LAPRAS株式会社でSREをしていますyktakaha4と申します🐧
みなさんの会社ではSLOやエラーバジェットに関する運用をおこなっていますでしょうか?
おなじみSRE本にも謳われる通り、これらは機能開発とシステムの信頼性維持をコントロールするための非常に優れた方法ですが、
エラーバジェットが枯渇してしまった時に、解決に向けてプロダクトチームやSREがどのように振る舞うべきか については踏み込んで言及されておらず、組織の形態にあわせてよりよい適用方法を模索する必要があるものと思います
今回は、(残念ながら😿)弊社で実際に発生した エラーバジェット枯渇と、それに伴う本番環境への機能フリーズ事例 をご紹介します
自社サービス開発をおこなっている組織におけるモデルケース のひとつとして参考になる部分があれば幸いです🚙
フリーズから解除に至るまで
ことのおこり
弊社では、エンジニア向けポートフォリオサービスのLAPRAS と、同じくエンジニア向け採用サービスのLAPRAS SCOUTを運営しています
その他、コーポレートページや別事業なども含めると10程度のシステムを本番運用していますが、
上述したふたつのサービスはビジネス上の重要度が特に高いものであるため、各サービスごとに固有のSLOを定義し監視をおこなっています
SLOおよびエラーバジェットについては、前任のSREであり現在はoVice株式会社で働いているshowwinさんが定義し運用をはじめたものですが、
幸いにして(?)実際にエラーバジェットを使い切ることもなく、エンジニア全員でおこなっているDS(デイリースクラム)のワークフローでダッシュボードを確認し、日々 ヨシ! を続ける…という状況が続いていました

エラーバジェットの枯渇
そんな中、LAPRAS SCOUTにおけるSLOのひとつとして定義されている システムへの受信メール連携の95%が5分以内に完了すること に異変が訪れます…⚰️
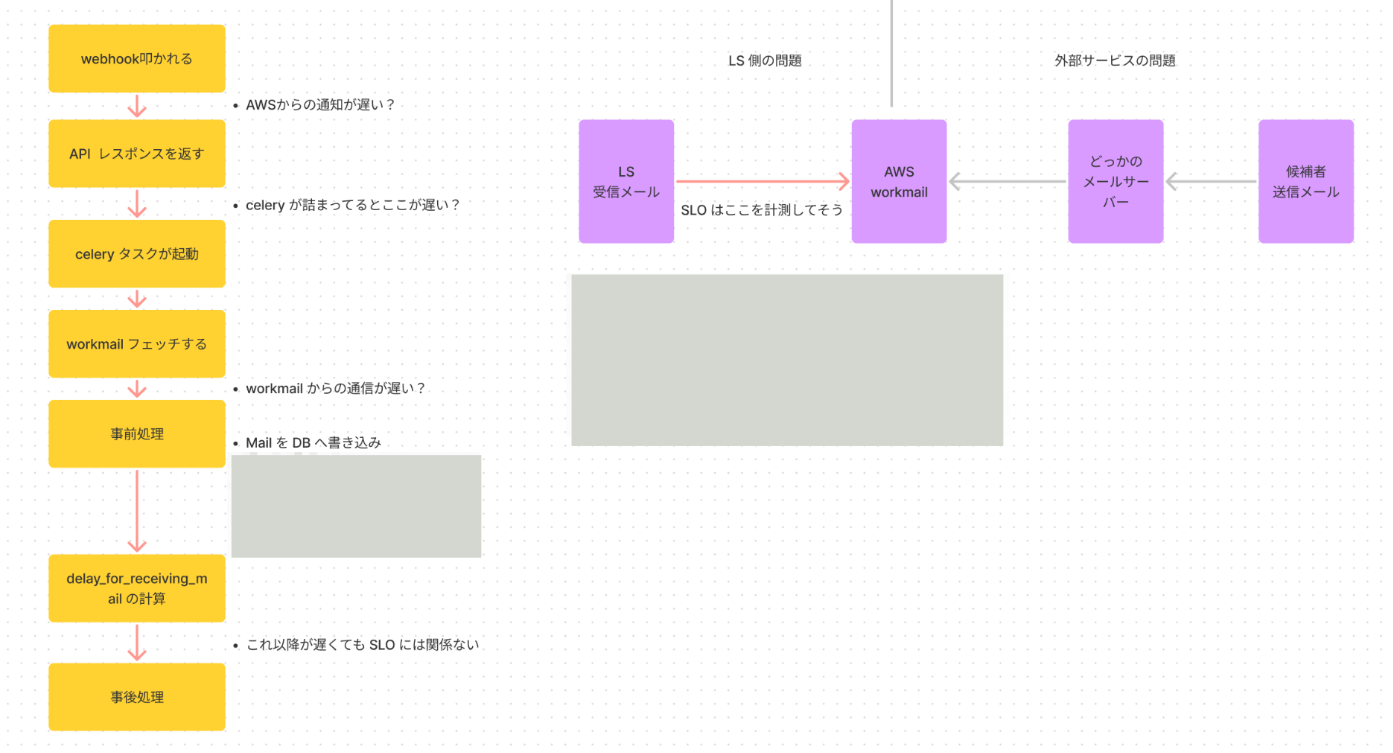
LAPRAS SCOUTには採用候補者と契約企業がメールをやり取りする機能があり、メールを受信する度にPythonのWebアプリケーションフレームワークであるDjangoで実装されているLAPRAS SCOUTに対して受信メールを連携する必要があります
弊社はサービスのインフラにAWSを採用しており、メールの送受信についてもAmazon SES や Amazon WorkMail といったマネージドサービスを利用しているのですが、
開発当初からの機能向上と歴史的な経緯の結果、メール受信のアーキテクチャはそこそこ複雑なものとなってきており、入社歴の浅い何人かの開発メンバーにとってはロジックや仕組みそのものがブラックボックスとなっているなど、課題がある状況でした
そうした状況下で迎えた2022年でしたが、年始からメール受信のエラーバジェットが明らかに減少傾向となり、DSの度に開発メンバーがざわつくようになります👹
弊社には業務委託も含めると現在15名ほどのエンジニアが在籍しており専門性も異なることから、中にはSLOやメール受信の仕組みに馴染みのないメンバーもいます
特にLAPRAS SCOUTを担当しているプロダクトチームはスクラムをおこなっているため、残っているスプリントバックログはどうなるのかといった二次的に発生する諸問題もあるため無理もないことです
(以下は会社紹介資料からの抜粋です)
何よりもSREとしてこの状況を発生させているのはほかでもない私なので、しれっと自分で対処してしまおうか…という念も一瞬よぎりましたが、
CTOのrockyさんと相談し、 SREはチームの主導も含めて対応に関与せず、プロダクトチームに一切を委譲する という判断をしました
例えば、これがインシデント対応のように事象の解決を最優先して対処すべき問題であった場合、
事業継続、ひいてはユーザーへの提供価値の回復のために有識者を中心としたチームにて早急に対応し、全体へはポストモーテム等を利用して事後共有するのが一般的と思います
今回は、早い段階で本番環境で簡単な動作検証をして機能そのものが毀損されている状況ではないことを確認できていたため、
今回の対応を通じて プロダクトチーム内のシステムに関する知識継承 と インシデント発生時の疑似体験 が プロダクトチーム内で実施されること を目標とし、
SREとしては、 プロダクトチームが目標を達成するための支援をおこなう …という方針としました
これに対して、LAPRAS SCOUTのプロダクトオーナー兼エンジニアのchanmoroさんは 下回ってから考える という戦略を取りました
元々エラーバジェットの使い方はプロダクトチームに委ねられており、スプリントの終盤で開発も残っている状況だったため、妥当な判断だったと思います

その後、1月の第4週に差し掛かったところでエラーバジェットを使い切り、本番環境への機能変更を凍結することとなりました🍦
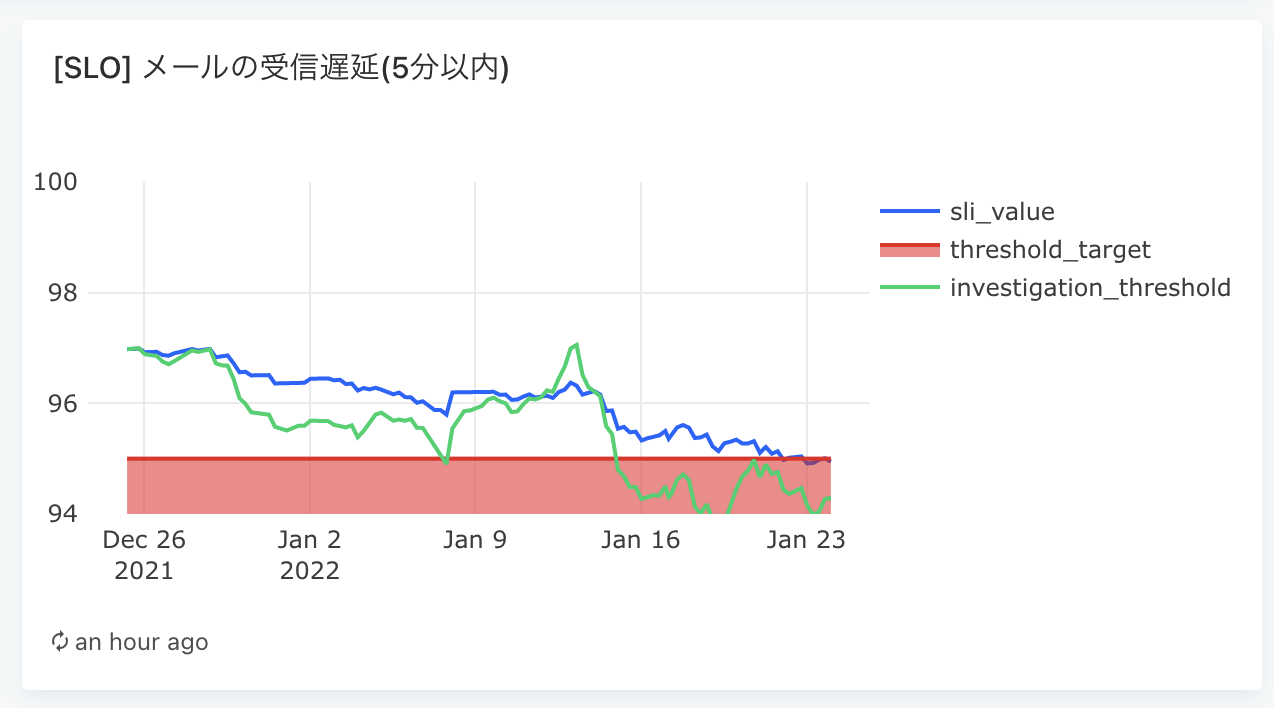
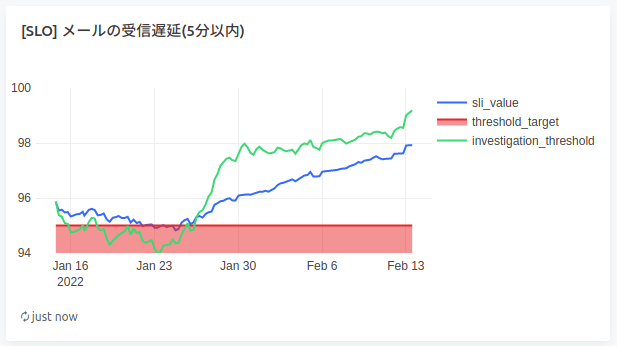
以下図の青色の線が実際のSLIの値(4週間ウィンドウで測定)、赤線がSLOの水準線となります
(緑色の線は試験運用中の値で その時点から一週間同じペースでSLIが増減した場合の値 を示すものとして表示しています)
プロダクションフリーズの宣言
今回のプロダクションフリーズにおいて、SREとして達成を支援すべきと定義した目標は以下でした
- プロダクトチーム内のシステムに関する知識継承
- インシデント発生時の疑似体験
- これらがプロダクトチーム内で実施されること
前述の通り、プロダクトチームには専門性の異なる様々なメンバーがいます
今回のプロダクションフリーズをシステム障害のようなものと捉えられてしまっていると、実際の対応中に齟齬が発生してしまうように思ったため、
上記の目標感がそれとなく認識してもらえるよう、 プロダクションフリーズキックオフ と称してエンジニア全員を招待した30分ほどのミーティングを開催しました
プロダクションフリーズ≠インシデント対応であること
第一に、これがインシデント対応ではなく力を抜いて取り組んでほしいという思いがあったので、弊社エンジニアのkawamataさんがおこなっていたライブラリアップデートの取り組みを引用し、 エラーバジェットを回復するというゲームに取り組んでもらいたい という説明をしました
以下はキックオフに用いたesaからの引用です
達成すべきクエストや、報酬(というにはマッチポンプ感がありますが…🚒)としてUniposをプレゼントすることなどを事前に伝えました

ゲームのルールについて説明する
ゲームを楽しむためには、参加者全員がルールを共有している必要があります
SLI/SLO/エラーバジェットといった前提となる用語の紹介や、ゲームのクリア判定の条件など、プロダクトチームが認識合わせや意思決定をするために必要となる情報をインプットしました

質疑
以上を伝えた上で質疑に入ったのですが、やはりというか SREはプロダクションフリーズの解消について関与しないのか という質問がありました
個人的な心情としてはこうしたトラブルシューティングはむしろ得意分野なので、これに対してだいぶ気持ちがぐらついたのですが、
スクラムマスターのendoさんが まずはプロダクトチームで巻き取ろう と言ってもらい、まずはプロダクトチーム側で一次対応をおこなうこととなりました
振り返ってみて、こうした質問に対しては、 SREはゲームの審判としてイベントに参加・協力する というメッセージを強調できるとよいものと思いました
今回の対応にあたってはフリーズ期間中に以下を審判の役割としておこなっていました。 プロダクトチームが問題解決に集中 できるよう、役割分担ができたのはよかったように思います
- エラーバジェットを日々確認し、プロダクションフリーズ解除を宣言すること
- プロダクトチームの質問に答える
- 例えば
メール受信時のログを確認したいがどのような方法が考えられるかといった質問に対して、知っている範囲で回答する - ルールが十分に決定されてないと思われる事象が見つかった場合、審判として公式見解を示す
- 例えば
- キックオフや振り返り等の各種イベントの招集
- ビジネスサイドなど、関係者への周知
- ここはCTOのrockyさんにも助けてもらいました🚑
フリーズ中の対応
情報共有
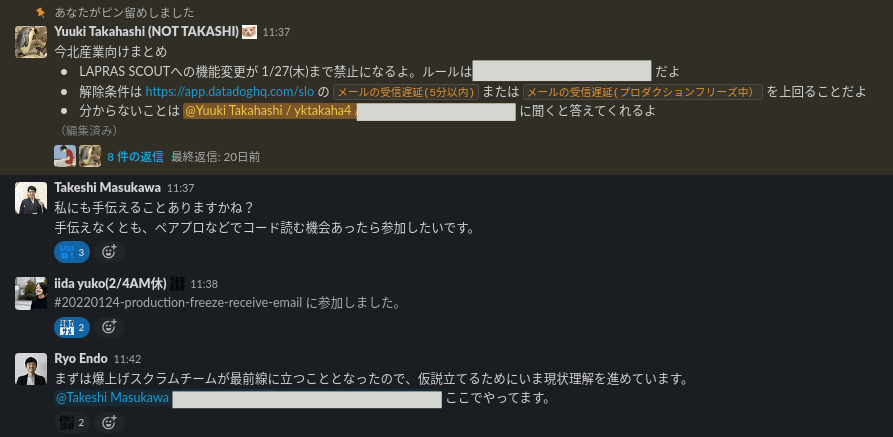
プロダクトチームによる対応が始まってから情報共有の方法を決められていなかったことに気づき、急いでSlackチャンネルを作って関係者を招待しました
また、このタイミングでビジネスサイドの方々への周知が十分でないことにも思い当たったので、プロダクションフリーズが開始されたことをRandomチャンネルで伝えました
結果的に、単に興味があるだけの人でも参加して状況を把握しやすくなったり、状況に進展があった時にリアクションなどで盛り上げてくれて運営側としては大変ありがたかったです🐜
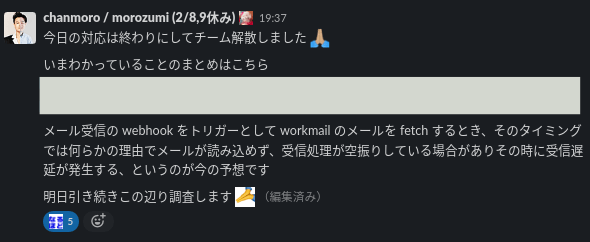
また、これは普段インシデント対応の際にもおこなっていたことだったのでchanmoroさんが気を利かせてやってくれたことでしたが、進捗状況を適宜報告してもらえたので、こちらも状況把握の観点で必要でしたし、助かりました
プロダクトチームの取り組み
これはプロダクトチームが自主的におこなっていたことですが、対応にあたってesaで専用の記事を作成し、状況を細かくまとめながら対応をしていました
Whimsical(作図ツール)にてアーキテクチャの整理をしたりなど、特定の人物だけで問題解決をしてしまうのでなく、細かく認識合わせをしながら対応を進められていてよかったです
問題の解決
数日にわたる戦いの結果、受信遅延が発生する理由についておおよその見当が付き、解決に寄与すると考えられるコード修正が本番にリリースされました
(コード修正内容の詳細については、記事の本旨から逸れるため割愛します)
その結果、無事にエラーバジェットが蓄積されるようになり、フリーズから3営業日目の時点で正式にプロダクションフリーズ解除となりました🎉

ちなみに、この記事を書いている時点でのエラーバジェットは98%まで増加しています
これは今回の対応をおこなう前の水準よりも高い値のため、実際にプロダクトの品質改善が達成できたものと思います
振り返り
解決の翌週に、関係者を集めて30分ほど振り返りの時間を作り、プロダクトチーム内でどのような対応をおこなったかの共有と、その中で見つかったKeepとProblemを共有してもらいました
以下は振り返りのesaの一部ですが、対応をおこなってくれたプロダクトチームとしては、普段ほとんど機能改修をおこなったことのない部分であったにも関わらず、認識を共有しながら対応を進められていたようでした

調査に直接的に関わらなかったメンバーからも、以下のようなフィードバックがありました

課題と反省
今回は初回にしてはかなりスムーズに実施できたように思いましたが、今後想定される失敗ポイントや運用上の課題についてもわかってきたので、幾つか書き残したいと思います
プロダクションフリーズ指揮官的な役割を任命したほうがいいかも?
そもそも プロダクトチームに一切を委譲する という方針でしたが、それ以前にインシデント対応的なプロセスで問題解決をおこなって欲しかったことを考えると、
インシデント指揮官 的な役割の人物を立てて対処に取り組んでもらうことを前提とした方がよいと強く感じました
今回は、プロダクトオーナー兼エンジニアという指揮官として理想的なメンバーがおり、かつ自主的に指揮官を担当してくれたことで事なきを得ましたが、
毎回同じ人物が指揮官をすると、知識の継承やインシデントの模擬対応という観点で望ましくないため、今後はローテーション制にしたりチーム内で指名してもらうといった運用にできるとよいものと思いました
ビジネスサイドの人を怖がらせすぎてしまった
実際にSlack上であったやり取りとして、状況を察したビジネスサイドの方が1on1などのミーティングを自主的にリスケしたりキャンセルする…といったことがありました
インシデント体制が敷かれた時と同様の対応をしてくださったことによるもので、お気持ちはありがたかったものの、審判的には 機能開発のリリース凍結を守ってもらえていれば必ずしも最優先で対応してもらう義務はない という判断が適当かと思ったため、
そうした温度感の齟齬が起きないように、Slackチャンネルでの周知などを通じて インシデント対応とは根本的に異なるイベント という認識を組織内で持ってもらうことが重要に感じました
SLOの設定根拠をプロダクトチームで理解できている必要がある
プロダクトチームからのフィードバックがあり納得したことですが、そもそも現在運用されているSLOの決定に現在のプロダクトチームが直接的に関わっておらず、対応をはじめる段階で 「そもそもこれはフリーズしてまで対応すべき重大な問題なのか…?」 という雑念があったとのことでした
これは、SLOの策定当時から体制変更に伴い開発組織が大きく変わっていることと、元々数ヶ月毎にSLOの見直しをおこなう…という運用があったものを十分守れていなかったことが原因でした
半年間ほど運用してきて、追加でSLIを定めたほうがよいと思われる観点や、かなりエラーバジェットを余らせているSLOもあるため、近く見直しに着手したいと思います
プロダクションフリーズ運用マニュアル
SREとして、プロダクションフリーズに関連して実施すべきことをチェックリスト型式でまとめました
次回対応することとなった時に活用したいと思います(自分で)
凍結の瞬間までに実施すべきこと
-
プロダクションフリーズに関する以下ルールの明文化および内容の確認
- 突入条件
- 凍結期間中の禁止事項
- 脱出条件
- エラーバジェットの残時間から、フリーズが開始される最短のタイミングを確認
- ビジネスサイドへの周知
凍結期間中に実施すべきこと
- 情報共有場所の認識合わせ
- プロダクトチームからの質問に答える
-
プロダクトチームへの協力依頼
- 調査および対応をドキュメントに残してもらう
- 進捗状況を共有してもらうよう(少なくとも日次ペースくらいで)
- 日々エラーバジェットを確認し、解除条件を満たすかチェック
凍結の解除後に実施すべきこと
- ビジネスサイドへの周知
- (解除後1週間くらいを目処に)振り返りの実施
- プロダクトチームから出た運用面でのフィードバックについて運用を改善
おわりに
代表が交代するといったできごとも起きていますが、どっこいやっています🐸
ポジションに興味を持って頂けた方がいらっしゃいましたらお話しましょう
文中でも紹介したCTOのrockyさんとのカジュアル面談を希望される方はこちらから
ありがとうございました🍏
参考
実際の事例として、以下のような記事を公開されている方がいました
大変参考になります…ありがとうございます

Discussion