レバテック開発部の前原です。以前はプラットフォームチームとしてマイクロサービスの開発を行っていましたが、開発部の新たな試みにより、事業の特定の問題を解消するチームとして社内の営業支援システムの改修を行っています。
はじめに
レバテックの社内の営業支援システムでは、数多くのステークホルダーからの要望をもとに開発が行われます。ステークホルダーからは「このテーブルにカラムを追加してください」といった具体的な要望が多く寄せられます。開発部ではこれらの要望に対して検討を重ね、要件の調整を行いますが、多くの場合、そのままカラムを追加することが多いです。
カラムの追加によって要望が実現されるかは考慮されますが、データモデリングを通して「モデルにどのような概念を含めるか」の検討は不十分でした。
その結果、本来必要な概念がデータモデルに反映されず、運用で問題をカバーすることになりました。これにより問題の解決がシステム外で行われ、業務フローを理解するのにシステム内外の知識が必要になったため、認知負荷が増加してしまいました。
データモデリングの重要性は部内でも認識されており、勉強会など積極的にインプットが行われています。しかし、書籍で学んだ理論的な知識と実際の経験との間には大きな溝があります。
この溝を埋め、学んだ理論を現場で使えるようにするために、データモデリングがどのように問題解決に寄与するかについての仮説を立て、実践を通じて検証します。
本記事は、その経験をまとめたものです。
データモデリングが解決する問題の仮説
データモデリングの活動を通して、次の4つの効果が得られると仮説を立てました。
1. ドメインへの深い理解とモデルへの反映
データモデリングの活動の過程でヒアリングを行ったり、データモデリングが正しいかの検討を行うため必然的にドメインへの理解が深まると考えました。
2. 問題を解決するモデルの構築
ドメインを深く知ることで問題への解像度が上がり、実際の業務に則したデータモデリングを行うことができる。データモデリングがうまくいくと、そのモデルが問題を解決するものになるという考えでした。
3. システムの認知負荷の軽減
業務の実態に則したデータモデルになるため、データモデルを見るだけで業務内容が把握できるようになり、新規参画者の認知負荷が減ると考えました。
4. 将来の要望に対する機能拡張性
データモデルをうまく抽象化してサブタイプを活用することで、新たな要望が増えてもサブタイプを増やしたり、サブタイプごとに固有の項目を増やすことで、拡張性が上がると考えました。
やったこと
前提条件
レバテックではフリーランス向けのエージェントサービスを運営しており、案件の管理を行なっています。
案件は、企業からフリーランスの需要が生まれた時に案件を作成され、フリーランスエンジニアとのマッチングがされる、または需要がなくなると閉じられます。
データモデリング
案件が開始状態になった時の流入経路と担当者を記録したいという依頼でした。流入経路とは「自社から電話した」や「企業さんからメールがあった」など、案件が開始するに至った要因となる活動や問い合わせのことです。
元の依頼では流入経路マスタを定義し、案件のステータス変更履歴に流入経路マスタのIDと担当者のIDを追加するというものでした。元のデータモデルと変更依頼を反映したデータモデルのイメージを以下に示します。
今回の依頼内容に基づく業務フローでは、案件を作成する際に「自社から電話をした」「企業からメールがあった」といった活動内容を直接入力する形式になっています。
このフローに対して疑問を感じました。具体的には、活動を行う業務と作成の業務は別のタイミングで行われる業務であり、別の関心ごとであると考えたのです。
そのため、業務内容を別途記録し、その業務活動のIDを案件の開始イベントに関連付ける形式にする方が実務に適していると思いました。
実際に「活動履歴」というテーブルが存在し、電話やメールなどのアクションの結果がこのテーブルに記録されています。この活動履歴をそのまま活用できるのではないかと考え、以下の構成を提案します。
初期のデータモデルよりは実態に則したデータモデルになったと思います。
次に、活動履歴を全て同じ概念として扱っていいかという疑問が生じました。この活動履歴は内容問わず全ての活動を扱っており、活動タイプによって必要な項目が異なります。当然、その項目はNullableなカラムになり、活動タイプによって必要な項目のバリデーションはアプリケーションによって担保されています。
たとえばこの活動履歴というテーブルは企業IDとエンジニアIDの両方のIDが存在し、企業IDがnullでない時は企業活動履歴、エンジニアIDがnullでない時はエンジニア活動履歴として扱うような設計になっています。
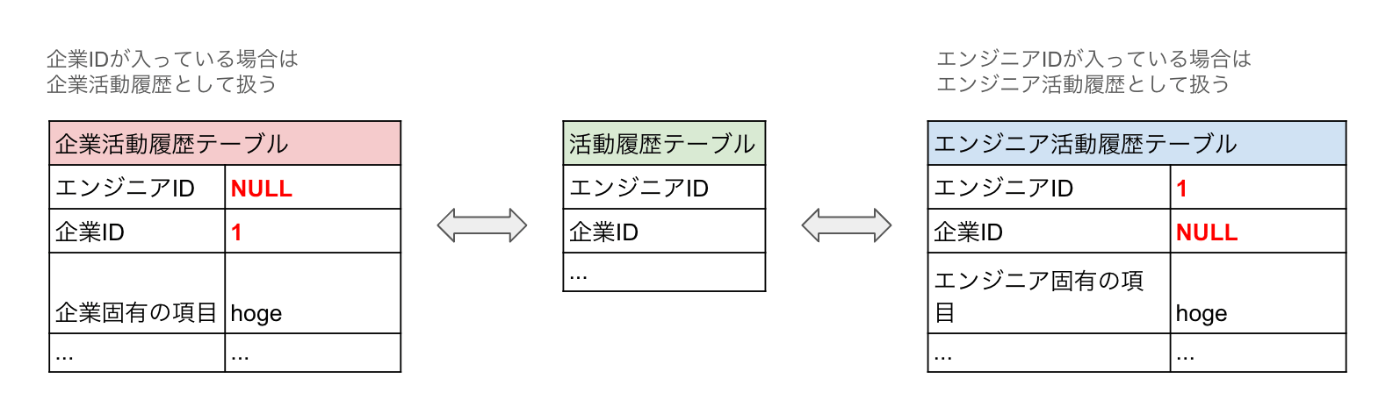
エンジニアIDが入っているか、企業IDが入っているかで扱いが変わる活動履歴テーブル
このような設計には整合性が壊れる危険性など、さまざまなデメリットがあります。また、活動にどのような種類があるのか、実際の業務がテーブル構造から読み取れないことが大きな問題だと考えました。
この問題に対処するため、既存の活動履歴を分割する形で、案件にまつわる活動履歴を新たに定義することにしました。
ここで、さらなる疑問が生じます。それは「自社から電話した」や「企業さんからメールがあった」などの活動を全て同じモデルとして扱っていいかという点です。
元の活動履歴のデータモデルでは、これらの活動をまとめて扱っていました。さらに、アクションとして扱う場合には活動予定日や実施可否のステータスの項目が必須になるなど、活動の種別によって固有の項目があることがわかりました。

レバテックからの能動的なアクションの場合には活動予定日時が入ることがある
そのため、サブタイプとして分割を行いました。サブタイプとして分割を行うことで、異なる概念が別のテーブルになり、それぞれに必要な項目をサブタイプで持つことができるようになります。このアプローチにより、システムの認知負荷が減ると考えました。
最終的には次のようなデータモデルになりました。
データモデリングを行って実際どうだったか?
仮説をもとにモデリングを実際に行ってみました。その仮説がどうだったかの所感を記載します。
1. ドメインへの深い理解
これは半分、仮説通りでした。
というのも当たり前で、データモデリングのためにヒアリングを行ったり、対象領域について学んだり、データモデリングについて頭を悩ませたりすることで、理解が深まるのは当然だと思います。半分と言ったのは、データモデリングを行ってから数ヶ月が経ち、その間に他の開発を行ったり、営業の方々と会話を重ねるうちに、当初のデータモデリングが間違っていることに気がついたからです。
これはデータモデリングの勘所が不足していたことも一因ですが、既存の概念に引っ張られすぎたことも影響しています。既存システムに「活動履歴」というモデルがあったため、すべてが活動の一種であると錯覚していました。
実際は問い合わせが来ることを活動と呼ぶのは不自然なため、アクションとは別な概念として扱うのが妥当だったと考えます。また、この流入経路の種別のことを「流入チャネル」と呼んでおり、活動ではなくチャネルとして抽象化すれば、より実態に即したモデルになったと考えています。
2. 問題を解決するモデルの構築
データモデリングがどのような問題を解決するのかの認識が漠然としすぎていたと思います。これは当然と言えば当然ですが、業務の問題を解決するためには、データモデルの改善だけでなくプロダクト全体で取り組む必要があります。
データモデリングを行うと自然と業務フローも決まると思っていました。今回のケースだと活動履歴が先に作られ、案件発生の際に活動を選択する業務フローになると考えました。そうなれば、実態に即しているし、データも綺麗に溜まるしいいことづくめだと思っていました。
しかし、実態は作業者側にインセンティブがないため、活動履歴の入力が徹底されていませんでした。また、履行管理はスプレッドシートで行い、データを残すためにCSVの一括アップロード機能を使用するなど、既存のシステムに対してオペレーションが最適化されていました。つまり、活動履歴を入力することが喜ばれることではなかったのです。
なぜCSV入力が行われるのか、既存の活動履歴の入力画面が使いにくいのか、もっと根本的にUXや業務フローを改善する必要があると感じました。
つまり、データモデリングそのものが現場の業務を直接解決するわけではなく間接的なものであるということです。
3. 認知負荷の軽減
これは中長期的に振り返らないといけない指標ですが、個人的には減ったと思っています。
実際にモデルの数は増え、ぱっと見の認知負荷は向上したとも思えます。しかし既存のデータモデルの設計では1つのモデルにさまざまな概念が混じっており、特定の概念でしか使わない項目や正規化されておらずにMECEになっていない項目などがあります。これらの概念を分けたことにより、実態に則したモデルとなり、モデルを見ただけでも業務の内容がある程度理解できるようになったと思います。
そのほかの体感としてはクエリの複雑性は上昇したと思いました。トレードオフとして、整合性や認知負荷を減らすことができているとは思います。
4. 将来の要望に対する機能拡張性
これは中長期的に振り返らないといけない指標ですが、まだ追加の要望が来てはいないので答え合わせはできていないですね。
最後に
総じてデータモデリングの理解や事業への理解は深まったが、課題解決までは至っていない所感です。
これはシステムの歴史もあり、データモデリングだけではなく業務プロセスそのものを変える必要があると学びました。あたり前の話ですが、実際に業務を改善するには根本的に業務自体を改善する必要があります。
データモデリングで改善できるものは偶有的な複雑さであり、本質的な複雑さを解消するには業務そのものを変える必要があるためです。しかし、業務そのものを変えるためにはデータモデリングを通じて業務理解を深めることが重要だと感じました。
改めて振り返ってみると、考えてみれば当然の結論に至ることも多くありました。しかし、「考えればわかる」ことと「体験としてわかる」ことの間には大きな違いがあるため、実際に体験できたことは非常に良かったです。
経験を通じて、事業への理解が不足していることや、データモデリングだけでなく根本的な業務改善が必要であることが分かりました。一方でデータモデリングを行ったことで課題が明確に浮き彫りになったので、やって良かったと思います。
おまけ、社内営業支援システムに起きている問題の仮説
社内ユーザーが利用する営業支援システムは、巨大なフォームとカスタムバリデーションによって構成されています。
例えば案件というページに特定のステータスを追加するケースを考えます。その際にステータスは案件ページのフォームの一つして追加され、他の項目との兼ね合いで発生するビジネスルールは、カスタムバリデーションによって制御されます。

そのため利用者は案件の状態に応じて必要な項目を入力し、間違いがあった場合はフォームの送信後にフィードバックされるという体験を強いられています。
また、開発者視点でも認知負荷があると考えます。業務のイベントそのものが記録されずに、業務が行われた結果のみが、リソースに関連づけられるため、画面上の項目がどの業務で使われているか想像しづらい、言い換えるとシステムと業務の対応づけにコストがかかると考えています。
一方で、このようなデータモデルは分析がしやすいというメリットもありますが、このメリットは利用者がデータを正確に入力していることが前提になります。利用者への負担は、入力マニュアルの整備やオンボーディングなどの教育活動によって補われています。つまり、システムはデータ取得に焦点を当てた設計がされており、これが利用者にとっての負担を要求しています。
レバテックでは、多くの従業員が在籍し、社内システムに寄せられる要望も多くにわたります。
その中で、どの開発を優先的に行うのかの判断するために優先度調整MTGを行っています。
多種多様なステークホルダーの要望に対して優先度をつける必要があります。
そのためには共通の軸が必要となり、工数×インパクトという基準で判断されてきました。
その結果、より戦略に有効であるもの=事業インパクトが高いものが優先され、データ入力よりもデータ取得に焦点が寄った設計がなされたのではないかと考えます。
そこに、いろんな要望を叶えたいという工数最小の力学が働き、データモデリングを行わず既存のリソースに項目を追加し続けることで巨大なフォームが出来上がったと考えます。
したがって、工数とインパクトだけでなく、ユーザーの入力しやすさや開発者の認知負荷も考慮して判断する必要があると思いました。この話題はこれだけでも一つの記事になりそうなので、またの機会に取り上げたいと思います。

Discussion