Leaner 開発チームの黒曜(@kokuyouwind)です。
この記事は Datadog Advent Calendar 2022 の 22 日目です。いよいよクリスマスが近づいてきましたね。
今回は Datadog APM のトレース機能を利用したパフォーマンスチューニングを実施したため、その内容をまとめます。
パフォーマンスチューニングの背景
今回パフォーマンスチューニングの対象にしたのは、外部サービスの商品を横断的に検索する「商品検索 API」です。この API では外部サービスごとに API を呼び出しており、取得したデータの加工や集約などを行っています。
機能を使ってみて確かに重いことはわかっているのですが、どの処理に時間がかかっているのかは判別できていませんでした。このため自分を含むメンバー全員が「外部サービス API 呼び出しが大半を占めており改善はできないだろう」と推測していました。
ところが Datadog APM を使ってデータを確認してみたところ、どうも外部サービスの API 呼び出し以上に時間がかかっている処理がありそうだぞ…? ということがわかり改善に繋げられた、という流れです。
以降、「Datadog APM トレースの設定と計測」「計測結果を元にしたパフォーマンスチューニング」「トレース設定の共通化」を順にまとめていきます。
Datadog APM トレースの設定と計測
Leaner ではサービスのモニタリングに Datadog APM を利用しています。
Rails アプリケーションでは ddtrace gem を導入することで、本番リクエストのトレースを簡単に可視化でき便利です。
以下の図は ddtrace gem 導入直後に取得した、商品検索 API のトレース情報です。
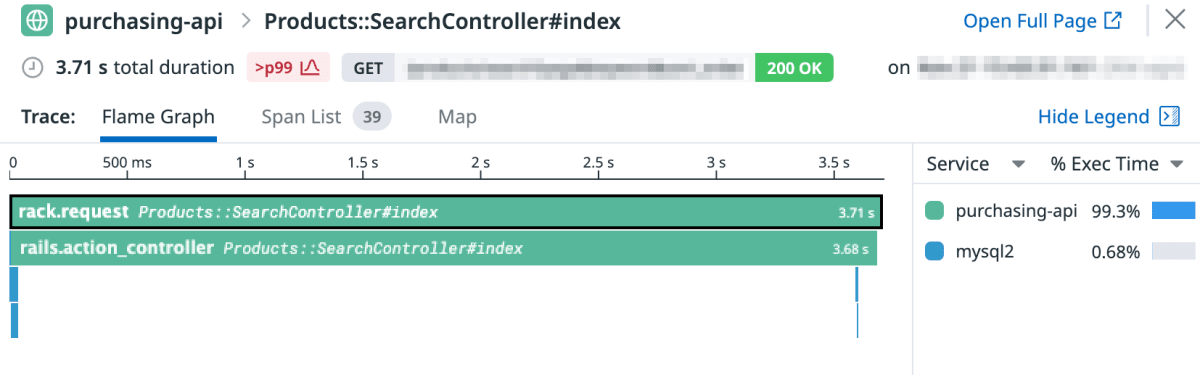
初期設定だけでも MySQL へのクエリがタイムラインに表示されていますね。
手動でのトレース対象追加
上述のトレースを見ると MySQL へのクエリ時間はごくわずかであるとわかりますが、他に何の処理にどのくらいの時間がかかっているのかはわかりません。これを切り分けるためには、 Rails アプリケーションのどの部分をトレースで区切って表示するか、利用者側で指定する必要があります。
なお、このときの「トレース上で表示する 1 つの区間」を Datadog では スパンと呼んでいます。
手動で Ruby コード内のスパンを指定するには、 手動インスツルメンテーション の手順に従って Datadog::Tracing.trace を利用します。
Datadog::Tracing.trace(name, **options) do |span, trace|
# このブロックを、インスツルメントするコードでラップします
# さらに、ここでスパンを変更できます。
# 例: リソース名の変更、タグの設定など...
end
今回は外部 API リクエストを呼び出す XXXGateway#search メソッドの呼び出し時間を確認したかったため、このメソッドの処理全体を Datadog::Tracing.trace で囲いました。
class XXXGateway
def search
Datadog::Tracing.trace('rails.gateway', service: service_name, resource: "xxx_gateway#search") do
# ここに元々の処理内容を記述
end
end
end
この変更を入れた状態でリクエストを確認すると、以下のように Gateway クラスへの呼び出しがスパンとして表示されました。
あわせて、その内部からの ethon.request 呼び出しも表示されるようになっています。
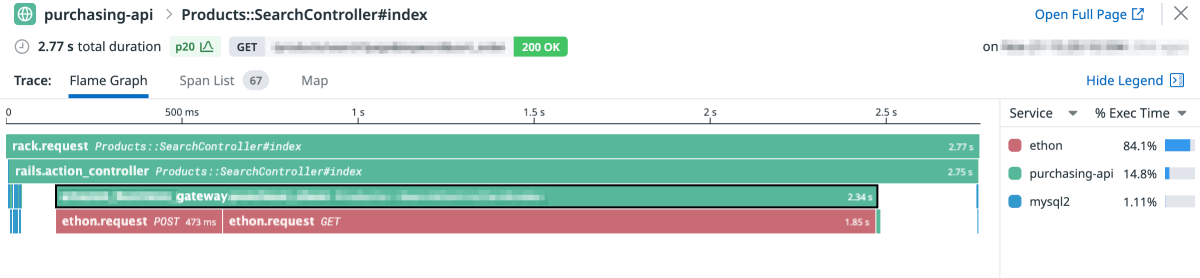
これによって、外部 API へのリクエストにかかっている時間がリクエスト全体の 84% ほどであることがわかりました。
逆に残る 16% の 400ms ほどはそれ以外の処理ということになります。割合としては低いものの、 I/O 以外の処理でかかる時間としては無視できない値になっていますね。
後ほど、より詳細なトレースを仕込んだ上でこの区間のチューニングを行っていきます。
マルチプロセス処理への対応
さきほどの例では外部 API リクエスト先がひとつだけでしたが、商品検索 API では設定に応じて複数の外部 API リクエストを同時に投げられるようになっています。
その際のトレースは以下のようになっていました。
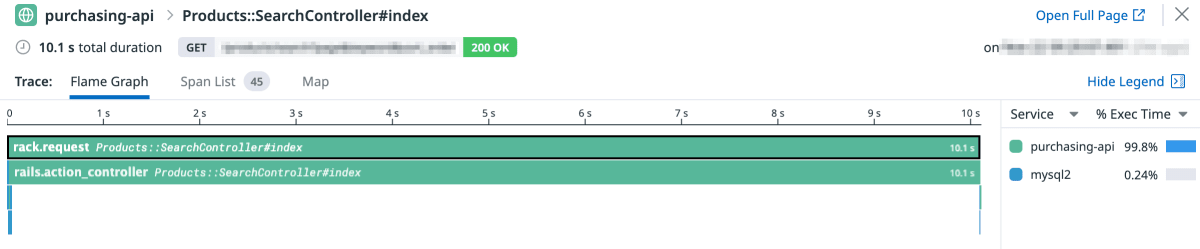
レスポンスに 10 秒もかかっており改善したいところですが、見ての通り外部 API へのリクエストはおろか、手動で設定したはずの XXXGateway#search 呼び出しのスパンも表示されていません。
これについて原因を調べたところ、 parallel gem を利用してマルチプロセスで処理しているためと考えられました。
def search_parallel(keyword)
Parallel.map(gateways, in_processes: gateways.count) do |gateway|
gateway.search(keyword)
end
end
外部 API リクエストを並列して処理できるよう、コントローラーでは上記のように各 Gateway の search メソッドを呼び出していました。この際、 Datadog の実行コンテキスト情報がプロセス間でうまく共有されておらず、子プロセスでのスパンを親プロセスのスパンと紐付けられていないのではないかと推測しました。
そこで、本来の用途とは異なりますが Distributed tracing の機能を使い、ローカル変数経由で親スパンの実行コンテキストを引き渡すように書き換えました。
def search_parallel(keyword)
# Parallelでプロセスが変わるため、Datadog traceが親スパンを正しく追跡できるようにする
Datadog::Tracing.trace('products.search_controller',
service: service_name,
resource: 'search_parallel') do |_span, trace|
Parallel.map(gateways, in_processes: gateways.count) do |gateway|
Datadog::Tracing.trace('products.search_controller',
service: service_name,
resource: "search_#{gateway.name}",
continue_from: trace.to_digest) do
gateway.search(keyword)
end
end
end
end
かなりネストが深くなってしまい読みづらいですが、ひとつめのトレースでメソッド全体をスパンとした上で実行コンテキストを trace 変数に取り出しておき、 Parallel.map 内部の子プロセスでは trace.to_digest によって親スパンの情報を continue_from に渡しています。
この変更により、以下のように正しくトレースが取得できるようになりました。
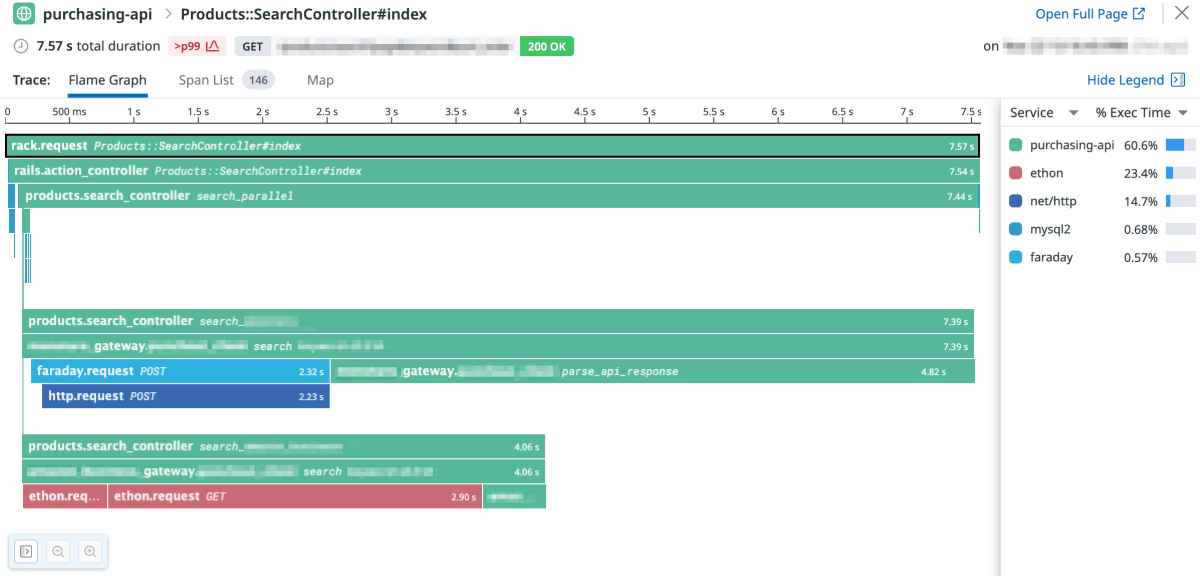
複数の Gateway からそれぞれの外部 API を利用していることが可視化できましたね。ライブラリの関係で ethon.request を使っているものと faraday.request を使っているものとが混在していますが、どちらもきれいに表示されています。
またリクエスト以外の処理時間を確認したかったため、レスポンスを加工する parse_api_response もスパンとして表示しています。
これを見ると、外部 API リクエスト以上に中段の parse_api_response が多くの時間を占めていることがわかります。
計測結果を元にしたパフォーマンスチューニング
ここまででトレースを利用して処理内容の可視化が進んだため、重い処理を改善していきます。
なお外部 API の呼び出しについては如何ともしがたいため、それ以外の処理について見ていきます。
parse_api_response の処理時間
parse_api_response に 5 秒もかかるのは明らかにおかしいため、まずはこの処理内容を確認します。しかしながら、ここでは XML レスポンスをライブラリに渡して Ruby オブジェクトに変換しているのみで、ごく普通の処理でした。
ローカルで同じレスポンスを利用して処理を試したところ、同じ程度の時間がかかり事象を再現できました。そこで stackprof を利用して詳細なプロファイルを取得してみた結果、 DidYouMean::Jaro.distance でほとんどの時間を消費していることがわかりました。
以下が該当処理のプロファイルをグラフ化したものです。
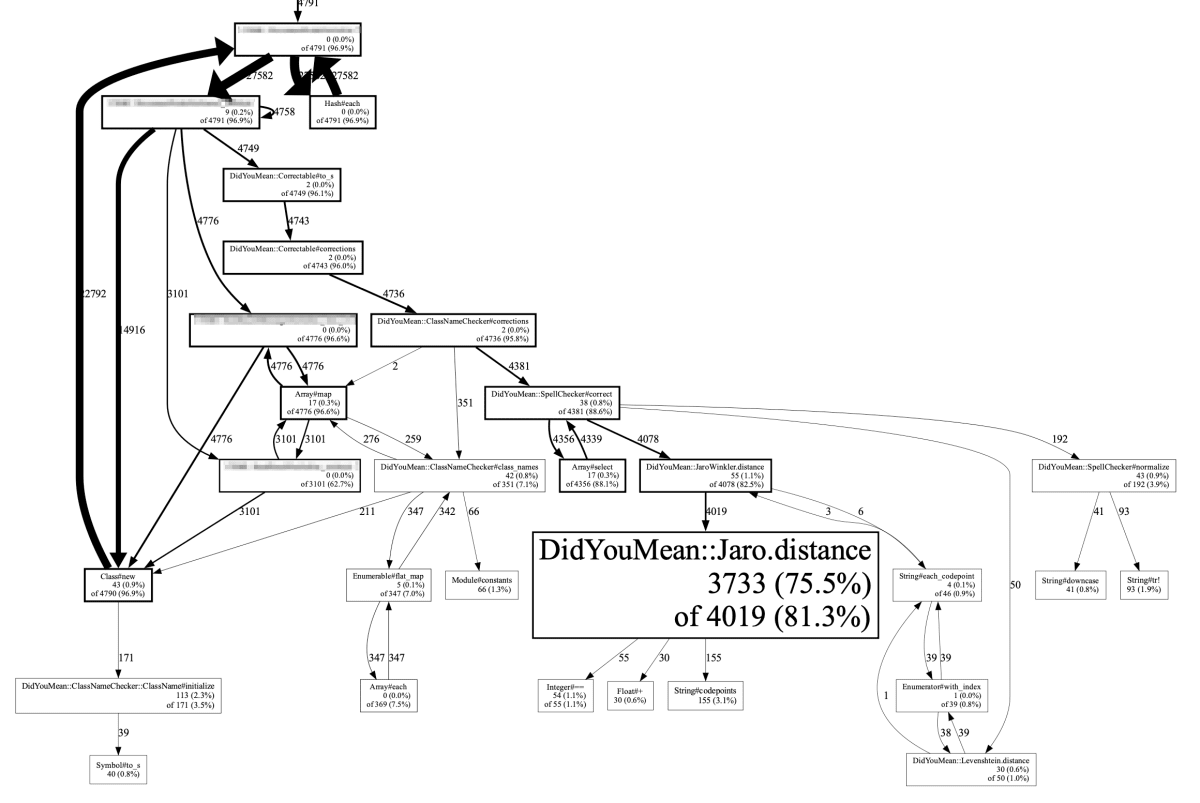
DidYouMean は未定義変数や未定義定数の参照が発生したときに修正候補を表示するライブラリで、本番環境では通常呼び出されないはずです。
なぜこのような呼び出しが発生したのかライブラリの実装を確認したところ、 XML に含まれる要素名を constantize することで要素ごとのクラスを取得しており、ここで NameError が発生したときには汎用のクラスにフォールバックしていました。つまり、要素に対応するクラスをライブラリが用意していないような XML ドキュメントを渡した場合、フォールバックのために大量の NameError が発生して DidYouMean 呼び出しも大量に行われることになります。
これを防ぐため、要素名の constantize を呼び出す前に const_defined? で定数の存在確認を行うようにしました。[1]
この変更を反映したうえで、同内容のリクエストから取得したトレースが以下です。
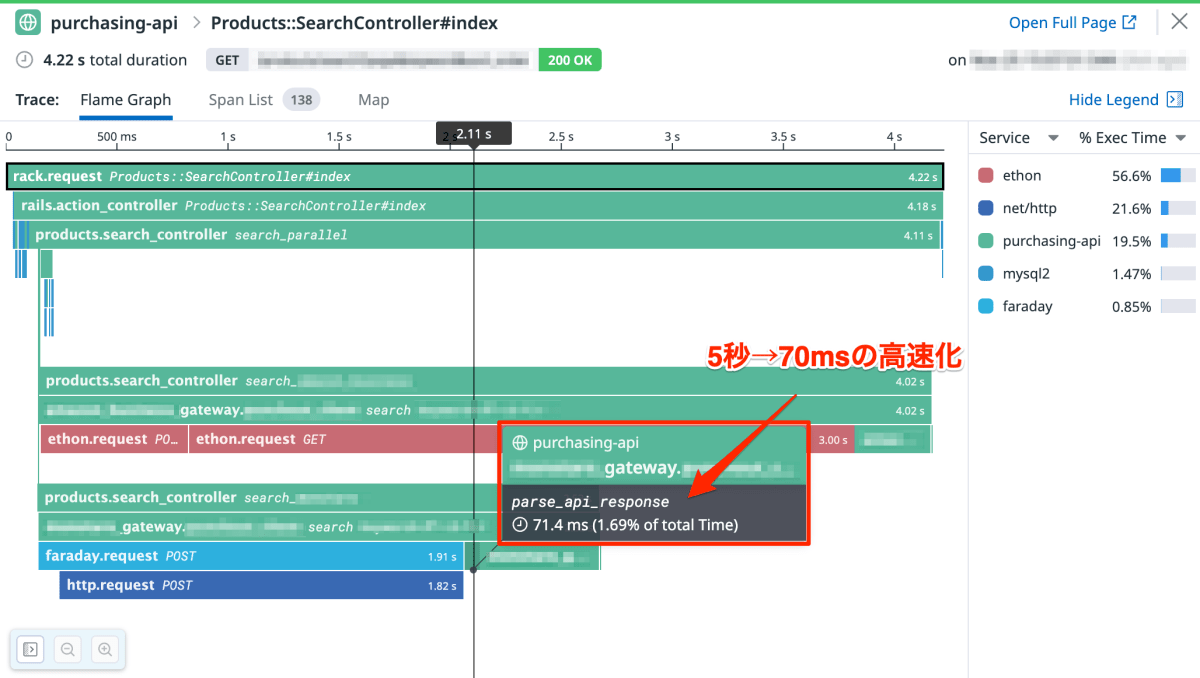
幅が短くなりすぎてタイムライン上で分かりづらいですが、もともと 5 秒ほどかかっていた parse_api_response の呼び出しを 70ms 程度と大幅に高速化できました。
リクエスト全体でも 10 秒前後から 5 秒前後と大幅に改善しています。
並列処理のオーバーヘッド
この時点でレスポンス速度はかなり改善したのですが、トレースを見ていくとたまに 500ms ほどの謎の時間が空いているケースがあることに気づきました。
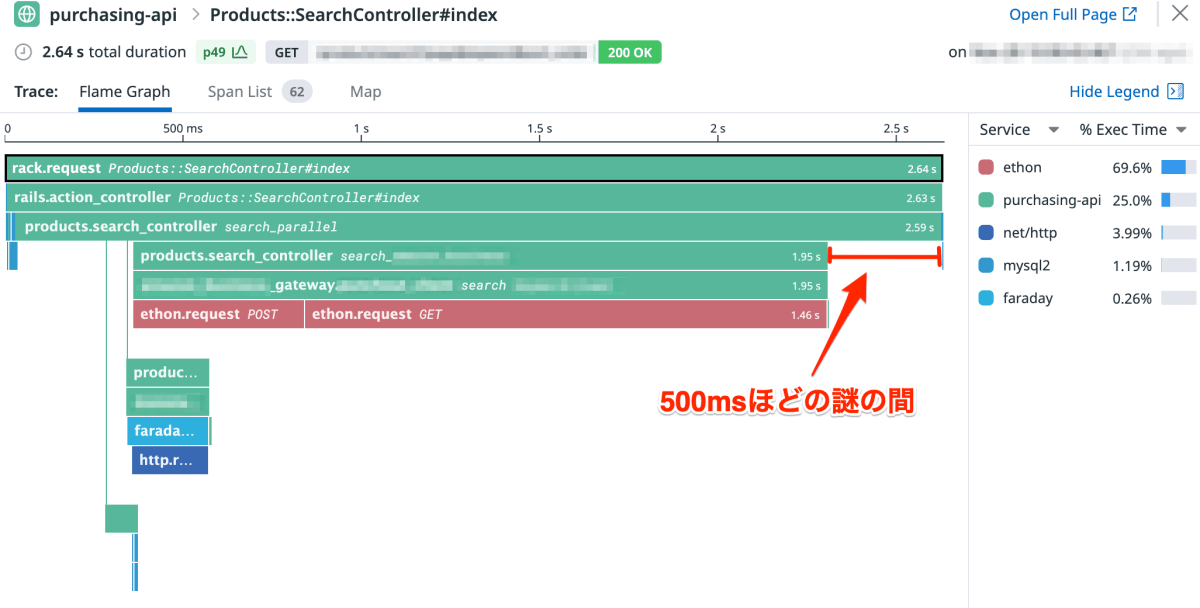
Ruby コード上では search_parallel 内のすべての処理、何も呼び出していない期間が存在するのは不思議です。
そこで Parallel で起動したマルチプロセスの終了オーバーヘッドではないかと疑い、スレッドでの並列処理に切り替えてみました。
def search_parallel(keyword)
- Parallel.map(gateways, in_processes: gateways.count) do |gateway|
+ Parallel.map(gateways, in_threads: gateways.count) do |gateway|
gateway.search(keyword)
end
end
この変更後、謎の空白期間がなくなったことを確認できました。
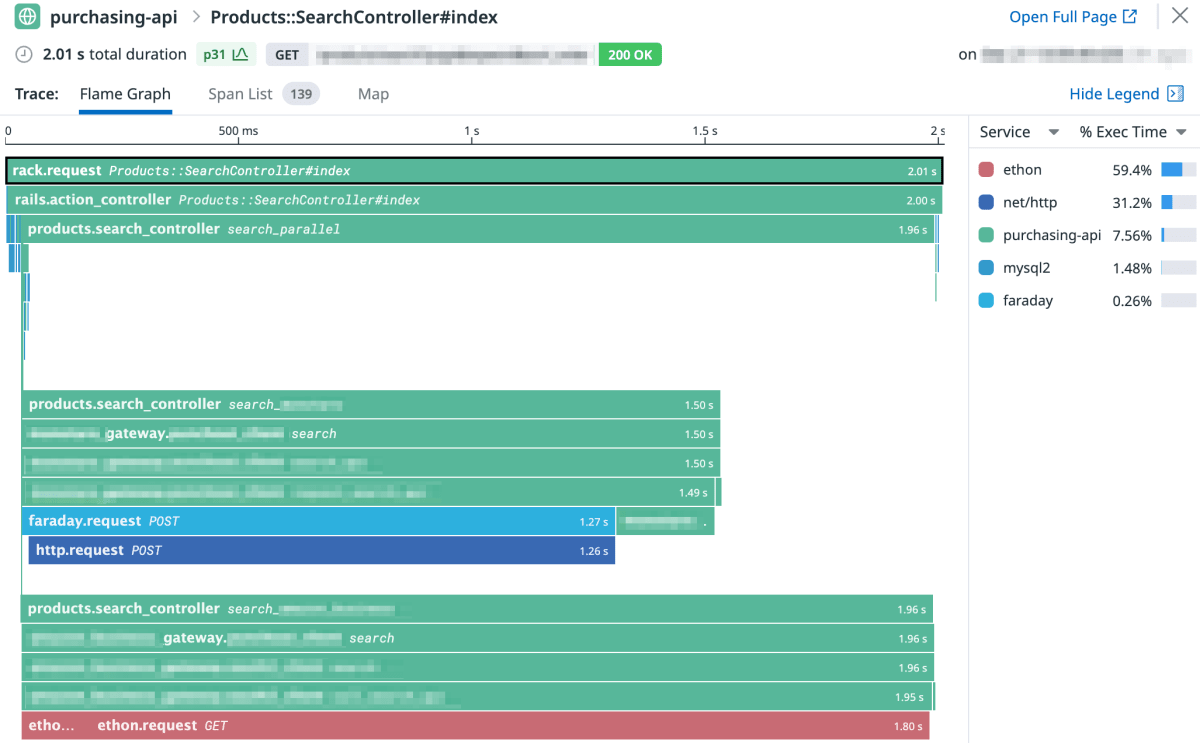
他の改善も交えたのでトレースのネストが深くなっていますが、 Gateway#search の完了から間をおかずに search_parallel も完了していることが確認できます。
全体で見ても、もっとも時間のかかっている外部 API 呼び出しが 1.80 秒なのに対し、商品検索 API 自体のレスポンスが 2.01 秒となっており、 API 呼び出し以外の処理は 200ms ほどで完了していることになります。当初から比べると圧倒的な改善といえるでしょう。
もとは CPU Heavy な処理を各 Gateway で行う想定だったためマルチプロセスでの並列処理にしていましたが、計測によってさほどの CPU 処理を行っていない割にマルチプロセスでのオーバーヘッドが大きいとわかり、改善に繋げられてよかったです。
トレース設定の共通化
ここまでで計測とパフォーマンスチューニングは十分ですが、今後も重い処理が見つかったときに改善しやすいよう、要所にトレースを設定しておきたいところです。
しかしこれまでのコード例で示したとおり、 Datadog::Tracing.trace は引数が多いうえブロック渡しのためにネストが深くなるため、あまり多く仕込むと可読性を損なう可能性が高いです。
そこで「引数指定を共通化した trace_span」と「指定したメソッド全体をトレース対象とする trace_methods」を DatadogTraceable モジュールに切り出し、扱いやすくしました。
以下がそのモジュールのコードです。
# Datadog::Tracingをラップし、メソッドのトレースを記述しやすくするためのモジュール
module DatadogTraceable
def self.included(klass)
klass.extend(ClassMethods)
end
module ClassMethods
# 指定したメソッド群をトレース対象にする.
# 引数を複数指定すると、すべてのメソッドがそれぞれトレース対象になる.
#
# fg.
# class Test
# include DatadogTraceable
# trace_methods :method_a, :method_b
# end
def trace_methods(*method_names)
# 計測対象をラップする必要があるため、計測対象メソッドと同名で計測用メソッドを定義したモジュールを生成する
wrapper = Module.new do
method_names.each do |method_name|
define_method method_name do |*args, **options|
trace_span(method_name.to_s) { super(*args, **options) }
end
end
end
# 計測対象メソッドより先に計測用メソッドが呼び出されないといけないため、
# prependして継承チェインの先頭側に追加する
prepend(wrapper)
end
end
# 指定したブロックをトレース対象にする. Datadog::Tracing#trace のラッパーメソッド.
# リソース名指定のみ必須で、それ以外に指定したオプションは Datadog::Tracing#trace にそのまま渡される.
#
# fg.
# class Test
# include DatadogTraceable
#
# def test_method
# trace_span('mySpan') { some_heavy_process }
# end
# end
def trace_span(resource_name, **options, &block)
Datadog::Tracing.trace(trace_name, **options.merge(service: service_name, resource: resource_name), &block)
end
private
def trace_name
# include 先のクラス名を利用して `product.search_controller` のような文字列を作る
self.class.name.underscore.tr('/', '.')
end
def service_name
# TODO: Datadogのサービス名を記述
end
end
使用法はコメントに書いている通りです。
例として、前述の SearchController#search_parallel 及び XXXGateway#search はそれぞれ以下のように書き換えました。
class SearchController < ApplicationController
include DatadogTraceable
def search_parallel(gateways)
# Parallelでスレッドが変わるため、Datadog traceが親スパンを正しく追跡できるようにする
# (マルチプロセスと違い明示的なdigest引き渡しは必要ない可能性があるが、trace_spanの使用例として記載)
trace_span('search_parallel') do |_span, trace|
Parallel.map(gateways, in_threads: gateways.count) do |client|
trace_span("search_#{gateway.name}", continue_from: trace.to_digest) do
gateway.search(keyword, page: page, lower_price: lower_price, upper_price: upper_price)
end
end
end
end
end
class XXXGateway
include DatadogTraceable
trace_methods :search, :call_search_api, :parse_search_response, :format_summary
def search
response = call_search_api
parsed = parse_search_response(response)
parsed.map(format_summary(_1))
end
# call_search_api, parse_search_response, format_summary をそれぞれ定義
end
特に XXXGateway#search については内部の処理ごとにメソッド分割し、それらをまとめて trace_methods でトレース対象にすることで、ボイラープレートコードを書くことなくきれいなトレースを生成できます。
このように DatadogTraceable 自体は小さなモジュールですが、かなり便利に使えています。現状はプロジェクト内にそのまま置いていますが、そのうち RubyGem として公開することも検討したいです。
まとめ
Datadog APM のトレース機能を利用することで、実リクエストから重い処理を特定し改善に繋げられました。
こうしたトレースは手元での取得もできますが、本番環境のほうがより信頼度の高いデータを多く蓄積できるため、うまく使い分けていきたいところです。
-
今回はライブラリ側で本来想定しない値を渡していたため、 Pull Request は出さずモンキーパッチで対応しました。 ↩︎

Discussion
こんにちは、Datadog Technical AdvocateのTaijiです。
Datadog アドベントカレンダーへのご参加ありがとうございました!
ささやかではございますが御礼をご用意しております。よろしければこちらからSwag申請を行ってください。
引き続きよろしくお願い申し上げます!