Twitter固有の要素を考慮したスパムフィルターの実装
以下では自分が運用しているトレンド解析システムで使用しているスパムフィルターの実装方法について解説していきます。
スパムフィルターで用いる機械学習
スパムフィルターの実装では機械学習の中でも「教師あり学習」と言われるものを用います。これはラベルと特徴量からなるデータから、どのような特徴を持つものがどのようなラベル(カテゴリ)に当たるかを自動的に学習するものです。
具体的に見ていきましょう。例えばTwitterには以下の様なツイートがあります。
1.眠い……でも起きなきゃ
2.同点から中田の3ランホームラン!
3.[無料でカンタン]に魔法石ゲット♪ ⇒http://xxx.xyz/999
4.相互フォローで繋がれる人募集中です!すぐフォロー返しますのでよろしくお願いします! リツイートもしてほしいな♪ #followme #refollow #followback #相互フォロー #sougo #相互 #フォロー返し #拡散希望 #リフォロー #出会い"
1,2番のような普通のツイートと違って3,4番のようなスパムツイートは「無料」「ゲット 」「相互フォロー」などなんとなく使用されている単語に特徴があることに気づくと思います。この時、1,2番に「スパムでない」とラベルをつけ「眠い」「中田」「ホームラン」などの単語(特徴量)を取り出し、3,4番に「スパムである」とラベルをつけて同じく「無料」「ゲット」「相互フォロー」などの単語(特徴量)を取り出し、そこから「特徴量(今回の場合は単語)からラベル(カテゴリ、今回の場合はスパムかどうか)を判定する」という学習を行わせることを考えます。
形態素解析
まずスパムツイートと普通のツイートでは出現単語にどのような違いがあるかを知らなければいけません。そこで形態素解析というツールを使います。例えばkuromojiでは「寿司が食べたい。」という文を次のように分析してくれます。
寿司 名詞,一般,*,*,*,*,寿司,スシ,スシ
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
食べ 動詞,自立,*,*,一段,連用形,食べる,タベ,タベ
たい 助動詞,*,*,*,特殊・タイ,基本形,たい,タイ,タイ
。 記号,句点,*,*,*,*,。,。,。
このように単語ごとに分割するだけでなく品詞(名詞、動詞などの単語の種類)や読みなども知ることができます。これを使って以下のようにツイートを単語に分割します。
val UNNECESSARY_PATTERN = "<.*?>|\\[\\[.*?\\]\\]|\\[.*?\\]||\\{\\{.*?\\}\\}|\\=\\=.*?\\=\\=|>|<|"|&| |-|\\||\\!|\\*|'|^[\\:\\;\\/\\=]$|;|\\(|\\)|\\/|:"
val URL_PATTERN = "(https?|ftp)(://[-_.!~*\\'()a-zA-Z0-9;/?:@&=+$,%#]+)"
val tokenizer = new Tokenizer.Builder().build
tokenizer.tokenize(text.replaceAll(UNNECESSARY_PATTERN, "").replaceAll(URL_PATTERN, " UURRLL ")).toArray(new Array[Token](0))
//非自立語(「の」「が」「ます」などの単語)を除く
.filter(token => {
val pos = token.getPartOfSpeechLevel1
pos != "記号" && pos != "助動詞" && pos != "助詞"
})
.map(_.getBaseForm)//原型に戻す(例:暑く→暑い)
ワードベクトル
次に単語のインデックス化を行います。例えば「今日 -> 0, 明日 -> 1, 暑い -> 2, 寒い -> 3, 涼しい -> 4」というように番号付けすると「今日寒いんだけど」という文は「今日(0)」と「寒い(3)」という単語が出ているので(1,0,0,1,0)(0番目と3番目が1のベクトル)と表せ、「明日は暑くなるらしい」という文は(0,1,1,0,0)、「寒い、寒すぎる」という文は(0,0,0,2,0)(「寒い(3)」が2回出てくるため)と表せます。
実際には単語はたくさんあるので数万、数十万という単位の次元になりますが、とにかくこうすることで文章という扱いづらいものをベクトルという数学の表現にすることができ、いろいろな処理を行えるようになります。コードは次のとおりです。
val WORD_COUNT_LOWER_THRESHOLD = 5
val wordIndexes = wordArray.map((_, 1)) //(各単語, 1)というtupleにする
.groupMapReduce(_._1)(_._2)(_ + _) //同じkey(単語)のtupleのvalue(上の1)を足し合わせる、すなわち単語の出現数を数える
.filter(_._2 > WORD_COUNT_LOWER_THRESHOLD) //2番目(単語の出現数)が一定数以上のもののみを取り出す
.keys //key, すなわち単語を取り出す
.zipWithIndex //Index化:(0番目の単語,0), (1番目の単語,1), (2番目の単語,2) ...というtupleに変換
.map(x => (x._1, x._2 + 1)) //LIBSVMはIndexは1以上にしなければいけない
.toMap //mapに変換
SVM
データをコンピュータに理解できる形に変換したらいよいよ学習を行います。機械学習は理論としては数学的な難解な部分を含んでいることが多いですが、単に使うだけなら多数のライブラリが用意されてるのでそれにデータを入れるだけで行うことができ、ここではSVMという手法を用います。
「Deep Learningが絵を描いたり文章を書いたりしてる時代にSVMか」という気もしますが国立台湾大学が2022年現在もライブラリの更新を続けており、一部の分野では線形モデルのほうが有効という話もあるので多分大丈夫でしょう。
SVMについてカンタンに説明すると、例えば上記の方法でベクトル化したツイートを空間上に配置したところ、普通のツイートとスパムツイートが次の図のように配置されてたとします。
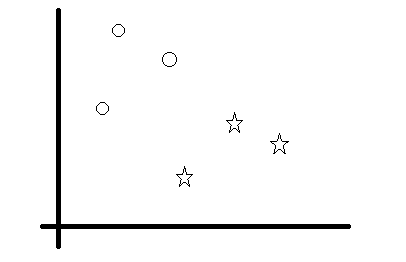
この場合、直感的に下のような直線を引けばベクトルがどちらの側にあるかで分類できるとわかると思います。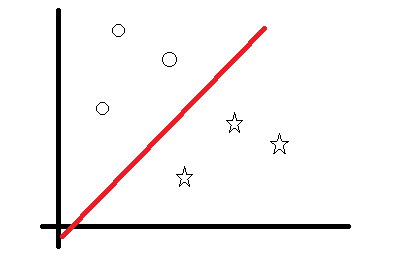
SVMとはこのような直線(正確には超平面)を計算することで分類を行う手法です。
プログラムとしては以下のようにライブラリにデータを入れるだけで使うことができます。
val preparedData = labeledData
.map(x => (if (x._1 == "spam") 1 else 0, convertToVector(x._2, wordIndexes)))
val param = new svm_parameter()
param.svm_type = svm_parameter.C_SVC
param.kernel_type = svm_parameter.RBF
param.gamma = 0.5
param.degree = 3
param.coef0 = 0
param.nu = 0.5
param.cache_size = 20000
param.C = 1
param.eps = 0.001
param.p = 0.1
val svm_problem = new svm_problem()
svm_problem.y = Array.empty //libsvmの関数、Array[Double]でlabelを入力する。
svm_problem.x = Array.empty //libsvmの関数,Array(Array[svm_node])形式でデータ部分を入力する。
var spamNum = 0
var hamNum = 0
var vectorLengthSum = 0.0
preparedData.foreach(data => {
val label = data._1
svm_problem.y = svm_problem.y :+ label
if (label == 1) spamNum = spamNum + 1
else hamNum = hamNum + 1
var inputarray: Array[svm_node] = Array.empty //prob.xに入力する用その2
val vector = data._2.sorted
vectorLengthSum = vectorLengthSum + vector.length
for (wordIndex <- vector) {
val node = new svm_node //prob.xに入力する用
node.index = wordIndex
node.value = 1
inputarray = inputarray :+ node
}
val node = new svm_node
node.index = -1 //prob.xには配列の末のsvm_node.indexに-1を入力しなければならない。
inputarray = inputarray :+ node
svm_problem.l = svm_problem.l + 1 //データ数を入力
svm_problem.x = svm_problem.x :+ inputarray
if (svm_problem.l % 1000 == 0) println("Data processed: " + svm_problem.l)
})
val dataSize = svm_problem.l
println("Data num: %d, spam: %d, ham: %d, spam rate: %.2f".format(dataSize, spamNum, hamNum, spamNum / dataSize.toFloat))
println("Average vector length:" + vectorLengthSum / dataSize)
val model = svm.svm_train(svm_problem, param)
データ収集
コードの説明は以上のとおりですが、実際に機械学習をする場合以下の様な手順を行う必要があります。
- データの収集
- 人手によるラベル付け
- 機械学習
3番めの機械学習は一回プログラムを書けば自動で行ってくれますが、1.2.が通常は人手で行わなければいけないので意外に面倒です。
しかしTwitterの場合その性質によりこの作業をある程度自動化できます。まず、スパムツイートはURLを含んでることが多いですが、例えば楽天のアフェリエイトドメイン(hb.afl.rakuten.co.jp)の場合はほぼ確実にスパムだと判定できます。これ以外にもスパムのみが使うドメインがあるのでそこからスパム判定ができます。また、スパムは「#相互フォロー」のような特徴的な日本語ハッシュタグを使っていることも多いのでそれもスパム判定に使えます。
また、Twitterでは公式クライアント以外から投稿する場合APIを用いる必要がありますが、どのアプリから投稿されたかが記録されるのでそれを元にスパム判定ができます。自分が開発しているトレンド解析システムの副産物でスパムのsourceリストがあるのでそれを用います。
これらを利用したスパムフィルターで少なくとも確実にスパムであるツイートがどれかは判定できるのでそれを用いてラベルづけを行います。もちろんこれだと取りこぼすものもあるのでスパムツイートを普通のツイートと誤ってラベル付してしまう場合もありますが、普通のツイートの方が圧倒的に多いので誤り率はごくわずかになります。
訓練データの更新
スパムツイートも時間とともに少しずつ変化していくことが考えられるので訓練データの更新を行っていく必要がありますが、ここでも手動で行うのではなく自動で行うことを考えます。
val score = spamFilter.calcSpamScore(status)
if (score > 1.0) {
pw.println("spam\t" + SpamTweetCollector.statusToString(status))
}
else if (score < -1.0) {
if (tweetCount % 25 == 0)//スパムでない通常のツイートは数が多いので減らす
pw.println("ham\t" + SpamTweetCollector.statusToString(status))
}
このコードではスコア(上の図で言うと2つのカテゴリを分ける赤い直線からの距離)が大きいものを「ほぼ確実にスパムであるもの」「ほぼ確実に普通のツイートであるもの」と仮定し記録しています。
Twitter固有の要素
APIを使ってツイートする場合そのアプリの名前がsourceに記録されます。スパムの場合「あなたの顔採点」「顔面センター試験」のようないかにもスパムというような名前のsourceでツイートされるため、これもスパム判定の材料に使えます。また、sourceについてはツイート本文と違い「の」などの非自立語も、含まれているかどうかでスパムかどうかの特徴が現れるためこれらも使います。同時に、同じ「あなた」と言う単語でもsourceのものかどうかで重要度が変わるため単語の頭に"source_"と付けます。具体的なコードは以下の様になります。
override def convertToWordArray(text: String, source: String): Array[String] = {
Array.concat({
if (source == null || source == "null") new Array[String](0) else tokenizer.tokenize(source.replaceAll(UNNECESSARY_PATTERN, "")).toArray(new Array[Token](0))
.map("source_" + _.getSurface)
}, {
val hashtags = new Extractor().extractHashtags(text).toArray(new Array[String](0))
for (i <- 0 until hashtags.length) {
hashtags(i) = "hashtag_" + hashtags(i)
}
hashtags
},
tokenizer.tokenize(text.replaceAll(UNNECESSARY_PATTERN, "").replaceAll(URL_PATTERN, " UURRLL ")).toArray(new Array[Token](0))
//非自立語(「の」「が」「ます」などの単語)を除く
.filter(token => {
val pos = token.getPartOfSpeechLevel1
pos != "記号" && pos != "助動詞" && pos != "助詞"
})
.map(_.getBaseForm)
)
}
英語の場合はCoreNLPを用いて以下のようにします。
override def convertToWordArray(text: String, source: String): Array[String] = {
var words = if (source == null || source == "null") Array[String]()
else source.replaceAll(UNNECESSARY_PATTERN, "").split("\\s").map("source_" + _)
val document = pipeline.process(
TwitterTextUtils.removeMentions(text
.replaceAll(UNNECESSARY_PATTERN, "")
.replaceAll(URL_PATTERN, " UURRLL ")
)
)
document.get(classOf[CoreAnnotations.TokensAnnotation]).forEach(token => {
var surface = token.get(classOf[CoreAnnotations.TextAnnotation])
if (surface.startsWith("'")) surface = surface.replaceAll("'", "")
//String pos = token.get(CoreAnnotations.PartOfSpeechAnnotation.class);
if (surface.startsWith("#")) {
val hashTagText = surface.substring(1)
for (w <- EnglishTextAnalyzer.splitCamelCase(hashTagText)) {
if (!StringUtils.isBlank(w)) {
val innerDicForm = EnglishTextAnalyzer.convertToBaseForm(w)
val partOfSpeech = if (!EnglishTextAnalyzer.STOP_WORD_SET.contains(innerDicForm)) PartOfSpeech.Jiritsu
else PartOfSpeech.Fuzoku
if (EnglishTextAnalyzer.isDicTerm(w, innerDicForm, partOfSpeech) && innerDicForm.length > 2) words = words :+ innerDicForm
}
}
}
var dicForm = token.get(classOf[CoreAnnotations.LemmaAnnotation])
val punctuationsMatcher = EnglishTextAnalyzer.PUNCTUATIONS_PATTERN.matcher(dicForm)
dicForm = punctuationsMatcher.replaceAll("").trim
if (!StringUtils.isBlank(dicForm)) {
dicForm = dicForm.toLowerCase
val partOfSpeech = if (!EnglishTextAnalyzer.STOP_WORD_SET.contains(dicForm)) PartOfSpeech.Jiritsu
else PartOfSpeech.Fuzoku
if (EnglishTextAnalyzer.isDicTerm(surface, dicForm, partOfSpeech) && dicForm.length > 2) { // && !TextProcesser.isKigo(surface)
words = words :+ dicForm
}
}
})
words
}
}
ちなみにブラウザ自動操作ツールでも使ってるのか、明らかにスパムでもsourceが"Twitter Web App"になってるものもあるのでsourceだけでスパムか判定するのは難しいです。
他にアカウント名が「toufu」のような普通のものではなく「Q3wz7ot51」のようなランダムな文字列だったらスパム、と判定する方法も考えられますが、現在のTwitter Stream APIではアカウント名は取得できません。
ソースコードはGitHubで公開しています。
スパムフィルターの性能指標
最後にスパムフィルター(一般的にはカテゴリ分類)の性能指標について解説します。性能指標には大きくprecision(正確率)とrecall(再現率)があり、以下の式で計算されます。
precision = (スパムと判定したツイートのうち実際にスパムであった数)/(スパムと判定したツイート数)
recall = (スパムをスパムであると正しく判定できたツイート数)/(スパムツイート全体の数)
なぜ2つ指標があるかというと、例えば楽天のアフェリエイトドメイン(hb.afl.rakuten.co.jp)を含むツイートをスパムと判定するフィルターがあった場合、そこでスパムと判定されたツイートは確実にスパムなので、precision(正確率)はほぼ100%になりますが、当然の事ながらそれ以外のスパムツイートは補足できないのでrecall(スパムツイート全体のうち実際に捕捉できた数)はとても低くなります。
逆にすべてのツイートをスパムと判定するフィルターがあった場合recallは100%になりますが今度はprecisionがとても低くなるので、片方の指標だけではそれが良いスパムフィルターなのか判断できません。そのためこの2つを両方考慮に入れて性能を考えていく必要があります。
Discussion