[OpenSearch] 事例読み解き / 運用してわかった SIEM ON AMAZON OPENSEARCH SERVICE の構築とインシデント対応の実際 (freee)
AWS Security Roadshow Japan 2021 の freee さんの発表「運用してわかった SIEM On Amazon OpenSearch Sservice の構築とインシデント対応の実際」を読み解く。OpenSearch 関係を拾う
Title: 運用してわかった SIEM On Amazon OpenSearch Sservice の構築とインシデント対応の実際
Speakers: freee株式会社 PSIRT Tech Lead 杉浦 英史 氏
Document: https://www.awssecevents.com/ja/ondemandtracks/tech_track_2/
AWS Samples
背景知識
セキュリティ向上をミッションとする "PSIRT" という組織での取り組み。コーポレート IT のチームは別にあり、PSIRT はプロダクト担当である
「多層防御」という考え方。
- WAF, IPS, AnitiMalware などで外部からの脅威を検知
- イメージスキャンで実行環境の脆弱性を検知
- EDR (Endpoint Detection and Response) や NGFW で内部からの攻撃を検知
- 侵入後の被害半径を軽減するための Risk based authentication
- 異常な振る舞いを CloudTrail, GuardDity で検知
これらを達成するために、ログの集約+アラート+解析 を行える仕組みが必要。SIEM はこのへんを表す概念らしいし、SIEM on AWS OpenSearch はその実装を提供する固有名詞ということらしい
SIEM を入れていなかった時代につらかったこと
Security log/ Service log/ Application log...ぜんぶ突合して見るのはしんどいし時間がかかる。
無駄なアラートが各所で発生しており狼少年状態に。
実質的に incident handling できていなかった。
SIEM を入れて技術的な構成はどうなったか
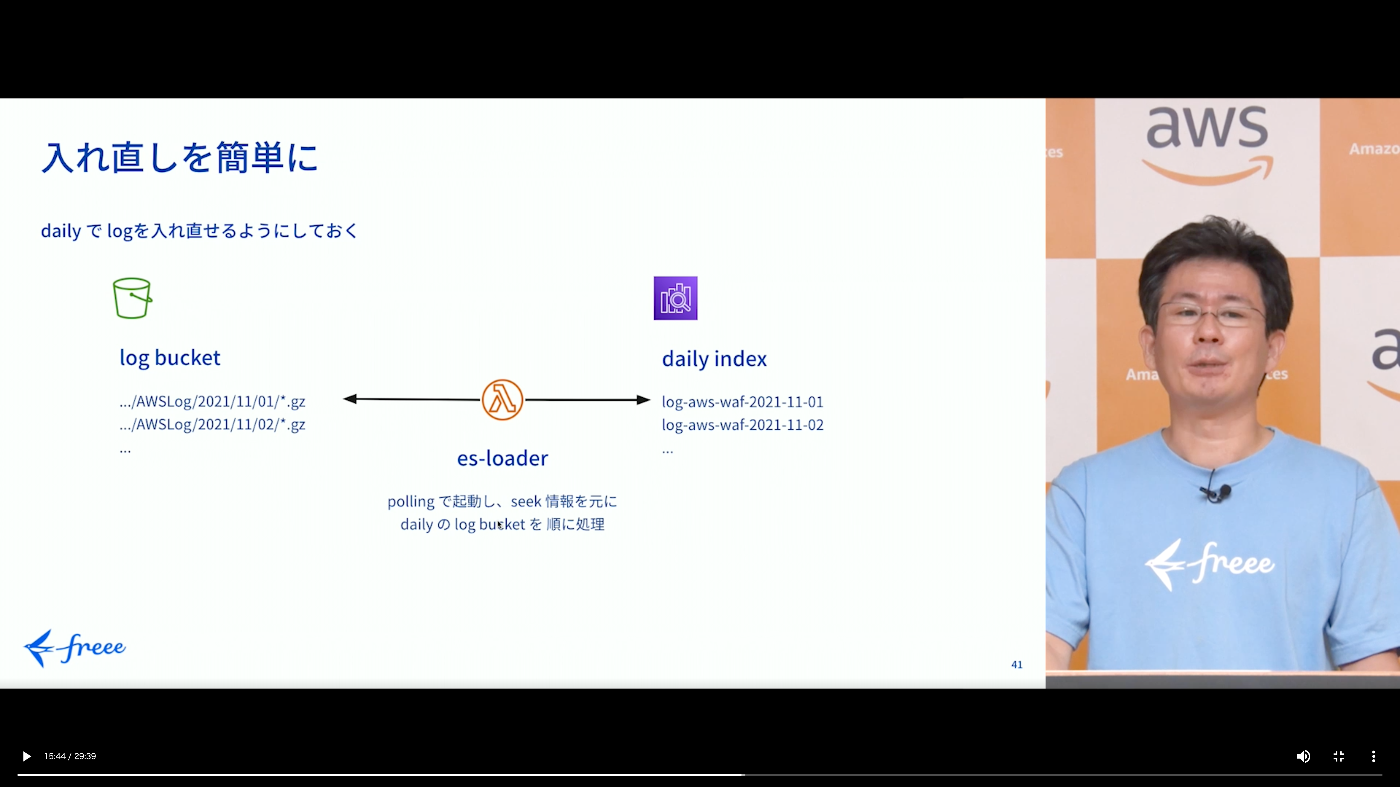
ログは S3 集約になった。ETL がしやすくなった。
es-loader と呼ばれる lambda が取り込んで ES に取り込んでくれる(大きな S3 object は分割できる)
Dead letter queue も実装済み
プラグインが使える。例えば aws-samples/siem-on-amazon-opensearch-service の sf_waf.py
扱うログの種類を増やしたかったら、↑のプラグインを増やして設定ファイルに追記することで対応可能
SIEM on AOS 導入後の困りごと
大きなオブジェクトは分割してくれるが、小さなオブジェクトが大量に発生する場合は S3 put trigger の lambda がスロットリング (429 Too Many Requests) してしまって DLQ に流れてしまう。
SIEM on AOS が提供する lambda (es_loader) は S3 PUT に反応するように作られているが、 freee では上記の事情があったためこの lambda を変更し、定期的に bulk insert する方式に変更した。
副次的な効果として、S3 と AOS はともに daily でパーティショニング/index を切っていたがこの管理が楽になった。(内部的に seek file の仕組みを使って取り込み状態を管理していた ... ※)
※ ... おそらく lambda の実装に固有なことを指していると思われる。Put でトリガーしない場合は「まだ取り込んでない分」をどこかで判定する必要があり、それは lambda のロジック中で扱う必要があるものなので
es-loader による取り込み処理が失敗した場合は DLQ に行くので、これらは手動でリカバリ対応する。
※ 15:44 ごろ
log-aws-waf-yyyy-mm-dd のフォーマットでインデックスを構成している
※ 16:35 ごろ

(1) Daily index
monthly にすると migrate(?) が終わらないしやり直しが大変。index は 50GB 以内に収めたい
(2) Hot/Warm/Cold storage
ログは RO なので、積極的に UltraWarm に移動する。
Hto -> UltraWarm への migrate は、AOS インスタンスから S3 に移動する処理が走るのでそれなりに時間がかかる。index を月次で切っているとここが重たくなる
(3) Index stage management
hot -> warm -> cold migraion を自動化する
(4) Planning + Feedback
ログの容量は予測不可能であるため、試してみること。
(5) 25% storage alert
node のストレージを使い切らないように監視すること
基本的にはベストプラクティスに従った運用を行っている
実際の業務の様子
ALB の横で WAF が、インスタンスの横で IPS が動いている。
WAF, IPS の相関分析
ある1日に着目し、攻撃性の高いアクセスを絞り込む
- WAF: 正しく検知できているアクセスは表示から除外(IP ブラックリストに載っている IP からのアクセス、特定のパス (攻撃性があると判断される) へのアクセス)
- WAF: XSS の疑いのある検知を発見したので、これを見ていく(一部すり抜けてしまっている)
- IPS: WAF をすり抜けた XSS 狙いのアクセスが見えており、検知されている(現実的であれば WAF のルールを改善することも検討する)
Anonymous access
s3 に unauthorized access が飛んできている事例。
実在するパスに GetObject が飛んできた。以前は、実際にそのパスがあったので、そこを塞いだ
誤って DoS
ある日、 Public API への大量アクセスがあった
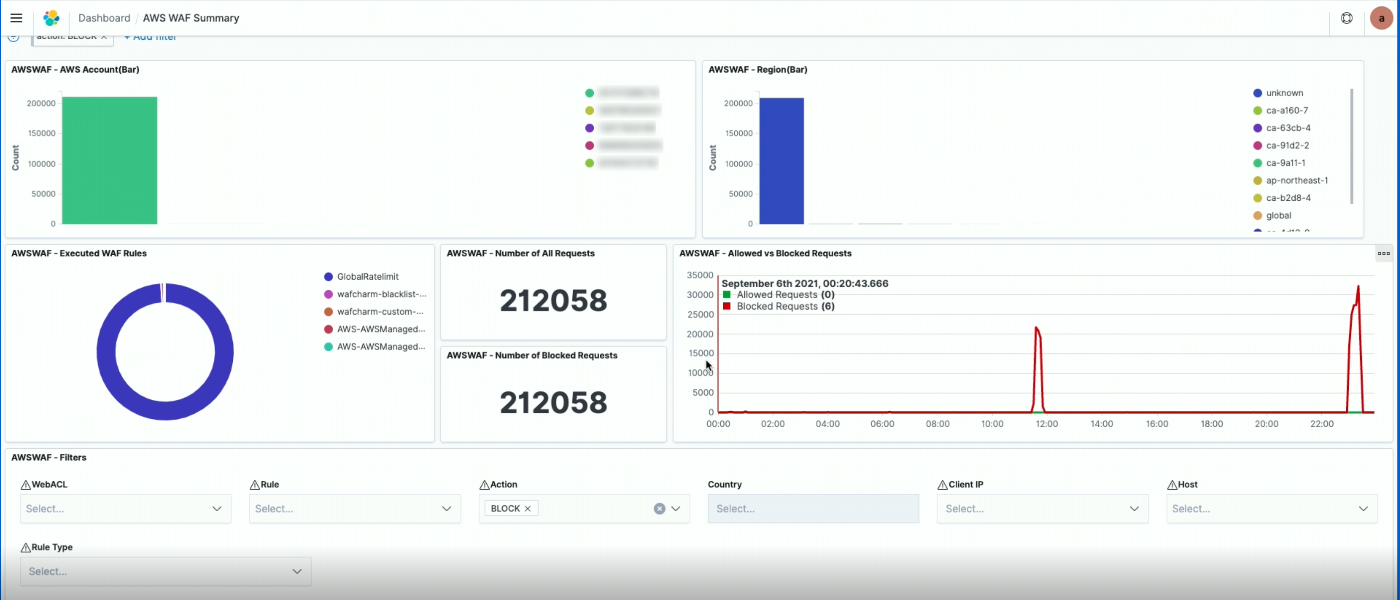
Block している API アクセスが出ていた。ほとんどが Rate limit だったので更に絞ると、Source IP は 2 つだけだったことがわかった。( uniq IP のウィジェットやアクセスのテーブルビューで確認)
実際にアクセスを見てみると、顧客が開発環境で API を使用しており、Rate limit の仕様を知らずに大量にアクセスしてしまっていたことが判明した。よって、個別に顧客に連絡を入れて調整した。
DLQ の回復処理
Flow Log などが大量に発生すると、es-loader がパンクしてしまう。
これを自動的に取り込むようにはなっておらず CLI で手動リカバリしているので、自動化が今後の展望
振り返りの実施
ログ全体を確認して振り返っていく作業を weekly でやっているが daily にしたい。
チームメンバーの「気づく能力」「トリアージの能力」を平均的に引き上げていきたい。
短期的なハンドリングはその場でやっているが、恒久的な対策が必要なものに関してはきちんと tracking できるようにしたい。
「同じことをやっている」ではだめなので、自動化可能なものは自動化するなど、普段の業務の在り方も update していく
今後の展望
「真の脅威」への対処をしていきたい。
Public API に対する攻撃は、ある。仕様を swagger で公開しているので、Format の問題や WAF で防御できるものはいいが、認証を通したアクセスで他のサービス利用者の情報を奪取しようとするアクセスが発生している。
DoS への耐性をテストするような攻撃も観測している。
設定ミスによるインシデントを防止する。("Cloud Security Posture Management" と言うらしい
index 管理のスライドに関して、理解に必要な知識を読み解く
Storage Tier
S3 のストレージクラスのような話。あるいは、UltraWarm に関しては RedShift Spectrum に近いのかもしれない
※詳しい技術的な内訳はもちろん異なるが、本質的には S3 に配置したデータをアーカイブ処理として Glacier に変更するようなものだと言えそう。
Hot, UltraWarm, Cold の 3つが存在。
UltraWarm は 2020/05 に GA している
Nitro ベースのインスタンスと S3 を組み合わせて良いようにしているとかなんとか書いてある。
UltraWarm amplifies the benefits of traditional hot-warm configurations. It uses a combination of Amazon S3 and optimized compute nodes powered by the AWS Nitro System to provide a hot-like experience for aggregations and visualizations.
全部が全部 S3 に逃がす、ということではなく、必要に応じてプリフェッチやキャッシュ、クエリ処理の最適化などを組み合わせているということが書かれている。従来の hot に近いパフォーマンスすら出せる場合があるとのこと(これはキャッシュやプリフェッチが最大限有効に機能したユースケースを指していると思われる)
To improve performance, these nodes use granular caching across all layers of the stack, adaptive prefetching, and query processing optimizations to provide similar, or in many cases superior performance to traditional warm nodes which rely on high density local storage.

↓ここはちょっと意味が分からなかった。
You can selectively attach the cold data to your existing UltraWarm nodes in seconds and gain valuable insights.
Compute/ storage を分離する、という話を前提にしているようだが、一度 Cold にしたデータを UltraWarm ノードにアタッチすることで一時的な分析ニーズに対しても高速に分析ができると謳っている、ように読める(実際、Kibana ダッシュボードからこの操作は行えるらしい)。よって、UltraWarm を利用することで、気軽に Cold storage にデータを移していく運用ができる=分析のユーザー体験を落とさずコストが最適化できる、ということを言っているのだろうか。
- Warm -> Cold へのストレージ移行は数秒である
- Cold storage のデータであっても、UltraWarm ノードにアタッチすることでオンデマンドな分析が行える
- UltraWarm ノードに接続されている場合は、Cold であっても(速度的な面で)Warm data と変わらない体験が得られる
余談:
ストレージを区別してインデックス管理する機能は本家 ES においても 6.7 から提供が開始されている。ILM (Index Lifecycle Management) という機能で、どうも S3 のそれとイメージは近い様子。
hot -> warm に入るタイミングと、 warm -> cold に入るタイミングをポリシーとして記述する。ここでいくつかの「アクション」が利用可能。
- Force merge ... index の最適化
- Freeze ... クラスタ内の mem pressure を低減するため(?) に使用
- etc.. / 詳しくは document 参照