はじめに
こんにちは、ランサーズでエンジニアをしている岡田です。
さっそくですが「ベクトル検索?なにそれ?」という方に向けて、ローカル環境でベクトルデータベースを試すお手軽セットを用意してみました。
Docker環境で誰でも簡単に作れるので、興味のある方はこれを機に試してみてはいかがでしょうか?
それではpostgresqlの拡張機能でベクトル検索を可能にするpgvectorを使って、ローカルDocker環境にサクッとベクトルデータベースを構築していきましょう!
事前準備
以下のフォルダ構成に従ってファイルを作っていきます。
pgvector_sample/
├─ docker-compose.yml
└─ app/
├─ cruds.py
├─ database.py
├─ models.py
└─ requirements.txt
まずはDockerコンテナを定義
services:
app:
image: python:3.13-slim
container_name: python_app
working_dir: /app
volumes:
- ./app:/app
command: tail -f /dev/null
networks:
- pg_network
pgvector:
image: ankane/pgvector:v0.5.1
container_name: pgvector
environment:
POSTGRES_USER: root
POSTGRES_PASSWORD: password
POSTGRES_DB: pgvector_db
networks:
- pg_network
pgadmin: # おまけでpostgresqlのGUIツールであるpgadminコンテナも作成
image: dpage/pgadmin4:9.7.0
container_name: pgadmin
environment:
PGADMIN_DEFAULT_EMAIL: admin@example.com
PGADMIN_DEFAULT_PASSWORD: password
ports:
- 80:80 # 右側のコンテナ内のポートは固定
networks:
- pg_network
depends_on:
- pgvector
networks:
pg_network:
driver: bridge
次に必要なライブラリを記述
greenlet==3.2.4
numpy==2.3.2
pgvector==0.4.1
psycopg2-binary==2.9.10
SQLAlchemy==2.0.43
typing_extensions==4.15.0
データベース接続の設定ファイル
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
POSTGRES_USER = "root"
POSTGRES_PASSWORD = "password"
POSTGRES_HOST = "pgvector"
POSTGRES_PORT = "5432"
POSTGRES_DB = "pgvector_db"
DATABASE_URL = (
f"postgresql://{POSTGRES_USER}:"
f"{POSTGRES_PASSWORD}@"
f"{POSTGRES_HOST}:"
f"{POSTGRES_PORT}/"
f"{POSTGRES_DB}"
)
engine = create_engine(DATABASE_URL)
SessionLocal = sessionmaker(bind=engine, autocommit=False, autoflush=False)
Base = declarative_base()
テーブル設計
from sqlalchemy import Column, Integer, String, Text
from pgvector.sqlalchemy import Vector
from database import Base, engine
class Document(Base):
__tablename__ = "documents"
id = Column(Integer, primary_key=True, index=True)
title = Column(String(255), nullable=False)
content = Column(Text, nullable=False)
embedding = Column(Vector(768))
# テーブル作成関数(関数実行でテーブル作成する用)
def create_tables():
Base.metadata.create_all(bind=engine)
ベクトル検索するために必要な関数
import numpy as np
from database import SessionLocal
from models import Document
from typing import List
def create_normalized_vector(dimension: int = 768) -> List[float]:
"""正規化されたランダムベクトルを生成"""
vec = np.random.rand(dimension)
return (vec / np.linalg.norm(vec)).tolist()
def add_document(title: str, content: str) -> Document:
"""サンプルドキュメントをDBに追加"""
try:
db = SessionLocal()
doc = Document(
title=title,
content=content,
embedding=create_normalized_vector()
)
db.add(doc)
db.commit()
return doc
except Exception as e:
db.rollback()
print(f"❌ エラーが発生しました: {e}")
return None
finally:
db.close()
def find_similar_documents_cosine(query_embedding: List[float], limit: int = 5) -> List[tuple]:
"""コサイン類似度で類似ドキュメントを検索(類似度も返す)"""
try:
db = SessionLocal()
results = db.query(
Document,
(1 - Document.embedding.cosine_distance(query_embedding)).label('cosine_similarity')
).order_by(
Document.embedding.cosine_distance(query_embedding).asc()
).limit(limit).all()
return results
finally:
db.close()
全部コピペして、フォルダ構成通りに並べれば事前準備は完成です!
(コードの細かい説明が知りたい人は、AIに聞いてみてください。簡単な構成なので、分かりやすく説明してくれると思います。)
構築していく
ルートディレクトリでDocker環境を立ち上げます。
xxx@xxx pgvector_sample % docker compose up -d --build
Dockerコンテナが立ち上がったら、まずはpgvectorコンテナで拡張機能をONにします。
xxx@xxx pgvector_sample % docker exec -it pgvector bash
# psql -U root -d pgvector_db
postgres=# CREATE EXTENSION IF NOT EXISTS vector;
postgres=# SELECT extversion FROM pg_extension WHERE extname = 'vector';
extversion
------------
0.5.1
(1 row)
postgres=# exit
上記のコマンドを実行する、もしくは
docker exec -it pgvector psql -U root -d pgvector_db -c "CREATE EXTENSION IF NOT EXISTS vector;"
でコンテナに入らず実行することもできます。
DBマイグレーションツールを使うのも面倒なので、pythonコンテナで直接テーブルを作成。
xxx@xxx pgvector_sample % docker exec -it python_app bash
root@5ac230a61cce:/app# python
>>> from models import create_tables
>>> create_tables()
テーブルができたら、検索対象となるベクトルを仮で作っておきます。
xxx@xxx pgvector_sample % docker exec -it python_app bash
root@5ac230a61cce:/app# python
>>> from cruds import *
>>> add_document("Document 1", "Content of document 1")
>>> add_document("Document 2", "Content of document 2")
>>> add_document("Document 3", "Content of document 3")
おまけ:pgadminに保存されているベクトルを確認してみましょう
- Dockerコンテナで立ち上げたpgadmin(http://localhost:80)にアクセスする

-
ServersからpgvectorコンテナのDBを登録します

- 登録するサーバーの名前は自由に決めて大丈夫です
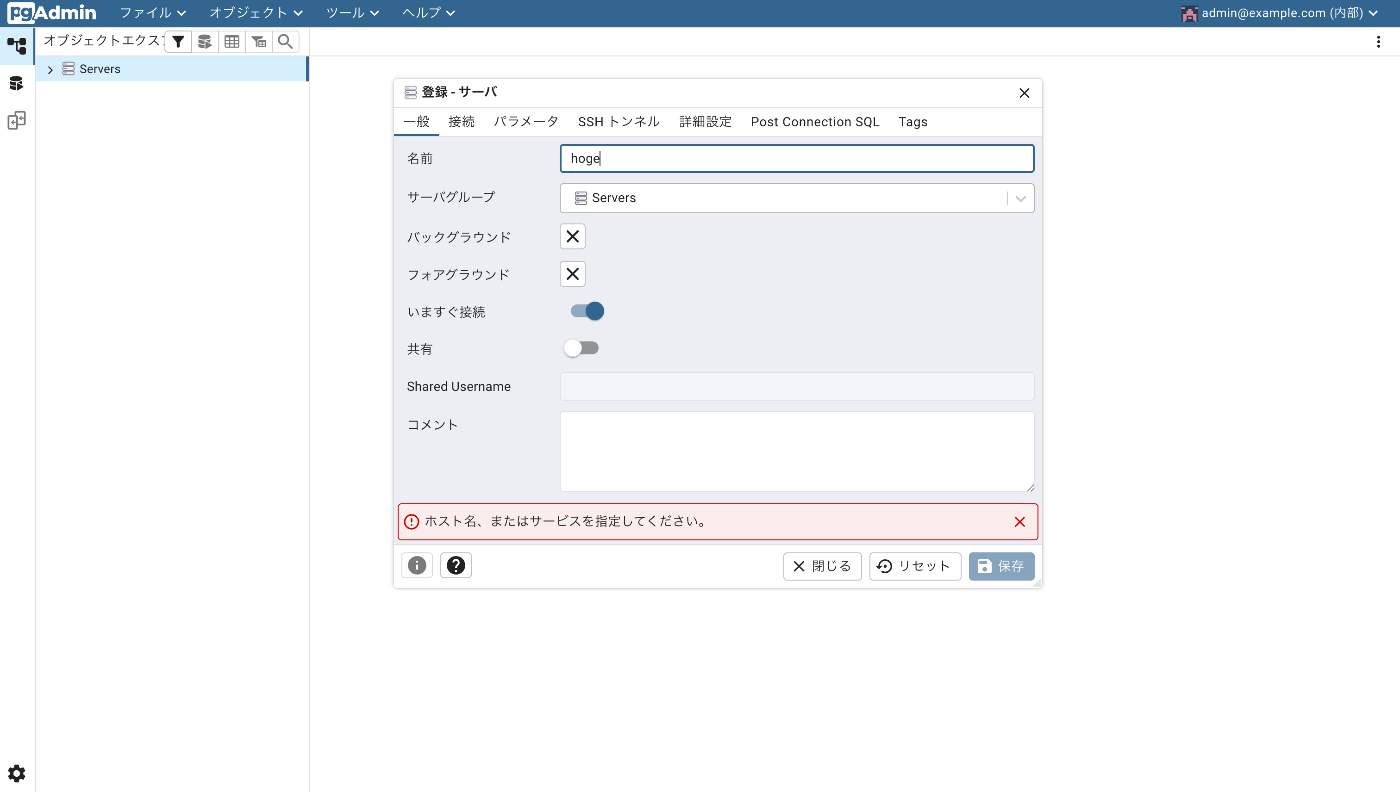
「接続」タブに移動して- ホスト名/アドレス:pgvector(docker-compose.ymlで決めたservice名)
- ポート番号(デフォルトなので5432)
- 管理用データベース:pgvector_db(docker-compose.ymlの環境変数で決めた名前)
- ユーザ名:root(docker-compose.ymlの環境変数で決めた名前)
- パスワード:password(docker-compose.ymlの環境変数で決めた名前)

全て入力したら「保存」ボタンを押して、接続完了です!(接続が成功すると左のバーに登録したサーバー名が表示されます)

- データベースから作成したテーブルを選択した後、左上にある「すべての行」ボタンをクリックするとテーブルに保存されたレコードが確認できます

ベクトル検索
いよいよ本題のベクトル検索をしていきます!
といっても、もうほとんどやることは終わっていて
create_normalized_vector()で検索クエリとなるベクトルを仮で作成して、find_similar_documents_cosine()を使えば、もうベクトル検索の結果が得られます。
>>> query_vec = create_normalized_vector()
>>> results = find_similar_documents_cosine(query_vec, limit=3)
>>> for i, result in enumerate(results, 1):
... doc, similarity = result
... print(f"{i}. {doc.title}: コサイン類似度: {similarity:.4f}")
...
1. Document 1: コサイン類似度: 0.7523
2. Document 2: コサイン類似度: 0.7451
3. Document 3: コサイン類似度: 0.7406
検索クエリのベクトルを変えると、検索結果が変わるのが分かります。
>>> query_vec = create_normalized_vector()
>>> results = find_similar_documents_cosine(query_vec, limit=3)
>>> for i, result in enumerate(results, 1):
... doc, similarity = result
... print(f"{i}. {doc.title}: コサイン類似度: {similarity:.4f}")
...
1. Document 2: コサイン類似度: 0.7606
2. Document 3: コサイン類似度: 0.7527
3. Document 1: コサイン類似度: 0.7458
以上、お手軽ベクトル検索体験でした。
ここまで付き合ってくださった方、ありがとうございます。
お疲れ様でした!
最後に
pgvectorはベクトル検索を除くとpostgresqlなので、ベクトル検索だけでなく、フィルタリングやスコアリングを併用した検索が可能です。
LlamaIndexやLangChainなどのRAG用の実装が提供されているライブラリを使えば、もっと色々な検索もできるでしょう。
なので、色々とカスタマイズして試してみてください。
ローカルのDocker環境なので、誰に迷惑をかけることもなく作って壊して遊んで理解を進められます!
本格的にベクトル検索をやるなら、テキストのベクトル化を提供している外部APIを使うか、オープンソースの機械学習モデルを使ってベクトル化してみると、精度の高い検索結果が出てきます。
(今回はデモなので、ランダムなベクトルが作成されてます)
参考にさせていただいた記事

Discussion