7月は、LayerX エンジニアブログを活発にする期間でした!
8月も発信を続けていきます、今日の記事はバクラク事業部 Enabling Team エンジニアの @yyoshiki41(中川佳希)が担当します。
Elasticsearch から OpenSearch へ
これまでバクラク事業部内では検索サービスに、AWSマネージドの Elasticsearch 7.10 を利用していました。
2023年1月 Amazon OpenSearch Serverless がGAとなったため、開発者での運用改善を含め移行先にあがりました。今回の記事では、移行へのステップや実装を刷新した点を紹介します。
OpenSearch Serverless
資料としては、AWS Black Belt Seminar の Amazon OpenSearch Serverless が非常に分かりやすく参考にさせていただきました。
アーキテクチャ上で最も唸った点は、ゲートウェイ、書き込みと読み込み、そしてストレージを独立させてスケール出来る構成を内部で実現しているというAWSらしいマイクロサービス化です。
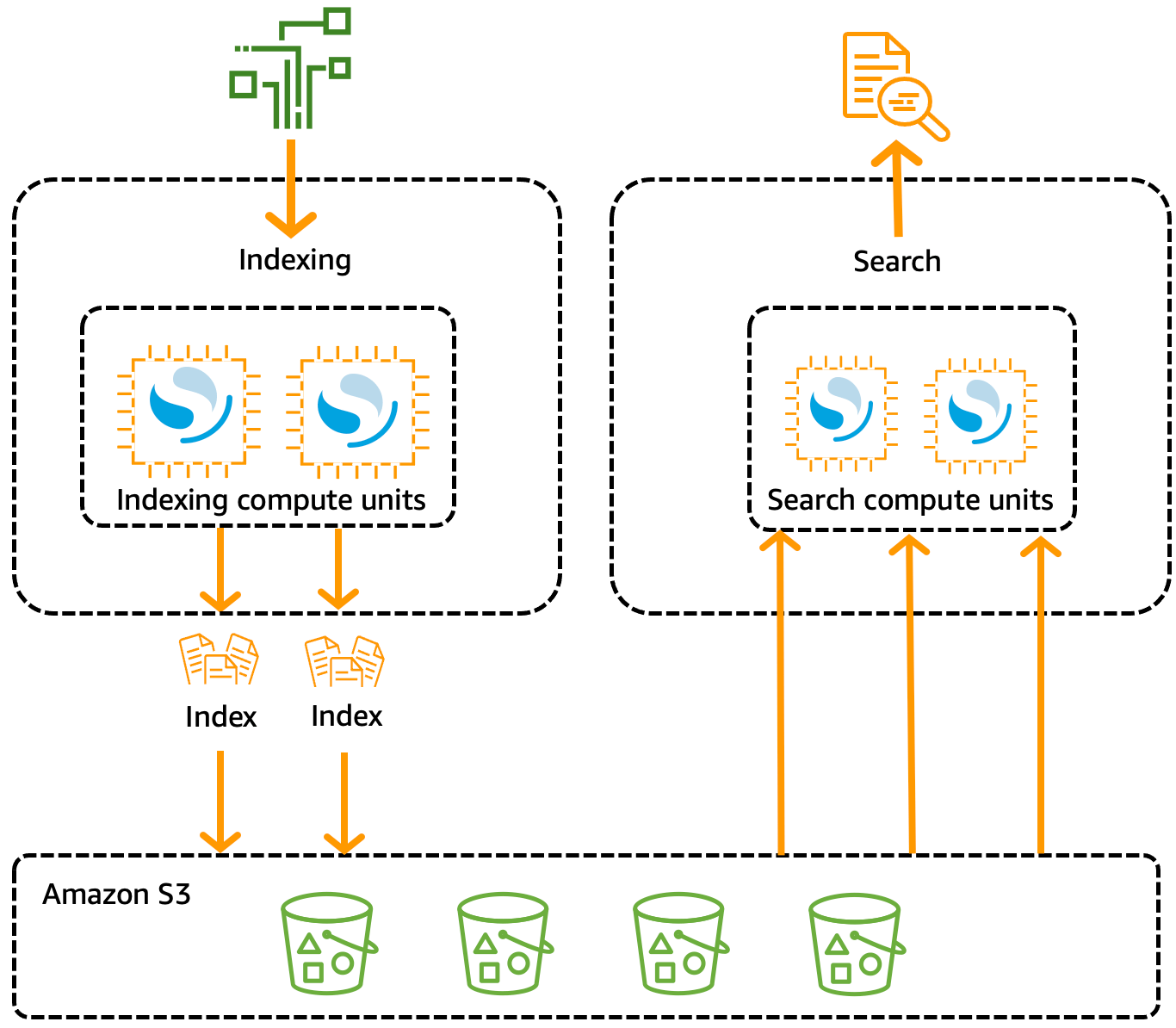
従来のインデックスを垂直分割して、Primary/Replica を決めデータノードに分散配置させるクラスタリングよりも理にかなったスケーリング戦略が取れる点は、非常に大きな差だと思います。
また、従来型クラスタリングのノード数が設定不要で、OCU(OpenSearch Capacity Unit)割当でのスケールイン/アウトが可能な点も運用コストが下がる Serverless のメリットです。(逆にインデックスの内部でのシャード数は自動的に決定され、ユーザー側で設定・反映も出来ないため、チューニングをしたいなどのケースなら Serverless ではない選択肢もあるかと思います。)
OCU(OpenSearch Capacity Unit) は、 indexing(書き込み)/search(読み込み) で個別に変更可能で、よりワークロードに適した設定でのコスト調整が可能です。
Application
アプリケーション開発において行った改善について紹介します。
1. Index Alias
以前は書き込み/読み込みにIndex名を直接使っており、データ構造の変更が行いづらい状態になっていました。
Index Alias を利用し、アプリ側からは Alias を参照するようにしました。これにより、実体となるIndexを作り替え、あとは Alias 紐づけ先を変更すれば、新しいIndexをリリースが出来ます。Indexのライフサイクルをより柔軟に出来、アプリ側での特別な変更も不要になります。
2. Re-Indexing
運用上、サービス系統からのオンラインでのIndexingとは別に、プライマリデータソースであるRDSからIndex再作成を行いたいケースもあるため、バッチ機構も新たに用意しました。新たなIndexを作成した後に、Alias 紐づけを行えば、任意のタイミングでのリリースが可能になります。
または、Alias に対し複数のIndexを紐付けることも可能です。Alias 書き込み先を新しいIndexに向け、バッチとサービスの逐次、両方からの処理を受け付ける場合です。
これはデータ構造に変化がなく、重複したデータがIndexから返ってくることをアプリ側でハンドル出来るケースで有用です。
また、上で必要となるIndex再作成を行うバッチ機構も新たに、Step-Functions -> ECS Run Task で行うようにしています。サービス系統からのワークロードからは切り離し、現在のデータボリュームでは十数分ほどで完了します。
3. custom routing の利用
通常では、ドキュメントの <_id> でシャードが決定されます。custom routing はドキュメントへのAPI操作時に、URLパラメータを付与し、OpenSearch利用者側でシャードキーを明示的にするものです。
バクラクのようなマルチテナント型の業務アプリケーションの場合、基本的にサービス系統からの操作はテナント単位で実行されます。(そのテナント内で完結し、他のテナントデータに影響を与えることがない。)
そのため、より効率的にかつ事故のリスクも減る形で提供できるよう routing には、テナントのIDを活用するように変更しました。
4. go クライアントライブラリのリプレイス
クライアントライブラリも elastic/go-elasticsearch から、opensearch-project/opensearch-go へ移行しました。APIの大きな変更もなく、retry-backoff や bulk operation も利用可能です。
モニタリングは DataDog で行っているため、tracer には net/http を利用してクライアントライブラリ内のTransport層で http.request として計測されます。
5. その他、リファクタリング
内部実装の話にはなりますが、Search を行う側のサービスには、OpenSearch API を直接公開せず、一段抽象化した関数で提供するように変更しました。オーナーの責務を明確にし、より安全に意図した形で Search 提供を行うためです。
また、ローカル開発で、スキーマjsonや Index Alias の設定を各開発者が curl 実行する手間をなくすため、開発サーバー起動時にフックして設定反映するようにもしました。OpenSearch API の詳細を知らなくても設定と Search 実行には困らないようにするためです。
Trade-off
最後に、移行でのトレードオフについても記述しておきます。
最も運用上大きな点は、OpenSearch Serverless にはまだスナップショット機構がないことです。冒頭の資料でもワークアラウンドが紹介されていますが、リストアの仕組みを組む必要がある点はデータボリュームが増えるほど面倒な点です。バクラクでは上で説明したプライマリデータソースからのRe-Indexingで回避を行っています。
そして、プラグインを自由に入れれるわけではない点も利用前のチェックが必須と思います。
Closing
今回の OpenSearch Serverless 化で運用コスト、より柔軟なスケールイン/アウトが可能になりました。今後も内部的な改善を含め、アプリ開発者にもSREにも優しいシステムを構築していきたいと思います!

Discussion