これは、SRE Advent Calendar 2023の18日目の記事です
はじめに
LAPRAS株式会社でSREをしているyktakaha4と申します🐧
私は、LAPRAS株式会社にSWEとして入社後、ロールチェンジを経て約2年間にわたって組織のLead SREとしてプロダクトの改善に取り組んできました
技術面での学びがあったり、うまくいったな~と感じたものについては適宜Zennに記事を書いてきたのですが、ちょっとしたドキュメンテーションでなどの記事にするほどまとまった分量が取れない小ネタ🍣については書くきっかけが無く、環境が変わったり忘れたりして揮発してしまう前に何かしら備忘メモを遺しておきたいと考えていました
そんな折に、ちょうどこのアドベントカレンダーのことを知り、よい機会なので参加することとしました🐤
大規模だったり技術難易度の高い組織でバリバリ働かれている方には物足りない内容かもしれませんが、最近SREをはじめたばかりの方であったり、なにがしかの事情で本番稼働中のシステム群を丸ごと引き継いだ方には、業務の取っ掛かりとしてお役立ていただけるかもしれません
なお、(番外編)と書かれいてるものは、私が直接管理していたりはじめたものではないのですが、組織内でやられていてよかった~と感じたものを紹介しています
ドキュメント
実務の中で、他者に対して共有されたり、繰り返し修正したりなど 資産性が高い と感じたものは大体以下の二種類に大別できたように思います
- チーム内・チーム外で共通認識を持つために定義付けが必要な情報
- ロードマップやOKRといった目標設定に用いるもの
- 定型化された必須のオペレーションを消化してもらうために必要な手順が逐次的に書かれた情報
- READMEの開発環境構築の節や、社内システムへの接続マニュアルなど
- それ以外の情報
- バックログとして扱う
上記の性質を持つドキュメントは、わたしが組織を離れるときにそのまま引き継ぎ資料になるはずです
そのため、他のドキュメントとは区別したインデックスドキュメントを定義し、定期的に内容を選別・更新しています
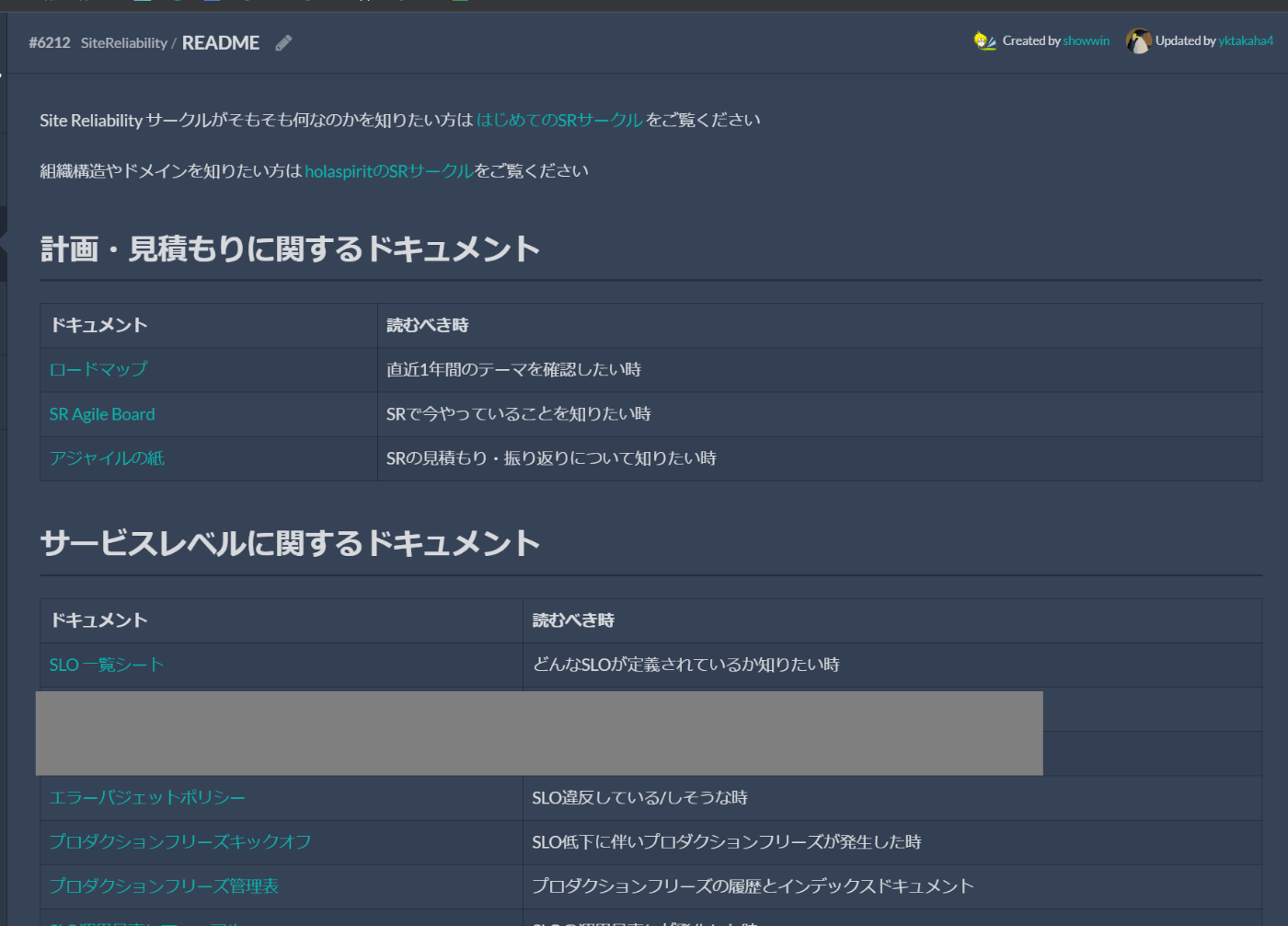
インデックスドキュメント
具体的な運用方法については社内で実践しているものがあるので、よければご覧ください
ロードマップ・OKR
目標管理においては、少なくとも以下の種類のドキュメントをよいように感じました
ある課題について会話している時に、それがロードマップとOKRのどちらの達成に寄与するものなのか区別できると、日々のタスク決定といったより短期的なサイクルでの判断で長期的な視点を加味できるようになったり、インシデント等で突発的な作業に工数を取られていることに気づけるようになります
- 複数期を跨いで実現してきたい方向性を示す情報
- 幣チームではロードマップ
- 今期において達成したい目標のチーム内外での合意を示す情報
- 幣チームではOKR

ロードマップ
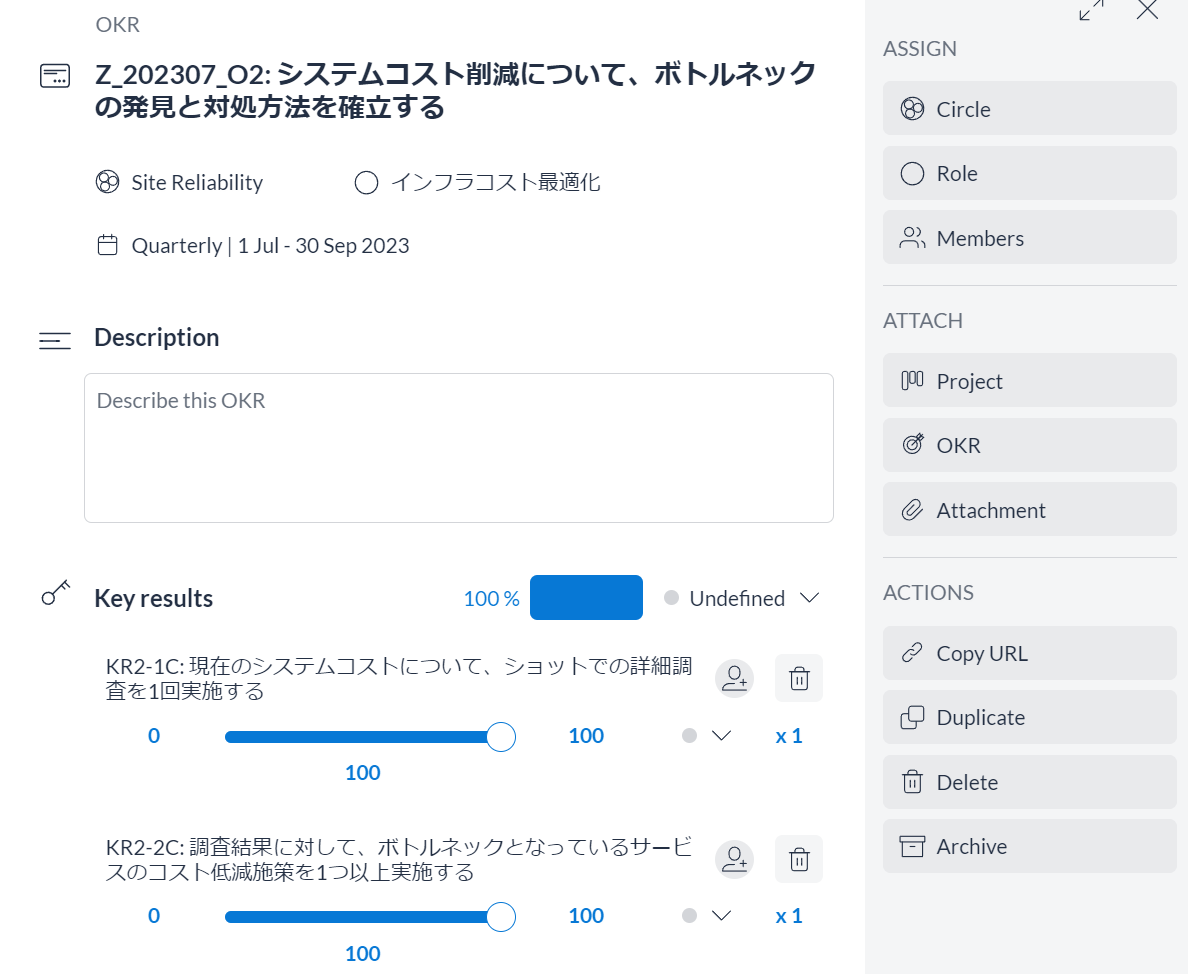
OKR
個人的に重要視していることとして、期の途中で目標を大きく変更する必要を感じた時でも、立てた目標を削除して置き換えるのでなく、期初から方向転換したという事実を記録しています
最も大切なのは短期的な目標の達成ではなく 顧客価値を最大化するために仮説を立てて実行する力を養うこと です
想定が外れた場合でも、なぜそのような目標を期初に立てたのか、どうして目標を変更することになったか議論することで、インシデント対応におけるポストモーテムのようにチームの改善能力を高めるきっかけにできます
システム構成図
特にシステムを引き継いだ初期においては、主要プロダクト間の連携について示す図や、ネットワーク構成図を作ることは自身の理解を深めるために有効と感じました
ただ、これらについて正確な内容を維持し続けるのは難しかったため、自身が構成をある程度把握した段階で維持対象のドキュメントからは外して、参考情報に留めてもよいかもしれません
オンボーディングの過程で新規着任者にコードリーディングしてもらいつつ、その時の最新の構成図を作ってもらう…といったワークをしてもよいものと思います
サービスメンテナンスポリシー
SREとして全社的に監視や仕組みを導入していこうとすると、それらに一律に同一の対応をするよりも、事業影響度が大きいプロダクトにリソースを割いた方が大きな効果が得られることに気づきます
プロダクトを重要度によっておおまかに大別し、それらについてどのような運用を原則とするか定めておくことで、運用や仕組みの構築をおこなう際の力の入れ具合をチーム内外で合意できるようになります
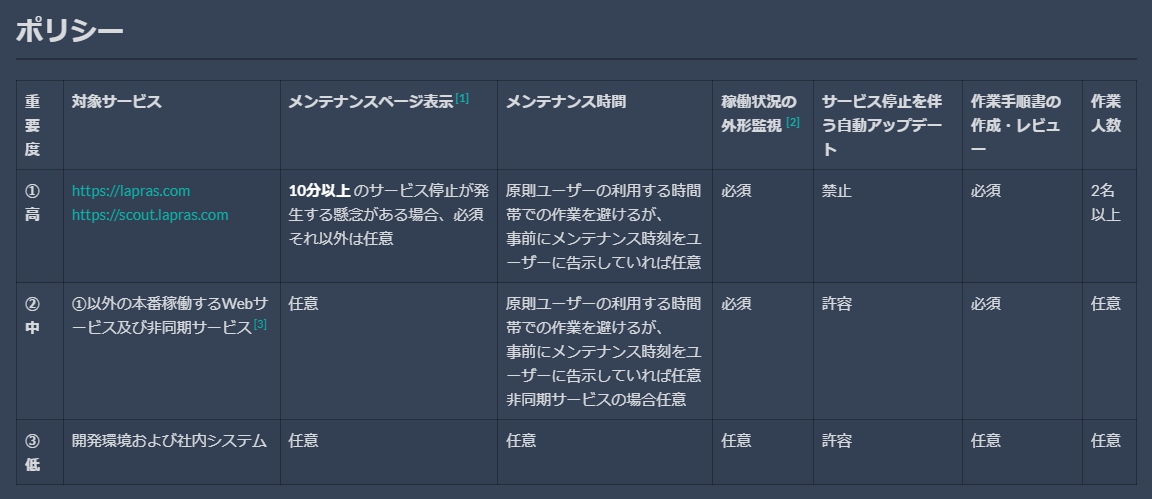
サービスメンテナンスポリシー
これにより、重要度が(今のところ)そこまで高くないシステムに対して、新規着任者が重厚すぎる監視運用を引いてしまうといったミスを防ぐ効果が見込めます
また、主要プロダクトに対して無断でのシステム停止を認めない…という方針は、フィーチャーフラグやストラングラーパターンなどの無停止でのシステム変更の計画を促すこととなるため、そうした意味でも明確にレギュレーションを宣言することが重要であるように思います
職務記述書
あなたが1人目のSREだった場合、組織の状況によって2人目のSREを採用することになる場合もあると思います
増員は社内異動やリファラルでの雇用機会など思わぬタイミングで発生することもあるので、自身がおこなっている業務をベースに職務記述書を予め作成しておくと、対外的なコミュニケーションの機会で活用できます
また、1人で仕事をしていると、他人に自身の業務を伝える機会がなく離職などによる業務の引き継ぎ時に後任に対してどのような業務上の期待が発生するか曖昧になりやすいですが、職務記述書を作成する過程で業務の棚卸しがされることも期待できます
弊社の例として、以下の内容について記載していました
- 配属チームと役割
- 募集背景
- 求める人物像
- スキルとマインドセットは分けて書く
- スキルは必須とあると尚可のものを分ける
- 仕事内容
-
配属チームと役割の項で書いたものよりも具体的なもの
-
- 待遇
また、以下のようなエンジニア組織全体にかかわる情報については、採用資料など別のドキュメントにまとめておくとよいように思います
- 利用する開発環境、ツール
- 組織全体の構造
- 社内エンジニアの特徴
- 選考フロー
バックログ
弊社のエンジニア組織ではプロダクトバックログはGitHubのとあるリポジトリのIssueに集約しており、調査や仕様検討などで何らかの記録をおこなうときは、Issueのコメントに記載しています
必要に応じてfigmaやesaなどの別ツールを用いる場合でも、それらのドキュメントへのリンクはGitHub Issueに集約します
単一のバックログを用いることで、検索性の向上やIssueクローズまでの時間などを計測しやすくなります
加えて、PR作成時にIssue(または、関連するSlackスレッドなどの修正が発生する元となった情報)へのリンクの添付も運用上必須としており、SaaSのアカウント設定変更などの記録が残りづらい情報についても、当時どのような意思決定があったか後任に引き継いでいけるように工夫しています
Issueへのリンク
表
弊社ではインフラの運用にKubernetesやTerraformを用いており、日々の業務の中で一定の変更管理がおこなえるようになってはいますが、そこからこぼれてしまう内容や、一覧化して定期確認したほうがよい内容については、スプレッドシートで表を作って運用しています
それらについてご紹介します
利用ドメイン一覧
ドメインレジストラとの契約は一般に長期にわたるため、担当者の離職時にコンテキストを失いやすいです
少なくとも、どのドメインをどのレジストラで取得しているか最低限把握できていると混乱が防げます
可視化することで、レジストラが多すぎて管理上散らかっていることが意識できると、移管しようという気持ちも湧いてくるものと思います

利用ドメイン一覧
運用中サービス・bot一覧
自社で管理しているシステムについては、管理系画面も含めて一定の粒度で全数を把握できるようにしておくとよいです
ホスティングをおこなっている環境(コンテナ / サーバレス / VPSなど)やCI/CDの有無について追記できていると、緊急性の高いセキュリティアップデートの時などに影響判断やトリアージがやりやすくなります
表の情報を常に新鮮な状態を保とうとすると息切れしやすいので、Qに1度棚卸の時間を設けたり、会議体で定期的に確認して追記する運用にできるとよいものと思います

利用サービス一覧
また、ここで作ったサービスURL一覧が育ってきたら、これらを外形監視対象にできると複利的な活用ができます
契約中外部サービス・支払カード一覧
プロダクト開発に関する社外SaaSについては、契約状態と支払いに登録しているカード番号を記録しておくと、支払いカードの変更時にまごつきません
カード情報については Visa ****9999 12/99 のように末尾桁だけ書いておくようにしましょう
SaaSは開発組織全体で利用することもあり、誰かが契約した後に利用状況が判別しないまま放置されるといったことが起きやすいものと思います
サービスの可用性はコンポーネントの数によって決まると思いますので、定期的な棚卸と、サービスの集約がおこなえるとよいものと思います

外部サービス一覧
カード番号については別表にして、それがどのような経緯で発行されているカードなのかと、正確な番号、CVCを知っているのはだれかをメモしておくとよいでしょう

カード番号情報
対応せんと死ぬ管理表
弊社ではインフラにAWSの各種マネージドサービスを利用しているため、継続的なミドルウェアやランタイムのバージョンアップが必要となります
これらはAWS Healthを利用すると参照できるため、弊社ではSNS -> AWS Chatbotを経由して特定のSlackチャンネルに流すようにしています
有償のSlackプランではメールアドレス経由でのメッセージ投稿をサポートしているため、その他のサービスではこちらを利用します

要対応情報を集約するSlackチャンネル
通知された情報については、GitHub Issueに記載した上で一覧表に記載し、完了状況を管理します
定期的な表の見直しをおこなうことで、計画的に対処しやすくなります

対応せんと死ぬ管理表
(番外編)インシデント管理表
弊社ではインシデント対応について一定のオペレーションが確立されており、こちらについても終息のタイミングをめどに記録をおこなっています
社内でインシデント指揮官という役割が存在するため、私は状況をリードするよりはSREとして問題解決に集中することができ、ありがたく思っています
内容としてはおおよそ以下のようなことを記録しています
- 発生日
- レベル
- 🟢: インシデント専用チャンネルに報告がされたが、実際の顧客影響が無かったり、ヒヤリハットで済んだ
- ⚠️: インシデント専用チャンネルに報告がされたが、影響が軽微だったり局所的だったため検討の上通常の不具合改修と同等のフローで解消された
- 🚨: インシデント専用チャンネル報告された後、実際にインシデントとして緊急対処がおこなわれた
- 対応チャンネル・ドキュメント等へのリンク
- 原因
- オペミス / 既存不具合 / 新規リリース失敗などあとから集計できるようにフラグ管理
運用
主に私が入社後に設計した運用のうち、過去に記事にしたものを貼っておきます
SRチーム運用
幣チームでは、アジャイルのプラクティスを参考にしつつIssueを消化していく運用を構築しており、以下の記事で解説しています
元々は2人目のSREをチームに迎え入れた時に必要に駆られて始めたことだったのですが、それ以外の副次的な効果も大きく、よい運用ができていると思っています
SLOとプロダクションフリーズ運用
各社でSLO運用は広く行われていると思いますが、弊社でもSLO運用とエラーバジェット枯渇時のプロダクションフリーズ運用をセットにして組織で運用しています
OS・ミドルウェアアップデート運用
弊社ではインフラにKubernetes(EKS)やRDSを利用しているため、本番環境での定期的なバージョンアップが必要になっています
元々esaの手順書1枚だけだったのを、テストや静的解析の強化や手順書の詳細化を漸進的におこなっていき、今では作業担当者をローテーションしつつ実施できる状況にまでなっています
上記記事を書いたときからの差分としては、手順の抜け漏れ発生リスクを下げるためにコマンド実行単位のより細かな手順書を定義し、チェックを付けながら実行していくというのを最近試しています
内容の置換がやりやすくなったのと、各作業工程でどの程度の量のコマンドを手で打っているのか可視化されるため、作業の自動化へのモチベーションが高められるようになったと思います

作業手順チェックリスト
請求・支払い関連の月次作業マニュアル
外部SaaSのサービス利用額や業務委託の方への支払いなど、お金周りの作業は月末~月初の数営業日以内に実施する必要があり、作業できる人がひとりだけになってしまうとリスクが高いため、マニュアル化した上で毎月イテレーションのタスクとして持ち回りで対処しています
特に、今年はインボイス対応に伴い決済情報への証憑添付をより厳格におこなう必要が生じたため、SaaS毎にどこから証憑を取得するかまとめておくと、作業者によって漏れが生じるのを防げます
現在、支払承認などの特定の操作以外は属人性を排除した定型運用にできていますので、今後アシスタントの方に作業を委譲するといったことも検討したいと思います
プロダクションレディネスチェックリスト
事業計画の達成に向けて新規システムを構築するといったことは、多くの組織において一定発生するものと思います
この時、チームにSREのようなシステムの安定運用がスコープになっている役割のエンジニアがいないと、期日までにできるだけ多くの機能を実装することが過度に優先され、結果バグが多かったり、監視が不十分でバグが起きていることすら十分に監視できていないプロダクトを本番稼働させてしまうことになり得ます
プロダクションレディネスチェックをチェックリストや対面レビューを通じておこなうことで、こうした状況を未然に防ぎやすくなるものと思います
公開アウトプットをあたると前述のリンクの内容のような高度なものが多く、弊社の実情に対しては少々荷が重かったため、以下のように簡易化したものを作成し、新規構築時にSWEにチェックしてもらう運用をしていました
- CI(自動テスト・lint)およびCDが実装されていること
- 外形監視がおこなわれていること
- 作りこみがされたプロダクトにおいては、エラー監視やパフォーマンスモニタリングがおこなわれていること

プロダクションレディネスチェックリスト
スキルチェック
職務記述書 の公開にあたって、ポジションへ応募があったときに実施するスキルチェックの内容についても、必要に応じて検討できるとよさそうです
弊社では、Terraformのバージョンアップのような、実務として実際におこなっている作業を題材に、その具体的な方法や注意点をディスカッションする…といったタイプのものを用意しています
現職で課題として出てくる技術を使ったことのない方の場合は、プロジェクトに参画して知らない技術・環境をどのようにキャッチアップしていくかといったことについてインタビューし、お互いに一緒に働くイメージを持てそうかといった観点をチェックしています
選考の大まかな流れについては以下のドキュメントにもまとめています
(番外編)タクティカルミーティング
弊社は組織運営にホラクラシーを用いており、私のチームでは2週間に1回ホラクラシーに基づいたタクティカルミーティングというものを実践しています
詳細は以下を読んでいただけるとわかりやすいものと思います
タクティカルミーティングの中で気に入っている運用としては、チェックリストがあります
これは、会議体の中で一定の項目を定期チェックしたい時に利用するもので、私たちの会議体では作ったばかりでまだアラート化していないメトリクスの傾向確認や、表の定期的な最新化の思い出しのために利用しています
チェックリスト
(番外編)新入社員オンボーディング
弊社では新入社員のオンボーディングに力を入れており、全社的には以下のような方針で定型化した運用を構築できています
私が入社した時のものなので少し内容が古いですが、エンジニア向けの内容としてはおおよそ以下のような流れになっています
直近では、昨年SREのnappaさんが入社して下さった際には私にてオンボーディングをしたのですが、それ以外のSWEのオンボーディング含め、打率高く型化した運用が構築できているように感じます
特に開発環境のオンボーディングについては、7年間直しながら運用を続けているものなので、弊社環境において躓きやすいところなどが一定網羅されており、初日にローカル環境を構築してメインプロダクトにbugfixなど軽微なPRを出すというのが習わしになっています
これはシニアレベルの方が来た時も同じで、暗にお手並み拝見するのでなく、早期にパフォーマンスを最大化してもらえるような仕組み作りをするのが、受け入れ側に求められているように感じます
オンボーディングドキュメント
細かく探すとまだあるような気もしますが、差しあたって思いつくものについては明文化できたので満足です🐣
明日のアドベントカレンダーもお楽しみに

Discussion