ESPnetのWindows CPU推論環境の構築
以下のスクリプトを実行できる環境を構築します。
from espnet2.bin.tts_inference import Text2Speech
import soundfile
text2speech = Text2Speech.from_pretrained("kan-bayashi/ljspeech_vits")
text = "Hello, this is a text-to-speech test. Does my speech sound good?"
speech = text2speech(text)["wav"]
soundfile.write("output.wav", speech.numpy(), text2speech.fs, "PCM_16")
2025年7月のESPnet公式サイトでは、windows/python3.10/pip/pytorch2.6.0のCIテストが通っています。この環境を構築していきたいと思います。

Python 3.10をインストールします。
pyenv install 3.10
ESPnetはnumpy 1.24よりも古いバージョンを求めるので
専用の仮想環境を作ったほうがいいです。
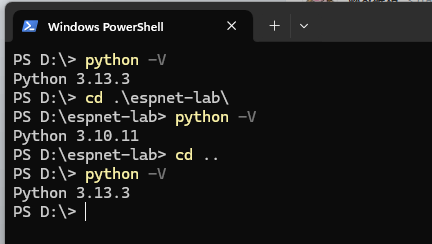
mkdir espnet-lab
cd espnet-lab
pyenv local 3.10
パソコンにインストールしたPythonのバージョンを確認します。
> pyenv versions
* 3.10.11 (set by D:\espnet-lab\.python-version)
3.13.3
PowerShell(VSCodeのターミナル画面を使う場合はVSCode)を再起動した後、espnet-labディレクトリに入ったら、Pythonのバージョンは自動的に3.10に変わります。
仮想環境を作ります。
python -m venv .venv
PowerShellで仮想環境に入ります。
PS D:\espnet-lab> .\.venv\Scripts\activate
(.venv) PS D:\espnet-lab>
PyThorch 2.6.0をインストールします。
(.venv) PS D:\espnet-lab> pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cpu
Looking in indexes: https://download.pytorch.org/whl/cpu
Collecting torch==2.6.0
Obtaining dependency information for torch==2.6.0 from https://download.pytorch.org/whl/cpu/torch-2.6.0%2Bcpu-cp310-cp310-win_amd64.whl.metadata
Downloading https://download.pytorch.org/whl/cpu/torch-2.6.0%2Bcpu-cp310-cp310-win_amd64.whl.metadata (28 kB)
Collecting torchvision==0.21.0
Obtaining dependency information for torchvision==0.21.0 from https://download.pytorch.org/whl/cpu/torchvision-0.21.0%2Bcpu-cp310-cp310-win_amd64.whl.metadata
Downloading https://download.pytorch.org/whl/cpu/torchvision-0.21.0%2Bcpu-cp310-cp310-win_amd64.whl.metadata (6.3 kB)
Collecting torchaudio==2.6.0
Obtaining dependency information for torchaudio==2.6.0 from https://download.pytorch.org/whl/cpu/torchaudio-2.6.0%2Bcpu-cp310-cp310-win_amd64.whl.metadata
Downloading https://download.pytorch.org/whl/cpu/torchaudio-2.6.0%2Bcpu-cp310-cp310-win_amd64.whl.metadata (6.7 kB)
Collecting typing-extensions>=4.10.0
Obtaining dependency information for typing-extensions>=4.10.0 from https://download.pytorch.org/whl/typing_extensions-4.12.2-py3-none-any.whl.metadata
Downloading https://download.pytorch.org/whl/typing_extensions-4.12.2-py3-none-any.whl.metadata (3.0 kB)
Discarding https://download.pytorch.org/whl/typing_extensions-4.12.2-py3-none-any.whl#sha256=04e5ca0351e0f3f85c6853954072df659d0d13fac324d0072316b67d7794700d (from https://download.pytorch.org/whl/cpu/typing-extensions/): Requested typing-extensions>=4.10.0 from https://download.pytorch.org/whl/typing_extensions-4.12.2-py3-none-any.whl#sha256=04e5ca0351e0f3f85c6853954072df659d0d13fac324d0072316b67d7794700d (from torch==2.6.0) has inconsistent Name: expected 'typing-extensions', but metadata has 'typing_extensions'
ERROR: Could not find a version that satisfies the requirement typing-extensions>=4.10.0 (from torch) (from versions: 4.4.0, 4.8.0, 4.9.0, 4.12.2)
ERROR: No matching distribution found for typing-extensions>=4.10.0
typing-extensionsの問題はpipを更新することで解決できました。
(.venv) PS D:\espnet-lab> python -m pip install --upgrade pip
Requirement already satisfied: pip in d:\espnet-lab\.venv\lib\site-packages (23.0.1)
Collecting pip
Downloading pip-25.1.1-py3-none-any.whl (1.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.8/1.8 MB 1.2 MB/s eta 0:00:00
Installing collected packages: pip
Attempting uninstall: pip
Found existing installation: pip 23.0.1
Uninstalling pip-23.0.1:
Successfully uninstalled pip-23.0.1
Successfully installed pip-25.1.1
pipでESPnetをインストールします。
(.venv) PS D:\espnet-lab> pip install espnet
Collecting espnet
Using cached espnet-202412-py3-none-any.whl.metadata (70 kB)
...
Downloading espnet-202412-py3-none-any.whl (2.0 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.0/2.0 MB 1.3 MB/s eta 0:00:00
...
Visual C++ 14.0以上もインストールする必要です。じゃないとpip install espnetの時にctc-segmentationがビルドできなくて失敗します。
wavファイルを出力するために、soundfileもインストールします。
pip install soundfile
ネット上の学習済みモデルを利用するために、espnet_model_zooをインストールします。
pip install espnet_model_zoo
NLTKについて
(.venv) PS D:\espnet-lab> python .\tts.py
Failed to import Flash Attention, using ESPnet default: No module named 'flash_attn'
[nltk_data] Downloading package averaged_perceptron_tagger to
[nltk_data] C:\Users\zzxia\AppData\Roaming\nltk_data...
[nltk_data] Unzipping taggers\averaged_perceptron_tagger.zip.
[nltk_data] Downloading package cmudict to
[nltk_data] C:\Users\zzxia\AppData\Roaming\nltk_data...
[nltk_data] Unzipping corpora\cmudict.zip...
...
(.venv) PS D:\espnet-lab> python .\tts.py
Failed to import Flash Attention, using ESPnet default: No module named 'flash_attn'
[nltk_data] Downloading package averaged_perceptron_tagger to
[nltk_data] C:\Users\zzxia\AppData\Roaming\nltk_data...
[nltk_data] Unzipping taggers\averaged_perceptron_tagger.zip.
[nltk_data] Downloading package cmudict to
[nltk_data] C:\Users\zzxia\AppData\Roaming\nltk_data...
[nltk_data] Unzipping corpora\cmudict.zip.
https://zenodo.org/record/5443814/files/tts_train_vits_raw_phn_tacotron_g2p_en_no_space_train.total_count.ave.zip?download=1: 0%| | 1.21M/356M [00:55<7:50:46, 1
ダウンロードが途中に切ってしまったらまた最初からダウンロードしないといけないです。
(.venv) PS D:\espnet-lab> python .\tts.py
Failed to import Flash Attention, using ESPnet default: No module named 'flash_attn'
[nltk_data] Downloading package averaged_perceptron_tagger to
[nltk_data] C:\Users\zzxia\AppData\Roaming\nltk_data...
[nltk_data] Unzipping taggers\averaged_perceptron_tagger.zip.
[nltk_data] Downloading package cmudict to
[nltk_data] C:\Users\zzxia\AppData\Roaming\nltk_data...
[nltk_data] Unzipping corpora\cmudict.zip.
https://zenodo.org/record/5443814/files/tts_train_vits_raw_phn_tacotron_g2p_en_no_space_train.total_count.ave.zip?download=1: 20%|▏| 69.5M/356M [43:52<3:01:05, 2
Traceback (most recent call last):
File "D:\espnet-lab\.venv\lib\site-packages\urllib3\response.py", line 779, in _error_catcher
yield
File "D:\espnet-lab\.venv\lib\site-packages\urllib3\response.py", line 925, in _raw_read
raise IncompleteRead(self._fp_bytes_read, self.length_remaining)
urllib3.exceptions.IncompleteRead: IncompleteRead(72874300 bytes read, 300755710 more expected)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "D:\espnet-lab\.venv\lib\site-packages\requests\models.py", line 820, in generate
yield from self.raw.stream(chunk_size, decode_content=True)
File "D:\espnet-lab\.venv\lib\site-packages\urllib3\response.py", line 1091, in stream
data = self.read(amt=amt, decode_content=decode_content)
File "D:\espnet-lab\.venv\lib\site-packages\urllib3\response.py", line 1008, in read
data = self._raw_read(amt)
File "D:\espnet-lab\.venv\lib\site-packages\urllib3\response.py", line 903, in _raw_read
with self._error_catcher():
File "D:\pyenv\pyenv-win\versions\3.10.11\lib\contextlib.py", line 153, in __exit__
self.gen.throw(typ, value, traceback)
File "D:\espnet-lab\.venv\lib\site-packages\urllib3\response.py", line 803, in _error_catcher
raise ProtocolError(arg, e) from e
urllib3.exceptions.ProtocolError: ('Connection broken: IncompleteRead(72874300 bytes read, 300755710 more expected)', IncompleteRead(72874300 bytes read, 300755710 more expected))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\espnet-lab\tts.py", line 3, in <module>
text2speech = Text2Speech.from_pretrained("kan-bayashi/ljspeech_vits")
File "D:\espnet-lab\.venv\lib\site-packages\espnet2\bin\tts_inference.py", line 277, in from_pretrained
kwargs.update(**d.download_and_unpack(model_tag))
File "D:\espnet-lab\.venv\lib\site-packages\espnet_model_zoo\downloader.py", line 399, in download_and_unpack
filename = self.download(url, quiet=quiet)
File "D:\espnet-lab\.venv\lib\site-packages\espnet_model_zoo\downloader.py", line 340, in download
download(url, outdir / filename, quiet=quiet)
File "D:\espnet-lab\.venv\lib\site-packages\espnet_model_zoo\downloader.py", line 84, in download
for chunk in response.iter_content(chunk_size=chunk_size):
File "D:\espnet-lab\.venv\lib\site-packages\requests\models.py", line 822, in generate
raise ChunkedEncodingError(e)
requests.exceptions.ChunkedEncodingError: ('Connection broken: IncompleteRead(72874300 bytes read, 300755710 more expected)', IncompleteRead(72874300 bytes read, 300755710 more expected))
(.venv) PS D:\espnet-lab> python .\tts.py
Failed to import Flash Attention, using ESPnet default: No module named 'flash_attn'
https://zenodo.org/record/5443814/files/tts_train_vits_raw_phn_tacotron_g2p_en_no_space_train.total_count.ave.zip?download=1: 1%| | 3.30M/356M [01:11<2:08:48, 4
これはNLTKのエラーじゃなくて、モデルダウンロード時のエラーみたいです。
ブラウザからダウンロードするなら、途中から再開できます。
https://zenodo.org/record/5443814/files/tts_train_vits_raw_phn_tacotron_g2p_en_no_space_train.total_count.ave.zip?download=1
プリトレインモデルのダウンロード
ダウンロード後の格納場所
>>> from espnet_model_zoo.downloader import ModelDownloader
>>> d = ModelDownloader()
>>> d
<espnet_model_zoo.downloader.ModelDownloader object at 0x000001C9467469E0>
>>> d. # TABを数回押す
d.cachedir d.data_frame d.get_data_frame() d.query(
d.clean_cache( d.download( d.get_url( d.unpack_local_file(
d.csv d.download_and_unpack( d.huggingface_download( d.update_model_table()
>>> d.cachedir
WindowsPath('D:/espnet-lab/.venv/lib/site-packages/espnet_model_zoo')
>>>


モデルをダウンロードする途中にnltk_dataディレクトリを削除すると
(.venv) PS D:\espnet-lab> python tts.py
Failed to import Flash Attention, using ESPnet default: No module named 'flash_attn'
[nltk_data] Downloading package averaged_perceptron_tagger to
[nltk_data] C:\Users\zzxia\AppData\Roaming\nltk_data...
[nltk_data] Unzipping taggers\averaged_perceptron_tagger.zip.
[nltk_data] Downloading package cmudict to
[nltk_data] C:\Users\zzxia\AppData\Roaming\nltk_data...
[nltk_data] Unzipping corpora\cmudict.zip.
https://zenodo.org/record/5443814/files/tts_train_vits_raw_phn_tacotron_g2p_en_no_space_train.total_count.ave.zip?download=1: 100%|█| 356M/356M [14:49<00:00, 420kB/s]
D:\espnet-lab\.venv\lib\site-packages\espnet_model_zoo\downloader.py:364: UserWarning: Not validating checksum
warnings.warn("Not validating checksum")
D:\espnet-lab\.venv\lib\site-packages\torch\nn\utils\weight_norm.py:143: FutureWarning: `torch.nn.utils.weight_norm` is deprecated in favor of `torch.nn.utils.parametrizations.weight_norm`.
WeightNorm.apply(module, name, dim)
D:\espnet-lab\.venv\lib\site-packages\espnet2\gan_tts\vits\monotonic_align\__init__.py:19: UserWarning: Cython version is not available. Fallback to 'EXPERIMETAL' numba version. If you want to use the cython version, please build it as follows: `cd espnet2/gan_tts/vits/monotonic_align; python setup.py build_ext --inplace`
warnings.warn(
WARNING:root:It seems weight norm is not applied in the pretrained model but the current model uses it. To keep the compatibility, we remove the norm from the current model. This may cause unexpected behavior due to the parameter mismatch in finetuning. To avoid this issue, please change the following parameters in config to false:
- discriminator_params.follow_official_norm
- discriminator_params.scale_discriminator_params.use_weight_norm
- discriminator_params.scale_discriminator_params.use_spectral_norm
See also:
- https://github.com/espnet/espnet/pull/5240
- https://github.com/espnet/espnet/pull/5249
Traceback (most recent call last):
File "D:\espnet-lab\tts.py", line 5, in <module>
speech = text2speech(text)["wav"]
File "D:\espnet-lab\.venv\lib\site-packages\torch\utils\_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
File "D:\espnet-lab\.venv\lib\site-packages\espnet2\bin\tts_inference.py", line 173, in __call__
text = self.preprocess_fn("<dummy>", dict(text=text))["text"]
File "D:\espnet-lab\.venv\lib\site-packages\espnet2\train\preprocessor.py", line 548, in __call__
data = self._text_process(data)
File "D:\espnet-lab\.venv\lib\site-packages\espnet2\train\preprocessor.py", line 483, in _text_process
tokens = self.tokenizer.text2tokens(text)
File "D:\espnet-lab\.venv\lib\site-packages\espnet2\text\phoneme_tokenizer.py", line 623, in text2tokens
tokens = self.g2p(line)
File "D:\espnet-lab\.venv\lib\site-packages\espnet2\text\phoneme_tokenizer.py", line 260, in __call__
phones = self.g2p(text)
File "D:\espnet-lab\.venv\lib\site-packages\g2p_en\g2p.py", line 162, in __call__
tokens = pos_tag(words) # tuples of (word, tag)
File "D:\espnet-lab\.venv\lib\site-packages\nltk\tag\__init__.py", line 168, in pos_tag
tagger = _get_tagger(lang)
File "D:\espnet-lab\.venv\lib\site-packages\nltk\tag\__init__.py", line 110, in _get_tagger
tagger = PerceptronTagger()
File "D:\espnet-lab\.venv\lib\site-packages\nltk\tag\perceptron.py", line 183, in __init__
self.load_from_json(lang)
File "D:\espnet-lab\.venv\lib\site-packages\nltk\tag\perceptron.py", line 273, in load_from_json
loc = find(f"taggers/averaged_perceptron_tagger_{lang}/")
File "D:\espnet-lab\.venv\lib\site-packages\nltk\data.py", line 579, in find
raise LookupError(resource_not_found)
LookupError:
**********************************************************************
Resource averaged_perceptron_tagger_eng not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('averaged_perceptron_tagger_eng')
For more information see: https://www.nltk.org/data.html
Attempted to load taggers/averaged_perceptron_tagger_eng/
Searched in:
- 'C:\\Users\\zzxia/nltk_data'
- 'D:\\espnet-lab\\.venv\\nltk_data'
- 'D:\\espnet-lab\\.venv\\share\\nltk_data'
- 'D:\\espnet-lab\\.venv\\lib\\nltk_data'
- 'C:\\Users\\zzxia\\AppData\\Roaming\\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
**********************************************************************
(.venv) PS D:\espnet-lab>
もう一度実行しても同じエラーが出ます。しかもダウンロードは再開しません。
(.venv) PS D:\espnet-lab> python tts.py
Failed to import Flash Attention, using ESPnet default: No module named 'flash_attn'
D:\espnet-lab\.venv\lib\site-packages\torch\nn\utils\weight_norm.py:143: FutureWarning: `torch.nn.utils.weight_norm` is deprecated in favor of `torch.nn.utils.parametrizations.weight_norm`.
WeightNorm.apply(module, name, dim)
D:\espnet-lab\.venv\lib\site-packages\espnet2\gan_tts\vits\monotonic_align\__init__.py:19: UserWarning: Cython version is not available. Fallback to 'EXPERIMETAL' numba version. If you want to use the cython version, please build it as follows: `cd espnet2/gan_tts/vits/monotonic_align; python setup.py build_ext --inplace`
warnings.warn(
WARNING:root:It seems weight norm is not applied in the pretrained model but the current model uses it. To keep the compatibility, we remove the norm from the current model. This may cause unexpected behavior due to the parameter mismatch in finetuning. To avoid this issue, please change the following parameters in config to false:
- discriminator_params.follow_official_norm
- discriminator_params.scale_discriminator_params.use_weight_norm
- discriminator_params.scale_discriminator_params.use_spectral_norm
See also:
- https://github.com/espnet/espnet/pull/5240
- https://github.com/espnet/espnet/pull/5249
Traceback (most recent call last):
File "D:\espnet-lab\tts.py", line 5, in <module>
speech = text2speech(text)["wav"]
File "D:\espnet-lab\.venv\lib\site-packages\torch\utils\_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
File "D:\espnet-lab\.venv\lib\site-packages\espnet2\bin\tts_inference.py", line 173, in __call__
text = self.preprocess_fn("<dummy>", dict(text=text))["text"]
File "D:\espnet-lab\.venv\lib\site-packages\espnet2\train\preprocessor.py", line 548, in __call__
data = self._text_process(data)
File "D:\espnet-lab\.venv\lib\site-packages\espnet2\train\preprocessor.py", line 483, in _text_process
tokens = self.tokenizer.text2tokens(text)
File "D:\espnet-lab\.venv\lib\site-packages\espnet2\text\phoneme_tokenizer.py", line 623, in text2tokens
tokens = self.g2p(line)
File "D:\espnet-lab\.venv\lib\site-packages\espnet2\text\phoneme_tokenizer.py", line 260, in __call__
phones = self.g2p(text)
File "D:\espnet-lab\.venv\lib\site-packages\g2p_en\g2p.py", line 162, in __call__
tokens = pos_tag(words) # tuples of (word, tag)
File "D:\espnet-lab\.venv\lib\site-packages\nltk\tag\__init__.py", line 168, in pos_tag
tagger = _get_tagger(lang)
File "D:\espnet-lab\.venv\lib\site-packages\nltk\tag\__init__.py", line 110, in _get_tagger
tagger = PerceptronTagger()
File "D:\espnet-lab\.venv\lib\site-packages\nltk\tag\perceptron.py", line 183, in __init__
self.load_from_json(lang)
File "D:\espnet-lab\.venv\lib\site-packages\nltk\tag\perceptron.py", line 273, in load_from_json
loc = find(f"taggers/averaged_perceptron_tagger_{lang}/")
File "D:\espnet-lab\.venv\lib\site-packages\nltk\data.py", line 579, in find
raise LookupError(resource_not_found)
LookupError:
**********************************************************************
Resource averaged_perceptron_tagger_eng not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('averaged_perceptron_tagger_eng')
For more information see: https://www.nltk.org/data.html
Attempted to load taggers/averaged_perceptron_tagger_eng/
Searched in:
- 'C:\\Users\\zzxia/nltk_data'
- 'D:\\espnet-lab\\.venv\\nltk_data'
- 'D:\\espnet-lab\\.venv\\share\\nltk_data'
- 'D:\\espnet-lab\\.venv\\lib\\nltk_data'
- 'C:\\Users\\zzxia\\AppData\\Roaming\\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
**********************************************************************
espnetを再インストールしても変化なし。
nltkが原因だお思います。
(.venv) PS D:\espnet-lab> pip show nltk
Name: nltk
Version: 3.9.1
Summary: Natural Language Toolkit
Home-page: https://www.nltk.org/
Author: NLTK Team
Author-email: nltk.team@gmail.com
License: Apache License, Version 2.0
Location: d:\espnet-lab\.venv\lib\site-packages
Requires: click, joblib, regex, tqdm
Required-by: espnet, g2p-en
nltkとespnetを再インストールしても変化なし。
もしかしてNLTKを必要とするのはLJSpeechです。
try:
# For phoneme conversion, use https://github.com/Kyubyong/g2p.
from g2p_en import G2p
f_g2p = G2p()
f_g2p("")
except ImportError:
raise ImportError(
"g2p_en is not installed. please run `. ./path.sh && pip install g2p_en`."
)
except LookupError:
# NOTE: we need to download dict in initial running
nltk.download("punkt")
g2p_enをimportする時にLookupErrorが発生したらNLTKデータをダウンロードします。
使っている"kan-bayashi/ljspeech_vits"モデルは上記のソースコードを使っていないが、config.yamlにg2p_en_no_spaceが設定されています。もしかして似たような原因?
g2p: g2p_en_no_space
g2p-enパッケージを再インストールしても変化なし。