベルーガ'],
['東京優駿', '推される', '2番人気'],
['東京優駿', '進める', '後方3番手'],
['東京優駿', '追い込む', '上がり3ハロン33秒6'],
['東京優駿', '敗れる', '2着'],
['東京優駿', '出走', '5月29日'],
['イクイノックス', 'は', '3歳馬の有馬記念制覇'],
['イクイノックス', 'は', '天皇賞(秋)と有馬記念の勝利と、年度代表馬に選出された功績が評価された'],
['イクイノックス', '評価された', '天皇賞(秋)と有馬記念の勝利と、年度代表馬に選出された功績'],
['イクイノックス', '位置付けられた', '第3位タイに'],
['イクイノックス', '出走することとなった', '正式に'],
['イクイノックス', '勝ち時計2:25.65は従来のレコードを1秒も縮めるレコードタイムであった', 'キタサンブラック産駒は海外GI初制覇を達成した'],
['イクイノックス', '逃げ切った', 'ドバイシーマクラシック']
]
}
この情報を元にLLMに回答を生成させている。
System: You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like 'Based on the context, ...' or 'The context information ...' or anything along those lines.
User: Context information from multiple sources is below.
---------------------
The following are knowledge sequence in max depth 2 in the form of directed graph like:
`subject -[predicate]->, object, <-[predicate_next_hop]-, object_next_hop ...`
['ドウデュース', 'は', '競走馬']
['ドウデュース', '主な勝ち鞍は', '朝日杯フューチュリティステークス']
['ドウデュース', '主な勝ち鞍は', '東京優駿']
['東京優駿', '出走する', 'ダノンベルーガ']
['東京優駿', '推される', '2番人気']
['東京優駿', '進める', '後方3番手']
['東京優駿', '追い込む', '上がり3ハロン33秒6']
['東京優駿', '敗れる', '2着']
['東京優駿', '出走', '5月29日']
['ドウデュース', '主な勝ち鞍は', '有馬記念']
['ドウデュース', '馬名の意味は', 'する+テニス用語']
['ドウデュース', '馬名の意味は', '勝利目前の意味']
['ドウデュース', 'は', 'JRA賞最優秀2歳牡馬']
['ドウデュース', '誕生は', '北海道安平町のノーザンファーム']
['ドウデュース', '所有馬となり', '株式会社キーファーズ']
['ドウデュース', '育成の後', 'ノーザンファーム空港牧場']
['ドウデュース', '入厩した', '栗東トレーニングセンターの友道康夫厩舎']
['ドウデュース', '誕生', '2019年5月7日']
['ドウデュース', '入厩した', '友道康夫厩舎']
['ドウデュース', '勝利した', '日本ダービー']
['ドウデュース', '位置づけられた', '第15位タイ']
['ドウデュース', '勝利した', '日本ダービー']
['ドウデュース', '出走する', '凱旋門賞']
['レース', '優勝した', '2着に6馬身差をつけ']
['レース', '終わった', '7着']
['イクイノックス', 'は', '日本の競走馬']
['イクイノックス', '制覇を果たし', '2022年にキタサンブラック産駒として初のGI']
['イクイノックス', '制覇を達成した', '2023年には秋春グランプリ']
['イクイノックス', 'は', '馬名の意味']
['イクイノックス', 'は', '2022年度のJRA賞年度代表馬']
['イクイノックス', 'は', '最優秀3歳牡馬']
['イクイノックス', 'は', '主な勝ち鞍']
['イクイノックス', '連覇', '2022年・2023年の天皇賞(秋)']
['イクイノックス', 'は', '2022年の有馬記念']
['イクイノックス', 'は', '2023年のドバイシーマクラシック']
['イクイノックス', 'は', '宝塚記念']
['イクイノックス', 'は', 'ジャパンカップ']
['ジャパンカップ', '出走する', '次走']
['ジャパンカップ', 'おけるイクイノックスのレーティング', '133ポンド']
['イクイノックス', '出走', '皐月賞']
['皐月賞', '出走', 'ドウデュース']
['イクイノックス', '出走', '東京優駿']
['東京優駿', '出走する', 'ダノンベルーガ']
['東京優駿', '推される', '2番人気']
['東京優駿', '進める', '後方3番手']
['東京優駿', '追い込む', '上がり3ハロン33秒6']
['東京優駿', '敗れる', '2着']
['東京優駿', '出走', '5月29日']
['イクイノックス', 'は', '3歳馬の有馬記念制覇']
['イクイノックス', 'は', '天皇賞(秋)と有馬記念の勝利と、年度代表馬に選出された功績が評価された']
['イクイノックス', '評価された', '天皇賞(秋)と有馬記念の勝利と、年度代表馬に選出された功績']
['イクイノックス', '位置付けられた', '第3位タイに']
['イクイノックス', '出走することとなった', '正式に']
['イクイノックス', '勝ち時計2:25.65は従来のレコードを1秒も縮めるレコードタイムであった', 'キタサンブラック産駒は海外GI初制覇を達成した']
['イクイノックス', '逃げ切った', 'ドバイシーマクラシック']
---------------------
Given the information from multiple sources and not prior knowledge, answer the query.
Query: ドウデュースがイクイノックスに勝ったのはどのレース?
Answer:
今回の例だとうまくいっているけども、実際に試してみた定性的な感じだとうまくいかないことのほうが多い印象がある。
query_engine = index.as_query_engine(
include_text=False, response_mode="tree_summarize"
)
response = query_engine.query(
"有馬記念を勝った馬の名前は?",
)
print(response)
I'm sorry, but based on the given context information, I cannot provide the name of the horse that won the Arima Kinen race.
ログを見ると、以下のキーワードで検索しているが、該当するNodeがないのだと思う。
DEBUG:llama_index.indices.knowledge_graph.retrievers:rel_map: {'有馬記念': []}
DEBUG:llama_index.indices.knowledge_graph.retrievers:rel_map: {'名前': []}
DEBUG:llama_index.indices.knowledge_graph.retrievers:rel_map: {'勝った馬': []}
indexの中身を見てみる。
keywords = ["有馬記念","名前","勝った馬"]
for k, doc_ids in index.index_struct.table.items():
if k in keywords:
print(f"Keyword: {k}\n\tDocuments:")
for doc_id in doc_ids:
print(f"\t\tdoc_id: {doc_id}")
print("\t\ttext: {}...".format(index.docstore.docs[doc_id].text.replace("\n","")))
Keyword: 有馬記念
Documents:
doc_id: 5b120c64-911f-4ec5-8d3c-7fa18c6781d6
text: ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。馬名の意味は「する+テニス用語(勝利目前の意味)」。2021年のJRA賞最優秀2歳牡馬である。== 戦績 ===== デビュー前 ===2019年5月7日、北海道安平町のノーザンファームで誕生。松島正昭が代表を務める株式会社キーファーズの所有馬となり、ノーザンファーム空港牧場で育成の後、栗東トレーニングセンターの友道康夫厩舎に入厩した。...
一応あるんだけどな。グラフ見てもこういうふうに辿ってほしいんだけど。
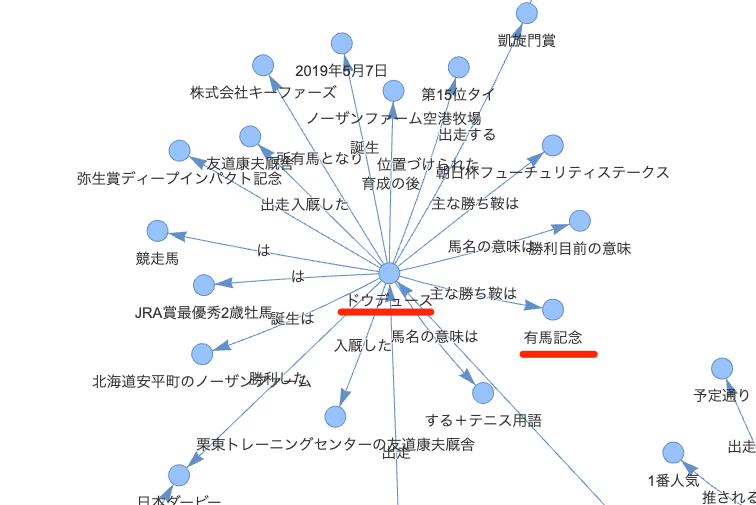
イクイノックスの方は「有馬記念」という完全一致のキーワードでノードがないようなのでたどり着けていないのだと思う。

こういう聞き方なら、答えてくれるので、ナレッジグラフの構成というか辿り方というかノードとなるキーワードが良くないのかもしれない。
query_engine = index.as_query_engine(
include_text=False, response_mode="tree_summarize"
)
response = query_engine.query(
"ドウデュースが勝ったGIレースを教えて",
)
print(response)
ドウデュースが勝ったGIレースは、朝日杯フューチュリティステークス、東京優駿、有馬記念です。
Embeddingsを使って検索させることもできるみたい。
import logging
import sys
from llama_index import SimpleDirectoryReader, KnowledgeGraphIndex, ServiceContext
from llama_index.text_splitter import SentenceSplitter
from llama_index.graph_stores import SimpleGraphStore
from llama_index.storage.storage_context import StorageContext
from llama_index.llms import OpenAI
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG, force=True)
reader = SimpleDirectoryReader(input_dir="./data", recursive=True)
documents = reader.load_data()
llm = OpenAI(temperature=0, model="gpt-3.5-turbo")
service_context = ServiceContext.from_defaults(llm=llm, chunk_size=512)
graph_store = SimpleGraphStore()
storage_context = StorageContext.from_defaults(graph_store=graph_store)
index = KnowledgeGraphIndex.from_documents(
documents,
max_triplets_per_chunk=2,
storage_context=storage_context,
service_context=service_context,
include_embeddings=True, # ここを追加
)
クエリ時はこんな感じ。
query_engine = index.as_query_engine(
include_text=True, # Trueに変更
response_mode="tree_summarize",
embedding_mode="hybrid", # 追加
similarity_top_k=5, # 追加
)
response = query_engine.query(
"有馬記念を勝った馬の名前は?",
)
print(response)
embedding_modeは以下の3つ。
- keyword: キーワードでトリプルを検索
- embedding: embeddingでトリプルを検索
- hybrid: keywordとembeddingのハイブリッドでトリプルを検索
回答はこうなった
イクイノックス
正しいのは正しいんだけど、ドウデュースの名前が出てこないのも微妙。ログを見てみる。
キーワードの抽出は上と同じ。これに加えてクエリのembeddiingを取得している様子。ということは、キーワードのembeddingでキーワードを検索するのではなくて、ノードのテキストを直接検索しにいってるのかな?
DEBUG:llama_index.indices.knowledge_graph.retrievers:rel_map: {'有馬記念': []}
DEBUG:llama_index.indices.knowledge_graph.retrievers:rel_map: {'名前': []}
DEBUG:llama_index.indices.knowledge_graph.retrievers:rel_map: {'勝った馬': []}
DEBUG:openai._base_client:Request options: {'method': 'post', 'url': '/embeddings', 'files': None, 'post_parser': <function Embeddings.create.<locals>.parser at 0x7a33fd2aa680>, 'json_data': {'input': ['有馬記念を勝った馬の名前は?'], 'model': <OpenAIEmbeddingModeModel.TEXT_EMBED_ADA_002: 'text-embedding-ada-002'>, 'encoding_format': 'base64'}}
LLMへの問い合わせを見る限り、どうもEmbeddingsでの検索はテキストを直接検索しているように見える。それに加えて、ナレッジグラフのキーワード検索も行われている様子。内容的には拾えてもよさそうなんだけどなー
System: You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like 'Based on the context, ...' or 'The context information ...' or anything along those lines."}, {'role': <MessageRole.USER: 'user'>, 'content': "Context information from multiple sources is below.
---------------------
file_path: data/ドウデュース.txt
さらに、ダービー馬による有馬記念制覇はオルフェーヴル以来10年ぶり9頭目で、三冠馬以外ではハクチカラ、ダイナガリバー、トウカイテイオーに次いで30年ぶり4頭目となったほか、父ハーツクライとの本競走親子制覇を達成した。本競走での親子制覇は史上6回目となった。(snip)
file_path: data/ドウデュース.txt
日本ダービーを勝利した馬が京都記念を勝利するのは、1948年春の京都記念のマツミドリ以来75年ぶりとなった。(snip)
file_path: data/ドウデュース.txt
勝ち馬のイクイノックスは本レースがラストランとなった。
2023年最終戦として有馬記念へ出走。鞍上には武豊が復帰した。
鞍上横山和生と本レースがラストランとなっており、レースを牽引して尚直線粘るタイトルホルダーと、二番手から先に仕掛けていた鞍上クリストフ・ルメールのスターズオンアースを抜き去り、先頭でゴール板を駆け抜けて見事復活の勝利を挙げた。武豊は2017年のキタサンブラック以来、6年ぶりの制覇となった。また、54歳9カ月10日での有馬記念勝利は最年長勝利記録であり、同時に自身が持つJRA・GI最年長勝利記録(54歳19日)を更新。ドリームジャーニーやオルフェーヴル、ブラストワンピースに騎乗し歴代最多の有馬記念4勝を挙げている池添謙一に並ぶ勝利数となった。馬番5番での優勝は、1970年のスピードシンボリ、1972年のイシノヒカルに次いで、51年ぶり3度目となった。
file_path: data/ドウデュース.txt
また、54歳9カ月10日での有馬記念勝利は最年長勝利記録であり、同時に自身が持つJRA・GI最年長勝利記録(54歳19日)を更新。(snip)
file_path: data/イクイノックス.txt
恐ろしい。下見所で見ていて馬がさらによくなっていると感じました。これ以上があるのか、と。前半57秒7で行って後半は57秒5でしょ。ありえないですよ。常識から外れています」と驚愕している。(snip)
The following are knowledge sequence in max depth 2 in the form of directed graph like:
`subject -[predicate]->, object, <-[predicate_next_hop]-, object_next_hop ...`
('有馬記念制覇', 'は', '三冠馬以外ではハクチカラ、ダイナガリバー、トウカイテイオーに次いで30年ぶり4頭目')
('武豊', '有馬記念勝利は', '最年長勝利記録である')
('有馬記念制覇', 'は', '10年ぶり9頭目')
('有馬記念勝利', 'は', '最年長勝利記録')
('馬', '勝利する', '京都記念')
---------------------
Given the information from multiple sources and not prior knowledge, answer the query.
Query: 有馬記念を勝った馬の名前は?
Answer:
所感
- ナレッジグラフでコンテキストの関係性が可視化できるのは良い
- が、検索でちゃんとたどり着けるのか?というところについては、たどり着けなかった場合も含めて、正直対応が難しい
- キーワードに依存してるので、ここでうまくキーワード化できないと厳しい感がある
- 試しにsimilarity_top_kを増やしたらむしろ取れなくなったりした(オルフェーブルが出てきた。間違ってはいないのだけども)
結構期待してたんだけどなー。文章の構造的に期待した結果になるかどうかというところは正直読めないところでもあるし、なんとなくだけどトリプルの構造的に、何が「起点」になるか=主語、をクエリに含めるような形じゃないとダメなのかなという気がした。難しい・・・
ナレッジグラフに関するドキュメントは他にもあるのでそちらに何かしらヒントがあるのかもしれない。
SQL Index
SQLデータベースをインデックスとして使う。果たしてデータベースをインデックスと言うのが正しいのかはわからんけど、データソースには違いない。
まずサンプルのデータベースとテーブルを作成する。sqlalchemyを使っている。
from sqlalchemy import (
create_engine,
MetaData,
Table,
Column,
String,
Integer,
select,
)
engine = create_engine("sqlite:///city_stats.sqlite") # ローカルファイル
metadata_obj = MetaData()
table_name = "city_stats"
city_stats_table = Table(
table_name,
metadata_obj,
Column("city_name", String(16), primary_key=True),
Column("population", Integer),
Column("country", String(16), nullable=False),
)
metadata_obj.create_all(engine)
でデータをINSERTするのだけども、ドキュメントではこんな感じで直接データを提議している。
rows = [
{"city_name": "Toronto", "population": 2930000, "country": "Canada"},
{"city_name": "Tokyo", "population": 13960000, "country": "Japan"},
{"city_name": "Chicago", "population": 2679000, "country": "United States"},
{"city_name": "Seoul", "population": 9776000, "country": "South Korea"},
]
for row in rows:
sql_statement = insert(city_stats_table).values(**row)
with engine.begin() as connection:
cursor = connection.execute(sql_statement)
せっかくなのでもっと多いデータでやりたいということで、Wikipediaの以下のページからデータを作る。
import pandas as pd
df = pd.read_html("https://en.wikipedia.org/wiki/List_of_largest_cities")[2]
df.columns = df.columns.droplevel(0)
first_population_col_index = df.columns.tolist().index('Population')
df = df.iloc[:, [df.columns.get_loc('City[a]'), first_population_col_index, df.columns.get_loc('Country')]]
df.rename(columns={"City[a]": "City"}, inplace=True)
df['Population'] = pd.to_numeric(df['Population'], errors='coerce')
df.dropna(inplace=True)
df['Population'] = df['Population'].astype(int)
df
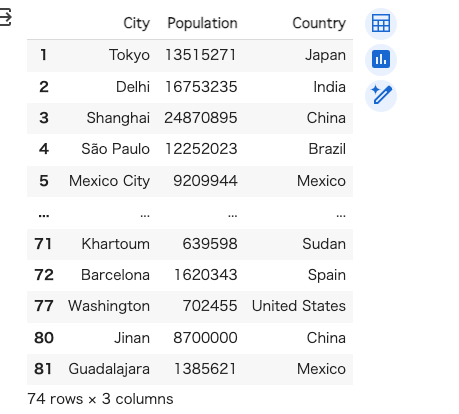
上記のデータフレームのデータをデータベースに追加する。
df.to_sql('city_stats', con=engine, if_exists='replace', index=False)
確認
sql_statement = select(city_stats_table)
with engine.connect() as connection:
results = connection.execute(sql_statement).fetchall()
for row in results:
print(row)
登録された
('Tokyo', 13515271, 'Japan')
('Delhi', 16753235, 'India')
('Shanghai', 24870895, 'China')
('São Paulo', 12252023, 'Brazil')
('Mexico City', 9209944, 'Mexico')
('Cairo', 9500000, 'Egypt')
('Mumbai', 12478447, 'India')
('Beijing', 21893095, 'China')
('Dhaka', 8906039, 'Bangladesh')
('Osaka', 2725006, 'Japan')
('New York City', 8804190, 'United States')
(snip)
ではテキストで検索してみる。まずデータベースに接続するためのSQLDatabaseオブジェクトを作成し、Service Contextの設定を行う。
from llama_index import SQLDatabase, ServiceContext
from llama_index.llms import OpenAI
llm = OpenAI(temperature=0.1, model="gpt-3.5-turbo")
service_context = ServiceContext.from_defaults(llm=llm)
sql_database = SQLDatabase(engine, include_tables=["city_stats"])
クエリは3つの方法がある。
- NLSQLTableQueryEngine
- SQLTableRetrieverQueryEngine
- NLSQLRetriever
NLSQLTableQueryEngine
NLSQLTableQueryEngineはテーブルの指定が必要になる。
from llama_index.indices.struct_store.sql_query import NLSQLTableQueryEngine
query_engine = NLSQLTableQueryEngine(
sql_database=sql_database,
tables=["city_stats"],
)
query_str = "最も人口が多い都市の都市名と人口を教えて。都市名は国名もつけて、人口は万人単位でおおよそで良いです。回答は日本語で。"
response = query_engine.query(query_str)
print(response)
最も人口が多い都市は、中国の重慶(Chongqing)で、人口は約3205万人です。
ログを見る。
スキーマ情報からまずSQLを生成している。
User: Given an input question, first create a syntactically correct sqlite query to run, then look at the results of the query and return the answer. You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for a few relevant columns given the question.
Pay attention to use only the column names that you can see in the schema description. Be careful to not query for columns that do not exist. Pay attention to which column is in which table. Also, qualify column names with the table name when needed. You are required to use the following format, each taking one line:
Question: Question here
SQLQuery: SQL Query to run
SQLResult: Result of the SQLQuery
Answer: Final answer here
Only use tables listed below.
Table 'city_stats' has columns: city_name (TEXT), population (BIGINT), country (TEXT), and foreign keys: .
Question: 最も人口が多い都市の都市名と人口を教えて。都市名は国名もつけて、人口は万人単位でおおよそで良いです。回答は日本語で。
SQLQuery:
生成されたSQLは以下。
SELECT city_name || ' (' || country || ')' AS city, population/10000 AS population
FROM city_stats
ORDER BY population DESC
LIMIT 1;
実際にSQLを実行した結果を付与してLLMに最終回答を生成させている
User: Given an input question, synthesize a response from the query results.
Query: 最も人口が多い都市の都市名と人口を教えて。都市名は国名もつけて、人口は万人単位でおおよそで良いです。回答は日本語で。
SQL: SELECT city_name || ' (' || country || ')' AS city, population/10000 AS population
FROM city_stats
ORDER BY population DESC
LIMIT 1;
SQL Response: [('Chongqing (China)', 3205)]
Response:
SQLTableRetrieverQueryEngine
SQLTableRetrieverQueryEngineでは、テーブルのスキーマに関する情報を事前に定義したベクトルインデックスを追加することで、テーブル名の定義は不要、クエリの内容から適切なテーブルを参照するようなSQLを生成する、というものらしい
from llama_index.indices.struct_store.sql_query import SQLTableRetrieverQueryEngine
from llama_index.objects import SQLTableNodeMapping, ObjectIndex, SQLTableSchema
from llama_index import VectorStoreIndex
# ログレベルDEBUGで詳細を確認できる
table_node_mapping = SQLTableNodeMapping(sql_database)
# 各テーブルにSQLTableSchemaを追加する
table_schema_objs = [
(SQLTableSchema(table_name="city_stats"))
]
obj_index = ObjectIndex.from_objects(
table_schema_objs,
table_node_mapping,
VectorStoreIndex,
)
query_engine = SQLTableRetrieverQueryEngine(
sql_database, obj_index.as_retriever(similarity_top_k=1)
)
ログを見ると以下のような文字列のEmbeddingが作成されていた。
Schema of table city_stats: Table 'city_stats' has columns: city_name (TEXT), population (BIGINT), country (TEXT), and foreign keys: .
クエリを実行してみる。
response = query_engine.query("最も人口が多い都市の都市名と人口を教えて。都市名は国名もつけて、人口は万人単位でおおよそで良いです。回答は日本語で。")
print(response)
最も人口が多い都市は、中国の重慶(Chongqing)で、人口は約3205万人です。
ログを見てみる。
まず最初にクエリの内容をEmbeddingに変換している。
DEBUG:openai._base_client:Request options: {'method': 'post', 'url': '/embeddings', 'files': None, 'post_parser': <function Embeddings.create.<locals>.parser at 0x7c305625ae60>, 'json_data': {'input': ['最も人口が多い都市の都市名と人口を教えて。都市名は国名もつけて、人口は万人単位でおおよそで良いです。回答は日本語で。'], 'model': <OpenAIEmbeddingModeModel.TEXT_EMBED_ADA_002: 'text-embedding-ada-002'>, 'encoding_format': 'base64'}}
ベクトル検索で対象のテーブルを抽出、といっても今回は1テーブルしかないんだけども。
DEBUG:llama_index.indices.utils:> Top 1 nodes:
> [Node 7662dbb1-36d3-46fa-b369-8c14c9ccd628] [Similarity score: 0.756545] Schema of table city_stats:
Table 'city_stats' has columns: city_name (TEXT), population (BIGINT)...
参照すべきテーブルが分かれば、あとはNLSQLTableQueryEngineと同様になる。
- LLMにスキーマなどを渡してSQLを生成させる
- SQL実行して結果取得
- LLMにSQL実行結果を渡して回答を生成させる。
メタデータでSQL結果を取得することもできる。
response.metadata["result"]
[('Chongqing (China)', 3205)]
なお、スキーマ情報は直接文字列で定義することも可能。
NLSQLRetriever
Query Engineは検索(retriever)と生成(synthesis)がパッケージ化されたものになっているが、retreiverを定義して直接使うこともできる。
from llama_index.retrievers import NLSQLRetriever
nl_sql_retriever = NLSQLRetriever(
sql_database, tables=["city_stats"], return_raw=True
)
results = nl_sql_retriever.retrieve(
"最も人口が多い都市トップ5の都市名と人口を教えて。都市名は国名もつけて、人口は万人単位でおおよそで良いです。回答は日本語で。"
)
print(results[0].text)
[('Chongqing (China)', 3205), ('Shanghai (China)', 2487), ('Beijing (China)', 2189), ('Karachi (Pakistan)', 2038), ('Delhi (India)', 1675)]
こういうユーティリティがあるみたい
from llama_index.response.notebook_utils import display_source_node
for n in results:
display_source_node(n)
Node ID: 8e8bf3bc-b519-4d96-b1df-b016d4104218
Similarity: None
Text: [('Chongqing (China)', 3205), ('Shanghai (China)', 2487), ('Beijing (China)', 2189), ('Karachi (P...
以下のような書き方だと各Nodeのメタデータに付与される形になるっぽい。
from llama_index.retrievers import NLSQLRetriever
from llama_index.response.notebook_utils import display_source_node
nl_sql_retriever = NLSQLRetriever(
sql_database, tables=["city_stats"], return_raw=False # return_raw=Falseに変更
)
results = nl_sql_retriever.retrieve(
"最も人口が多い都市トップ5の都市名と人口を教えて。都市名は国名もつけて、人口は万人単位でおおよそで良いです。回答は日本語で。"
)
for n in results:
display_source_node(n, show_source_metadata=True) # show_source_metadata=Trueに変更
Node ID: 88629fb2-4789-4c8b-9d47-a9d76c9f6815
Similarity: None
Text:
Metadata: {'city': 'Chongqing (China)', 'population': 3205}
Node ID: 1fc44882-08dc-43f5-896b-84b5cd900ad8
Similarity: None
Text:
Metadata: {'city': 'Shanghai (China)', 'population': 2487}
Node ID: b2845b18-e509-4912-924d-c96ba84456e7
Similarity: None
Text:
Metadata: {'city': 'Beijing (China)', 'population': 2189}
Node ID: b7689734-f96a-4fb0-aba9-dc9d54155f00
Similarity: None
Text:
Metadata: {'city': 'Karachi (Pakistan)', 'population': 2038}
Node ID: f827fd5b-acd5-4d56-a971-000d630bc725
Similarity: None
Text:
Metadata: {'city': 'Delhi (India)', 'population': 1675}
このretrieverをRetrieverQueryEngineでラップすれば、回答の生成が行える。
from llama_index.query_engine import RetrieverQueryEngine
query_engine = RetrieverQueryEngine.from_args(nl_sql_retriever)
response = query_engine.query(
"最も人口が多い都市トップ5の都市名と人口を教えて。都市名は国名もつけて、人口は万人単位でおおよそで良いです。回答は日本語で。"
)
print(response)
上位5つの都市とその人口は以下の通りです。
1. 上海 (中国) - 2487万人
2. 北京 (中国) - 2189万人
3. 重慶 (中国) - 3205万人
4. カラチ (パキスタン) - 2038万人
5. デリー (インド) - 1675万人
順番に並んでないのはご愛嬌かな。
Document Summary Index
Document Summary Indexは、各ドキュメントをまず要約して、その要約をドキュメントに紐づくノードとともにインデックス化する。クエリ時はまずこの要約を検索して該当するドキュメントを選択し、そのドキュメントに紐づいているノードを取得するという流れになっているらしい。
まずwikipediaからドキュメントを作成。
from pathlib import Path
import requests
# Wikipediaからのデータ読み込み
wiki_titles = ["ドウデュース","イクイノックス"]
for title in wiki_titles:
response = requests.get(
"https://ja.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
# 'exintro': True,
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
wiki_text = page["extract"]
data_path = Path("data")
if not data_path.exists():
Path.mkdir(data_path)
with open(data_path / f"{title}.txt", "w") as fp:
fp.write(wiki_text)
ドキュメントをロード。おー、今までSimpleDirectoryReaderでまるっと読み込んでたけど、ドキュメントIDを文書のタイトルとかにするというやり方があるのか。
from llama_index import SimpleDirectoryReader
# ドキュメントの読み込み
horse_docs = []
for wiki_title in wiki_titles:
docs = SimpleDirectoryReader(input_files=[f"data/{wiki_title}.txt"]).load_data()
docs[0].doc_id = wiki_title
horse_docs.extend(docs)
DocumentSummaryIndexを使ってインデックス化する。
from llama_index import ServiceContext, get_response_synthesizer
from llama_index.indices.document_summary import DocumentSummaryIndex
from llama_index.llms import OpenAI
import nest_asyncio
# Tree Summarizeは非同期でないとダメっぽい
nest_asyncio.apply()
chatgpt = OpenAI(temperature=0, model="gpt-3.5-turbo")
service_context = ServiceContext.from_defaults(llm=chatgpt, chunk_size=1024)
response_synthesizer = get_response_synthesizer(
response_mode="tree_summarize", use_async=True
)
doc_summary_index = DocumentSummaryIndex.from_documents(
horse_docs,
service_context=service_context,
response_synthesizer=response_synthesizer,
show_progress=True,
)
npaka先生の記事ではプロンプトも日本語化しているけど、まずはデフォルトのプロンプトがどのようなものかを一旦見ておく。
こんな感じで、全てのNodeを渡して、
- 何について書いてあるか?
- この文章からどのような質問が考えられるか?
を要約として生成するように指示している。
System: You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like 'Based on the context, ...' or 'The context information ...' or anything along those lines.
User: Context information from multiple sources is below.
---------------------
file_path: data/ドウデュース.txt
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。(snip)
file_path: data/ドウデュース.txt
単勝オッズ2.2倍の1番人気に推された。道中は勝ち馬アスクビクターモアを見る形で追走。残り800メートル過ぎに後方からロジハービンが一気に進出したため、いったんポジションを下げる。(snip)
file_path: data/ドウデュース.txt
6月10日に国際競馬統括機関連盟が発表した「ロンジンワールドベストレースホースランキング」において、ドウデュースは日本ダービーを勝利した功績を評価され、シャフリヤールやエンブレムロードと並ぶレーティング120で第15位タイに位置づけられた。(snip)
---------------------
Given the information from multiple sources and not prior knowledge, answer the query.
Query: Describe what the provided text is about. Also describe some of the questions that this text can answer.
Answer:
System: You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like 'Based on the context, ...' or 'The context information ...' or anything along those lines.
User: Context information from multiple sources is below.
---------------------
data/ドウデュース.txt
しかし出馬投票後の同月24日、調教後に左前肢跛行を発症しドバイターフへの出走を取り消した。(snip)
file_path: data/ドウデュース.txt
馬番5番での優勝は、1970年のスピードシンボリ、1972年のイシノヒカルに次いで、51年ぶり3度目となった。(snip)
---------------------
Given the information from multiple sources and not prior knowledge, answer the query.
Query: Describe what the provided text is about. Also describe some of the questions that this text can answer.
Answer:
全部のNodeの要約が揃ったら、再度まとめて要約させる。
System: You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like 'Based on the context, ...' or 'The context information ...' or anything along those lines.
User: Context information from multiple sources is below.
---------------------
The provided text is about a Japanese racehorse named ドウデュース (Do Deuce). It provides information about the horse's background, career, and achievements in various races. The text mentions that ドウデュース won the Asahi Hai Futurity Stakes in 2021, the Tokyo Yushun (Japanese Derby) in 2022, and the Arima Kinen in 2023. It also highlights the horse's performance in other races such as the Ivy Stakes and the Satsuki Sho (Japanese 2000 Guineas). The text mentions the jockey, trainer, and owner associated with ドウデュース, as well as the horse's rankings in international horse racing rankings.
Some questions that this text can answer include:
- What are the major victories of ドウデュース in horse racing?
- Who is the jockey and trainer of ドウデュース?
- What is the owner's name and the ownership history of ドウデュース?
- What are the rankings of ドウデュース in international horse racing rankings?
- What are some of the races that ドウデュース participated in and how did it perform in those races?
The provided text is about the racing career and achievements of a horse named ドウデュース. It mentions the horse's participation in various races, including the Dubai Turf and the Emperor's Cup (Autumn). It also highlights the horse's performance in the Japan Cup and the Arima Kinen, where it achieved a victory. The text further mentions the horse's jockey changes and its association with trainers. Additionally, it provides information about the horse's pedigree and its connections to other notable horses.
Based on this text, some questions that can be answered include:
- What races did ドウデュース participate in?
- Did ドウデュース win any races?
- Who were the jockeys and trainers associated with ドウデュース?
- What is the pedigree of ドウデュース?
- What are some notable achievements of ドウデュース in its racing career?
---------------------
Given the information from multiple sources and not prior knowledge, answer the query.
Query: Describe what the provided text is about. Also describe some of the questions that this text can answer.
Answer:
最終的にこういう要約が生成される
The provided text is about a Japanese racehorse named ドウデュース (Do Deuce). It provides information about the horse's background, career, and achievements in various races. The text mentions the horse's participation in races such as the Asahi Hai Futurity Stakes, Tokyo Yushun (Japanese Derby), Arima Kinen, Ivy Stakes, Satsuki Sho (Japanese 2000 Guineas), Dubai Turf, Emperor's Cup (Autumn), and Japan Cup. It also highlights the horse's victories in some of these races. The text mentions the jockey, trainer, and owner associated with ドウデュース, as well as the horse's rankings in international horse racing rankings.
Some questions that this text can answer include:
- What are the major victories of ドウデュース in horse racing?
- Who is the jockey and trainer of ドウデュース?
- What is the owner's name and the ownership history of ドウデュース?
- What are the rankings of ドウデュース in international horse racing rankings?
- What are some of the races that ドウデュース participated in and how did it perform in those races?
- What is the pedigree of ドウデュース?
- What are some notable achievements of ドウデュース in its racing career?
これらのテンプレートは以下で定義されている。
なので日本語の場合はこれを全部設定して、get_response_synthesizerとDocumentSummaryIndexでソレを指定すればOK。
from llama_index.prompts import ChatPromptTemplate, ChatMessage, MessageRole
from llama_index import ServiceContext, get_response_synthesizer
from llama_index.indices.document_summary import DocumentSummaryIndex
from llama_index.llms import OpenAI
import nest_asyncio
# Tree Summarizeは非同期でないとダメっぽい
nest_asyncio.apply()
chatgpt = OpenAI(temperature=0, model="gpt-3.5-turbo")
service_context = ServiceContext.from_defaults(llm=chatgpt, chunk_size=1024)
# QAシステムプロンプト
TEXT_QA_SYSTEM_PROMPT = ChatMessage(
content=(
"あなたは世界中で信頼されているQAシステムです。\n"
"事前知識ではなく、常に提供されたコンテキスト情報を使用してクエリに回答してください。\n"
"従うべきいくつかのルール:\n"
"1. 回答内で指定されたコンテキストを直接参照しないでください。\n"
"2. 「コンテキストに基づいて、...」や「コンテキスト情報は...」、またはそれに類するような記述は避けてください。"
),
role=MessageRole.SYSTEM,
)
# QAプロンプトテンプレートメッセージ
TEXT_QA_PROMPT_TMPL_MSGS = [
TEXT_QA_SYSTEM_PROMPT,
ChatMessage(
content=(
"コンテキスト情報は以下のとおりです。\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"事前知識ではなくコンテキスト情報を考慮して、クエリに答えます。\n"
"Query: {query_str}\n"
"Answer: "
),
role=MessageRole.USER,
),
]
# チャットQAプロンプト
CHAT_TEXT_QA_PROMPT = ChatPromptTemplate(message_templates=TEXT_QA_PROMPT_TMPL_MSGS)
TREE_SUMMARIZE_PROMPT_TMPL_MSGS = [
TEXT_QA_SYSTEM_PROMPT,
ChatMessage(
content=(
"複数のソースからのコンテキスト情報を以下に示します。\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"予備知識ではなく、複数のソースからの情報を考慮して、質問に答えます。\n"
"疑問がある場合は、「情報無し」と答えてください。\n"
"Query: {query_str}\n"
"Answer: "
),
role=MessageRole.USER,
),
]
# ツリー要約プロンプト
CHAT_TREE_SUMMARIZE_PROMPT = ChatPromptTemplate(
message_templates=TREE_SUMMARIZE_PROMPT_TMPL_MSGS
)
# 要約指示プロンプト
SUMMARY_QUERY = "提供されたテキストがどういうことについて書かれているかを要約して説明しなさい。また、このテキストで答えることができるいくつかの質問について説明しなさい。"
response_synthesizer = get_response_synthesizer(
response_mode="tree_summarize",
use_async=True,
text_qa_template=CHAT_TEXT_QA_PROMPT, # 日本語QAプロンプトテンプレートの指定
summary_template=CHAT_TREE_SUMMARIZE_PROMPT, # 日本語TreeSummarizeプロンプトテンプレートの指定
)
doc_summary_index = DocumentSummaryIndex.from_documents(
horse_docs,
service_context=service_context,
response_synthesizer=response_synthesizer,
show_progress=True,
summary_query=SUMMARY_QUERY, # 日本語要約指示プロンプトの指定
)
なかなかテンプレートがどう使われているかを追いかけるのはしんどいな・・・それはともかくドキュメントに対してはこういう要約が生成された。
doc_summary_index.get_document_summary("ドウデュース")
提供されたテキストは、競走馬のドウデュースに関する情報を含んでいます。ドウデュースは日本の競走馬であり、2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念など、いくつかの重要なレースで勝利を収めています。また、ドウデュースは2019年に誕生し、株式会社キーファーズの所有馬となりました。さらに、ドウデュースは2歳時にJRA賞最優秀2歳牡馬に選ばれ、日本ダービーなどのレースでも成功を収めました。
このテキストで答えることができるいくつかの質問は、以下のようなものです:
- ドウデュースの主な勝ち鞍は何ですか?
- ドウデュースの馬名の意味は何ですか?
- ドウデュースのデビューはいつで、どの競馬場で行われましたか?
- ドウデュースは何歳の時に朝日杯フューチュリティステークスを制覇しましたか?
- ドウデュースの鞍上は誰ですか?
- ドウデュースはどのレースでダービーレコードを達成しましたか?
- ドウデュースは凱旋門賞に出走しましたか?
- ドウデュースは京都記念で何着になりましたか?
- ドウデュースはドバイターフに出走しましたか?
- ドウデュースは天皇賞(秋)に出走しましたか?
提供されたテキストでは、ドウデュースの競走成績や血統情報、特定のレースでのパフォーマンスなどが述べられています。これらの情報をもとに、上記の質問に詳細な回答を提供することができます。
doc_summary_index.get_document_summary("イクイノックス")
提供されたテキストは、競走馬イクイノックスに関する情報を含んでいます。イクイノックスは日本の競走馬であり、2022年にはGI制覇を果たし、2023年には秋春グランプリ制覇を達成しました。イクイノックスはキタサンブラックの産駒であり、父方の血統にはGIを7勝したキタサンブラックや高松宮記念を制覇したキングヘイローが含まれています。イクイノックスの戦績には、2歳時の新馬戦と東京スポーツ杯2歳ステークスでの連勝、3歳時の皐月賞での2着、東京優駿(日本ダービー)での2着、天皇賞(秋)での勝利、有馬記念での勝利などが含まれています。
このテキストで答えることができる質問は以下の通りです:
1. イクイノックスの勝利したGIレースはどれですか?
2. イクイノックスの父は誰ですか?
3. イクイノックスは何歳の時に天皇賞(秋)を制覇しましたか?
4. イクイノックスは有馬記念で何着になりましたか?
5. イクイノックスの血統にはどのような競走馬が含まれていますか?
またこれらの要約についてはEmbeddingが作成されていることもわかる。
DEBUG:openai._base_client:Request options: {'method': 'post', 'url': '/embeddings', 'files': None, 'post_parser': <function Embeddings.create.<locals>.parser at 0x785811bc7c70>, 'json_data': {'input': ['提供されたテキストは、競走馬のドウデュースに関する情報を含んでいます。ドウデュースは日本の競走馬であり、2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念など、いくつかの重要なレースで勝利を収めています。また、ドウデュースは2019年に誕生し、株式会社キーファーズの所有馬となりました。さらに、ドウデュースは2歳時にJRA賞最優秀2歳牡馬に選ばれ、日本ダービーなどのレースでも成功を収めました。 このテキストで答えることができるいくつかの質問は、以下のようなものです: - ドウデュースの主な勝ち鞍は何ですか? - ドウデュースの馬名の意味は何ですか? - ドウデュースのデビューはいつで、どの競馬場で行われましたか? - ドウデュースは何歳の時に朝日杯フューチュリティステークスを制覇しましたか? - ドウデュースの鞍上は誰ですか? - ドウデュースはどのレースでダービーレコードを達成しましたか? - ドウデュースは凱旋門賞に出走しましたか? - ドウデュースは京都記念で何着になりましたか? - ドウデュースはドバイターフに出走しましたか? - ドウデュースは天皇賞(秋)に出走しましたか? 提供されたテキストでは、ドウデュースの競走成績や血統情報、特定のレースでのパフォーマンスなどが述べられています。これらの情報をもとに、上記の質問に詳細な回答を提供することができます。', '提供されたテキストは、競走馬イクイノックスに関する情報を含んでいます。イクイノックスは日本の競走馬であり、2022年にはGI制覇を果たし、2023年には秋春グランプリ制覇を達成しました。イクイノックスはキタサンブラックの産駒であり、父方の血統にはGIを7勝したキタサンブラックや高松宮記念を制覇したキングヘイローが含まれています。イクイノックスの戦績には、2歳時の新馬戦と東京スポーツ杯2歳ステークスでの連勝、3歳時の皐月賞での2着、東京優駿(日本ダービー)での2着、天皇賞(秋)での勝利、有馬記念での勝利などが含まれています。 このテキストで答えることができる質問は以下の通りです: 1. イクイノックスの勝利したGIレースはどれですか? 2. イクイノックスの父は誰ですか? 3. イクイノックスは何歳の時に天皇賞(秋)を制覇しましたか? 4. イクイノックスは有馬記念で何着になりましたか? 5. イクイノックスの血統にはどのような競走馬が含まれていますか?'], 'model': <OpenAIEmbeddingModeModel.TEXT_EMBED_ADA_002: 'text-embedding-ada-002'>, 'encoding_format': 'base64'}}
このインデックスをファイルに保存する場合は以下。
doc_summary_index.storage_context.persist("index")
DEBUG:fsspec.local:open file: /content/index/docstore.json
DEBUG:fsspec.local:open file: /content/index/index_store.json
DEBUG:fsspec.local:open file: /content/index/graph_store.json
DEBUG:fsspec.local:open file: /content/index/default__vector_store.json
DEBUG:fsspec.local:open file: /content/index/image__vector_store.json
保存したインデックスを読み出す場合は以下。
from llama_index.indices.loading import load_index_from_storage
from llama_index import StorageContext
storage_context = StorageContext.from_defaults(persist_dir="index")
doc_summary_index = load_index_from_storage(storage_context)
ではクエリ。query engineを使ったハイレベルアクセスと、retrieverを使ったローレベルアクセスの両方が紹介されている。
query engineを使ったハイレベルアクセスの場合。
query_engine = doc_summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
summary_template=CHAT_TREE_SUMMARIZE_PROMPT,
)
response = query_engine.query("ドウデュースが勝ったGIレースは?")
print(response)
ドウデュースが勝ったGIレースは朝日杯フューチュリティステークス、東京優駿(日本ダービー)、有馬記念です。
どちらのドキュメントが選択されるのかはEmbeddingで決まるようで、特にログにも出ておらず、はっきりとは分からないが、ドウデュースのNodeが選ばれているのでおそらく正しく選択されているのだと思われる。
retrieverを使ったローレベルアクセスにはEmbeddingベースとLLMベースがあるらしい。
LLMベースはこんな感じ。
from llama_index.indices.document_summary import DocumentSummaryIndexLLMRetriever
from llama_index.query_engine import RetrieverQueryEngine
retriever = DocumentSummaryIndexLLMRetriever(
doc_summary_index,
)
response_synthesizer = get_response_synthesizer(
response_mode="tree_summarize",
)
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
response = query_engine.query("イクイノックスが勝ったGIレースは?")
print(response)
ログを見るとまた違うプロンプトが使用されている。
User: A list of documents is shown below. Each document has a number next to it along with a summary of the document. A question is also provided.
Respond with the numbers of the documents you should consult to answer the question, in order of relevance, as well
as the relevance score. The relevance score is a number from 1-10 based on how relevant you think the document is to the question.
Do not include any documents that are not relevant to the question.
Example format:
Document 1:
<summary of document 1>
Document 2:
<summary of document 2>
...
Document 10:
<summary of document 10>
Question: <question>
Answer:
Doc: 9, Relevance: 7
Doc: 3, Relevance: 4
Doc: 7, Relevance: 3
Let's try this now:
Document 1:
提供されたテキストは、競走馬のドウデュースに関する情報を含んでいます。ドウデュースは日本の競走馬であり、2021年の朝日杯フューチュリティステークス、2022年の東京優駿(日本ダービー)、2023年の有馬記念など、いくつかの重要なレースで勝利を収めています。また、ドウデュースはJRA賞最優秀2歳牡馬に選ばれたこともあります。
このテキストで答えることができるいくつかの質問は、以下のようなものです:
- ドウデュースの主な勝ち鞍は何ですか?
- ドウデュースの馬名の意味は何ですか?
- ドウデュースのデビューはいつで、どの競走場で行われましたか?
- ドウデュースは何歳の時に朝日杯フューチュリティステークスを制覇しましたか?
- ドウデュースは東京優駿(日本ダービー)で何着になりましたか?
- ドウデュースは凱旋門賞に出走しましたか?
- ドウデュースは京都記念で何着になりましたか?
- ドウデュースはドバイターフに出走しましたか?
- ドウデュースは天皇賞(秋)に出走しましたか?
提供されたテキストでは、ドウデュースの競走成績や血統情報、特定のレースでのパフォーマンスなどが述べられています。また、ドウデュースがドバイや凱旋門賞に再挑戦する予定であることも示されています。
Document 2:
提供されたテキストは、競走馬イクイノックスに関する情報を含んでいます。イクイノックスは日本の競走馬であり、2022年に初のGI制覇を果たし、2023年には秋春グランプリ制覇を達成しました。彼はドバイシーマクラシックや宝塚記念などのレースで優勝し、GI4連勝を達成しました。また、彼は天皇賞(秋)でも連覇を果たし、JRA総獲得賞金ランキングでも上位に位置しています。イクイノックスは競走馬引退後、社台スタリオンステーションで種牡馬として供用されることが発表されました。初年度の種付料は2000万円で、アーモンドアイとの配合も予定されています。イクイノックスの血統には、父キタサンブラックなどの馬が含まれています。
このテキストで答えることができるいくつかの質問は:
1. イクイノックスの父は誰ですか?
2. イクイノックスはどのような成績を収めましたか?
3. イクイノックスはどのようなレースで勝利しましたか?
4. イクイノックスはどのような特徴を持っていますか?
5. イクイノックスの最も注目すべき勝利は何ですか?
6. イクイノックスはどのような賞を受賞しましたか?
7. イクイノックスの次のレースは何ですか?
8. イクイノックスはどのような評価を受けていますか?
などがあります。
Question: イクイノックスが勝ったGIレースは?
Answer:
どうやらLLMベースの場合は、ドキュメントの要約をLLMに渡して、クエリがどのドキュメントに該当するか?を選択するらしい。プロンプトテンプレートはこれ。
なのでこれも日本語に書き換えてやる。
from llama_index.indices.document_summary import DocumentSummaryIndexLLMRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.prompts.base import PromptTemplate
from llama_index.prompts.prompt_type import PromptType
# ChoiceSelectプロンプトテンプレート
DEFAULT_CHOICE_SELECT_PROMPT_TMPL = (
"ドキュメントの一覧を以下に示します。各ドキュメントの横には文書の要約とともに番号が付いています。そして質問も提供されています。"
"質問に答えるために参照する必要があるドキュメントの番号を、関連性の高い順に、関連性スコアと共に回答してください。"
"関連性スコアは、そのドキュメントが質問に対してどの程度関連していると思われるかに基づいて1~10の数値で表します。\n\n"
"質問に関係のないドキュメントは含めないでください。"
"フォーマットの例: \n\n"
"Document 1:\n<summary of document 1>\n\n"
"Document 2:\n<summary of document 2>\n\n"
"...\n\n"
"Document 10:\n<summary of document 10>\n\n"
"Question: <question>\n"
"Answer:\n"
"Doc: 9, Relevance: 7\n"
"Doc: 3, Relevance: 4\n"
"Doc: 7, Relevance: 3\n\n"
"では、はじめましょう。\n\n"
"{context_str}\n"
"Question: {query_str}\n"
"Answer:\n"
)
# ChoiceSelectプロンプト
DEFAULT_CHOICE_SELECT_PROMPT = PromptTemplate(
DEFAULT_CHOICE_SELECT_PROMPT_TMPL, prompt_type=PromptType.CHOICE_SELECT
)
retriever = DocumentSummaryIndexLLMRetriever(
doc_summary_index,
choice_select_prompt=DEFAULT_CHOICE_SELECT_PROMPT,
)
response_synthesizer = get_response_synthesizer(
response_mode="tree_summarize",
summary_template=CHAT_TREE_SUMMARIZE_PROMPT,
)
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer
)
response = query_engine.query("イクイノックスが勝ったGIレースは?")
print(response)
イクイノックスが勝ったGIレースは、2022年の有馬記念、ドバイシーマクラシック、宝塚記念、ジャパンカップです。
Embeddingベースの場合。こちらはEmbeddingの類似検索でドキュメントを選択するのでChoiceプロンプトは不要。
from llama_index.indices.document_summary import DocumentSummaryIndexEmbeddingRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.prompts.base import PromptTemplate
from llama_index.prompts.prompt_type import PromptType
retriever = DocumentSummaryIndexEmbeddingRetriever(
doc_summary_index
)
response_synthesizer = get_response_synthesizer(
response_mode="tree_summarize",
summary_template=CHAT_TREE_SUMMARIZE_PROMPT,
)
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer
)
response = query_engine.query("イクイノックスが勝ったGIレースは?")
print(response)
直接関係ないのだけど、DEBUGログを有効にしていても、LLMからどういう回答が返って来たのかがわからない場合がある。
このあたりを先にやったほうがいい気がちょっとしてきた。
ということでためしてみた
ここ読み飛ばしてたな。
LlamaIndexはインデックスのコンポーザビリティを提供し、他のインデックスの上にインデックスを構築することができます。これにより、カスタムナレッジをGPTに供給するために、ドキュメントツリー全体のインデックスをより効果的に作成することができます。