
これはなに
こんにちは、障害対応が大好きなもりたです(自己紹介)[1]。
今回は障害対応をするのが大好きなわたし[2]が、障害対応のリーダー(インシデントコマンダー。以降IC)をやる上で気をつけている点を整理します。障害対応の進め方ってなんか直感みたいになりがちな上、予期して起こせないので学ぶのも難しいですよね。そこで、こうやったらいい感じですよというのをまとめてみました。
構成
構成
構成は以下です。
- 概論
- 基礎
- コミュニケーション
- 対外的なもの
- 対応チーム内でのもの
- 調査の進め方
はじめに障害対応における論点を整理し、その後基礎的な大切な点、特に大切な2点を紹介するという流れです。
それではやってまいりましょう。
障害対応のインシデントコマンダーで気をつけていること
概論

最初にICの役割や障害対応における論点を抑えましょう[3]。
【改訂新版】システム障害対応の教科書によると、ICの役割は以下の通りです。
主な役割
- 作業担当への実施指示(旗振り)
- 障害対応要員や関連チームの招集・組成、維持(体制構築)
- 顧客、関連チームとのコミュニケーション(窓口)
- 障害の発生と終息の宣言
- 要員のシフト、食事、宿泊(兵站)
- 情報の整理と更新(障害状況ボード)
- 外部向けのオフィシャルな障害報告書作成(レポーティング)
たとえば、監督官庁への報告資料などを含む(【改訂新版】システム障害対応の教科書 P42)
多いなあと思ったのであれば大正解です。ここで大事なのはその多い役割を切り出せること。適宜コミュニケーションリード(以降CL)や実作業担当者に役割を委譲していき、ICは判断に回れると良いです。
また、この役割を見渡したとき、特に重要なのが「コミュニケーション」と「調査の舵取り」の2点です。
今回はこれを整理していきたいと思います。
基礎
コミュニケーションと調査の舵取りの説明に入る前に、障害対応全体で重要なポイントをいくつか整理します。
誤報を恐れず報告する
はじめに「障害かも...?」と思った時点で気軽に共有をしましょう。
わたしは深夜に一人だけ仕事をしていることが多いんですが、周囲が退勤していようが遠慮せずチャンネルメンションを投げたりします。勇気が必要ですが、特に開発者内であれば誤報は全く気にする必要がありません。障害かもと思った時点で共有し、誤報でも堂々としている経験を積むことで度胸はついてくると思います[4]。
対応のフェーズを知る

障害対応にはフェーズが存在します。
フェーズを知っておくと、本来取るべき対応手順が入れ替わって報告が漏れていた、みたいなケースを防げるのでぜひ知っておくと良いです。参考文献から引用します。
- イベントの確認
システムエラーやユーザからの申告(この時点ではシステム障害ではない)。- 検知・事象の確認
システムが本来の機能を果たせていない可能性を検知した時点で、障害対応を開始する。- 業務影響調査
システム障害によってユーザにどんな影響が出ているかを調査する。- 原因調査
システム障害を引き起こしている部位を特定する。なぜそのような状態に至ったかを調査する。- 復旧対応
業務を回復するための手段を実施する。- 本格(恒久)対応
5が暫定的な手段であった場合、本格的な対策を行う(修正版のアプリケーションをリリースする、サーバを保守交換するなど)。- 障害分析・再発防止策
システム障害の類似調査や根本原因を分析し、再発防止を行う。(【改訂新版】システム障害対応の教科書 P35)
なお3, 4は並行して行われることも多いですが、順序としては業務影響調査が優先されます。
また、復旧対応はサービス復旧を指しており、システムの復旧は二の次になります。
役割の委譲
概論でも書きましたが、ICの役割は多岐に及ぶため、適宜役割を切り出して自分は指示に回ります。ICがぱつぱつになると障害対応はうまく進みません。普段からどこまで自分が対応できるか知っておき、この範囲は誰かに任せようと考えておけると良いです。
わたしの場合は実作業と対顧客のCLは人に任せてしまい、自分は状況の整理その他に回ることが多いです。
コミュニケーション
ここからは障害対応の中で重要な要素であるコミュニケーションと調査の舵取りに関して大切な点をまとめていきます。
まずはコミュニケーションの説明をします。「対外的なコミュニケーション」と「障害対応チーム内でのコミュニケーション」に分けて考えます。
対外的なコミュニケーション
対外的なコミュニケーションで大切にしたいのは、障害対応チーム以外のメンバーが障害対応の詳細を知りたいとなったときに情報に辿り着けるような状態を作っておくことです。
そこで重要なのが「障害対応ボードの用意」と「コミュニケーションチャネルの用意」です。
障害対応ボードの用意
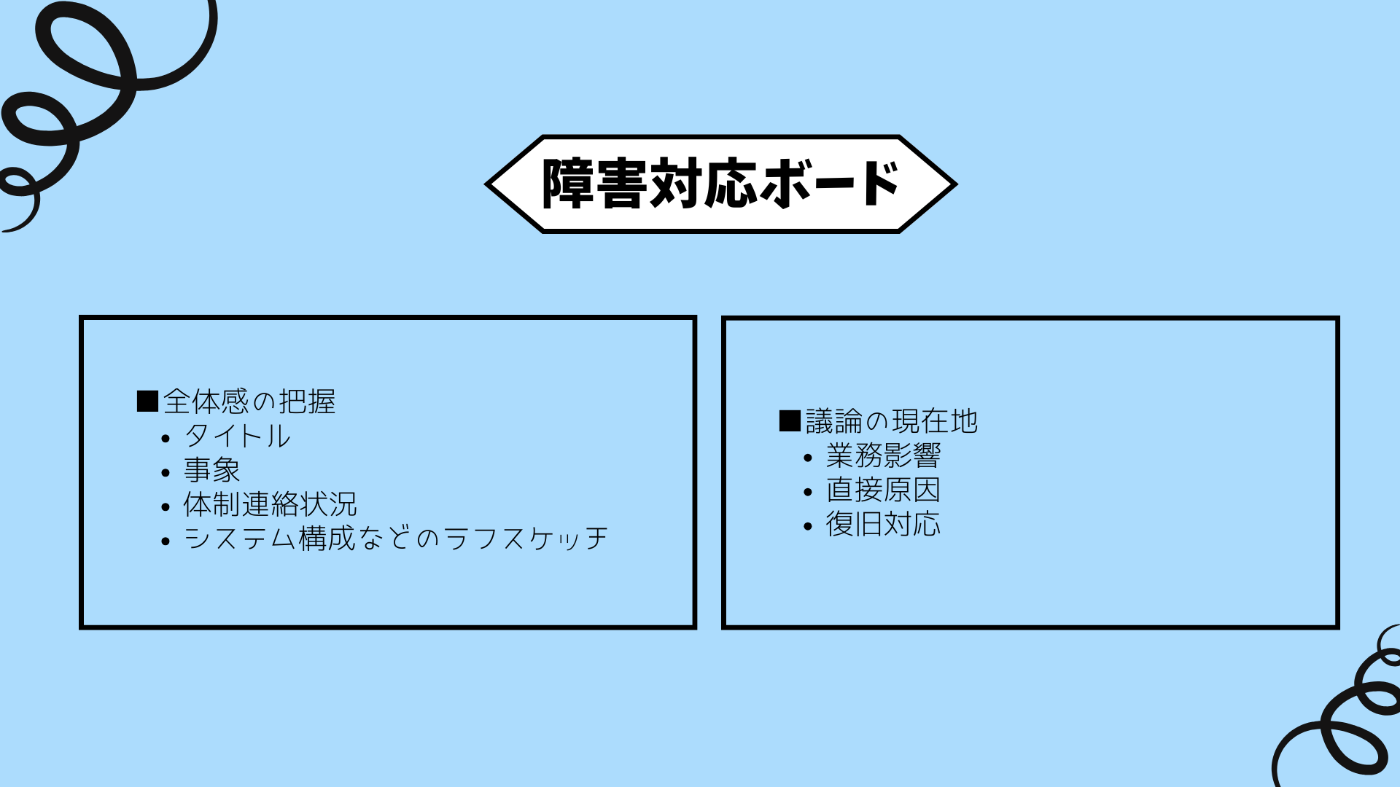
まず「障害対応ボードの用意」ですが、こちらは障害対応の情報がまとまっている資料のことを指します。
【改訂新版】システム障害対応の教科書によると以下の情報をまとめておくと良いようです。
- タイトル
- 事象
- 業務影響・影響範囲
- 直接原因
- 復旧対応
- 体制/連絡状況
- 更新日時
- システム構成と障害原因箇所のラフスケッチ
- 経緯(タイムライン)
(【改訂新版】システム障害対応の教科書 P141)
多いなと思う人のためにもう少し考えてみましょう[5]。
障害状況ボードは基本的にサマリー資料であり、後から障害の状況を把握したい人がさっと見て全体感と現状の論点を把握できるようにするものです。そのため、わかっている事実を整理した上で、現時点で議論がどういう位置まで進んでいるのかを示すことが重要です。
ということを念頭に先ほどのまとめるべき情報を見てみると、以下のふたつにカテゴライズ可能です。
- 全体感の把握
- タイトル、事象、体制連絡状況、システム構成などのラフスケッチ
- 議論の現在地
- 業務影響、直接原因、復旧対応
- ここはフェーズによっては完了して現在地ではなくなる
- 業務影響、直接原因、復旧対応
資料を作る際はこの点に気をつけて作成すると、少し見やすい資料になるかと思います。
また、上記の資料はかっちり作り込む必要はなく、場合によってはSlackのスレッドに同様のものを整理して投稿するだけにとどめることもあります。
コミュニケーションチャネルの用意
そして、次に大切なのが「コミュニケーションチャネルの用意」です。
これは対応しているSlackのスレッドやWeb会議室のリンク、対面MTGなら会議室の部屋番号を明示することです。どこに行けば対応チームに会えるのか示しています。Googleカレンダーに大きく「障害対応」とスケジュールを囲っておき、予定のリンクにそれらの情報を乗せておくと分かりやすいです。
また、障害対応に進捗があった場合や、時間経過のタイミングで状況をブロードキャストできると良いです。
対応チーム内でのコミュニケーション
続いて対応チーム内でのコミュニケーションについて、大切にしている点をまとめます。こちらは4点あり、以下の通りです。
- なんでもいいから喋る
- 全てをテキストにする
- メンバーを議論に乗せる
- 認識齟齬を避ける
それぞれ説明します。
なんでもいいから喋る
障害対応が始まったけど、手がかりがなく沈黙が流れる...みたいなことありませんか? そんなときはICが口火を切りましょう。
障害が発生していると、焦りや不安からなにを喋ったら良いのかわからないことがあります。しかしそこで黙っていても状況は改善しません。分かっていることを全て並べるなど、場を温める努力をしましょう。
また、この際正しいことをいう必要はありません。「AがXXXということは、Bですか?」という発言が間違っていても、「いや、Cじゃないですか?」などメンバーが他の推論をする呼び水となります。
かつ、間違った推論でもよいとICが示すことで、他のメンバーがアイデアを出しやすくなります。意図的に道化を演じることでメンバーの喋りやすい環境を作りましょう。
全てをテキストにする
続いてのポイントは、全てをテキストにすることです。全てをテキストにするというのは、
- 意思決定のログ(議事録)
- 作業のログ
などのことです。
全てをテキストにするメリットはいくつかあり、列挙すると以下の通りです。
- 脳のメモリが解放される
- 人間は文字にすることで脳のメモリを解放できる。演算処理能力を高めるために外部の記憶媒体にデータを吐き出すのはコンピュータも人間も同じ
- 論点の整理になる
- 分かったことやTODOを一覧にすることで、論点のヌケモレを防げる
- 事実レベルの証跡になる
- 作業ログを残すことで証跡をつくれる。あとからその作業について説明したいときも、ログのリンクをとりあえず渡すという手段が使える
また、テキスト化のコツとしては
- メタ情報の付記
- 調査結果、事実、推測、TODO、意思決定などどんな性質のテキストなのかを付記する
- 取捨選択しない
- 取捨選択はあとで障害対応ボードにサマライザする際にやればよいことなので、ダラダラと全て書いてよい
- 得意な人に任せる
- ICをやりながら全てを書くのは大変なので、適宜役割として切り出すのもおすすめ
などが挙げられます。
メンバーを議論に乗せる
障害対応中に議論に追いつけなくなった経験はありませんか?
メンバーが議論から取り残される事態は、障害対応中に最も避けたいポイントです。これが起きると、
- 議論に参加できない人が出ることで、貴重なリソースが減ってしまう
- 議論から離脱する人がいるような議論では、だいたい他の人もすれ違いが発生している
- すれ違ったり理解できていない人がその後の作業を担当することで、さらに効率が悪くなったり二次被害をうむ
上記を避けるために以下を実施しています。
- 議論の節目で定期的に同期する
- 追いつけない人がいる/いないに関わらず、認識合わせのためにまとめる
- 作業担当者が帰って来たら毎回同期する
- 作業していると議論を聞いていないため、議論の現在地がわからなくなる。議論が追えなくなると、脱落する
- 作業担当者が戻ってくるたびに、前回からの進展をまとめて共有する
- 一日のおわりにまとめる
- 対応が複数日に及ぶとき、ICが帰宅する時点でまとめておく
- 翌日に障害対応を続ける際のとっかかりになるし、帰宅後に対応する人が出た場合にも参照できる
認識齟齬を避ける
チーム内コミュニケーション最後のポイントは「認識齟齬を避ける」です。
これは作業担当者から調査結果を受け取るときのポイントなんですが、以下のような事態がよく起きるため注意しています。
- 事実として受け取ったつもりが、作業担当者の推測だった
- 事実と推測を区別しながら受ける
- 結果を受け取ったが、調査方法に問題があり間違っていた
- 調査方法を含めて報告を受け取る
調査の舵取り
続いて、調査の舵取りについて。こちらは3点でまとめます。
問題の切り分けをしながら進める
まず大切なのが、問題となっているコンポーネントがどれなのかわかっていないときに、ざっくりと問題を切り分けながら進めていくことです。
例えば、システムA→B→C→Dとデータが連携されていて、どこかでデータがおかしくなっているとしましょう。このとき、闇雲に探していくのではなく、どこまで検証したから問題はこちら側にあるはず、と安全な範囲と危険な範囲を切り分けていくことが大切です。
また、この問題の切り分けをする際にも事実と推測を区別して進めることが大切なのですが、調査の進展を早めるためにあえて推測レベルで進めることもあります。ただこれは当てずっぽうの推測を許容するという話ではなく、例えば2万件の対象データがあったときに無作為に100件くらい調査してシロならシロと考える、などのことです[6]。
調査をする際は想定する結果を先に考えておく
続いて、調査をする際は、想定する結果を先に考えておくことも大切です。
先ほどの例では、2万件全てを確認するのと、抽出した100件を確認するのとで情報の精度は違えども同じような結果が得られるかもしれません。もしここで確認したいことが原因調査のために重要なら全件を選べば良いですし、重要でないなら一部の確認にとどめておくこともできます。
このように、先にその調査を通しての確認事項を明確にすることで、調査の仕方は変わってきます。
他にも以下のようなことを考えています。
- 解決につながる調査になっているか
- 解決にどれほどどれほど繋がるかによって、やる/やらないやデータの精度を決める
- 想定した結果が得られなかった時どうするか
- 想定した結果が得られないとき、次の一手を想定して取得するデータの種類を変えられる
- いつまで続けるか
- 切り上げて次に進むタイミングを決める。また、時間のかかる調査の実施タイミングを選択できる
調査しないを手段に加える
そして、調査を切り上げることも手段です。これは自前で調査せず知見のある人にヘルプを求めることを言っています。
具体的には他チームのシニアエンジニアだったり、外部サービスが関係しているならサポートの窓口に問い合わせをするなどの手段があります。
おわりに

以上、わたしが障害対応時に気をつけていることでした。
こういうのってインシデントコマンダー以外には関係ないもののように思えますが、障害対応をやっている時は全員がインシデントコマンダーのつもりで動けたほうが精度高く進められます。この記事で紹介した点に気をつけて障害対応を乗り切ってみてもらえると幸いです。
参考文献
-
【改訂新版】システム障害対応の教科書
- めっちゃいい本でした。前半を読むだけでも障害対応でどう振る舞えばいいかのコツがいくつかわかる
-
システム障害対応 実践ガイド
- こちらも良い書籍
-
メモを取れば財産になる
- ぜんぶテキストにすると脳のメモリを解放できます、はこの本から

Discussion