Open7
exo の AI クラスターで遊ぶ
exo とは?
Run your own AI cluster at home with everyday devices.
インストール
git clone https://github.com/exo-explore/exo.git
cd exo
pip install -e .
source install.sh
起動
exo
構成
1台
- Mac mini (M4 Pro, 24GB)

→ 11.44 TFLOPS
3台
- Mac mini (M4 Pro, 24GB)
- MacBook Pro (M2, 16GB)
- MacBook Pro (M2, 16GB)
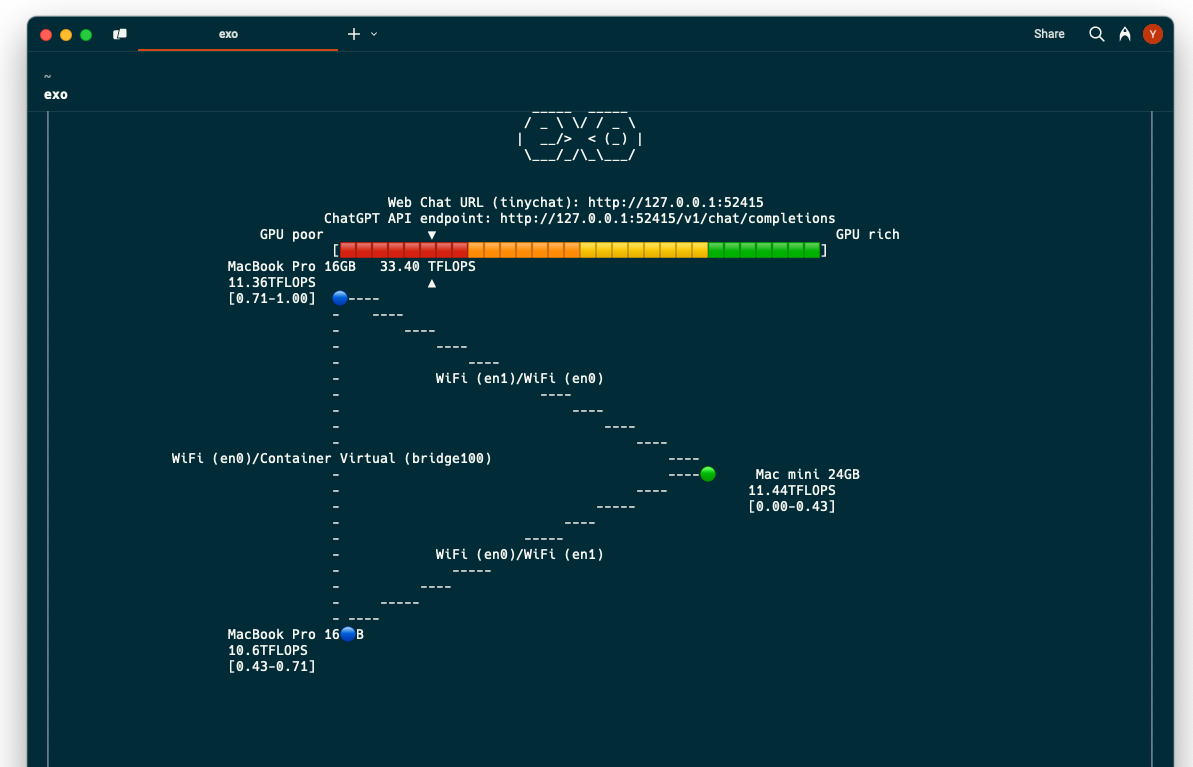
→ 33.40 TFLOPS
tinychat
1 台 (Mac mini) で試す
簡単なプロンプトを試す。
Llama 3.2 1B - 0.49 SEC TO FIRST TOKEN 109.0 TOKENS/SEC 916 TOKENS
Llama 3.2 1B - 0.79 SEC TO FIRST TOKEN 103.2 TOKENS/SEC 1837 TOKENS
Llama 3.2 1B - 1.34 SEC TO FIRST TOKEN 85.5 TOKENS/SEC 2773 TOKENS
2 台 (Mac mini + MacBook Pro) で試す
Generating... で考え込んでしまって、完了しない。
なんでだろう?ネットワークとかか?
→ Thunderboltブリッジでつないだら動き始めた?(これが本当に原因か不明)
簡単なプロンプトを試す。
Llama 3.2 1B - 0.77 SEC TO FIRST TOKEN 28.0 TOKENS/SEC 861 TOKENS
Llama 3.2 1B - 1.17 SEC TO FIRST TOKEN 28.5 TOKENS/SEC 1857 TOKENS
Llama 3.2 1B - 2.07 SEC TO FIRST TOKEN 24.7 TOKENS/SEC 2904 TOKENS
何か 2 台にして、遅くなっている……?これじゃ意味ない?
exo optimally splits up models based on the current network topology and device resources available. This enables you to run larger models than you would be able to on any single device.
単体では動かせないモデルを動かせるようになる、ということなのかな。
16GBのメモリのマシンでギリギリ使用できないLLMは?
...
結論
「ギリギリ使用できないLLM」は、RAMが16GBではほぼ足りないが、スワップを大量に使えば動く可能性があるもの。
具体的には:
✅ 動く可能性があるが、実用的でない
- LLaMA 2 30B(4-bit量子化)
- Mixtral 8x7B(4エキスパート, 4-bit量子化)
- GPT-NeoX 20B(4-bit量子化)
🚫 ほぼ確実に動かない
- LLaMA 2 65B(4-bit量子化)
- GPT-3 175B(どんな量子化でも無理)
- Claude 2以上のモデル(オープン版なしだが、仮にあっても無理)
結論:
16GBでは「30B級以上のモデル」は基本的に動かない。
物理メモリを32GB以上に増設するか、VRAM 24GB以上のGPUを使うのが理想的。
MacBook Pro (メモリ16GB) で、32Bのモデルを試す
モデル: Qweb 2.5 coder 32B
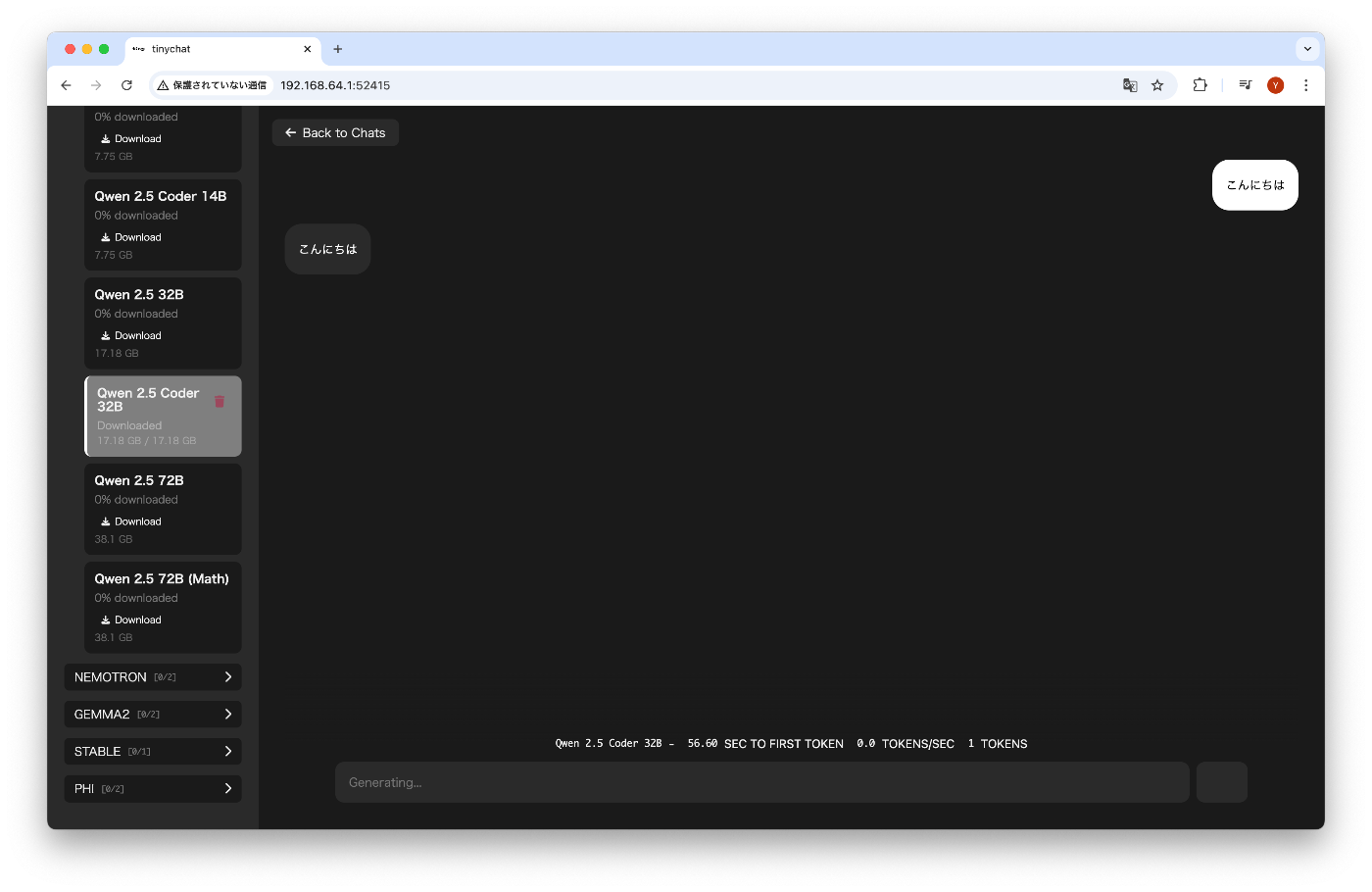
一応、動いてはいるようだが、なかなか酷しい状態。これが改善されるはず?
Mac 3 台で、32Bのモデルを試す
構成

モデル: Qweb 2.5 coder 32B
Qwen 2.5 Coder 32B - 3.69 SEC TO FIRST TOKEN 5.2 TOKENS/SEC 943 TOKENS
1台の場合から改善された。何とか使えるレベルなのだろうか。