会社で Zenn Publication を導入したので、個人アカウントからちょっとした Tips 記事を書いてみます。
TL;DR
- JavaScript の String.prototype.substring は UTF-16 コードユニットを数えるので、英数字と日本語文字が混じっていても問題なく「人間から見た文字数」で動作する
- 絵文字などコードユニットを複数使う文字では、切り取り指定通りの文字数にならないことがある
- Unicode プロパティを指定した正規表現を使うと絵文字対応版の substring が簡単に実装できる
マルチバイト文字列の substring を取得したい
ちょっとした事情で、マルチバイト文字列の部分文字列を取り出す必要が生じました。例えば「あいうえお」の 2 文字目から 3 文字目を取り出して「いう」という文字列を作りたい、といったユースケースです。
この際、全角文字などのマルチバイト文字をどうカウントするかという問題があります。
たとえば abcde と あいうえお は人間からすると 5 文字ですが、前者が 1 文字 1 バイトなのに対して後者はエンコーディングによって異なるものの 1 文字 2~3 バイトになります。 [1] またバイト数とは別に、英数字を 0.5 文字として「全角文字数」でカウントするケースもありえます。
どの数え方にしたいかは状況に異なりますが、今回は全角・半角などを区別せず「人間にとっての 1 文字」をそのまま 1 文字として数えたい状況でした。
公式ドキュメントを見てみる
JavaScript が substring でマルチバイト文字をどう扱うかよくわからないので、まずは公式ドキュメントを見てみます。
マルチバイト文字の話が一切ないですね…。
ググってみる
公式ドキュメントでわからなかったので、 javascript マルチバイト文字 substring でググってみます。
マルチバイト対応バージョンの実装例などが出てきました。とはいえ「バイト数で数えたいケース」や「半角文字を 0.5 文字で数えたいケース」が入り混じっており、標準仕様が結局どれなのかはよくわかりません。
試してみる
結局試してみるほうが速そうなので、マルチバイト文字が混じった文字列で substring がどう動くか試してみます。
> "aiueoあいうえお".substring(5, 8)
'あいう'
JavaScript の substring は「始端インデックス」と「終端インデックス」を受け取り、「始端インデックスの文字」から「終端インデックスの直前の文字」までの部分文字列を返します。インデックスは配列と同じく 0 始まりです。
上記の例であれば「インデックス 5(= 6 文字目)からインデックス 8(= 9 文字目)の直前(= 8 文字目)」を切り出します。ちょっとややこしいですね。
文字列の中身は aiueoあいうえお なので、 6 文字目から 8 文字目は あいう です。
…マルチバイト文字の扱いを懸念しましたが、問題なく「人間から見た文字数」で動いているようですね。
length の公式ドキュメントを見てみる
substring のドキュメントにはマルチバイト文字の扱いについて何も記載がありませんでしたが、実は String length プロパティの公式ドキュメント を見るとマルチバイト文字の扱いについて言及があります。
このプロパティは、文字列内のコード単位の数を返します。 JavaScript で使用される文字列書式である UTF-16 は、ほとんどの一般の文字は単一の 16 ビットコードユニットで表しますが、あまり使われない文字に対しては 2 つのコードユニットを使用する必要があり、 length で返される値が文字列の実際の文字数と一致しなくなる可能性があります。
どうやら JavaScript では文字数として UTF-16 のコードユニットで数えるようです。 UTF-16 では英数字と日本語文字のいずれも 1 コードユニットで表せるため、どちらも同じ 1 文字としてカウントされるということですね。
絵文字の扱い
組み込み関数ではうまく扱えない
さきほどの記事にあった「あまり使われない文字に対しては 2 つのコードユニットを使用する必要があり」というケースの典型例には絵文字が挙げられます。
実際に試してみると、絵文字を 3 つ使った文字列の length は 6 となってしまいます。[2]
> "🤔💎🚀".length
6
同じように絵文字を含む文字列の substring を試してみると、切り出し位置の指定がずれてしまい、中途半端な位置から切り出すと表示できない文字が生まれてしまいます。
> "🤔👏🚀🐳🤖".substring(1, 5)
'�👏�'
絵文字対応の substring
正規表現の unicode プロパティを利用すると、実際のコードユニット数に関わらずユニコードの表す 1 文字単位で正規表現をかけることができます。
これを使えば、ユニコード対応の substring は以下のように実装できます。
const unicodeSubstring = (str, start, end) => {
const reg = new RegExp(`^.{${start}}(.{0,${end - start}})`, 'u')
return str.match(reg)?.[1]
}
コンソールで適当に試してみます。
> unicodeSubstring("🤔👏🚀🐳🤖", 1, 5)
'👏🚀🐳🤖'
インデックス 1(= 2 文字目) からインデックス 5(= 6 文字目) の直前、つまり 2 文字目から最後までが正しく取得できました。
まとめ
substring の公式ドキュメントにマルチバイト文字の扱いについて記載がなく、適当にググった結果でも全角カウントなど求める内容と違う話が多かったため少し困りましたが、絵文字などを扱わない限り「JavaScript の扱う文字数」と「人間から見た文字数」は一致することがわかりました。
なんとなく「マルチバイト文字は JavaScript からうまく扱えない」という先入観があったのですが、誤解が解けてよかったです。

Discussion
たぶんわかりやすくするためにそう表現していると思うのですが、載っているスクリプトで数えられるのは、厳密には「人間から見た文字数」ではなくて「Unicodeの厳密な意味でのCodePoint(
\u0から\u10FFFFまで)の個数」になっているような気がしています。(↓Code Pointの定義です)

JSの
codePointAtやsubstringなどで使う場合は、String lengthのMDNのドキュメントにあるとおりUTF-16での値についてを考慮しているようで、サロゲートペアなどは考慮されず「UTF-16の1つのCodeUnit」と考えられているみたいです。なので、絵文字でない日本語でも、Unicodeの追加漢字面に載っているもの等はサロゲートペアを使って表現しており、lengthが2のものもあります。たとえば「𠮷」は追加漢字面に載っている漢字ですが、「𠮷」のlengthは2です。以下の画像とリンクは、TC39から引っ張ってきたStringの文字の数え方やもろもろの関数についての仕様と、unicode.orgから引っ張ってきたCode Unitの定義です。


ご承知のとおり、💇♀️や👋🏻などの、UTF-16では4バイトよりも多く使うEmojiは、Full Emoji Modifierなどを組み合わせたもので、「文字数」は厳密に評価できないかもしれません。これは私は「しらんがな」と割り切っています。
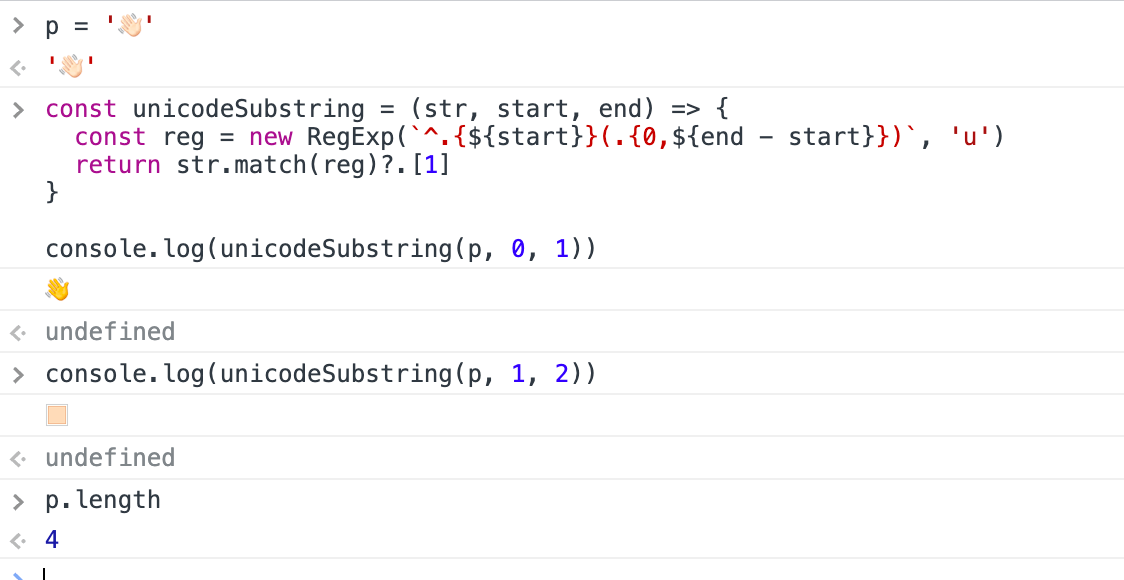
イングランドの国旗など、unicodeのコードポイントを複数並べて作られたものはとにかく長い印象です。個人的には「なんでそんなことするだぁ」というふうに感じます。→ 🏴
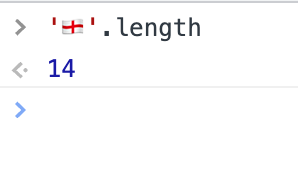
絵文字だけでなく、異体字セレクタもあるため、たとえば「辻」はJSでは1文字ですが、異体字セレクタを追加することで「辻󠄀」はJSでは3文字という扱いになります。こちらは普段は問題ないですが、人名などの操作を文字数と絡めて行うときにバグになりやすいと思っています。
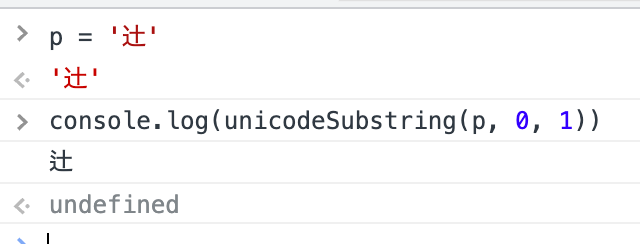
↑漢字が変わってしまう。
「ぱ」と「ぱ」は見た目は全く同じで、直感的には1文字ですが、前者はUTF-16では2文字で、後者は1文字扱いになります。前者は「『は』+
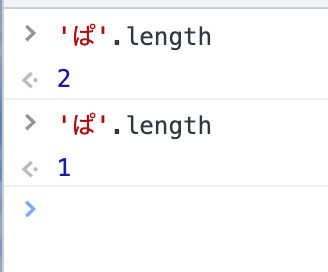

\u309A」になっています。極稀に一部のシステムと連携したときに発生しているのを見かけます。これは逆に直感的には全然1文字ではないですが、Unicodeの1つのCodePointで表している上、サロゲートペアなども不要なので1文字です。→ ﷽
とはいえすべてエッジケースで、人名以外はほとんどわざとやっている行為に近く、あまり厳密にやらなくてもいいとは思っています。
私としては、「マルチバイト文字」「2バイト文字」「ワイド文字」「半角文字」「全角文字」というような言い方がマイクロソフトやIBM由来の昔からの歴史的経緯がある規格のもので、Unicodeと共存しにくい、互換性の低い概念だと思います。たとえば「半角文字」はJIS X 0201で使われていたカタカナや英数字を表現するためのもので、それをうまくユーザーに伝えるために「半角」「全角」と誰かが言いだしたのだと思います。半角も全角ももはやUnicodeでは同じもので、表示時に使う幅だけが違うはずです。なので、Unicodeのコードポイントという文脈から、UTF-8では何バイト使用するのか、UTF-16では何バイト使用するのか、Shift JISに変換すると何バイト使用するのか、と考えるのが自然な気がしています。JSのドキュメント等でマルチバイト文字の話が出ないのはそういう文脈によると思います。
また、たとえばUTF-16では、ふつうの
aでも実は2バイト使いますが、俗に「1バイトの文字」というふうに表現されているような気がします。ある意味、UTF-16ではすべての文字がマルチバイト文字だと思います。(aは、UTF-8、Shift JIS、ASCIIでは1バイトです)それからJavaScriptでは、UTF-16またはUCS-2(UTF-16の拡張前のもの)を使っており、特段断られていない限りはUTF-16でよろしくというふうにEcmaScriptの標準で決まっているみたいです。
↓参考
ご参考になれば幸いですm(_ _)m
(あえて触れなかったのかもしれませんが…)
Intl.Segmenterを利用すると厳密とまではいかなくとも改善されるようです。例に挙がっているいる文字で試すと、とりあえず人間から見た文字数を取得できています。
以下が試したコードです。
以下が実行結果です。実際にはターミナルに出力すると絵文字の表示が崩れたので(その場合でもセグメント数は期待した値になっていました)、ファイルにリダイレクトしたものを貼り付けています。
しかしながら、最初に「厳密とまではいかなくとも」と書いたのには理由があります
(
Intl.Segmenterは最近知ったので間違っていたらすみません)。上記のコードではロケールを省略していても期待した結果になっていますが、MDN のドキュメントには下記ような記述があります。
ここで「ロケールの指定によっては結果が異なることもある?」という疑問が出てきます。
その点について下記のページなどをちょっと読んでみると
(ここの Note に記載されている内容から)境界の決定方法は実装によるようですが、デフォルトのアルゴリズムの参考として下記のリンクが記載されていました。
その中の「3 Grapheme Cluster Boundaries」も少し読んでみるとやはりロケール別の書記素クラスターなどを利用しないと対応できない状況もありそうです。
このような訳で少しモヤっとしたことを書いてしまいましたが、現状に比べると多くの場合で改善できそうなので、絵文字対応の substring を改善する参考になればと思いコメントしました。
@hankei6km
ありがとうございます!! Intl.Segmenterというものがあるんですね…👀全然知らなかったのでとても助かりました。しかもこれは試してみたところ異体字セレクタなども加味して実装されているのですごく良さそうですね…ドキュメントについてもありがとうございます見てみます
@harukaeru
異字体セレクタに対応しているのは、やはり良い感じですよね。
絵文字などのカウントは楽になりそうなので Intl.Segmenter は個人的にも期待大です。
あとはちょっと書き損ねていたのですが現状ではサポートされていない環境もあるようなので、その辺が早く落ち着いてくれればと思っています。
コメント見落としている間にすごく詳細な議論を頂いていた…! お二人ともコメントありがとうございます!
こちらはお察し頂いたとおりで、そもそも「人間から見た文字数」がFull Emoji Modifierを使っているものだと対応状況によって複数絵文字になってしまうなど厳密には議論不能なので、敢えてファジーな表現を使っています。
記事の意図としては「広く使われる英字・日本語文字の範囲では、JavaScript標準の文字列でいわゆる半角・全角を区別せず直感的な文字数を数えられる」が主題でした。(この時点でかなりファジーな議論)
その上で、自分で同様の文字数カウントを実装するための方法を調べた結果正規表現のunicodeプロパティが使えそうだったため、(自コード上では不要だったものの)substringを再実装してみたというのをオマケ的に書いていました。が、こちらは説明不足でだいぶ不正確になっていましたね…
本文にコメント参照の追記をしておこうと思います。ありがとうございました!