これは、LAPRAS Advent Calendar 2024の14日目の記事です。
- プライベートでAWSでのインフラ構築を依頼される(ボランティア)
- Terraformを本格的に触ってみてIaCの魅力に今更気づく
- 1 on 1にて「自分、インフラに興味ありますっ!SRE部署行きたいです!」と勢いで異動要望
という感じの流れがあってから1ヶ月ほどで...「バックエンドエンジニア兼なんちゃってMOps」だった自分が、SREチームに参画することになりました。
この記事ではそんな「監督!自分、SRE行けます!行かせてください!!」という勢いのみで、完全に畑違いのチームに参画した時のキャッチアップ方針・実務への取り組み・結果について解説します。
1. チーム参画が決まってからやったこと
1-1. 「望んでやって来た」ことを示す
まず異動が決まったタイミングで「望んでインフラ・SREに来た」ということを明示的に受け入れ先のチームに伝えました。
また「ぞす!自分、インフラ未経験だけどやれます!」という勢いだけだと相手もコミュニケーションに困りそうだろうなということで、とりあえず自分の場合はAWS SAAの資格を取得しておきました。
資格があることで「インフラ未経験だけど最低限これ位の知識はあります」ということを分かりやすく伝えられます。
また、異動をさせる側・受け入れる側も「本当にこの人はこの分野やりたいんだな」と安心して送り出し・受け入れすることが出来る、という効果も狙ってとのことでした。
1-2.SREチームの上司との期待値すり合わせ
猪突猛進しようとする癖のある自分ですが、SREは守備力を高める仕事。
変に一人で頑張ろうとししすぎて、「あの祠(インフラ)を壊したんか!?」とならないようにしないと...というのを意識して、最初にしっかりと期待値をすり合わせしてもらうことにしました。

上記に加え、『新しいチームに加わるエンジニアのための "被" オンボーディングガイド』に従い、特に最初のキャッチアップ期間中は「実タスクの量をこなす」ことよりも、「現状把握に努めること」を優先しようという会話もしました。
1-3. キャッチアップのためにやること・やらないことを明確に
先程の期待値すりあわせでは主に「(仕事面で)この時期までにこうなって欲しい」ということを合意するために行いました。
それとは別に、上記の目標を達成するために「どういったスキルを重点的にキャッチアップすると良さそうか」というのも相談しておきました。

※受け入れチーム先との相談で用いた『ぼくのかんがえたSREに必要そうなスキルマップ図』。正直粒度がバラバラだったりするが、一旦の優先順位付けを確認するのには使えた。会議をする際には、簡単な図やドキュメントを作っておくといろいろ捗る
「運用改善の企画」や「SLA、SLO、SLI の設定」といったSREチームの向かう大きな方向性決めを(マネージャーでない)自分が即座に担当するわけではありません。
=>なのでそういったいわゆる「上流工程」のお仕事に繋がる部分の学習はマネージャーとの合意の上で一時的に『諦める』ことにしました。
※せいぜい、「Site reliability engineering」や「Service-level objective」といったWikipediaの記事を流し読みするレベルに留めました。
その代わりに実際に担当するであろうタスクで即座に使えるような、具体的なツールやライブラリの使い方や構成などを学ぶことにリソースを集中させることにしました。
ここらへん「"Site Reliability Engineering"をやるのだから、SRE本を読むなどして、根幹となるSLA、SLO、SLI などの考え方についてしっかり学ぶべきだ!」という意見もあるかと思います。
実際、新卒でSREポジションに入られる方ならしっかりと研修期間を取って学ぶ方が良いと自分も思います。
ただ自己学習をするにもリソース(時間)が無限にあるわけではないのである程度の「選択と集中」は必要になるというのが自分の考えです。
2. チーム参画前後にやったキャッチアップ
2-1. Terraformの復習 & k8sの学習
Terraformに関してはAWS ECSを用いたシステム構築をプライベートで行っていた際に参考にしていた『Pragmatic Terraform on AWS』を通しで読み直ししました。
※『実践Terraform』の同人版?特にフォーマットにこだわりなければ左記のものでよいと思う
上記の書籍、Terraformの(1)基礎知識(2)実践的な構築(3)設計の考え方、がちょうど良い塩梅で簡潔に説明されており、Terraformでの構築を通してAWSについても学べる...という至れり尽くせりなまさに「こういうのが欲しかった…!」という超おすすめ本です。
k8sに関しては、「何もわからん(誇張なし)」という状態だったので、まずは概要を掴むためにインターネットイニシアティブ社がYoutubeで出されている『Kubernetes 入門 (IIJ Bootcamp 2023)』という研修動画を視聴しました。
※研修動画と言っても、ずんだもんが「k8sの何が嬉しいのか」や「k8sの基本構成(コントロールプレーンやワーカーノードなど)」をコミカルかつ分かりやすく解説してくれる見やすい内容です
それに続いて『つくって、壊して、直して学ぶ Kubernetes入門』という書籍を読破しました。
kind(minikubeみたいなやつ)というローカルでk8sを学習するためのツールを用いて、実際にpodやdeployment、serviceといった各種リソースを作ったりあえて壊して直してみたり...と実務に近い学習が出来るオススメ本です。
その後、CKADの合格を目標に、Udemyの「Kubernetes Certified Application Developer (CKAD) with Tests」という講座を購入しました。
これもUdemyの講座提供者が提供するインフラ環境でのハンズオン学習が出来るので非常に実践的で身につきやすいと思います。
※とは言えまだこれは半分くらいしか見終わってない... + 本当はこの記事を書くまでにCKAD合格しておきたかったのだが、お恥ずかしながらまだ試験対策が終わっておらず未受験デス...(T_T)
一部学習未了なところもありますが、この時点で後述する「アーキテクチャ質問会でのコードリーディング」や「Pod分離」などの実タスクをこなす上でほぼ困ることはなくなっていました。
2-2. インフラのアーキテクチャ質問会に付き合ってもらう
メインプロダクトのシステムに関しては既にSRがアーキテクチャ図を作ってくれていたのでそれを元に質問会時間を作ってもらい、全体感の理解に努めました。
ただ上記とは別に、社内で使っているBIツール(Redash)やジョブ管理ツール(Rundeck)など、「使い方はわかるがイマイチどう動いているのかワカラン」というシステムのアーキテクチャについても個別にキャッチアップのための質問会を開いてもらうことにしました。
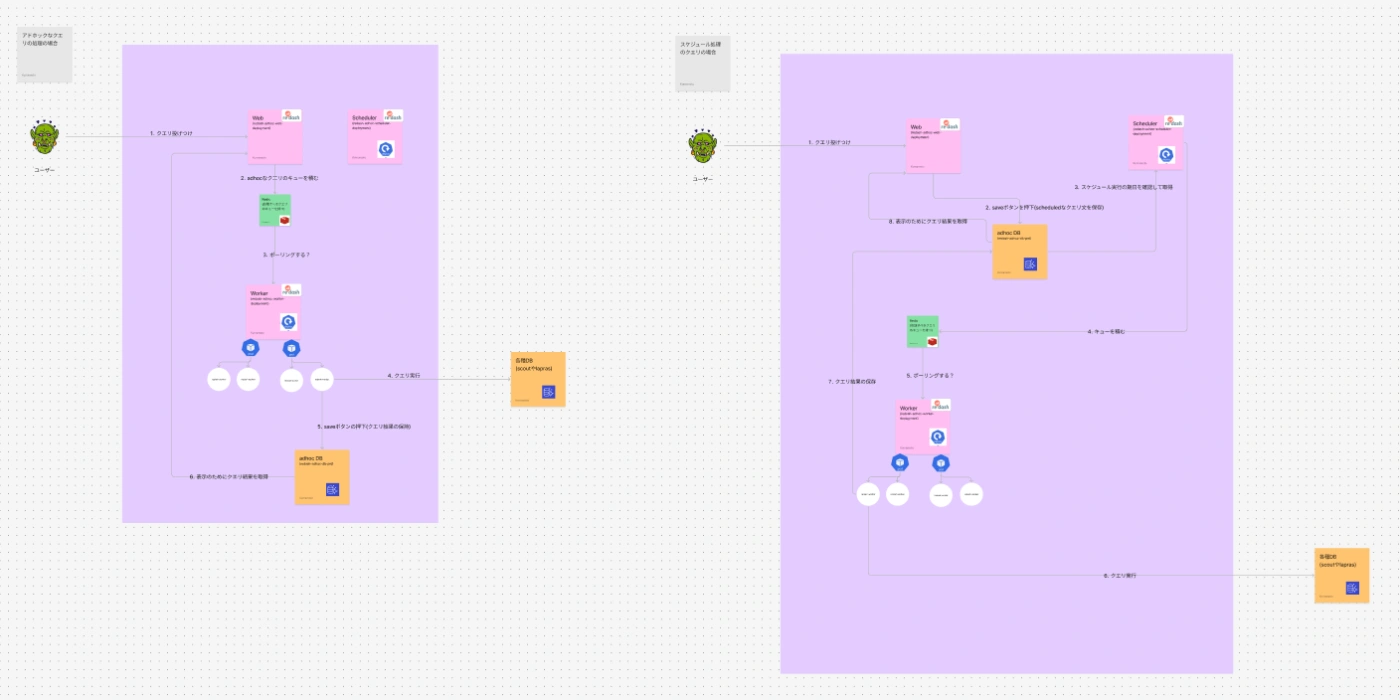
また質問会ではいきなり「正解」を提示してもらうのではなく、Figma上で「たぶんこんな感じの構造になってるんですかね?」という予想を示して適宜、k8sやterraformのコードやAWSの管理コンソールなどを見ながら修正していくというスタイルで進めさせてもらうことにしました。
このやり方は「教える側」が結構疲れる作業だとは思うので、気楽にオススメ出来るわけではないのですが、実際にインフラの概略図を描いていくことでしっかりと現状が頭に入ったので非常に効果的だなと感じています。
※これに限らず、いつも辛抱強く質問に付き合っていただいたnappa さんに感謝🙏
3. チーム参画後にやったタスク
3-1. k8s関連の小さなタスクのアサイン
最初の方は「podに複数のアプリケーションが載っているのをリファクタしたい」などの「急ぎじゃないし、致命的でもない小規模タスク」というまさにGood First Issueなお仕事を振ってもらうことにしました。
このタスクアサインの際にも、「なぜやるのか」「どういう方向に持っていきたいのか」を自分から質問しながら明らかにしていくという「ちょっとしたIssueリファインメント」に付き合ってもらうなどを行うようにしました。
タスクを進める際には、Issueのコメント欄に「書きすぎでは?」というくらいに行動ログを残していく、ということを意識して進めるようにしました。
※普段の業務でも調査ログなどはしっかりと残しているが、いつも以上に行動の『意図』を明確に書くように意識していた
また、こういったタスクをこなす中でSREチームが使っているちょっとしたツールや便利コマンド、お仕事のtipsなどを伝授してもらいました。
3-2. 似たような作業を複数回やる系のタスク
チームに参画してから1ヶ月ほど経ったタイミングで、弊社内で使っているPostgreSQL(以下psql)のメジャーバージョンをアップデートしていく作業を任されることになりました。

psqlは複数ヶ所で使われていることもあり、それだけアプデ作業をこなさなければいけません。
アプデ対象のDBを使っているシステム・サービスごとに気をつけなければいけないことは異なるのですが、作業自体には共通するところが多い=似たような作業を複数回行うものです。
初回のアプデでは、「あっ、CIがテスト回すのに使ってるpsqlのDockerイメージもバージョン変えないと!」といった見落としや「ここのシステム、午前にこんな頻度で使われてるなら、DBのアプデ時間は午後にした方がいいですね」などといったアドバイスを貰いながらの作業となったのですが、徐々に回数をこなす中で「このタスクなら次にやる機会があったらおそらく独力で回していける」という領域になっていきました。
4. 結果
冒頭の「インフラ未経験なエンジニアは2ヶ月でSREになれるのか」という問いに対してですが、「SREとして2ヶ月でしっかり大活躍してます!とは言えないが、一応、SREとして続けていっても大丈夫なんじゃない?」という状態にはあるのでギリギリYesと言って良いのかなと思います。
そこでこのまとめのセクションではSREチームにジョインが一応は成功したことを踏まえて(1)自分がやってよかったこと(2)チームにやってもらえてよかったこと(3)まとめ...の3つを考えていこうと思います。
4-1. 自分主導でやってよかったこと
- 業務内外で自己学習を進める
- アーキテクチャ質問会を開いてもらう
開発チームにいた時は「業務を通じて学習する」ということが可能でした。
ただやはり今まで扱ったことのない分野での仕事となると、それは中々難しく、ペアプロでタスクをこなしていくにしても「一人の時に、どれだけ事前に準備・学習をしておいたか」によって、そのタスクから得られる学びの質が変わってきました。(少なくとも自分の場合は)
またシステムの全体像を理解した上で仕事をするのも、キャッチアップの速度や質を上げるのには重要だと思います。
ただ既存システムのアーキテクチャ把握などは(それまでの開発の歴史的経緯を知らない個人が)一人でコツコツと調査していくのは、どうしても限界があります。(見落とし・勘違いが発生したり、単純に調査時間がかかったりする)
なのでここに関しては既に全体を把握しているメンバーに依頼して、インタラクティブにやり取りしながら、ホワイトボードやFigmaなどのツールを使って学んでいく方が効率的だと感じました。
4-2. チーム主導でやってもらってよかったこと
- とにかくペアプロでタスクに当たる
- Issueごとに小さな振り返りの機会を設ける
- 定期1 on 1 + 期待値を振り返る会の設定
一見、簡単そうに見えたタスクが複数の問題を孕んでいて、「ヤクの毛刈り」的な状態に陥ることはママあるように思います。
そういった時にも「ペアプロ」と「振り返り」をしっかり毎回のタスクごとにしていれば、「これは事前想定よりも大きなタスクだったね」「ここに関する知識を付けると良さそう」など現状と目標とのビハインドをしっかりと自分とペアプロメンバーで相互確認出来ます。
今回の異動はジョブチェンジや転職に近いものだったのにも関わらず、上記のような密なコミュニケーションがあったからこそ、初期から今まで余計な不安やストレスを感じることなく過ごせています。

※定期的に雑談を交えた振り返りするのオススメ
4-3. まとめ
ありきたりではありますが、「キャリアシフトを伴う異動」には
(1)自己学習
(2)受け入れ側との密なコミュニケーション
の両輪が大事そう...というのが今回の学びです。
以上、これからも「まともなSRE」になっていくため精進していきます!押忍!!

Discussion