はじめに
昨今はクリーンアーキテクチャやオニオンアーキテクチャといった、レイヤードアーキテクチャを採用するプロジェクトが増えています。
その中で、「ユーザーからの入力に対する検証をどのレイヤーで行うべきか?」という議論は、設計方針を左右する問題です。今回はこの問題について考えてみました。
この記事の要約
- 「ドメイン層」に入力検証を実装するのは避けた方がいい。
- 「コントローラ層」または「ユースケース層」に実装するのがいい。
- どちらを選ぶかは、拡張性と開発効率のトレードオフである。
入力検証とは?
システムにおける「検証」には、主に以下の三種類があります:
- 入力検証(Input Validation): 形式的な妥当性チェック(例:必須、長さ、メールアドレス形式など)
- ビジネス検証(Business Validation): 業務ルールに基づく妥当性チェック(例:1日に予約できる回数上限)
- 出力検証(Output Validation): 不正な状態や表示崩れなどの出力に関するチェック(例:XSS対策)
本記事ではどこで行うべきか議論が起こりがちである「入力検証」に絞って扱います。
入力検証を配置したときのレイヤーごとの特徴
レイヤードアーキテクチャで、入力検証を各レイヤーで配置した時の特徴を述べます。
レイヤードアーキテクチャとは?
ここでは、クリーンアーキテクチャやオニオンアーキテクチャといったアーキテクチャでも一般的に見られる、典型的なレイヤードアーキテクチャの構成に従い、以下の3つの層に分類します:
- コントローラ層:外部とのインターフェース(APIやUI)を受け持つ層
- ユースケース層:アプリケーションの振る舞い(ユースケース)を記述する層
- ドメイン層:業務ルールを表す層。エンティティやドメインサービスなどを含む
三つのレイヤーで考える
ここから本題であるどのレイヤーに入力検証を書くべきか考えていきます。
コントローラ層で入力検証をする
コントローラ層は外部からのリクエストを受け付けるシステムの入り口です。ここで入力検証を行うと、リクエストの形式的な妥当性をチェックし、問題があればすぐにエラーを返せます。後続の処理に不正な入力を送らず、効率的なエラー通知が可能です。

メリット
- フレームワークの機能(例えばSpringのバリデーションアノテーションなど)を活用でき、実装コストが低い
- 入力エラー時に即レスポンスを返せるため、応答がシンプル
デメリット
- GUI以外の入力手段(CLIやAPI)でも同様の検証が必要な場合、重複実装が発生
- コントローラが入力検証の責務を持つため、肥大化しやすい
- フレームワークの機能に密接に依存するため、単体テストがしにくい場合がある
コントローラ層での実装例(TypeScript + Express)
コントローラでの実装例です。postの呼び出しで検証を行っています。
app.post(
'/users',
[
body('email').isEmail(),
body('name').isLength({ min: 1 }),
body('age').optional().isInt({ min: 0 }),
],
(req: Request, res: Response) => {
const errors = validationResult(req);
if (!errors.isEmpty()) {
res.status(400).json({ errors: errors.array() });
return;
}
createUserUseCase.execute(req.body);
res.status(201).json({ message: 'User created' });
return;
}
);
ユースケース層で入力検証をする
ユースケース層はアプリケーションの振る舞いやビジネスロジックを記述する層です。ここで入力検証を行うと、ユースケースに必要なデータの完全性や整合性を検証できます。UIやAPIなどの複数の箇所から同じユースケースが使われる場合でも、一貫した品質を保てるのがメリットです。
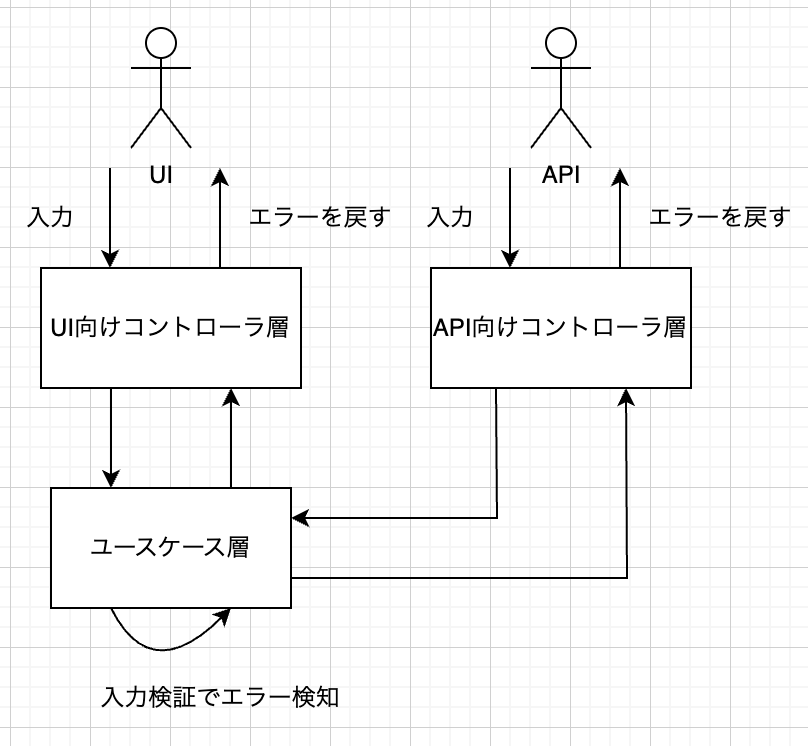
メリット
- 複数のインターフェース(API、バッチ、CLIなど)から呼ばれても、一貫した検証が保証できる
- コントローラ層と違ってフレームワークに依存しない形にすればテストしやすい
- コントローラ層でもフレームワークに依存しないで入力検証をしようと思えばできますが、それをするとコントローラ層で実装するメリットが薄れる
- コントローラ層がスリムになる
デメリット
- フレームワークのバリデーション支援を使いにくく、実装コストがやや高くなる
- エラー発生時にコントローラ層への適切なエラー伝達とレスポンス調整が必要になる場合がある
ユースケース層での実装例
// DTO(Data Transfer Object)とバリデーションロジックを定義
type CreateUserInput = {
email: string;
name: string;
age?: number;
};
class CreateUserValidator {
static validate(input: CreateUserInput): string[] {
const errors: string[] = [];
if (!input.email.match(/^[^\s@]+@[^\s@]+\.[^\s@]+$/)) {
errors.push('Invalid email format');
}
if (!input.name || input.name.length === 0) {
errors.push('Name is required');
}
if (input.age !== undefined && input.age < 0) {
errors.push('Age must be non-negative');
}
return errors;
}
}
// ユースケース本体
class CreateUserUseCase {
execute(input: CreateUserInput) {
const errors = CreateUserValidator.validate(input);
if (errors.length > 0) {
throw new Error(`Validation failed: ${errors.join(', ')}`);
}
// この後処理が続く
}
}
ドメイン層で入力検証をする
ドメイン層はビジネスの中心となる概念やルールを表現する層です。ここで入力検証を行うのは、オブジェクトが常に有効な状態を保つためです。不正なデータがドメインモデルに入るのを防ぎますが、入力の早い段階でエラーを検出することはできません。
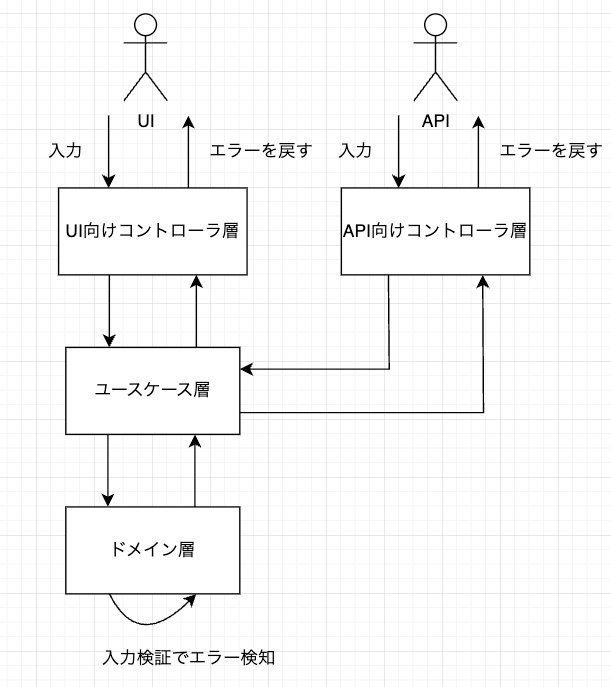
メリット
- 不変条件や業務ルールと密接に結びついたバリデーションが可能
- エンティティの整合性が担保される
デメリット
- ユースケース層の引数から入力された未検証のオブジェクトが、ユースケースの関数内に存在することを許容することになる
- 入力の段階で早期に弾けないため、エラー処理が煩雑になる
ドメイン層での実装例
type UserProps = {
email: Email;
name: string;
age?: number;
};
class User {
private constructor(
private readonly email: Email,
private readonly name: string,
private readonly age?: number
) {}
static create(props: UserProps): User {
if (!props.name || props.name.length === 0) {
throw new Error('Name is required');
}
if (props.age !== undefined && props.age < 0) {
throw new Error('Age must be non-negative');
}
return new User(props.email, props.name, props.age);
}
}
どこに入力検証を書くべきか?
先ほど述べた三つの層での検証のうち、どこで検証すべきか考察していきます。
ドメイン層で入力検証は契約による設計を満たせない
デメリットにも記載しましたが、入力検証をドメイン層に書くとユースケース層で契約による設計ができなくなる問題や、エラー検知が遅れる問題があります。
ドメイン層は、ドメインモデルが常に有効な状態を保つことに責任を持ちます。一方で、この責務に入力検証を含めると問題が発生します。
以下のコード例を見てください。
- CreateUserUseCaseクラスのexecute内でUserクラスを作っています
- Userクラス内で検証をしています
class User {
constructor(
private readonly email: string,
private readonly name: string
) {
if (!email.includes('@')) {
throw new Error('Invalid email');
}
if (!name) {
throw new Error('Name is required');
}
}
}
class CreateUserUseCase {
execute(input: { email: string; name: string }) {
const user = new User(input.email, input.name);
// 以後処理が続くが、ここの処理でも未検証のinputにアクセスできる
}
}
このコードの問題点は、主に以下の2点に集約されます。
未検証データがユースケース層に存在するリスク
まず第一に、ユースケース層が未検証のデータを扱う期間が発生してしまうという問題です。
executeメソッド内でUserインスタンスが生成されるまでの間、inputオブジェクトは形式的な検証がされていません。もしこの間にinputオブジェクトのプロパティを参照して何らかの処理を行うと、不正なデータでビジネスロジックが実行されてしまうリスクがあります。
これは、ユースケース層が「検証済みのデータ」という事前条件を保証できない状態であり、契約による設計が損なわれていると言えます。ドメイン層に検証を委ねることで、ユースケースの内部に未検証のデータが入り込み、その後の処理で意図しないバグやエラーを引き起こす可能性が高まります。
もちろん、ユースケース内でinputを扱うたびに再度検証することも不可能ではありません。しかし、それは同じ検証ロジックを繰り返し書くことになりかねず、コードの重複と保守性の低下を招きます。
単純な検証がビジネスロジックにまで入り込むリスク
二つ目の問題はビジネスロジック自体が複雑になることです。
ドメイン層でエラーが発覚するということは、ユースケース層のビジネスロジックの実行中に、形式的なデータ不備が発覚することを意味します。この場合、ビジネスロジックは形式エラーを処理するロジックも組み込む必要が出てきます。
本来、ビジネスロジックは「このメールアドレスのユーザーが存在するか」や「在庫があるか」といった業務ルールに集中すべきです。しかし、入力検証をドメイン層に置くと、「数字の桁は収まってるかどうか」といった形式的なチェックの責任まで負うことになり、ロジックが肥大化し、保守性を落とします。
ユースケース層での検証は契約による設計を満たせる
コントローラ層は言わずもがなですが、ユースケース層の検証でも場合によっては契約による設計は可能です。
契約による設計が満たしにくい例
場合によってと書いた通り、ユースケース層で検証をすると問題が発生することがあります。
その問題を先ほど書いた実装例で説明します。この再掲された検証には問題が二点あります:
- ドメイン層で検証した場合と同じく、ユースケースのメソッドが呼び出された時点では、inputオブジェクトはまだ形式的な検証がされていません
- そもそも検証を実装し忘れる可能性がある
ユースケース層での実装例(ユースケース本体のみ再掲)
class CreateUserUseCase {
execute(input: CreateUserInput) {
// ここではinputが未検証
const errors = CreateUserValidator.validate(input);
if (errors.length > 0) {
throw new Error(`Validation failed: ${errors.join(', ')}`);
}
// この後処理が続く
}
}
この課題を解決する一つのアプローチとして、AOP(アスペクト指向プログラミング)が有効です。
契約による設計が満たせる例
先ほどのユースケース層の課題は、AOPのような実装をすれば解決します。
AOP(アスペクト指向プログラミング)とは?
AOPは、ログ記録やバリデーション、認可といった横断的関心事と呼ばれる共通の処理を、ビジネスロジックから切り離して管理するプログラミング手法です。これにより、各メソッドが本来のビジネスロジックに集中できるようになります。
入力検証の場合、メソッドが実行される前に自動的に検証ロジックを差し込むことで、ユースケースのコードがシンプルになり、常に検証済みのデータで処理を開始できる状態を作れます。
実装例
言語によってはAOPのようなコードを書けないこともあります。今回はTSのデコレータによってAOPのような実装を書きました。
このAOPによって先ほどのコードにあったデメリットを消すことができます。
- メソッドが呼ばれた時に検証メソッドが呼ばれるため、契約による設計ができる
- LintルールやCIを頑張って作れば、Validatorが実装されてないユースケースクラスのメソッドがあったらエラーにすることもできる
ユースケース層での実装例(AOPバリデーション)
Validatorをデコレータで設定しているコード。これによって、メソッド呼び出し時にバリデーションをしている。
class CreateUserUseCase {
@Validate(CreateUserValidator.validate)
execute(input: CreateUserInput) {
// 検証済みの入力に基づいて処理
console.log('User created with', input);
}
}
デコレータに設定しているValidatorの実装。
interface ValidationError {
field?: string;
message: string;
}
type ValidatorFunction<T> = (data: T) => ValidationError[];
function Validate<T>(validator: ValidatorFunction<T>) {
return function (
_target: any,
_propertyKey: string,
descriptor: PropertyDescriptor
) {
const originalMethod = descriptor.value;
descriptor.value = function (...args: any[]) {
const input = args[0] as T;
const errors = validator(input);
if (errors.length > 0) {
throw new Error(`Validation failed: ${JSON.stringify(errors)}`);
}
// 検証が成功した場合、元のメソッドを実行
return originalMethod.apply(this, args);
};
};
}
interface CreateUserInput {
username: string;
email: string;
age?: number;
}
// バリデータクラスの例
class CreateUserValidator {
static validate(input: CreateUserInput): ValidationError[] {
const errors: ValidationError[] = [];
if (!input.username || input.username.trim() === '') {
errors.push({ field: 'username', message: 'ユーザー名は必須です。' });
} else if (input.username.length < 3) {
errors.push({ field: 'username', message: 'ユーザー名は3文字以上である必要があります。' });
}
if (!input.email || !/^[^\s@]+@[^\s@]+\.[^\s@]+$/.test(input.email)) {
errors.push({ field: 'email', message: '有効なメールアドレスではありません。' });
}
if (input.age !== undefined && (input.age < 0 || input.age > 150)) {
errors.push({ field: 'age', message: '年齢は0から150の間である必要があります。' });
}
return errors;
}
}
このようにAOPのように書くことができれば、ユースケース層に検証機能を書いても、契約による設計は達成できます。
AOPのように書くのが難しいと考える人もいるかもしれませんが、言語的に可能であるならば、AIを使えば作成は容易と思います。
結論
入力検証をどこに置くかは、プロジェクトの性質や将来の拡張性によって判断すべきです。ドメイン層での検証は避けるべきですが、コントローラ層とユースケース層にはそれぞれトレードオフがあります。
ドメイン層での検証は非推奨
ドメイン層はデータの不変条件を保つ役割を担いますが、入力段階の検証には適していません。ここに検証を置くと、ユースケース層で未検証のデータを受け入れてしまい、「契約による設計」が崩れ、システムの安定性を損なう原因となります。
コントローラ層 vs. ユースケース層:トレードオフ
どのレイヤーに検証ロジックを置くかは、システムの「入口」がいくつあるか、そして実装コストと保守性のバランスをどう取るかで判断しましょう。
- コントローラ層での検証は、実装コストを抑えたい場合や、Web APIのように単一の入口からのみユースケースが使われる場合に適しています。例えば、バックエンドがWeb APIのみを提供し、フロントエンドがそのAPIに厳密に従って入力データを整形する場合など、入力インターフェースが限定的で変更されにくいプロジェクトフレームワークの機能を最大限に活用できます。
- ユースケース層での検証は、API、UI、バッチ処理など、複数の異なる入力チャネルを持つシステムや、将来的に多様なインターフェースが追加される可能性のあるプロジェクトに有効です。一貫した検証ロジックを再利用でき、保守性やテストのしやすさが向上します。AOPなどの技術を使えば、契約による設計も保てます。
上記の比較を踏まえて、入力検証を書くところはコントローラ層かユースケース層に書くと良いでしょう。
まとめ
入力検証は一見シンプルな処理に思えますが、どのレイヤーに責任を持たせるかによって、アーキテクチャ全体の設計方針や保守性に影響を及ぼします。
そこで本記事では、コントローラ層・ユースケース層・ドメイン層の3つの選択肢を比較し、それぞれのメリット・デメリットや設計上の影響を整理しました。
この記事が皆さんのプロジェクト設計に少しでも貢献できれば幸いです。

Discussion