browser-useメモ
browser-useについて調査する
どういうものか
- ブラウザのデバッグプロトコルを使ってLLMで操作するpythonライブラリ
- Playwright API → Chrome DevTools Protocol (CDP)
- ClaudeのComputer useのスコープを狭めたものと理解できる
- 似たツールとしてMCPのPuppeteerサーバーがある→mcp/puppeteer
- モデル(LLM)の呼び出しにLangChain Modelのインターフェイスに依存することでマルチプロバイダ対応してる
- なのでLangChainで動くモデルに対応してる
- 結果的にLangChain風のAgentフレームワークのミニマムな実装になってる
何ができるの?
ブラウザ操作を自動化してできることはできる
- Hugging Faceで特定のライセンスを持つモデルを検索し、その情報をファイルに保存する
- 求人情報を収集してCSVファイルに保存する
- Google Docsでドキュメントを書き、PDFとして保存する
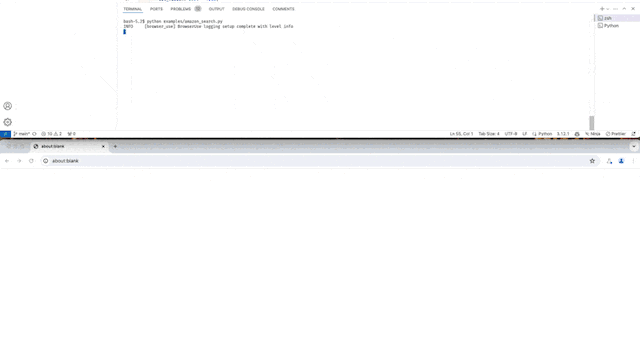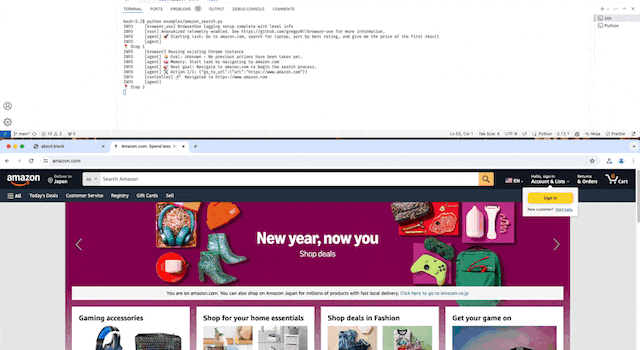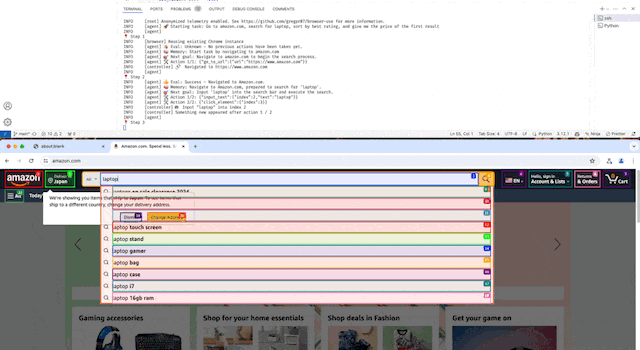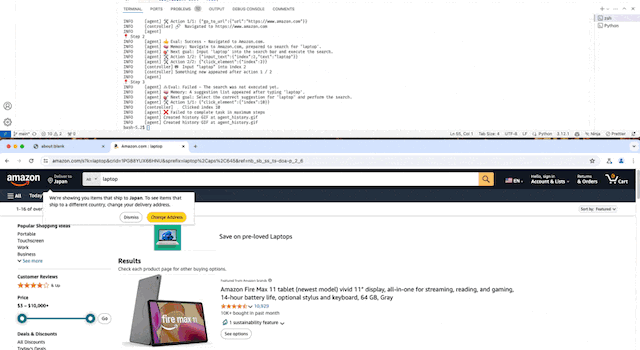
- Amazonで商品を検索して価格を取得する
- Captchaを解く
- Kayakでフライトを検索する
- Wikipediaで情報を検索する
- 複数のタブを開いて情報を比較する
デモ動画(等速)
Chromiumのパスを指定する
起動するブラウザを指定することで任意のプロファイルのセッションを使ったりできる。
-
BrowserConfigクラスを使用する際に、chrome_instance_pathオプションでChromiumのパスを指定できます。このオプションは、Browserクラスの初期化時に設定できます。 -
BrowserConfigは、browser.pyで定義されており、headless(ヘッドレスモードでの実行)、keep_open(スクリプト終了後にブラウザを開いたままにするか)、disable_security(ブラウザのセキュリティ機能を無効にするか)などの他の設定も含まれています。
以下は、chrome_instance_pathを使用してChromiumのパスを指定する例です。
from browser_use.browser.browser import Browser, BrowserConfig
browser = Browser(
config=BrowserConfig(
headless=False,
chrome_instance_path='/Applications/Google Chrome.app/Contents/MacOS/Google Chrome'
)
)
agent = Agent(
task=task,
llm=model,
browser=browser,
)
await agent.run()
この例では、chrome_instance_pathにChromiumの実行可能ファイルのパスを指定しています。
file_upload.py や find_and_apply_to_jobs.py、real_browser.py の例でも、chrome_instance_path オプションが使用されています。これらの例では、macOS環境でGoogle Chromeのパスが指定されていることがわかります。
起動済みのChromeインスタンスに接続する
起動中のChromeインスタンスに接続することができると操作結果の進捗をみながらpythonのREPLでインタラクティブに操作できるので便利
また手動でログインしてその続きを自動でやってもらうなど柔軟に実行範囲を調整できる
- 接続するには、まず既存のChromeインスタンスを
--remote-debugging-portオプション付きで起動する必要があります。例えば、macOSの場合、ターミナルで以下のコマンドを実行します。/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --remote-debugging-port=9222 --no-first-run
このコマンドは、ポート9222 でリモートデバッグを有効にした状態でChromeを起動します。(一度Chromeを修了しておく)
内部実装
-
playwright.async_apiのconnect_over_cdpメソッドを使用 -
次に、
test_attach_chrome.pyに示されているように、connect_over_cdpメソッドを使用して接続from playwright.async_api import async_playwright async def test_full_screen(start_fullscreen: bool, maximize: bool): async with async_playwright() as p: try: print('Attempting to connect to Chrome...') browser = await p.chromium.connect_over_cdp( 'http://localhost:9222', timeout=20000, # 20秒の接続タイムアウト ) print('Connected to Chrome successfully') # ... ここでブラウザ操作を行う ... except Exception as e: print(f"Error connecting to Chrome: {e}")
匿名使用状況データの収集をオフにする
- デフォルトでテレメトリが送信されている
- 匿名使用状況データの収集をオプトアウトするには、環境変数
ANONYMIZED_TELEMETRYをfalseに設定する必要があります。
❯ ANONYMIZED_TELEMETRY=false python ./examples/amazon_search.py
DomService/buildDomTree
- DomServiceがWebページのDOMツリーを解析します。
- buildDomTree.jsをevalしてDOMツリーを構造化します。
- get_clickable_elementsが構造化されたDOMツリーからクリック可能な要素を抽出・フィルタリングします。
- 抽出されたクリック可能な要素には一意のインデックスが付与されます。
- クリック可能な要素の情報はBrowserStateに格納され、エージェントに提供されます。
- エージェントはBrowserStateを参照し、クリック可能な要素の情報を元に、次のアクション(例えば、click_elementアクション)を決定します。
SystemPrompt/プロンプトエンジニアリング
-
システムプロンプト:
SystemPromptクラスを使用して、エージェントの動作を制御するシステムプロンプトを定義します。このプロンプトには、エージェントがタスクをどのように実行すべきかの指示やルールが含まれており、例えば、応答形式、利用可能なアクション、要素の相互作用方法、ナビゲーションとエラー処理、タスク完了条件などが含まれます。important_rules()メソッドをオーバーライドすることで、既存のルールに加えて新しいルールを追加できます。- 例えば、
MySystemPromptクラスでは、タスクに関わらず最初にwikipedia.comを開くというルールを追加しています。 - システムプロンプトには、現在の日時や、利用可能なアクションに関する情報が含まれます。
- システムプロンプトは、エージェントがWebページを分析し、タスクを達成するための行動計画を作成する
- 例えば、
-
入出力構造: エージェントの入出力形式
- 現在のURL
- 利用可能なタブ
- インタラクティブな要素のリスト
- 出力
- 実行するアクションとそのパラメーターを含むJSON形式
カスタムアクション
-
アクション: エージェントは、特定のタスクを実行するためのアクションが定義されている
- これらのアクションは、クリック、テキスト入力、ページコンテンツの抽出、新しいタブを開く、URLに移動するなどのブラウザ操作に関連付けられています。
- カスタムアクションを登録することで、ファイルへの保存、データベースへのプッシュ、通知、ユーザーからの入力を得るなどの追加機能も利用できます。
登録方法
- @controller.registry.action デコレータで登録する
- アクションのパラメータを Pydantic モデルで定義
- requires_browser=True を設定すると、現在のブラウザコンテキストにアクセスできます
Examples
-
clipboard.pyでは、クリップボードへのテキストのコピーやクリップボードからのテキストの貼り付けを行うアクションが定義されています。 -
custom_output.pyでは、タスク完了時に特定の情報を抽出して返すdoneアクションが定義されています。 -
file_upload.pyでは、ファイルのアップロードやファイルダイアログのクローズを行うアクションが定義されています。 -
find_and_apply_to_jobs.pyでは、求人情報をファイルに保存したり、履歴書を読み込んだり、アップロードするアクションが定義されています。 -
save_to_file_hugging_face.pyでは、Hugging Faceから取得したモデル情報をファイルに保存するアクションが定義されています。
タスク完了までの実行回数を制限
- エージェントの実行時にmax_stepsパラメータを使用して、実行する最大ステップ数を設定できます
- デフォルトは100
await agent.run(max_steps=50)
Gemini
モデルをGeminiに変えたら動かなかった
ERROR [agent] ❌ Result failed 5/5 times: │
│ Invalid argument provided to Gemini: 400 * GenerateContentRequest.tools[0].function_declarations[0].parameters.properties[action].items.properties[open_tab].properties: should be non-empty for OBJECT type │
│
既知のバグらしい
buildDomTree.jsだけ持ち出す
buildDomTree.jsは画面の中のどのXPATHが操作できるかというのをブラウザ上にアノテートするスクリプト。
この仕組みとSystemPromptを使って、ページ内のxpathとタグ+要素の組み合わせのセットをモデルに渡すことができる。
スクレイピングコード生成や他のAgentのToolを自作するのに役立ちそうなのでNode.jsから使えるようにした。
所感
- ページ構造をxpathセットに圧縮することでマシンリーダブルでLLMにとってノイズの少ないソースにするというのが根幹のアイデア
- 人間「情報とってきて」
- browser-use「xpathの塊ドバッ」
- LLM「id-1をクリックせよ」
- Playwright「了解」