はじめに
レバテック開発部の今井です。
最近は不変なデータやレイヤー化が重視されるようになりました。
それによって、カプセル化が有効な領域が狭くなったように感じています。
この記事では、どうしてカプセル化の有効な領域が減り、それによって何が起こるのかを説明していきます。
本記事の対象アプリケーション
本記事の対象は業務アプリケーションのバックエンドです。
ゲームや組み込み、フロントエンドは本記事の対象外です。
本記事のオブジェクトとモジュールの意味
本記事ではオブジェクトとモジュールを次の意味で使います。
- オブジェクト : 1クラスや1インスタンスのこと。
- モジュール : ある機能を提供するために協働し、一定の独立性を持ったオブジェクトのまとまりのこと。
TL;DR
- 不変性とレイヤー化により、カプセル化の概念とその適用範囲が変化しています。
- オブジェクト内に振る舞いを持たせる必然性が低下しています。
- オブジェクトの役割は、型による意味付けやデータ整合性の保持などの有効性はあります。
- イベントストーミングなどの手法が今後は重要かもしれません
- モジュールレベルでのカプセル化は、システムの柔軟性と変更容易性を高めるために依然として価値があります
カプセル化の崩壊
カプセル化とは?
カプセル化と一言でいっても複数の解釈があります。[1]
- 情報の隠蔽化。実装上、オブジェクトのプロパティを private にすること。
- 振る舞いと情報をひとまとめにすること。実装上、プロパティとメソッドがあり、外部公開すべきものが public になっているオブジェクトのこと。
本記事では適宜どちらかの意味でカプセル化という用語を使います。
両者ともに、オブジェクトレベルのカプセル化はレイヤ化とデータの不変性によって崩壊または実質的な意味を失ったと考えています。
データ不変性と副作用の排除によって振る舞いをカプセル化する意味が減る
データの不変性と副作用の排除は、コードの予測可能性と信頼性を高める関数型プログラミングの核心です。
これらの原則を採用すると、オブジェクト指向プログラミング(以後、OOP)のメソッドの役割に影響を与えます。
不変性はオブジェクトの状態が一度定義されると変更されないことを意味し、副作用の排除は関数が外部状態に依存せず、同じ入力に対して一貫した出力を返すことを保証します。
これにより、オブジェクトの状態を変更するメソッドがなくなります。さらに、副作用を排除するため、DB呼び出しなどの外部状態との相互作用を伴うメソッドも制限されます。
以下のオブジェクト内でデータ可変させるコードはchangeNameメソッドで値を変更しています。一方で、値を不変にしたコードの場合、createNewNameメソッドで新しいUserを返しています。このとき、オブジェクトがUserの状態を管理する機能がなくなっています。
結果として、振る舞いと情報を一体化させるという意味でのカプセル化の重要性は相対的に低下します。
class User {
private name: string;
constructor(name: string) {
this.name = name;
}
public changeName(newName: string): void {
this.name = newName;
}
public getName(): string {
return this.name;
}
}
class User {
readonly name: string; // 不変性を保証
constructor(name: string) {
this.name = name;
}
public createNewName(newName: string): User {
return new User(newName); // 新しいインスタンスを返す
}
public getName(): string {
return this.name;
}
}
レイヤ化によってカプセル化ができなくなる
副作用をドメインモデルのオブジェクトから排除することは、アーキテクチャのレイヤー分離を促進します。
外部入出力を含む副作用は、一般的にアプリケーションのインフラストラクチャ層に隔離されます。これにより、ビジネスロジックが外部の状態に依存せずに再利用可能で、テストしやすいものになります。
データアクセスのために出力時に情報隠蔽ができなくなる
ビジネス上のデータはほとんどが次の理由から外部との入出力が必要です。
- データをDBやファイルに永続化する必要がある
- メール等で通知する必要がある
- 取り扱うデータがキャッシュに乗せきれない
これは、ドメイン層のデータもデータアクセス層を介してデータベースや外部APIとのやり取りが必要であることを意味します。
このため、出力に紐づけられるドメイン層のデータはデータアクセス層に提供するために、外部公開する必要があり、情報隠蔽化が崩れます。
何らかの計算のために振る舞いをデータと一体化させるメリットは薄い
前節では外部への出力のために情報隠蔽化が崩壊することを説明しました。
外部から入力されて外部に出力されない情報の取り扱いにおいても、カプセル化は課題があります。
外部から入力されて外部に出力されない情報の取り扱いとして、外部からの入力をコンストラクタインジェクションでオブジェクトに保存し、なんらかの振る舞いを提供するパターンを考えます。
例えば以下のコードのHogeCalculatorクラスがそれになります。このクラスはHoge型データをコンストラクタインジェクションして、その後Bar型の引数を受け取るcalcメソッドで何からの計算をしています。
class HogeCalculator {
readonly hoge: Hoge;
constructor(hoge: Hoge) {
this.hoge = hoge;
}
calc(bar: Bar): Foo {
// hogeとbarを使った計算をここで実行し、結果のFoo型の値を返す
}
}
HogeCalculatorクラスは、コンストラクタでHoge型データを受け取り、そのデータを使用してcalcメソッド内で計算を行いますが、これはOOPのカプセル化の目的からずれてるように見えます。
本来、カプセル化はデータとそれを操作する振る舞いを一体化し、外部からは公開されたメソッドを通じてのみアクセスを許すことで、内部の複雑さを隠蔽することを目指します。しかし、HogeCalculatorは、状態を管理するよりもcalcのような特定メソッドを実行するためのユーティリティとして機能しており、状態と振る舞いの一体化というカプセル化からずれてます。このクラスは実質的に関数的な処理を提供しているだけです。
そのため、calcメソッドのようなものを実装するときに純粋関数を選択肢から外す理由はあまりないです。
以下のcalc関数はコンストラクタインジェクションをやめて、calcメソッドを純粋関数にしたものです。純粋関数の方が再利用性が良く、コードも簡単です。
このように考えていったとき、振る舞いとデータの一体化という意味でのカプセル化のメリットは相対的に小さくなったと考えられます。
function calcPureFunction(hoge: Hoge, bar: Bar): Foo {
// hogeとbarを使った計算をここで実行し、結果のFoo型の値を返す
}
オブジェクトのメソッドは自身のプロパティを第一引数にした関数の糖衣構文になる
カプセル化が破れて情報隠蔽ができなくなった場合、メソッドはオブジェクトのプロパティを第一引数にした関数の糖衣構文と言えます。
これを下の例で説明します。
下記コードではUserDataにdescribeメソッドがあります。このUserDataのdescribeメソッドは次のように書き直すと純粋関数にできます。
- すべてのプロパティをpublicにする。
-
describeメソッドをオブジェクトから消す。 -
UserDataを引数で受け取るdescribe関数を新たに書く。
class UserData {
public readonly name: string;
public readonly age: number;
constructor(name: string, age: number) {
this.name = name;
this.age = age;
}
// オブジェクト内でプロパティを利用した処理を提供するメソッド
describe() {
return `${this.name} is ${this.age} years old.`;
}
}
function describeUser(user: UserData): string {
return `${user.name} is ${user.age} years old.`;
}
これはUserDataのdescribeメソッドは、自身を暗黙の第一引数とした関数に変換可能であることを示します。言い換えれば、カプセル化が破れてすべてのプロパティがpublicにできると、オブジェクトのメソッドは自身のプロパティを第一引数にした関数の糖衣構文と考えることができます。
この変換ができることから、振る舞いはオブジェクトの外に出すことが可能になり、メソッドがオブジェクト内にある必然性がなくなります。
カプセル化が破れたあとのオブジェクトの役割
本質的にオブジェクトとメソッドを結びつけるメリットがないことを説明しました。
この章では、このようなカプセル化が破れたあとのオブジェクトの役割を考えていきます。
型による意味づけ
型をつかうと、特定のデータをまとめたものに名前を与えられます。
このように、型によって何らかの意味を付与することはまだ重要と考えています。
例えば次の例が挙げられます。
- パスワードの型を暗号化前と暗号化後を型で区別する
- 支払いがクレジットカードなのか代引きなのかを型で区別する
- ユーザーIDと注文IDを区別する
型はドメインにとって重要な区分やデータのまとまりを表現できます。
このように型によるドメインの表現はモデリングでも重要です。
データ整合性を保つ
先ほどオブジェクトから振る舞いはなくなると述べました。
しかし、オブジェクトがデータの整合性を確保することは、例外的にオブジェクトに求められる振る舞いと考えています。
なぜならば、オブジェクトはデータをまとめたり型としてデータの性質を表す役割があるため、オブジェクトに自身が持つデータの整合性を維持して欲しいからです。
例えば、以下のようなときはデータの整合性をクラスが保証すべきと考えています。
- 郵便番号欄に「東京都」と書く
- 文字数制限を升目で表現している書類に対して、1マスに2文字も書く
- 承認者しか書いてはいけない書類の欄に、申請者が記入をする
まとめると、オブジェクトは外部に影響を与える振る舞いはないけど、自身が持つデータの整合性の維持はオブジェクト自身の役割にできると思います。
ドットによるメソッド呼び出し
業務ドメインにとって本質的ではないかもしれませんが、IDEによって、クラスのメソッドは.(ドット)によって探しやすいです。
これは実装上のメリットとしては小さくありません。
関数でも実装できますし、技術的な話なのでこのメリットに固執すべきではないですが、享受できるなら享受したいメリットです。
カプセル化の崩壊をモデリングで解釈し直す
カプセル化が崩壊し、振る舞いがオブジェクト内に収まる必然性がなくなったと話しました。
つまり、カプセル化が崩壊するとデータと振る舞いが分離します。
そのため、オブジェクト指向で考えられていたデータ視点の分析だけではなく、振る舞い視点の分析も重要になっていきます。
振る舞い視点のモデリング
振る舞い視点のモデリングは複数あります。
例えば、イベントストーミングのような手法もあげられるでしょう。
イベントストーミングは、業務プロセスやシステムの振る舞いを理解し、モデリングするための手法です。
このアプローチは、業務ドメインのイベントを紙やステッカーに書き出して壁に貼り、それらのイベントをつなげて全体の流れを可視化します。
これ以外にも鉄道指向プログラミングなどが、関数型言語の文脈から提案されています。
業務アプリケーションのオブジェクトには一部の振る舞いがない
上で述べた振る舞いを重視したモデリングは、業務を反映したモデリングとなり得るでしょうか?
私はこれらの振る舞いを重視したモデルも業務を反映していると考えています。
通販サイトの例
例えばですが、通販サイトがあるとします。
この通販サイトは次のようなモデリングをするとします。
- ユーザーごとに購入予定商品を束ねたモノをカートと呼ぶ
- カートは支払い処理をすると注文になる
これをモデリングして、カートと注文のモデルができるとします。
それでは支払い処理はカートが持つのでしょうか? 注文が持つのでしょうか?
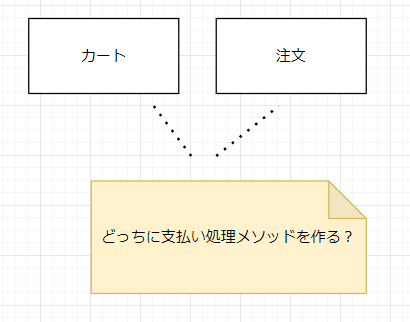
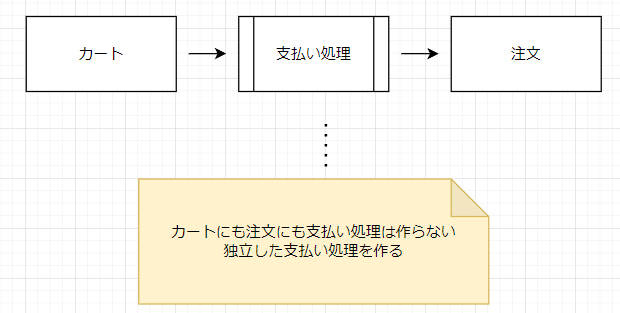
私だったら、支払い処理というオブジェクトまたは関数を作ります。カートにも注文にも支払い処理は作りません。
なぜならば、実店舗を考えるとカートにも注文にも支払い処理がないからです。
実世界では、カートの商品をレジに通すことによって注文が生まれます。つまり、カートも注文も支払い処理という機能を持っていません。これをそのままモデルに反映する方が無難です。
書類のアナロジー
さきほどの話は通販サイトを実店舗に置き換えて考えました。
それでは注文から倉庫への指示とか、人事データから給与計算とか、そういったものはどうすべきでしょうか?
このような業務アプリケーションで扱うようなデータは、紙の書類のアナロジーでとらえるのが良いと考えています。
もしもITシステムがなければ、これらの情報を扱う仕事は、人が書類を用意し、書類を書き、書類を受け渡します。
この書類がオブジェクトであり、人がやることがデータとデータを繋ぐ処理であったり、外部入出力であったりします。[2]
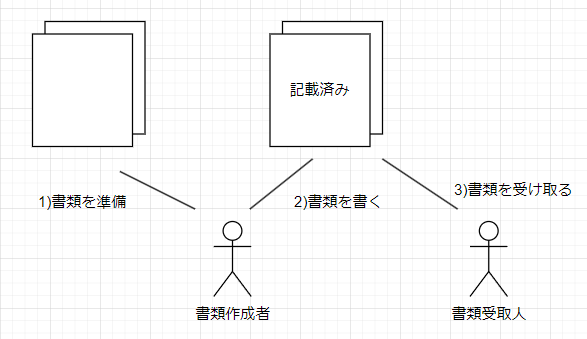
業務アプリケーションで扱うものは純粋な情報が多く、重要な振る舞いをオブジェクト自身が持つことは適切ではないことがあります。
そのため、この書類のアナロジーをモデリングに利用することは有効と考えられます。
モジュールレベルのカプセル化
今まで、カプセル化の崩壊の話をしてきましたが、これはオブジェクトレベルの話です。
オブジェクトレベルでのカプセル化の重要性が薄れつつある一方で、モジュールレベルでのカプセル化は依然として大きな価値を持っています。
このカプセル化は、システムの異なる部分間の明確な境界を確立し、それぞれのモジュールが独立して機能し、他のモジュールとは明確に定義されたインターフェイスを通じてのみ通信するようにします。[3]
このモジュールは、いわゆるマイクロサービスやSaaS、適切に分割されたライブラリなどが考えられます。
これらのモジュールは、特定の機能をインターフェースを介して提供し、データを隠蔽化しています。
モジュールレベルのカプセル化は、システム全体の柔軟性を高め、変更や拡張を容易にし、依存関係を最小限に抑えることができます。
まとめ
この記事では、不変性とレイヤー化がカプセル化の理解を変え、特に業務アプリケーションのバックエンドのオブジェクトとモジュールに影響を与えていることを考察しました。
OOPによるオブジェクトやモデリングについて見直す必要があるかもしれません。
一方で、モジュールレベルのカプセル化は依然として有用と考えられます。
実際にはドメインやアプリケーションごとに最適解が変わります。
そのため、開発者は様々な観点からドメインを分析することが重要です。
-
カプセル化について、オブジェクト指向入門 第2版: 原則・コンセプトでは「そのモジュールの属性の中からいくつかの属性をそのモジュールに関する正式な情報として選択し、顧客モジュールの作成者がその情報を利用できるようにしなければならない」(同書籍, p.64)としている。この書籍を参考にすれば、本文中のデータの隠蔽化も、データと振る舞いを一体にする話も、カプセル化の側面のひとつである。 ↩︎
-
DFDっぽいとは思うけど、振る舞い視点で分析していくとそうなっていくのだと思う。 ↩︎
-
クリーンアーキテクチャで説明されていたアランケイ氏のオブジェクト指向と似ているかもしれない。 ↩︎

Discussion