Leaner 開発チームの黒曜(@kokuyouwind)です。
先日の RubyKaigi 2024で Let's use LLMs from Ruby 〜 Refine RBS types using LLM 〜 というタイトルで登壇させていただきました!
参加しての感想は別記事にするので、この記事では発表の概要や裏話などをまとめます。
動画アーカイブ
発表スライド
自分の発表資料は slides.com というサービスでスライドを作っています。
埋め込み表示ができませんが、上記リンクから開くと発表時のスライドがそのまま見られます。
一応 Speaker Deck にもアップロードしていますが、 PDF 出力時にフォントが化けてしまっているためちょっと見づらいです。
発表の簡単な概要
Ruby の型定義である RBS を手で書くのは大変だし、既存手法の rbs prototype rb や typeprof で生成しても結局最後は手作業での修正が必要なので、そのあたりを LLM でうまくやれないか試してるよ、という趣旨の発表でした。
このためのツールとして RBS Goose を作っています。
RBS Goose を作った目的
例えば以下のような Config クラスがあったとします。
class Config
def self.configure(&block)
new.tap(&block)
end
%w[client role prompt].each { attr_accessor _1.to_sym }
end
これに対し、 rbs prototype rb lib/config.rb > sig/config.rbs とすると、以下の RBS ファイルが生成されます。
class Config
def self.configure: () { (untyped) -> untyped } -> untyped
end
この RBS では、 self.configure がブロックを受け取ることはわかりますが、それ以外の型はすべて untyped になっており、あまり情報が得られない型になっています。
また静的解析で RBS を生成するため、動的に定義される各種 attr_accessor は定義されていません。
ここで、事前に RBS Goose を使うよう定義した rake sig:refine コマンドを実行すると、以下のように sig/config.rbs の具体的な型が推測され、 RBS ファイルが更新されます。[1]
class Config
+ attr_accessor client: Langchain::LLM::OpenAI
+ attr_accessor role: String
+ attr_accessor prompt: String
+
- def self.configure: () { (untyped) -> untyped } -> untyped
+ def self.configure: () { (Config) -> void } -> Config
end
実際の出力結果は rbs_goose_test リポジトリの PR にまとめています。
RBS Goose の仕組み
内部構造はかなり単純で、以下のような Few Shot Prompt を LLM に投げているだけです。
Your job is to output a more reasonable RBS type definition based on the given Ruby code and RBS type definition.
For all input RBS type definitions, output an improved RBS type definition.
Replace untyped with concrete types whenever possible and add any missing method definitions, attr_accessor, etc.
Correct any mistakes in existing types.========Input========
lib/email.rbclass Email attr_reader :address # ...(略) endsig/email.rbsclass Email attr_reader address: untyped # ...(略) end...(略)
========Output========
sig/email.rbsclass Email attr_reader address: String # ...(略) end...(略)
========Input========
lib/config.rbclass Config %w[client role prompt].each { attr_accessor _1.to_sym } # ...(略) endsig/config.rbsclass Config #...(略) end...(略)
========Output========
先頭にあるのが「Ruby コードと RBS コードから、 RBS コードの untyped を具体的な型に直したり、不足メソッドを補ったりしろ」という命令です。
続けて ========Input======== と ========Output======== で区切って、先に Email などの関係ない例でどういう動作を期待しているのかの例を提示します。この部分が Few Shot と呼ばれる部分です。[2]
この後に再度 ========Input======== で区切ってから本来推測して欲しい Config などの Ruby ソースコードと rbs prototype rb で作った RBS コードを渡し、 ========Output======== の区切り記号までを入れています。
LLM は続く文章を推測しようとしますが、このとき既に文章にある Input と Output の対応に似せた出力を作るため、以下のように改善した RBS コードをマークダウン書式で出力してくれるわけです。
sig/config.rbsclass Config attr_accessor client: Langchain::LLM::OpenAI attr_accessor role: String attr_accessor prompt: String ...(略) end
なお %w[client role prompt].each で動的に attr_accessor を呼び出している箇所については、どう推測するかを LLM の持っている知識に任せており、推測ロジックは一切書いていません。
このあたりに LLM の賢さが表れていますね。
RBS Goose の性能評価
この手法ではベースとなる RBS の生成手法と、推論に利用する LLM のモデルとで、多くの組み合わせが存在します。
それぞれについて、プロンプトを固定しどのような結果が返ってくるかを試したのが実験結果 1 の表(スライド) です。

Perfect が手直しの必要ない RBS を出力したもの、 Almost がごく一部で修正必要な RBS を出力したもの、空欄はかなり微妙な出力だったものです。また横のカッコは実行に要した秒数です。
スライドでは各セルが実験結果 PR へのリンクになっているため、詳細を知りたい場合はリンクから飛んでみてください。[3]
縦で見ていくとベースとなる RBS 生成手法ではあまり差が見られない一方で、横で見ると OpenAI の各モデルで Perfect が多く、 Anthropic の各モデルでは Almost が多くなっています。これは Anthropic のモデルが本来推定するべきでない untyped を無理やり推定し、存在しないクラスを捏造していたことが大きいです。
また実行時間・推測精度ともに GPT-4 Omni が圧倒的な成績を示しており、基本はこのモデルを使うのがいいだろう、ということがわかりました。[4]
これだけ見るとすごく良い結果なのですが、もう少しコード規模を大きくして RBS Goose 自身の型を推測させると実験結果 2 の表(スライド) の通り、 Perfect がなくなって最高でも Almost になります。
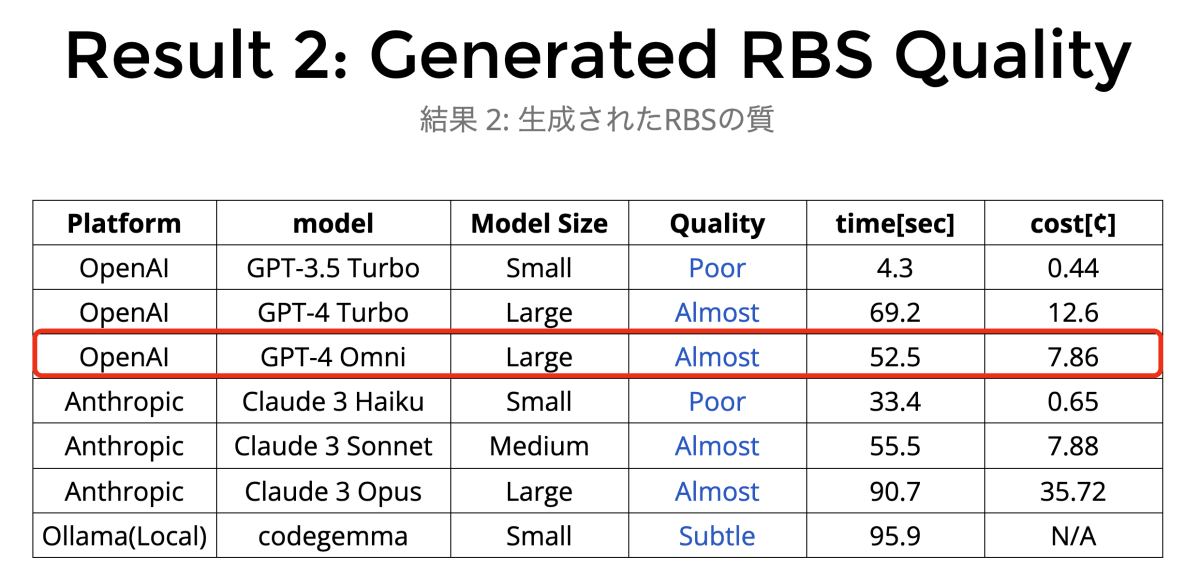
一定規模以上のプロジェクトでは、それっぽい結果は出るものの steep check を通るレベルではなく、結局手作業での修正が必要になります。
なまじ半端にそれっぽい型が出ているせいで型エラー原因の特定が難しく、正直なところまだ実用レベルとは言い難いという感触です。
型エラーを利用して RBS を更に LLM に修正させるなどアイディアはあるため、実用レベルを目指して今後も開発を続ける予定です。
発表の補足
懇親会で質問されたことや、ツイート・感想ブログなどで見かけた部分を補足しておきます。
一括生成の必要性について
Q. TypeScript みたいにエディタ上で都度補完されれば、一括生成の必要はないはず?
A.
理想の世界としてはそうなんですが、 Ruby の型は後で入った Gradual なものである関係上、目の前にある数十万行のプロジェクトコードに一切型がついてない、ということが往々にしてあります。
また型を書くのはオプションのため、提供される Gem ライブラリでも型の書かれていないものがほとんどです。
このため、いまあるコードに型をつける作業のために一括生成の仕組みを作り、プロジェクト全体に型がついた暁には型の恩恵を受けてエディタ補完のみでいい感じの型付きコードを書ける、という世界を目指したいというのが開発の動機になっています。
プロンプトチューニングについて
Q. プロンプトチューニングはしてない?
A.
そもそも実現可能か調べるために素朴なプロンプトを書いたら思ったよりちゃんと動いたので、プロンプトチューニングするところまではやってません。
個人的な印象では、プロンプトの細かいチューニングよりも先に「RBS の詳細な文法規則」や「外部ライブラリの型はなにか」といったドキュメントをきちんと埋め込んで知識を参照できるようにするほうが先かなと考えています。
とはいえ Few Shot の区切り記号などは適当すぎる気がするので Claude の Prompt Generator あたりを使ってそれっぽいプロンプトに整えるくらいはやりたいです。
RubyKaigi 会場でもらったアイディア
会場や懇親会などで色々話して、今後やりたいなと思っているアイディアです。
gem_rbs_collection で利用できるレベルを目指す
最初は Rails アプリケーションに型をつけるところを目標にしてたんですが、やはりいろいろ難しそうなのでもう少し難易度の低いところから攻めようかなと考えています。
https://github.com/ruby/gem_rbs_collection で記述するような Gem の型は動的要素が少ないものも多く、まずはこの PR の雛形として利用できるレベルを目指したいです。
また RBS Goose とは別軸ですが、 gem_rbs_collection ではレビューの手が足りてないと伺ったので、初歩的なレビューフィードバックを LLM で行えないかもちょっと試してみたいと考えています。
RBS コードではなく RBS::AST を直接扱う
人間から扱いやすいので素朴に RBS コードを入出力していたのですが、「許される記述や結合則を LLM に教えづらい」「orthoses gemと統合できず、一度 Output しないといけない」などの問題がありました。
LLM が生成する分には記述しやすさよりも明快性のほうが重要なため、例えば RBS::AST::Declarations などを JSON 表現に変換して受け渡すことで、文法の曖昧性を気にしなくて良くなるのではないかというのを期待しています。この方式にすれば orthoses gem からも load_env したものが利用でき、わざわざファイルシステムを介する必要がなくなるはずです。
まとめ
RubyKaigi 2024 での発表内容をざっとまとめました。
個人的に LLM は「Ruby で型を手書きせずに、型の恩恵を受けられる世界」を実現できる可能性が結構あるかなーと思っているので、今後も取り組みを続けていくつもりです。
次は Ruby アソシエーションの開発助成金に公募を出すのと、来年の RubyKaigi で英語登壇するのを目標に頑張ります!
なお、まだ実用レベルではないですが一応 OSS プロダクトを立ち上げてるということで、 GitHub Sponsors に登録してみました。もし RBS Goose の未来に期待して支援してくれる方がいたら LLM 利用料が賄えて助かります。
おまけ: CfP で提出した内容
自分の提出した CfP の内容を記載しておきます。来年 CfP を出す誰かの参考になれば幸いです。
ちなみに読んで貰うとわかりますが、 CfP では「LLM の使い方紹介」を重視していて、 RBS Goose については実装事例として軽く触れるくらいの立ち位置でした。
この構成でスライド作って社内リハを行った結果、「LLM 入門の話よりも RBS Goose の話をもっと聞かせてほしい」とフィードバックをもらい、スライドを 8 割くらい変えた経緯があります。
直前に構成を大幅変更したことで結果的にタイトル詐欺っぽくなってしまったため、次回の CfP では最初から RBS Goose にフォーカスして出すことにします。
ヘッダー情報
- タイトル: Let's use LLMs from Ruby 〜 Refine RBS types using LLM 〜
- Speaker: kokuyou
- Format: Regular Session
- Track: General
- Spoken language in your talk: Japanese
Abstract
Large Language Models (LLMs) have evolved rapidly over the past few years and there have already been many practical applications in a variety of fields.
Though Python is recognized as a de facto standard language to use LLMs, we are Rubyists so we would like to explore how we use LLMs in the Ruby language.
In this session, I will explain the basics of Large Language Models(LLMs), and then cover Langchain.rb as a tool to use LLMs from the Ruby language.
The development of RBS Goose, which is a tool to refine RBS type signatures, is a good practical example. We’ll share how it works including prompt construction, as well as the tips for LLMs development and our evaluation of its performance, including accuracy and speed, at the combination of various prompts, Few-Shot examples, and LLMs.
For Review Committee: Details
本セッションではLLMsについて概説したうえで、RubyからLLMsを扱うための手法を紹介し、具体的な開発事例としてRBSの型推測を行うRBS Gooseを取り上げます。
想定聴講者はLLMsに興味はあるがRubyからの実用はしていない参加者、及びRBSの非形式的な型推測に興味のある参加者です。ただしLLMs・RBSいずれも前提知識がほぼ不要な発表構成とし、初学者にも理解しやすいレベル感にする予定です。
発表構成の想定は以下のとおりです。
まず、LLMsの大まかな仕組みとして「大量の文章データをもとに、単語同士の結びつき確率をモデル化したもの」であり、よく使われる事例は「文脈を元に、確率の高い次の単語を予測する」ことで要約・翻訳・会話などのタスクを行っていること、追加のデータを学習するファインチューニングによってタスクごとの精度を高めておりChatGPTはGPTを会話データでファインチューニングしたものであること、などを解説します。
これに関連し、LLMsの他の応用例としてテキストをベクトルへと変換し、文章間の類似度測定や検索がベクトル計算で行えるようになるEmbeddingをあわせて紹介し、昨今はLLMsの記憶レイヤーとしてベクトルデータベースが多用されることも合わせて紹介します。
次に、RubyからLLMsを扱うためのツールとして Langchain.rb( https://github.com/andreibondarev/langchainrb ) を紹介し、Prompt Templates や Few Shot Prompt Templates の概念を紹介しつつ使い方をコードで示します。
また知識ベースとして Chroma( https://trychroma.com/ ) や Pinecone( https://www.pinecone.io/ )などベクトルデータベースを使う方法、他のツール類と連携するエージェントシステムの概念についても簡単に触れます。
(これらは昨今のLLMsにおいて重要な立ち位置を占めるため触れておきたいですが、発表の主題からは逸れるため、非常に簡易的な紹介に留めるか省略する可能性もあります)
その後、具体的な応用事例としてRBSの型推測ツールであるRBS Goose( https://github.com/kokuyouwind/rbs_goose )の開発事例を紹介します。
具体的なプロンプトやコードで動作原理を示したうえで、orthoses( https://github.com/ksss/orthoses)のミドルウェアとすることで rbs prototype や orthoses-rails( https://github.com/ksss/orthoses-rails )などで自動生成されたコードをさらに RBS Goose で詳細化する運用を紹介します。
またツールのテストを記述する際、LLMsへのリクエストを抑制しテスト時間を高速化するため vcr( https://github.com/vcr/vcr )を活用しているTipsを紹介します。
性能評価として、すでにRBSで型付けされたプロジェクトを対象に、rbs prototype + RBS Gooseで出力されたRBSが理想的なものとどれだけ異なるかを比較することで、現状の精度と課題を論じます。またLLMsをOpenAI APIからGoogle Gemini ProやローカルLLMsなどに差し替えた場合やファインチューニングを行ったモデルに差し替えた場合、命令プロンプトやFew-Shotのexamplesを差し替えた場合などのケースでも同様の測定を行い、精度の比較を行う予定です。
(RBS Gooseは現在開発している段階のため、本節の内容は大幅に変更・省略される可能性があります)
現時点での成果として、 RBS Goose 自体の型を RBS Goose によってある程度の精度で推測できています。
RBS Goose による出力は https://github.com/kokuyouwind/rbs_goose/commit/6a46bb5bdc969d048b1d55b74578f7218be8e1eb から参照できます。
また Steep Check に通るようにしたdiffが https://github.com/kokuyouwind/rbs_goose/commit/4a2afbbf44be228b7e3e938480fb8eb71d68bac6 です。これには本来望ましい出力とのdiffのほか、外部gemの型定義不足やコード自体の不備に関する修正も含まれています。
上記は gpt-3.5-turbo によるものですが、 gpt-4 との精度の差異を検証した diff が https://github.com/kokuyouwind/rbs_goose/pull/2 になっています。
このように同じ設定でも言語モデルによって出力が異なるため、各種の言語モデルを用いて結果を比較していく予定です。
For Review Committee: Pitch
LLMsは昨今の話題性と比べると、Rubyから扱うためのライブラリや応用事例が少ない状況です。
(参考値として、Pythonの本家LangChainのGitHubリポジトリが73.4k Star、JavaScript版のLangChain.jsが9.6k Starに対し、Langchain.rbは797 Starに留まっています)
今後もLLMsの急速な発展が予想されていることからも、コミュニティの中でRubyからLLMsを扱うためのノウハウを共有し、関連プロジェクトを紹介することは大きな意義を持つと考えています。
筆者は昨年のRubyKaigi 2023においてLT枠で RBS meets LLMs - Type inference using LLM の発表を行っており、本セッションはこのLTのFuture Workを含んでいます。
昨年から継続してLLMsの動向を追っているためLLMs関連技術の概説やツールチェインの利用例を示すことができ、またRBSというRubyKaigiで扱われることの多い題材と絡めることで参加者の興味を引きやすいという点で、本テーマの発表に適していると考えています。

Discussion