レバテック開発部DevOps推進グループSREチームの蒲生です。
このたびレバテックを退職することになりました。
今までやってきたことを振り返ることで、お前普段なんもやってなかったやろと思っている方への説明とまだまだやらなアカンことあるけど許してねって気持ちを吐き出したいなと思います。
初めてSREとして働き始めてからレバテック事業でのSREチーム結成、活動していくまでで「やってよかったな」と思ったことを紹介していきます。(僕個人ではなくチームでの取り組み)
「こうしておけばよかったな」という懺悔も混ぜておきます。
1. 監視体制作り
初めてのSREだったので定石通り、こちらのピラミッド通りにプラクティスを実践しました。
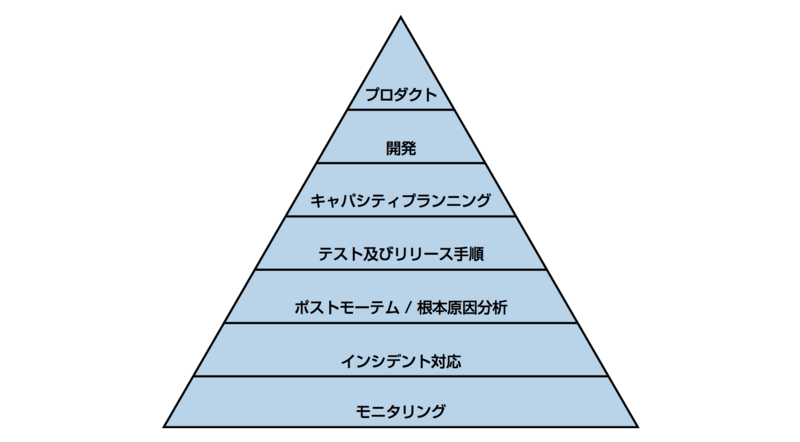 (O’Reilly Site Reliability Engineeringより)
(O’Reilly Site Reliability Engineeringより)
簡単な状況
- 監視設定はCloudWatch
- CDKでリソースのCPUやメモリ、スレッド数などにアラートを設定していた
課題
- ログ検索がしづらい
- どのアプリケーションのログがどのロググループに入っているか把握しづらい
- ログが構造化されて保存されていないため、検索性が高くない
- 監視設定の一覧性が高くない
- 設定漏れが起きやすい
- どのアプリケーションにどんな設定をしているか把握しづらい
- 監視設定のSREチームへの依存
- 必要最低限の監視設定を行うためにSREチームが作業に入る必要があった
- SREチームの人数に対してアプリケーションの数が多く、ボトルネックになりやすかった
- 監視設定のばらつき
- 設定する開発者によって監視設定にばらつきがあり、設定漏れなどが発生していた
- 必要最低限の監視設定を行うためにSREチームが作業に入る必要があった
取り組み
Datadogの導入
- メインの監視ツールをCloudWatchからDatadogに移行しました。
- 導入初期は、SREチーム側で各アプリケーションに対して設定したほうがいいアラートを設定して、開発メンバーが細かい設定をしなくても自動で監視対象になるようにしました。
- 導入後、しばらく経ってからはアラートのしきい値の調整やダッシュボードの管理などを開発チームに行ってもらうようにしていきました。
やってよかったな
- ある程度監視設定の統一ができました\(^o^)/
- 始めは細かいしきい値の調整をせずに、統一的に監視設定を行いました。
- AWSのタグ付けを行えば、自動的に監視対象に入るようにしました。
- これによって、導入当初はSREチームもアラートを拾いやすい状態になりました。
- 始めは細かいしきい値の調整をせずに、統一的に監視設定を行いました。
- 監視設定の各チームへの移譲ができました\(^o^)/
- 設定箇所のナレッジ共有
- SREチームが設定した統一的な監視箇所を開発チームが知ることで、どこにどういう監視設定をすればいいかのナレッジを広めることができました。
- 開発チームによる監視運用
- ナレッジが広まり監視設定を開発チーム内で完結できるようになったことで、しきい値の調整も柔軟に行える体制になりました。
- また自分たちで設定したアラートなので、トラブルシューティング速度も向上しました。
- 設定箇所のナレッジ共有
懺悔室
- 監視設定のコード化しておけばよかったな(ノω·`o)
- 導入当初は手動設定の手軽さ、UI操作での分かりやすさを取ってしまいましたが、どうしても設定にばらつき、監視漏れなどが起こっていたので早めにコード化すればよかったなと思います。
- コード化には取り組んでいたんですが
- 当時の主なIaCツールがCDKで、Datadogと設定を連動させるのが難しかったり
- チーム内のメンバーの入れ替わりなどがあり実用性のあるところまで持っていけなかったです、、
自分で自分をよいしょ
- 開発チームによる監視運用ができるようになったことで、SREにとって重要な障害対応に対して本腰を入れて取り組む下地ができたと思います。
- その後の障害対応ルール作成、ポストモーテムなどピラミッドの上の階層の取り組みに踏み切ることに繋がりました。
2. IaC文化の浸透
 (O’Reilly Infrastructure as Codeより)
(O’Reilly Infrastructure as Codeより)
簡単な状況
- CDK V1で作られた社内ライブラリを各アプリケーションのインフラリポジトリから参照してスタックを作成する形
- アプリケーションコードも含めたEC2からECSへのリプレイスが走っていたので、その新環境のみCDKで作成するようになっていました。
- CDKを触れる開発者は一部
- 権限的にも
- スキル的にも
課題
- インフラ変更を一部の開発者に依存
- 監視設定と同じように、ボトルネックの要因になりえるものでした
- 既存インフラ(EC2など)はコード化されないまま
- 手動で構築されたものなので、認識されていない設定などに影響する変更をするリスクがありました
取り組み
ペアプロ
- 初期
- インフラ基盤の初期構築はSREチームで行う状態は維持しつつ、その後の運用で発生するインフラのちょっとした変更から、開発メンバーとのペアプロを進めていきました。
- 中期
- 当時アプリケーション含めEC2からECSへのリプレイスが走っていたので新規のインフラ(まだ本番運用していない、スクラップ&ビルドがしやすい)を構築してもらう経験をしてもらいました。
- 後期
- 開発チーム内でインフラの実装がほぼ完結する状態になりました。自チームで不安があるところがないか時々ヒアリングして、必要の上SREチームがレビューに入るようにしていましたが、その数もどんどん減っていきました。
AWSの権限整理
- CDK、TerraformのCI/CD作成
- ペアプロの成果もあり、インフラリポジトリが開発メンバーによって変更されることが増えてきたので、ローカルでのデプロイによるコードと実体の差分の発生を防ぐためにCI/CDを構築しました。
- AWSの各開発者の権限整理
- AWSのSecrets Managerなど気密性の高い情報などに開発メンバーがアクセスできないように、AWS IAM Identity Centerで開発メンバーをグループ分けして適切な権限を付与する形にしました。
既存インフラのIaC化
- TerraformとAnsibleで手動構築環境をコード化
- 当時SREチームで既存環境を触る人が自分一人だけだったので、このまま手動管理をしていくと新規参画者のオンボーディングも、開発メンバーへのインフラ運用の展開もできないと考えて、TerraformとAnsibleでのコード化を進めました。
- AWSの設定に関してはCDK Importでのコード化も考えたのですが、手動構築環境とリプレイス環境とのネットワーク構成の差分や手動で構築された故の不明瞭な設定の多さがあったので、変更する部分の周辺だけをコード化しやすいTerraformの方を採用して既存環境をコード化していきました。
やってよかったな
ペアプロ
- インフラリポジトリを触る開発メンバーがたくさんになった\(^o^)/
- 開発メンバーとインフラの運用課題を議論する機会もできてSREチームのエンゲージメントも上がったように思えます。
AWSの権限整理
- セキュリティが上がった\(^o^)/
- 開発者に適切な権限を与えることで、セキュリティを担保しながら安心してインフラの運用を開発者に行ってもらうようにできました。
- 変更をコードで追えるようになった\(^o^)/
- 手動変更とはオサラバして、変更内容やその変更のコンテキストをコードやプルリクエストで追えるようになりました。
既存インフラのIaC化
- インフラリポジトリを触る開発メンバーがたくさんになった\(^o^)/
- それまでリプレイス環境のみ開発メンバーが積極的に運用できる状態だったので、既存環境の運用チームもインフラを変更できるようになりました。
- 既存環境でもカナリアリリース的なアプローチが気軽にできるようになった\(^o^)/
懺悔室
- CDK v1→v2のアップデート失敗(ノω·`o)
- 当時CDK V1の社内ライブラリを作って、それをもとにインフラを構築していたんですが
ライブラリの構成を複雑にしすぎ、V2にあげようとしてもスタック同士の依存関係や関数の仕様変更を解決する工数が膨大になってしまい、そのままV1→V2に上げることを諦めることになりました。
- 当時CDK V1の社内ライブラリを作って、それをもとにインフラを構築していたんですが
- CloudFormation、CDK、Terraformが同時に存在することに(ノω·`o)
- 初期のIaC化はCloudFormationを使って行われ、インフラコードの移行が完了しないまま生のCDK、社内ライブラリを利用したCDK、CDK V2、Terraformと様々な様式が用いられてしまい、とりとめのない状態になってしまいました。
自分で自分をよいしょ
- インフラの変更はほぼ開発チームで行う状態になり、SREチームの作業やレビューがが機能開発のボトルネックになることは少なくなりました。
- 既存インフラのIaC化を進めたことでインフラの大規模な変更がしやすくなり、別環境の作成やカナリアリリースが可能になりました。
3. Embedded SREの成長支援と事業部専門SREチームの発足
簡単な状況
- 全社SREチームだけある状態
- 複数事業をまたいだチーム体制
- 事業、チームごとにSREがいる状態ではない
- 全社全体でのクラウド環境運用保守に関して幅広くカバーしていた
- 複数事業をまたいだチーム体制
課題
- 事業に焦点を当てたSRE活動に力を入れにくい
- 監視設定やIaCが進んだ段階で、さらに事業やエンドユーザー目線でのSRE活動を行うには、SREチームがいる場所がアプリケーションや事業から遠い位置にいました
- 事業やアプリケーションに関する理解
- アプリケーションチームの開発事情
- などに関して高い解像度を持っていなかったので打てるアプローチが限られていました
- 監視設定やIaCが進んだ段階で、さらに事業やエンドユーザー目線でのSRE活動を行うには、SREチームがいる場所がアプリケーションや事業から遠い位置にいました
- 事業部付けの開発部内で抱えている運用課題に力を入れにくい
- 全社SREチームの解像度だとまずそういう課題を認識しにくい
- 落ちてるボールを拾うにも、そのボールが大きすぎて個人が片手間で対応できるものではない
取り組み
Embedded SREの成長支援
まず事業の開発部内でSRE活動をする人を増やそうということで、
開発部内から何人かEmbedded SREとして働きたい人を募って、その方たちの成長支援を行いました。
- SREの考え方のインプット
- SRE本の輪読、SREワークショップの実施(chaspyさん作のドキュメントを参考にしました)
- インフラ構築、IaC化
- 既存インフラの再構築
- SRE本に書いてあるSRE初学者への学習体験は「混沌ではなく構造を提供する」ことが大事だと思ったので、まずは現状のインフラがどうなっているか、なぜそうなっているのかの理解を支援しました。
- 既存インフラの再構築
- 監視、オブザーバビリティの考え方のインプット
- 入門監視やオブザーバビリティエンジニアリングの輪読を行いました。
SRE文化の展開
Embedded SRE内でSREに関する知見が溜まったタイミングで開発チームへの文化の展開を行いました。
- SREワークショップの開催
- Embedded SRE内で行ったワークショップを開発チーム向けに展開しました
- SLOワークショップの開催
- The Art of SLOの教材を使って、架空のアプリケーションに対してSLI/SLOの設定を行うワークショップを開催しました。
- SLO策定
- 事業において重要な箇所をピックアップして、開発チームとマーケティングの方と一緒にSLI/SLOの策定を実践しました。
事業部専門SREチームの発足
Embedded SREとして各開発チームにSRE文化を展開しました。
その一方で、チームを横断した課題や開発部全体で抱えている問題への対処をするためには、事業全体を見るSREチームが必要と判断して、Embedded SREの方たちとともに事業内SREチームを新しく結成しました。
取り組んだこと
- O11yの実践
- マイクロサービスアーキテクチャの複数サービスに対してAPMを使ったトレーシング設定を行いました。
- 一部の事業でDatadog→NewRelicへの移行を行いました。
- TiDBの導入
- サービスごとにAWSのAuroraクラスターを持っていましたが、サービス同士の依存関係を完全に切り離すことが難しいところがあり、一つのAuroraクラスターのメンテナンスにかかる調整コストが高い状態でした
- すべてのAuroraクラスターを一つのTiDBクラスターにまとめることで、無停止でバージョンアップができる状態を目指して、絶賛移行作業中です。
やってよかったな
- 共通のことばや文化で喋れるようになった\(^o^)/
- SREの文脈で出てくることばや考え方を前提に話すことができるようになりました
- 各開発チームで個々に対応できない問題に手を伸ばすことができた\(^o^)/
- チーム間に落ちている大きなボールに手を伸ばす体制を作れました
懺悔室
- 各開発チームが抱える課題に対してのアプローチが少なくなった(ノω·`o)
- 監視設定やIaCを進めていたときより、全体を俯瞰したアプローチや地道な布教活動を行う事が多かったので、開発チームが直近困っている課題に対するアプローチは少なくなったように思えます。
- 定量的成果を見せられていない(ノω·`o)
- オブザーバビリティの導入や布教活動、SLOの策定に関して、具体的な事業への貢献を数値でまだ見せられていないので、今の活動を継続するためには定量面の成果を作らないといけないなと思っています。
自分で自分をよいしょ
- SREの考えを持って開発する人が増えた感触
- 週次でメトリクス確認会を各開発チームで行ってパフォーマンスなどを定点観測して行動に移す、などSRE的活動をする開発者が増えたのは嬉しいことでした。
- 各開発チームで運用課題に立ち向かうための体制を少し作れた
- チーム間に落ちているボールを拾うSREチームを置いたことで、チームごとに抱える課題に対して各チームが集中して取り組みやすい状態に近づけられたのかなと思います。
まとめ
ここまでSREを始めてから3年半でやったことの中で「やってよかったな」と思ったことをピックアップしました。
監視やインフラのコード管理など下地を整えてから、
より事業やユーザー目線でのSRE活動を進めていく、という流れを実践したのは大きな経験だったかなと思いますし、再現性の高いアプローチだったのかなと振り返って感じます。
レバテックを退職して次のところでもSRE活動を行っていくので、
こちらで振り返ったことをもとにまた信頼性の高いサービス作りを目指して頑張っていきたいと思います!

Discussion