この記事は「レバテック開発部 Advent Calendar 2024」の 1 日目の記事です!
TL;DR
- TypeScript ユーザーが Haskell を写経しながら学んでいった記録です
- 題材は「JSON Parsing from Scratch in Haskell」で、この記事自体はこれのコードリーディングのメモみたいなものになります
- うまく言えないのですが、型に対するメンタルモデルが変わった感じがしました
初日から長ったらしい記事を書いてしまったので、早めにまとめが来るような書き方をしました。そこだけでも読んでいただければ🙏
はじめに
レバテック開発部でバックエンドエンジニアをしている瀬尾です!
テックブログ運営も担当しており、今年はアドベントカレンダーを企画しました〜
その 1 日目として今回の記事を書いています。
バックエンドといえば、関数型スタイルで書くと型システムを最大限利用できたりテストしやすくなったり、自己文書化されたりして保守性がいいぞ!といった話を最近よく目にするようになりました。
レバテック開発部であつかう領域は状態が多く複雑性が高いため、そういったエッセンスを取り込んで、どうにか整理していきたいと考えています。
そこでこの記事では、Haskell を通して関数型の何たるかを言語から感じたいと思います。
前提
私は普段 TypeScript や PHP を書いていて、Haskell に関してはずぶの初心者です。キャッチアップのメモをコード解説っぽく残しながら、僕と同じようなレベル感の人がこの記事で Haskell をふんわり読めた気になってくれたらと思っています。
関数型プログラミングに関していうと、なっとく本 や F#関数型ドメインモデリング本 をかじった程度の知識があります。
具体的には、高階関数/カリー化/部分適用/全域関数 といったワードは理解しているつもりです!
あと F# のコードも、上の本を読んだ程度にはなんとなく読めます。
また、プログラミングの上達方法に 写経 があるといいます。といっても自分はあまりそれをしたことがないので、今回は自分にとって未知の言語を写経してみて、どんなもんじゃいというのを感じたいと思っています。
題材
こちらの「JSON Parsing from Scratch in Haskell | abhinavsarkar.net」(以下、abhinav 記事と呼びます)を写経していこうと思います!
Haskell 自体に関しては、出てきた情報に都度キャッチアップしながら書いていく所存です。
写経した感想
突然なのですが、全体の感想 に入ります!
以降が鬼のように長くなってしまったので、Haskell の JSON パーサー自体は興味ある人だけに読んでいただいて、先に写経を通した "個人的な感想" を書いて中締めしたいと思います。変なこと言うてたらすみません。
(飲み会以外で初めて中締めってワード使ったな…)
型の流れみたいなもの
それを関数型だっていうのかもしれませんが、型の流れを強く意識させられました。
- 全てに型があって、値も関数もまずどんな型であるか考えるのだなと思いました
- 演算子もコンストラクタ的なものもどんな型シグネチャを持つのか考えたり、そのあと式変形のような要領で型クラスのインスタンスを実装したり…
- 具体的な値を考えない型の時点で問題を解決していく ような感覚がありました
TS とは違う型のメンタルモデル
自分の型に対する考え方が根本的に違ったかもと思いました。
型の流れの意識に通ずる話で、上手くいえないふんわりイメージですが…
「number 型の値が 2 つあるはずだから number を 2 つ持った Interface を作る」ではないんだな~みたいな、型安全のためだけに型を使っていたな~ みたいなことを思いました。
- 僕の考えが浅いだけかもしれませんが、TS ではそんなメンタルモデルで型を導入していく感覚がありました
- これはなにか具体の値を扱いやすくするために型を考えてるような感覚で、その型を取り巻く背景を考慮していないというか、なんだか点みたいに捉えているイメージでした
- Haskell だと「型を扱うこと = 概念的に値を扱うこと」という感覚で、今までの自分とは型の導出までのアプローチが異なると感じました
正確に説明できてる感じがしないけど大目に見てください🙏
Rust を勉強してるときに感じたやつの型バージョン
Rust を書くとあまり考えてこなかったメモリ管理を意識させられるように、Haskell を書くと考えてこなかった値の背景にある概念としての型を意識させられるなと感じました。
これが強制的に感じさせられるものなのか、今回の題材がよかったのかはわかりません(abhinav 記事でしか Haskell を書いてないので!)
- 何もかも型で説明されるから、ひとつの型をとってもその定義から成り立ちや背景まで考えさせられた感覚があります
- TypeChallenge の型パズル的な何かを感じましたw
- TypeChallenge は、具体である値のために型を考えさせられるイメージがあるけど、Haskell は常に抽象を考えさせられて具体のことはあまり考えなかった気がしました
型クラス
写経してみる前は型クラスの名前にビビっていましたが、上で述べたような抽象を考えていくときに便利なツールなんだなと思いました。
- これのおかげで「持ち上げ」といった動作が可能になり、Result 型みたいな文脈があっても処理をシンプルに記述できることがわかりました
- TypeScript で関数型プログラミングをやろうとするとサードパーティのライブラリに頼らざるをえないことの理由をなんとなく察しました
写経
当然といっちゃ当然なのですが、未知の言語で写経に取り組むと「手の運動」になりかねません。
やるなら、知っている言語の何らかのアプリにするか、今回やったようにしっかりキャッチアップしながら進めるかだなと思いました。
今回の自分のやり方でも、ここまで書いたような感想を得られたので、無駄ではなかったように感じました。
以降は本編であり、かつおまけ的な内容です!
JSON パーサーの導入
言語仕様
abhinav 記事では JSON 言語仕様のリファレンスとして、RFC 8259 を使用していきます。JSON の言語仕様をちゃんと見たことはなかったのでまとめてみます。
-
スカラー型
-
Null:
nullの文字列 -
Boolean:
truefalseの文字列 -
String:
""で囲まれた0個以上の Unicode 文字(特殊文字のエスケープや 16 進数表記もある) -
Number: 整数部、小数部、指数部の組み合わせ(
0,1234,1.23,0.222,1e5,5E-45,1.23e9,1.77E-9みたいなの)
-
Null:
-
複合データ型
-
Array:
[]で囲まれた 0 個以上の JSON の値 -
Object:
{}で囲まれた 0 個以上の Key-Value ペアになった値
-
Array:
-
空白文字
- スペース
\n、リターン\r、タブ\tを含む0個以上の文字列
- スペース
これらを以下では JSON 値、JSON 〇〇型と呼んでいきます。
JSON 値は複合データ型の中身でわかる通り再帰的であり、任意の空白文字で囲まれています。
また、JSON の文法は、文脈自由文法のサブセットである決定論的文脈自由文法(Deterministic Context-Free Grammar)です。これは、決定論的であるため同じ入力に対して複数の解析木が生まれることがないということを示します(ドヤ顔で語っているが、abhinav 記事の受け売り)
構文解析
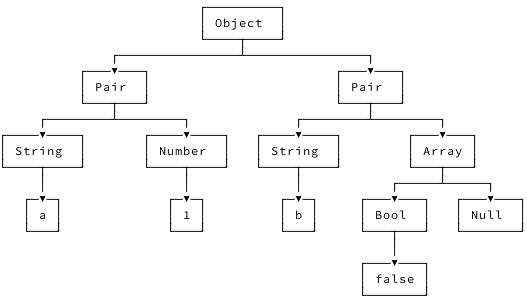
{"a": 1, "b": [false, null]} の解析木(abhinav 記事より引用)
構文解析(Parsing) とは、テキスト形式の入力データを受け取って、構文が正しいかチェックしながらデータ構造に変換するプロセスです。この記事では、テキスト形式の JSON データを Haskell の内部データ構造に変換していきます。
文脈自由文法の一般的な構文解析アルゴリズムは大きく分けて 3 つあるそうですが、今回は 再帰下降パーサー(Recursive Descent Parser) を実装します。これは、入力に対して相互再帰的な処理を行うトップダウンパーサーです。トップダウンとは解析木のルートからリーフノードに下っていくという意味で、相互再帰とは複数の関数のあいだで再帰になっているという意味です。
今回は、Parser Combinator という単純なパーサーを組み合わせて複雑なパーサーを作成する方法で実装していきます。大きなパーサーは高階関数で表現していきます。
写経|JSONパーサーの準備編
以降の章では abhinav 記事をかいつまみながら、Haskell 周りでキャッチアップしたことについて記述していくコードリーディングのメモになります。
間違ったこと書いてたらすいません!そのときはコメントで教えてもらえると…🙏
Haskell の環境構築は、こちらの記事を参考にさせていただきました。
abhinav 記事では、パーサーを Haskell の基本ライブラリだけで実装していきます。
基本の JSON 型を定義したあと、それぞれの型に対するパーサー実装 → その実装のリファクタリングを繰り返して、最終的に下記のようなすごくスッキリした感じのパーサーが出来上がります。
jValue :: Parser String JValue
jValue = jValue' `surroundedBy` spaces
where
jValue' = jNull
<|> jBool
<|> jString
<|> jNumber
<|> jArray
<|> jObject
リファクタでは、難関そうなイメージがある Functor, Applicative, Alternative, Monad といった型クラスの概念が自然と導入されていく流れがあり、非常に面白かったです。
JSON 値の型定義
data JValue = JNull
| JBool Bool
| JString String
| JNumber { int :: Integer, frac :: [Int], exponent :: Integer } -- タプル
| JArray [JValue] -- 再帰
| JObject [(String, JValue)] -- 再帰
deriving (Eq, Generic)
JSON 値型 JValue は J〇〇 の直和で表現されます。それぞれの要素 J〇〇 は、その次に示された型の値を引数にとるコンストラクタとなります。
JSON 数値型 JNumber は、整数部(int)・小数部(flac)・指数部(exponent) を表現するタプルになっています。小数部だけ整数のリスト [Int] になっていますが、これは先頭に0を持つことがあるからです。
パーサーの定義
パーサーは入力を受け取って一部を解析し、対応するデータ構造へ解析します。そして解析していない残りの入力は、後で解析できるように残しておきます。次のような関数となります。
newtype Parser i o =
Parser { runParser :: i -> Maybe (i, o) }
-- ここで、runParser :: Parser i o -> i -> Maybe (i, o) でもある
Parser は、入力 i を受け取って出力 Maybe (i, o) を返す関数 runParser のラッパーです。出力が Maybe 型(Result 型みたいなの)なので、パースに成功すれば残りの入力とパースした出力 Just (i, o) を返しますが、失敗であれば何も返しません。
data Maybe a = Nothing | Just a -- a は任意の型
この後はこの定義を使って、各 JSON 値のパーサーを実装していきます。
Char パーサー
JSON パーサーのためのパーサーを実装していきます。
ここでは、入力文字列の最初の文字を指定された文字とマッチさせるパーサーを書きます。
char1 :: Char -> Parser String Char -- 1
char1 c = Parser $ \case -- 2
(x:xs) | x == c -> Just (xs, x) -- 3
_ -> Nothing -- 4
-
char1の型シグネチャとして、Char 型で 1 文字を受け取って、String 型の文字列を入力、Char 型をパース済みの出力とするパーサーParser String Charを出力することを表しています。 -
$演算子で、右側の LambdaCase 式(パターンマッチの入力を省略して記述するやつ)をパーサーに渡しています。$によってカッコを省略してます。 - cons 演算子
:は値をリストの先頭に加える関数であり、String に対して Char リストの先頭と残りを分ける構造とのパターンマッチができます(Haskell の String は Char のリストだから)。
それにマッチした場合は先頭文字xに対してガード条件| x == cで指定の文字と一致するかを確認しています。 - 一致しなければ、
Nothingを返します。
Char パーサーのリファクタ
パーサー char1 のガード条件 | x == c を一般化して、任意の条件を適用できるようにした char を実装します。
satisfy :: (a -> Bool) -> Parser [a] a
satisfy predicate = Parser $ \case
(x:xs) | predicate x -> Just (xs, x)
_ -> Nothing
char :: Char -> Parser String Char
char c = satisfy (== c)
任意の型 a を用いた述語関数 (a -> Bool) を受け取ってパーサーを生成する関数 satisfy を実装しました。
Haskell では関数やその演算子がカリー化されており、(== c) はあと c と比較したい値を受け取るだけの、部分適用された述語関数となります。
よって (== c) を与えると、String 型(= [Char] 型)と Char 型を入力とした Parser String Char を返します。
こうして、Char パーサーは satisfy を使った小さな関数になりました。
Digit パーサー
これも JSON パーサーのためのパーサーです。
先程の satisfy を使用して、下記のように書くことができます。
digit1 :: Parser String Int
digit1 = Parser $ \i -> -- 1
case runParser (satisfy isDigit) i of -- 2
Nothing -> Nothing
Just (i', o) -> Just (i', digitToInt o) -- 3
digit1 は、入力文字列 i を受け取って 0~9 に一致した場合、残りの入力 i' とパース済みの整数 digitToInt o を返すパーサーです。
(余談ですが、Haskell では元の値に関連した値を表現するときにアポストロフィーを付けて表現する慣習があるそうです。数学っぽい!)
-
iを入力にもつラムダ式\iを Parser に渡しています。 -
(satisfy isDigit)から返される、先頭が数字であると成功するパーサーString -> Maybe (String, Char)を入力iに適用しています。 - 結果の値
Maybe (String, Char)が成功していた場合、出力をdigitToIntで整数として返します。
Functor としてリファクタしていく
class Functor f where
fmap :: (a -> b) -> f a -> f b
この定義の例として、fmap (*2) [1, 2, 3] は [2, 4, 6] を返します。
Functor 型クラスのメソッドである fmap は、関数 (a -> b) を受け取ると、f a -> f b を返します。例で関数にあたるのは (*2) で、これは (Int -> Int) の関数です。
f は a, b それぞれを格納するデータ型のコンストラクタで、例ではリスト [] です。fmap は、リストに格納された Int 型の値に対して関数を適用しています。
タプルを fmap で表現する
タプル型は、第一要素を固定した状態で Functor のインスタンスとなっています[1]。
instance Functor ((,) a) where
fmap f (x, y) = (x, f y)
補足:カンマはタプル型のコンストラクタ
(== c) が部分適用された関数になる話に似ているのですが、タプル型を構成するときの記号であるカンマは、以下のような関数として定義してあります。
(,) :: a -> b -> (a, b)
この定義にしたがって、3の出力の部分を fmap を使って表現します。
Just (i', digitToInt o)
-- ↓ fmap との合成関数で表現
Just . fmap digitToInt $ (i', o)
ここで、. は合成関数を表す演算子であり、(f . g) x = f (g x) となります。(i', o) が x にあたる部分で、出力に digitToInt を適用したあと Maybe コンテナに格納します。
パターンマッチを fmap で表現する
case runParser (satisfy isDigit) i of
Nothing -> Nothing
Just (i', o) -> Just . fmap digitToInt $ (i', o) -- さっきfmapになった部分
-- ↓ 上のパターンマッチをfmapと合成関数で表現
Parser $ \i -> fmap (fmap digitToInt) . runParser (satisfy isDigit) $ i
-- ^^^^^^^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^^^^^^^^^^^^^^^^ ^
-- f g x
合成関数 fmap (fmap digitToInt) . runParser (satisfy isDigit) に入力 i を与える形になりました。
最初に実行される (g x) にあたる部分は Maybe (String, Char) を返します。これに対して、f にあたる部分は 2 重に fmap を適用しています。最初の fmap は Maybe コンテナに対するもので、次の fmap は先程のタプルに対するものです。前段の出力である Maybe コンテナを一旦無視するような表現になっています。
Parser 型の Functor インスタンスを定義
Functor は、fmap の動作のとおり、ひとつの型引数をとる型コンストラクタに対して定義される型クラスです。Parser 型において、入力の型引数を与えた Parser i は出力であるパース後の型 o をとるコンストラクタになります。そのため、Parser i を Functor のインスタンスにすることができます。
instance Functor (Parser i) where
fmap f parser = Parser $ fmap (fmap f) . runParser parser
Parser 型に対しての fmap は下記のような定義になります。
fmap :: (a -> b) -> Parser i a -> Parser i b
パーサーの結果である Maybe コンテナに対して関数 (a -> b) を適用して、パースの出力を変換できるようになっています。
結果的に Digit パーサーは下記のように書くことができます。
satisfy isDigit から返ってくるパーサー String -> Maybe (String, Char) のパース結果に対して、fmap で digitToInt を適用しています。
digit :: Parser String Int
digit = digitToInt <$> satisfy isDigit
ここで、<$> は fmap の演算子です。fmap (*2) [1, 2, 3] も (*2) <$> [1, 2, 3] も [2, 4, 6] を返します。
書き方 1 つでめっちゃスッキリになるところがとても数学っぽいなと思いました。
String パーサー
String パーサーは、先に定義した Char パーサーを利用しつつ、再帰的に書きます。
string1 :: String -> Parser String String
string1 s = case s of
"" -> Parser $ \i -> Just (i, "")
(c:cs) -> Parser $ \i -> case runParser (char c) i of
Nothing -> Nothing
Just (rest, _) -> case runParser (string1 cs) rest of
Nothing -> Nothing
Just (rest', _) -> Just (rest', c:cs)
string1 は、入力文字列から s と完全一致する部分を抽出するパーサーを返します。完全一致しない場合は Nothing を返します。
s が空文字列でない場合、先頭の文字が char c で入力として利用されて、成功したら残りの文字列 cs にまた同じ処理を行って、最終的に完全一致したら Just (rest', c:cs) を返します。c:cs はパースしたい文字列 s と同じです。
Applicative としてリファクタしていく
string2 :: String -> Parser String String
string2 s = case s of
"" -> Parser $ pure . (, "") -- 1
(c:cs) -> Parser $ \i -> case runParser (char c) i of
Nothing -> Nothing
Just (rest, c) -> fmap (c:) <$> runParser (string2 cs) rest -- 2
Functor を利用して、ネストが減りました。変化したのは 2 箇所です。
- pure 関数は
pure :: a -> f aと表され、入力をfのコンテキストに持ち上げます。
(, "")はタプル型コンストラクタの部分適用で、Parserに(a -> Just (a, ""))を渡している元のコードと同じです。 -
runParser (string2 cs) restはパース残りの文字列csのパースを行い、Maybe (rest' パースされたcs)型を返します。
fmap (c:)は、文字列の先頭にcを追加する関数(c:)をパース成功した Maybe のタプル型のタプル部分に適用します。
つまり、これも元のJust (rest', c:cs)と同じです。
Parser の Applicative インスタンスを定義
Applicative 型クラスは、Functor を継承した型クラスです。
class Functor f => Applicative f where
pure :: a -> f a
(<*>) :: f (a -> b) -> f a -> f b
Parser はすでに Functor のインスタンスとなっており、Applicatve のインスタンスになることができます(本当はそのための他いくつかの条件も満たしているという理由もある)
instance Applicative (Parser i) where
-- pure の実装
pure x = Parser $ pure . (, x) -- > Parser $ \input -> Just (input, x)
-- <*> 演算子の実装
pf <*> po = Parser $ \input -> case runParser pf input of
Nothing -> Nothing
Just (rest, f) -> fmap f <$> runParser po rest
pure は入力と x をそのまま Maybe (input, x) 型にもちあげるパーサーを返します。
また、<*> 演算子は Parser i (a -> b) -> Parser i a -> Parser i b という定義です[2]。
pf :: Parser i (a -> b) は入力を受け取って出力 Maybe (i, a -> b)を返します。
po :: Parser i a は残りの入力を受け取って出力 Maybe (i, a) を返します。
fmap f <$> は展開すると fmap (fmap f) となり、runParser po rest の出力となる Maybe (i', a) 型のタプルの型変数 a に対して関数 f を適用する形になります。
このことを用いて、String パーサーを簡潔に定義することができます。
string :: String -> Parser String String
string "" = pure ""
string (c:cs) = (:) <$> char c <*> string cs
入力として空文字を与えられたら、Maybe (input, "") を返します。
入力が空文字でない場合、先頭の文字から再帰的にパースします。
(:) <$> char c は、先頭文字パーサー char c の結果 Parser String Char の出力側に対して、(:) での結合を部分適用したパーサー Parser String (String -> String) です。
これと残りの文字列に対する再帰パーサー string cs を <*> 演算子で組み合わせると、string の型である Parser String String に適用して、出力のパース済み文字を結合していく String パーサー Parser String String ができます。
ネストがなくなり、再帰処理も 1 行でスッキリと書けてしまいました。きもちいい〜
写経|JSONパーサー編
ここまで実装した char, digit, string パーサーを使って JSON 値のパーサーを実装していきます。
JNull パーサー
JSON Null 型のパーサーを実装します。
jNull :: Parser String JValue
jNull = string "null" $> JNull
String パーサーで null の文字列をパースして、成功したら JNull を返します。
ここで登場する見慣れない演算子は Functor のもので、定義は ($>) :: f a -> b -> f b です[3]。
string "null" が返すパーサー Parser String String(f a)に JNull のコンストラクタ(b)を適用することで、成功したときに JNull を返すパーサー Parser String JValue が得られます。
JBool パーサー
JSON Bool 型のパーサーを実装します。
Bool 値のパーサーは true の文字列をパースして、失敗したら false の文字列をパースして…と実行する必要があります。このような解の候補から条件を満たすものを見つける方法を、バックトラック法といいます。
Haskell では、バックトラック法を Alternative 型クラスの <|> 演算子を使うことで簡単に実現できます。
instance Alternative (Parser i) where
empty = Parser $ const empty
p1 <|> p2 = Parser $ \input -> runParser p1 input <|> runParser p2 input
jBool :: Parser String JValue
jBool = string "true" $> JBool True
<|> string "false" $> JBool False
Alternative で書いた順番の通りに、失敗したら次のパーサーで処理していく流れを実装しました。
JString パーサー
JSON String 型は、エスケープや 16 進数表記の Unicode、制御文字を含みます。それらをいい感じに取り扱うため、はじめに JSON Char パーサーを実装します。
jsonChar :: Parser String Char
-- 特殊文字 -> 一般文字と処理したいため、この順序で実装
jsonChar = string "\\\"" $> '"'
<|> string "\\\\" $> '\\'
<|> string "\\/" $> '/'
<|> string "\\b" $> '\b'
<|> string "\\f" $> '\f'
<|> string "\\n" $> '\n'
<|> string "\\r" $> '\r'
<|> string "\\t" $> '\t'
<|> unicodeChar -- 下に定義してある unicode パーサー
<|> satisfy (\c -> not (c == '\"' || c == '\\' || isControl c)) -- 「"」「\」「ASCII制御文字」以外の通常文字パーサー
where
-- "\u" の後に続く4つの数字から、Unicodeで対応する文字を得るパーサー
unicodeChar =
chr . fromIntegral . digitsToNumber 16 0
<$> (string "\\u" *> replicateM 4 hexDigit)
Unicode 対応
Unicode 標準は、基本多言語面(Basic Multilingual Plane, BMP)でカバーされる U+0000~U+FFFF の 16 ビットの範囲に一般的な文字を割り当てて表現しています。それ以外の絵文字 🎅 や音楽記号 𝄞 等は、それらを拡張した範囲で割り当てられています。そのような文字は 16 ビットを超えた値で表現されるため、その値から 16 ビットの値の対であるサロゲートペアを求めて、そのペアを使ってエンコードします。
例えば、ト音記号 𝄞 のコードポイントは U+1D11E で、サロゲートペアは (U+D834, U+DD1E) です。
つまり Unicode である JSON 文字列型は、一度に一文字ではなく文字のペアを考慮する必要があります。
Monad インスタンスとして JString パーサーを実装
Monad を使って、最初に 2 文字を読み取ったときに有効なサロゲートペアが見つかるかに応じて異なる処理をできるように実装します。Monad を使うことで、ある操作の結果に基づいて次の操作を実行するような、文脈をもった計算を書くことができます。
instance Monad (Parser i) where
p >>= f = Parser $ \input -> case runParser p input of
Nothing -> Nothing
Just (rest, o) -> runParser (f o) rest
ここで定義した >>= はバインド演算子です。他言語の "andThen" っぽいやつらしい!
パーサー p を入力に適用、成功して Just (rest, o) を得たら、f に前段の出力 o を適用したパーサーを残りの文字列 rest に適用して、最終的なパース結果を得るという流れを実装できます。
これを使って JString パーサーを実装します。
>>= の代わりにその糖衣構文である do 式を使って、バインド演算子にあたる順次処理をわかりやすく記述します。演算子は登場しないけど、do 内の処理は >>= で連結されています。
jString :: Parser String JValue
jString = JString <$> (char '"' *> jString') -- 1
where
jString' = do
optFirst <- optional jsonChar -- 2
case optFirst of
Nothing -> "" <$ char '"' -- 3
Just first | not (isSurrogate first) -> -- 4
(first:) <$> jString' -- 5
Just first -> do -- 6
second <- jsonChar -- 7
if isHighSurrogate first && isLowSurrogate second -- 8
then (combineSurrogates first second :) <$> jString' -- 9
else empty -- 10
optFirst や second に値を束縛して、それに応じた分岐を記述しています。パーサーが失敗したらそれが伝播して処理が中断されます。
-
"をパースに成功したら where で定義しているパーサーjString'に残りの入力を渡して、最終的な結果にJStringコンストラクタを適用しています。 - 受け取った残りの文字の先頭をパースした
jsonCharの結果を Maybe 型に詰めて、optFirstに格納します。
このあとはoptFirstの値によって 3 つに分岐します。 - 次の文字をパースして
"(文字列おわり)だったら、左側の空文字を返します。 - 最初の文字
firstが存在し、かつサロゲートペアを判定するヘルパー関数isSurrogateが false だった場合 -
jString'を再帰的に実行して、その結果をパース済み文字と順に結合して返します。 - 最初の文字
firstがサロゲートペアだった場合 - 2 文字目を
jsonCharでパースしてsecondとして得ます。 - 1 文字目と 2 文字目がサロゲートペアとして有効かをヘルパー関数によって判定します。
- 有効であれば、2つのサロゲートペアをヘルパー関数
combineSurrogatesで結合して Unicode 文字を得て、5 のように残りの文字列をjString'によってパースし、結果を結合して返します。 - 有効でなければ
empty(Alternative での失敗)を返します。
JNumber パーサー
JSON 数値型は、冒頭に示したとおり様々な形式をとります。
JNumber { int :: Integer, frac :: [Int], exponent :: Integer } 型を作るために、下記のようなパーサー jNumber を実装します。
jNumber :: Parser String JValue
jNumber = jIntFracExp <|> jIntExp <|> jIntFrac <|> jInt
それぞれ下記のパーサーから構成されており、<|> 演算子で左から順に試して最初に成功した結果を返します。
-
jIntFracExp: 整数部分 + 小数部分 + 指数部分 -
jIntExp: 整数部分 + 指数部分 -
jIntFrac: 整数部分 + 小数部分 -
jInt: 整数部分のみ
まずはそれぞれの JSON 数値パーサーで使う道具を実装します。ヘルパー関数については省略します。
-- 符号なし整数のパーサー
jUInt :: Parser String Integer
jUInt = (\d ds -> digitsToNumber 10 0 (d:ds)) <$> digit19 <*> digits
<|> fromIntegral <$> digit
-- 符号あり整数のパーサー
jInt' :: Parser String Integer
jInt' = signInt <$> optional (char '-') <*> jUInt
-- 小数点以下の数値パーサー
jFrac :: Parser String [Int]
jFrac = char '.' *> digits
-- 指数部である e 以降の数値パーサー
jExp :: Parser String Integer
jExp = (char 'e' <|> char 'E')
*> (signInt <$> optional (char '+' <|> char '-') <*> jUInt)
-
jUInt: 符号なし整数のパーサー
digit19 :: Parser String Intを使って最初の数字の 1~9 をパースして数値を返します。
digits :: Parser String [Int]を使って残りの数字をパースして数値リストを返します。
前者の結果を後者に適用して整数部を[Int]型で得て、整数に変換します。1 桁の場合はそれだけをパースし、同様にして返します。 -
jInt': 符号あり整数のパーサー
-をパースしてjUIntの結果に適用、パースした符号に基づいて数値型を返します。 -
jFrac: 小数点以下の数値パーサー
.をパースできたら、その後の数字をパースして数値リストを返します。 -
jExp: 指数部である e 以降の数値パーサー
符号あり整数と小数パーサーと同様の操作をしています。
この道具を用いて、JNumber パーサーの要素はこのように実装できます。
jInt :: Parser String JValue
jInt = JNumber <$> jInt' <*> pure [] <*> pure 0 -- ない部分は pure で持ち上げる
jIntExp :: Parser String JValue
jIntExp = JNumber <$> jInt' <*> pure [] <*> jExp
jIntFrac :: Parser String JValue
jIntFrac = (\i f -> JNumber i f 0) <$> jInt' <*> jFrac
-- JNumber <$> jInt' <*> jFrac <*> pure 0 としてもよいはずだが
-- 整数部と小数部をそれぞれ i, f として受け取る形で実装している
jIntFracExp :: Parser String JValue
jIntFracExp = (\ ~(JNumber i f _) e -> JNumber i f e) <$> jIntFrac <*> jExp
-- ラムダ関数では jIntFrac の結果から i, f を取り出し、指数部を jExp の結果で更新する形となっている
-- `~` を使うとjIntFracの結果に対するパターンマッチを遅延できる
これらを組み合わせると、JNumber パーサーは
jNumber = jIntFracExp <|> jIntExp <|> jIntFrac <|> jInt
と実装できます。
JArray パーサー
JSON 配列型は再帰的な構造をとり、カンマで区切られた任意の JSON 値を 0 個以上持つことができます。また、そのアイテムの間に任意の量の空白を含むこともできます。
それらを考慮するための関数を用意します。
-- p2 -> p1 -> p2 という順でパースして、p1 の結果を返す
-- `*>`, `<*` はそれぞれ p2 の結果を無視する
surroundedBy :: Parser String a -> Parser String b -> Parser String a
surroundedBy p1 p2 = p2 *> p1 <* p2
-- 要素 `v` とセパレーター `s` を繰り返しパースして、要素のリストを返す
separatedBy :: Parser i v -> Parser i s -> Parser i [v]
separatedBy v s = (:) <$> v <*> many (s *> v)
<|> pure []
-- 空白文字を 0 回以上パース
-- 空白文字をスキップするためにつかう
spaces :: Parser String String
spaces = many (char ' ' <|> char '\n' <|> char '\r' <|> char '\t')
これらを使うと、下記のように JArray パーサーを実装できます。
jArray :: Parser String JValue
jArray = JArray <$>
(char '['
*> (jValue `separatedBy` char ',' `surroundedBy` spaces) -- jValue はまだ未定義の JSON 値パーサー
<* char ']')
ここで、バッククォートは中置演算子として関数を使用する構文です。
separatedBy の型シグネチャにおいて jValue `separatedBy` char ',' は、i が String、v が JValue、s が Char です。よって、このパーサーの型は Parser String [JValue] となります。
このパーサーと space を surroundedBy に与えて、最終的に JValue のリストが得られます。
JObject パーサー
JObject パーサーは、 JArray パーサーで出てきた知識を使って実装できます。
jObject :: Parser String JValue
jObject = JObject <$>
(char '{' *> pair `separatedBy` char ',' `surroundedBy` spaces <* char '}')
where
pair = (\ ~(JString s) j -> (s, j))
<$> (jString `surroundedBy` spaces) -- Key のパース
<* char ':' -- keyValue ペアのセパレーター
<*> jValue -- Value のパース
JValue パーサー
これまで実装したパーサーを数珠つなぎにして、冒頭でお見せした JValue パーサーを実装できます。
jValue :: Parser String JValue
jValue = jValue' `surroundedBy` spaces
where
jValue' = jNull
<|> jBool
<|> jString
<|> jNumber
<|> jArray
<|> jObject
jValue を使って実際に JSON をパースする関数 parseJSON を定義できます!
parseJSON :: String -> Maybe JValue
parseJSON s = case runParser jValue s of
Just ("", j) -> Just j
_ -> Nothing
長かったけど、とてもスッキリした実装になって気持ちいい~!
おわりに
まず、abhinav さんの記事が素晴らしかったです。
全体として流れがよく、Functor, Applicative, Alternative, Monad といった型クラスの導入が鮮やかだなと思いました。また、リファクタして一般化、そこから Functor などの形を見抜く流れ、その 式変形 感から数学っぽさを感じて感動しながらコードを読みました!
abhinav さんありがとうございます!
また、パーサーは初実装でした!
JSON はまだ単純なほうだといっても、さまざまな仕様を考慮するのは大変なんだな~と思いました。
写経については、書けたとは言っても Haskell 初見では無謀気味だった気がします。やるにしても、入門した人が言語特性や型クラスの使い所を定着させるためにやるのがちょうどよさそうだなと思いました。
ただ頑張ってキャッチアップすれば書いてるものの意味はわかったので、楽しめました!
解説するのに集中するため端折りながら説明したので、気になる方は abhinav さんの元記事を読んでみてください!
反省
ちゃんとテストを動かして動作確認できなかったです;;
- 今回写経したコードは こちら のリポジトリに置いてあります!みたいなことを言うつもりだったんですが、Haskell の開発環境自体を理解する時間が間に合わず、用意できませんでした。
- QuickCheck のテストをどう動かせばいいかわからなかったり、写経しただけではそのまま動いてくれない部分があったり(?)で、その解決より
アドカレの記事を完成させるコードを理解することを優先したためです。 - のちのち公開しようと思います!アジャイル🙏
アドベントカレンダー
明日は もりた さんが投稿します~
「レバテック開発部 Advent Calendar 2024」をぜひご購読ください😉

Discussion