はじめてのFaster-RCNN
本記事の構成
本記事では,主要な物体検知モデルの一つである Faster-RCNN について解説した記事です.この記事では,Faster-RCNN の処理過程について概略を示した後に,各処理の詳細について触れます.このような構成にすることで,全体像を踏まえつつ,興味のある部分や必要な部分に重点的にフォーカスできるようにしています.
本記事で扱うこと,扱わないこと
扱うこと
- Faster-RCNN がどういうモデルか
- 物体検知モデルの処理過程と詳細
扱わないこと
- Faster-RCNN の学習方法
- Faster-RCNN のロスの計算式
Faster-RCNN とは
Faster-RCNN は 2016 年に Shaoqingらによって提案された物体検知モデルアーキテクチャです.2016年に提案されたモデルですが,現在でも用いられています. (厳密にはFaster-RCNNの改良版)
Faster-RCNN 以前の物体検知モデルとその課題
Faster-RCNN 以前のモデルでは,物体の位置の特定とクラスの識別には異なる手法が用いられていました.具体的には,クラスの識別にCNNが用いられることはありましたが,画像中の物体領域の特定にはCNNは用いられず,selective searchと呼ばれる方法が主に用いられていました.Selective search は,古典的な画像処理に基づく手法で画像の領域を抽出します.この手法は計算コストが高く,実行時間がかかることが問題視されていました.
Faster-RCNNの革新的な点
そのような背景の中,Faster-RCNN は物体の位置の特定をCNNで行えるようにし,物体の位置の特定からクラスの判定まですべてCNNで行うことに成功しました.これにより高速かつ精度よく物体の検知が可能となりました.
Faster-RCNN の処理の概要
Faster-RCNN はまず,画像をCNNを用いて特徴量を抽出します. (以下これを特徴量画像と呼びます.)
その後,2つのステップで処理が行われます.
- その特徴量から特徴量画像中の物体の位置を推定する
- 特徴量画像で推定された物体の領域をもとにクラス推定をする
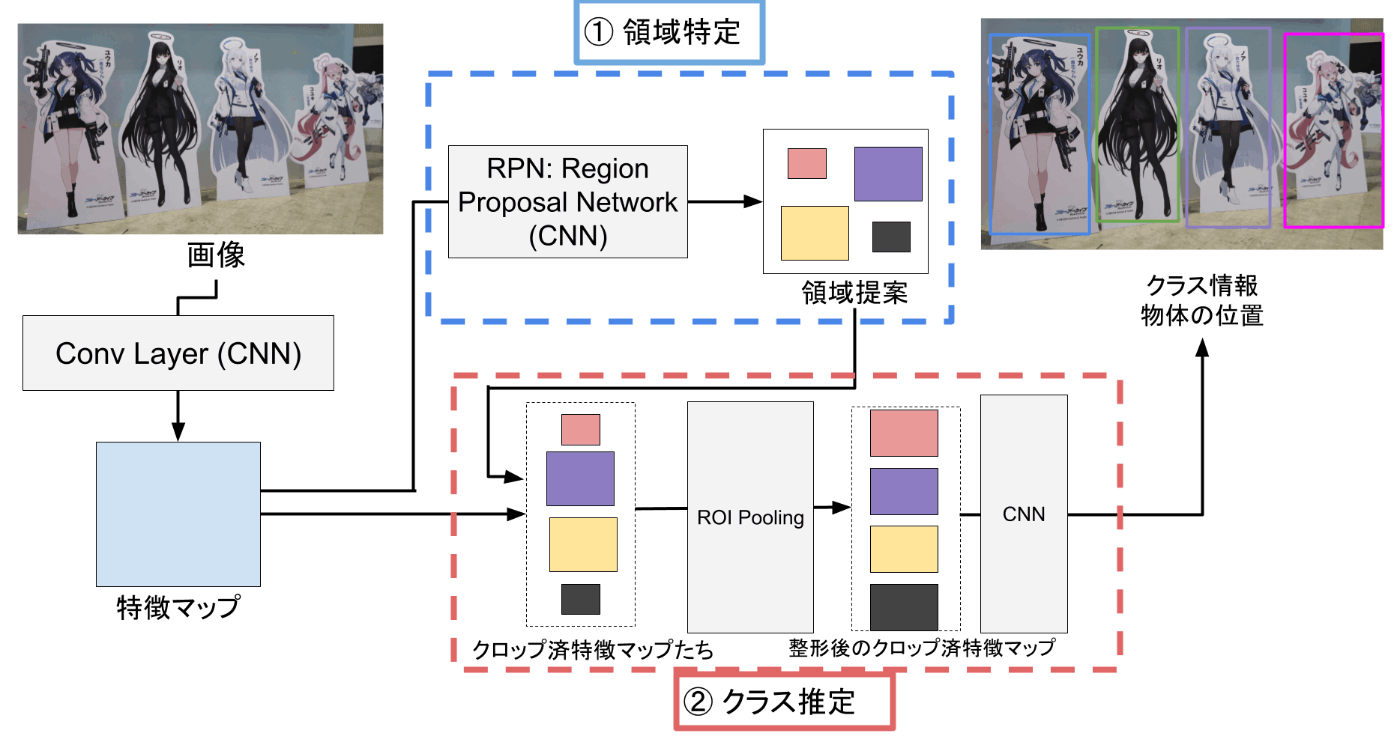
Faster-RCNNの処理の概要.図中のグレーのボックスはCNN等による処理を示す.文字単体 (e.g. 特徴マップ,領域提案)は何らかのデータを示す.
- ①の部分では,RPN (Region Proposal Network)と呼ばれるCNNを用いて,特徴マップ中の物体の特徴量がある位置とその物体らしさを推定します.
- ②の部分では,1.をもとに抽出した物体の特徴量を前処理 (ROI Pooling)をした上で,分類器に入れ,クラスと物体の位置を推定します.
厳密には①で検知した領域全てではなく一部のみを用います.これは各処理の詳細で述べます.
各処理の詳細
上の図の各処理を細かく見ていきましょう.以下に分けてそれぞれ見ていきます.
- 前処理の部分 (Conv Layer で特徴マップを出力するまで)
- ①の領域特定の部分
- ②のクラス推定の前半 (ROI Poolingの部分)
- ②のクラス推定の後半
1. 前処理の部分
特徴マップの抽出方法
ここでは,Covn Layerを用いて画像から有用な特徴マップを抽出する処理を行います.
この処理の目的は,後続の物体検出タスクに適した特徴表現を得ることです.原論文では,VGG netやZF netが出力する特徴マップが使用されていました.Conv Layerの性能を最適化するために,モデルの一部または全部のパラメータについて学習を行います.この過程をファインチューニングと呼び,特定のタスクや対象データセットに対してモデルを適応させることができます.このように,Conv Layerは単なる特徴抽出だけでなく,学習可能なコンポーネントとして機能し,全体の物体検出システムの性能向上に貢献しています.
改善版Faster-RCNNの特徴量抽出
なお,最近のFaster-RCNNでは,物体検出の精度向上を目指して,ResNet等のマルチスケールの特徴マップを採用することもあります.マルチスケールの特徴マップは,物体検出タスクにおいて重要な役割を果たします.この手法では,異なる解像度の特徴量を同時に扱うことができ,これにより物体検出の精度向上が期待できます.
具体的には,マルチスケールの特徴マップを使用することで,二種類の重要な特徴量を得ることができます.一つは大局的な特徴量で,これは物体の全体的な形状や位置を捉えるのに役立ちます.もう一つは細部に注目した特徴量で,物体の詳細な特徴を表現します.
これら異なるスケールの特徴量を適切に組み合わせることで,物体検出システムは位置特定とクラス推定の両方において性能を向上させることができます.大局的な情報と詳細な情報の両方を活用することで,システムはより正確かつ頑健な検出結果を提供できるのです.
2. ①の領域特定の部分
ここは,RPN (Region Proposal Network) により特徴マップ中の物体位置と物体らしさのスコアを出力するフェーズです.
まずRPNの動作に必要な,アンカーの説明をした上でRPNの詳細な処理について説明します.
アンカー(Anchors)
アンカーはRPNが物体候補領域を提案する際の基準となる矩形領域です.特徴マップの各位置に対して,複数の異なるサイズとアスペクト比を持つ矩形を事前に定義します.元論文では,3種類のスケール(元画像で128x128,256x256,512x512 pixelsに相当する面積)と3種類のアスペクト比(1:1、1:2、2:1)の組み合わせの,計9種類のアンカーを各位置に設定します。
これらのアンカーは,物体候補領域の初期推定値として機能します.RPNは,これらのアンカーを基準に微調整を行います.
つまり,アンカーの数だけ領域が出力されることになります.その後RPNで出力する物体らしさの確率に基づいて,必要なもののみを後続の②の回帰に入れます.
RPNの構造
RPNは、特徴マップを入力として受け取り、以下の2つの出力をアンカーの数だけ生成します:
物体らしさスコア: 各アンカーが物体を含む確率
バウンディングボックス回帰値: アンカーの位置とサイズを調整するためのパラメータ
これらの推定には,一部モデルを共通したCNNを用いて処理を行います.
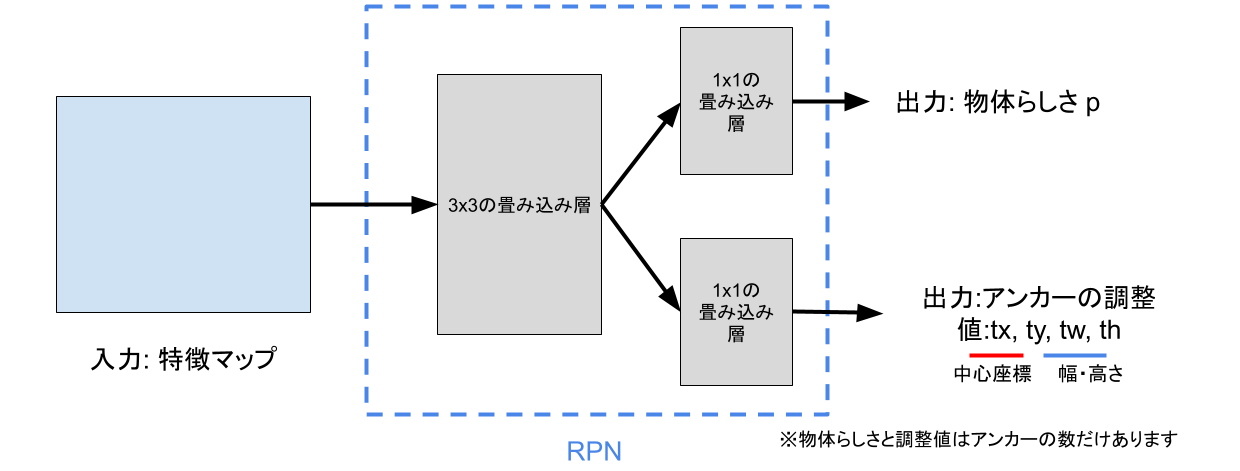
RPNの各詳細
3x3 畳み込み層
3x3の畳み込み層を使用して、特徴マップをさらに処理します。
この層は、RPN専用の特徴を学習します。
物体らしさ(Objectness)予測ブランチ
1x1の畳み込み層を使用します.
各位置の各アンカーに対して、背景か物体かの2クラス分類を行います。
バウンディングボックス回帰ブランチ
1x1の畳み込み層を使用し,各アンカーの位置とサイズを微調整するためのパラメータを出力します。
具体的には以下の4つのパラメータ(tx, ty, tw, th)を予測します:
tx, ty: アンカーの中心座標の調整値
tw, th: アンカーの幅と高さの調整値
そして,予測されたパラメータを使用して、アンカーを以下のように調整します:
Copyx = xa + wa * tx
y = ya + ha * ty
w = wa * exp(tw)
h = ha * exp(th)
ここで、(xa, ya, wa, ha)は元のアンカーの中心座標、幅、高さを表し、(x, y, w, h)は調整後のバウンディングボックスの値です。
後処理
RPNを通過した段階では,アンカーの数だけバウンディングボックスが存在し,物体ではないものやバウンディングボックスの重複等が発生している可能性があります.
正しく物体のみをダブリなくバンディングボックスとして抽出し,後続のクラス分類に入力するために,後処理を行います.
具体的には,ROIによって出力された物体らしさのスコア上位K件数について抽出したあとで,NMS (Non Maximum Surpression)と呼ばれる方法によって,バウンディングボックスの削除を行います.
詳細については省きますが,重複度合いを算出して,その値が一定以上であるものを削除していくことを繰り返します. (同様の説明で図が豊富なのは以下,具体的な手法の解説は以下が詳しいです.)
これらの処理により,物体が存在するバウンディングボックスのみを残し,次の段階(ROI Poolingと分類器)に渡されます。
クラス推定前半
ここでは,提案領域からクラス分類を行うための前処理をするフェーズです.
画像中の物体のサイズは様々なため,特徴量空間中で提案される領域も同一ではありません.そのため,後続のクラス分類がしにくいという問題があります.この処理の主な目的は,異なるサイズの候補領域(Region of Interest)から固定サイズの特徴マップを生成することです.
そのため,畳み込み層から得られた特徴マップと,Region Proposal Networkによって提案された候補領域(ROI)を入力とします.
ROIプーリングの処理では,まず各ROIを固定数のセクション(例えば7x7)に分割します.次に,各セクション内で最大値(max pooling)または平均値(average pooling)を取る操作を行います.この結果,すべての候補領域に対して,同じ固定サイズ(例:7x7)の特徴マップが生成されます.
この処理により,異なるサイズと形状の候補領域から,一貫したサイズの特徴表現を得ることができます.これは,後続の全結合層での処理を行えるようにします.
クラス推定後半
ROIプーリングによって生成された固定サイズの特徴マップは,Faster RCNNの検出ネットワークに入力されます.この検出ネットワークは,通常,複数の全結合層で構成されており,二つの主要なタスクを並行して行います:物体のクラス分類と境界ボックスの回帰です.
クラス分類では,ネットワークは各候補領域に対して,予め定義された物体カテゴリとバックグラウンド(物体なし)クラスの確率を出力します.この過程で,ソフトマックス関数を用いて各クラスの確率を計算し,最も高い確率を持つクラスをその候補領域の予測クラスとします.
同時に,境界ボックス回帰では,元の候補領域の位置と寸法を微調整します.これにより,物体をより正確に囲む境界ボックスを生成します.この調整は,x座標,y座標,幅,高さの4つのパラメータに対して行われ,より精密な物体の位置特定を可能にします.
最後に,非最大値抑制(Non-Maximum Suppression, NMS)を適用して,重複する検出結果を除去します.これにより,同じ物体に対する複数の検出を1つにまとめ,最終的な検出結果を得ます.この一連のプロセスにより,Faster RCNNは高精度で効率的な物体検出を実現しています.
Discussion