Zennの全本を全文検索したい
はじめに
Zennのロードマップに本の全文検索はありますが、今のところタイトルやチャプターの一致検索しか対応していません
Zenn Roadmap · zenn-dev/zenn-community
なんとかして全文検索できるようにならないでしょうか?
原稿リポジトリを直接検索
Zennは投稿データをGitHubアカウントと接続することができます。
なので検索したい本の原稿がGitHub公開リポジトリである場合、GitHub上で全文検索することが可能です。

(「Chakra UIの歩き方 & Tips集」のリポジトリを検索している様子)
しかし複数の本を横断して検索することはできませんし、GitHub連携されていない場合や公開リポジトリがない場合この方法も使えません。
今回私は複数の本を横断的に検索したかったため、替りの方法を求めました。
内部APIを使った本文データのクロール
ZennのロードマップによるとAPI提供のスレッドはありますが時期は未定です。
ZennとZennにサインアップする私との間の 利用規約 に従って、サイトデータにアクセスすることでこの問題に対応します。
リバースエンジニアリングの詳細を公開することが目的ではないため情報は伏せますが、サイト内部APIから以下の情報が取得できます
- 本の一覧
- 本の中のチャプター一覧
- チャプターの中のテキスト一覧
このことから「テキスト」に対して検索し、それが含まれている「チャプター」「本」と辿ることで、複数の本を横断的に検索することが理屈上は可能そうです。
しかし一般的に全文検索システムをホストするのはコストがかさみます。なんとかお手軽に構築する方法はないでしょうか?
Google Drive APIを使った検索インデックス
Google Drive APIは保存してあるファイルに対する全文検索機能を提供します
Search for files and folders | Google Drive API | Google Developers
そして各ファイルについてプロパティという key=value 形式のメタデータを付与することができます
Properties | Google Drive API | Google Developers
この2つを組み合わせることで
- チャプターの中のテキストを1ファイルに保存してアップロード
- プロパティに本とチャプターのIDを付与
- Google Drive APIでアップロードして全ファイルを検索
- 検索結果から本とチャプターのIDを取得
というフローを作ることができます。
次項からはJavaScriptを使った具体的なアプリケーション実装を解説します。
Service Accountを発行
https://console.cloud.google.com/iam-admin/iam からファイルのアップロードと検索にGoogle Drive APIへアクセスする用のService Accountを発行します。
次にこのService Accountによって読み書きできるルートフォルダを https://drive.google.com/drive/my-drive から作成します。これを行うのはService Accountではなく、自身のGoogleアカウントです。
このフォルダに対して先程のService AccountのEmailに対して編集権を与えます。

このService Accountのキーを生成してそれをプログラムから使います
Creating and managing service account keys | Cloud IAM Documentation | Google Cloud
Google Driveへのアップロード
Google APIs Node.js Client を利用します。
初期化処理
const {google} = require('googleapis');
const auth = new google.auth.GoogleAuth({
credentials: {
client_email: SERVICE_ACCOUNT_EMAIL,
private_key: `-----BEGIN PRIVATE KEY-----\n${GOOGLE_PRIVATE_KEY}\n-----END PRIVATE KEY-----`,
},
scopes: 'https://www.googleapis.com/auth/drive.file',
});
google.options({auth});
const service = google.drive('v3');
SERVICE_ACCOUNT_EMAIL と GOOGLE_PRIVATE_KEYは先程作成したService AccountのキーのJSONに含まれています。
ディスク上に書き出したJSONからでも組込むことができますが、運用時のことも考えて環境変数秘匿データを入れてインメモリで処理するためにこういう設計にしました。
フォルダ作成関数
今回のシステムではZennの本自体の件数が少ないので影響はないですが、Google Driveの共有フォルダには1フォルダ50万ファイルの制限があります。
Any single folder in Drive which is not in a shared drive can have a maximum of 500,000 items placed within it.
https://support.google.com/a/answer/2490100
なのでこのような自動化ではシャーディングを施すのが安全です。以下の例では本ごとに子フォルダを切りました。
async function createFolder(book) {
const name = book.user.username + '/' + book.slug
const exist = await service.files.list({
q: `name = '${name}' and mimeType = 'application/vnd.google-apps.folder' and '${ROOT_FOLDER_ID}' in parents`,
fields: 'files(id, name)',
})
if (exist.data.files.length > 0) {
await service.files.delete({fileId: exist.data.files[0].id})
}
const bookFolder = await service.files.create({
requestBody: {
name,
mimeType: 'application/vnd.google-apps.folder',
parents: [ROOT_FOLDER_ID],
}
})
return bookFolder.data
}
Google Driveはフォルダ名の重複を許可します。複数回同じ本を保存すると2つのフォルダができてしまうのを防ぐため service.files.delete() で既存のフォルダを削除しておきます。
アップロード関数
const assert = require('assert');
async function upload(folder, book, chapter, order=0) {
assert(chapter.allowed, 'Chapter is not allowed')
assert(chapter.body_html, 'body_html is not defined')
const properties = {
'order': order,
'book': book.title.slice(0, 40),
'username': book.user.username,
'slug': book.slug,
'chapter_title': chapter.title,
'chapter_id': chapter.id,
'chapter_slug': chapter.slug,
'cover_url': book.cover_image_small_url
? book.cover_image_small_url.replace(/^.*(https:\/\/storage.googleapis.com)/, "$1")
: 'https://zenn.dev/images/book.png',
'avatar_url': book.user.avatar_small_url.indexOf('storage.googleapis.com') > -1
? book.user.avatar_small_url.replace(/^.*(https:\/\/storage.googleapis.com)/, "$1")
: ''
}
const description = chapter.body_html.replace(/(<([^>]+)>)/ig, '').slice(0, 4000)
const res = await service.files.create(
{
requestBody: {
mimeType: 'application/vnd.google-apps.document',
parents: [folder.id],
name: book.title + ' - ' + chapter.title,
description,
createdTime: chapter.body_updated_at,
properties,
},
media: {
mimeType: 'text/html',
body: chapter.body_html,
},
}
);
return res.data
}
book.title.slice(0, 40)
book.cover_image_small_url.replace(/.../)
のように文字数をカットしているのは、プロパティにUTF-8 124バイト制限があるためです。
もう1点、descriptionにchapter.body_htmlのHTMLを削除したテキストを入れておくのは検索結果のハイライトをお手軽に実装するためのパスです。ここでも文字数制限のため末尾を削っています……
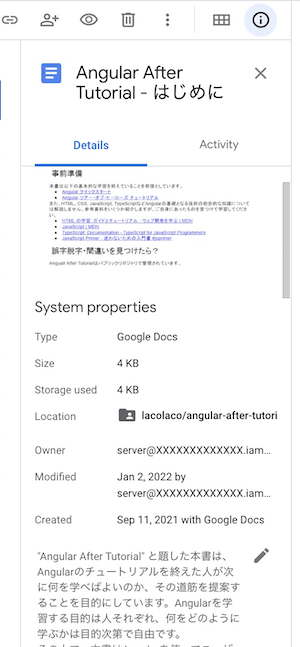
(「Angular After Tutorial」の第一章が保存された様子)
全文検索関数
async function searchFromDrive(input, opts={}) {
const {pageToken, username, slug} = opts
let query = `mimeType = 'application/vnd.google-apps.document' and `
query += `fullText contains '${input}' and `
if (username) {
query += `properties has { key='username' and value='${username}' } and `
}
if (slug) {
query += `properties has { key='slug' and value='${slug}' } and `
}
query += 'trashed = false'
const res = await service.files.list({
q: query,
pageToken,
fields: 'files(id, name, parents, description, properties), nextPageToken',
});
const books = filesToBooks(res.data.files, input)
return {books, nextPageToken: res.data.nextPageToken};
}
ちょっと見慣れない処理ですが、プロパティの構造を駆使した検索クエリを動的に組み立てて目的のファイルまで到達します。クエリの構文は以下にドキュメントがあります。
Search for files and folders | Google Drive API | Google Developers
pageTokenは名前のとうりページング用です。filterToBooks() はアプリケーション固有の整形処理なので省略します。
また、著者ごとの一覧や本のタイトルだけを一致させたい場合はプロパティだけのクエリをかけると実現できます
async function searchBooks(input, opts={}) {
const {pageToken, username} = opts
let query = `mimeType = 'application/vnd.google-apps.document' and `
query += `name contains '${input}' and `
if (username) {
query += `properties has { key='username' and value='${username}' } and `
}
query += 'trashed = false'
const res = await service.files.list({
q: query,
pageToken,
orderBy: 'createdTime',
fields: 'files(id, name, parents, description, properties), nextPageToken',
});
const books = filesToBooks(res.data.files, input)
return {books, nextPageToken: res.data.nextPageToken};
}
フロントエンド作るぞ
今はNode.jsでバックエンド側だけ開発できた状態ですので、今度はこれを使うためのWebアプリインターフェイスを用意することにしました。
とくにこだわりがないのでNext.js+Cloud Functionsで構成してFirebase Hostingにデプロイしました。
Cloud Functions部分
さっき作った検索関数を**firebase-js-sdk**でブラウザから呼び出せるようにします。
const functions = require("firebase-functions");
const {searchBooks, searchChapters} = require("./lib/drive");
exports.search = functions.region('asia-northeast1')
.https
.onCall(async (data, context) => {
const {query, username, slug, pageToken} = data;
const {auth} = context;
functions.logger.info(`search: ${query}`, {auth});
const result = await searchChapters(query, {username, slug, pageToken});
return result;
})
exports.searchBooks = functions.region('asia-northeast1')
.https
.onCall(async (data, context) => {
const {query, username, pageToken} = data;
const {auth} = context;
functions.logger.info(`search: ${query}`, {auth});
const result = await searchBooks(query, {username, pageToken});
return result;
})
本の検索UI

検索が実行されたら先程デプロイしたFunctionを呼び出します。
<form onSubmit={async (event) => {
event.preventDefault()
const search = await callableAPI('searchBooks')
const query = event.target.query.value
const result = await search({query})
setBooks(result.data.books)
}}>
<div className="flex p-2">
<span className="pr-2">🔍</span>
<input
className="pl-2"
type="text" name={`query`} placeholder="Find Books"/>
</div>
</form>
callableAPI() の中身です
import {connectFunctionsEmulator, getFunctions, httpsCallable} from "firebase/functions";
import {initializeFirebaseApp} from "./firebase";
export async function callableAPI(name) {
const app = await initializeFirebaseApp()
const functions = getFunctions(app, 'asia-northeast1')
if (process.env.NEXT_PUBLIC_FUNCTIONS_EMULATOR_HOST) {
connectFunctionsEmulator(functions, process.env.NEXT_PUBLIC_FUNCTIONS_EMULATOR_HOST, process.env.NEXT_PUBLIC_FUNCTIONS_EMULATOR_PORT);
}
return httpsCallable(functions, name)
}
connectFunctionsEmulator() は開発中にlocalhostで実行しているFunctionを呼び出してくれる便利なやつです。
本のチャプターの全文検索
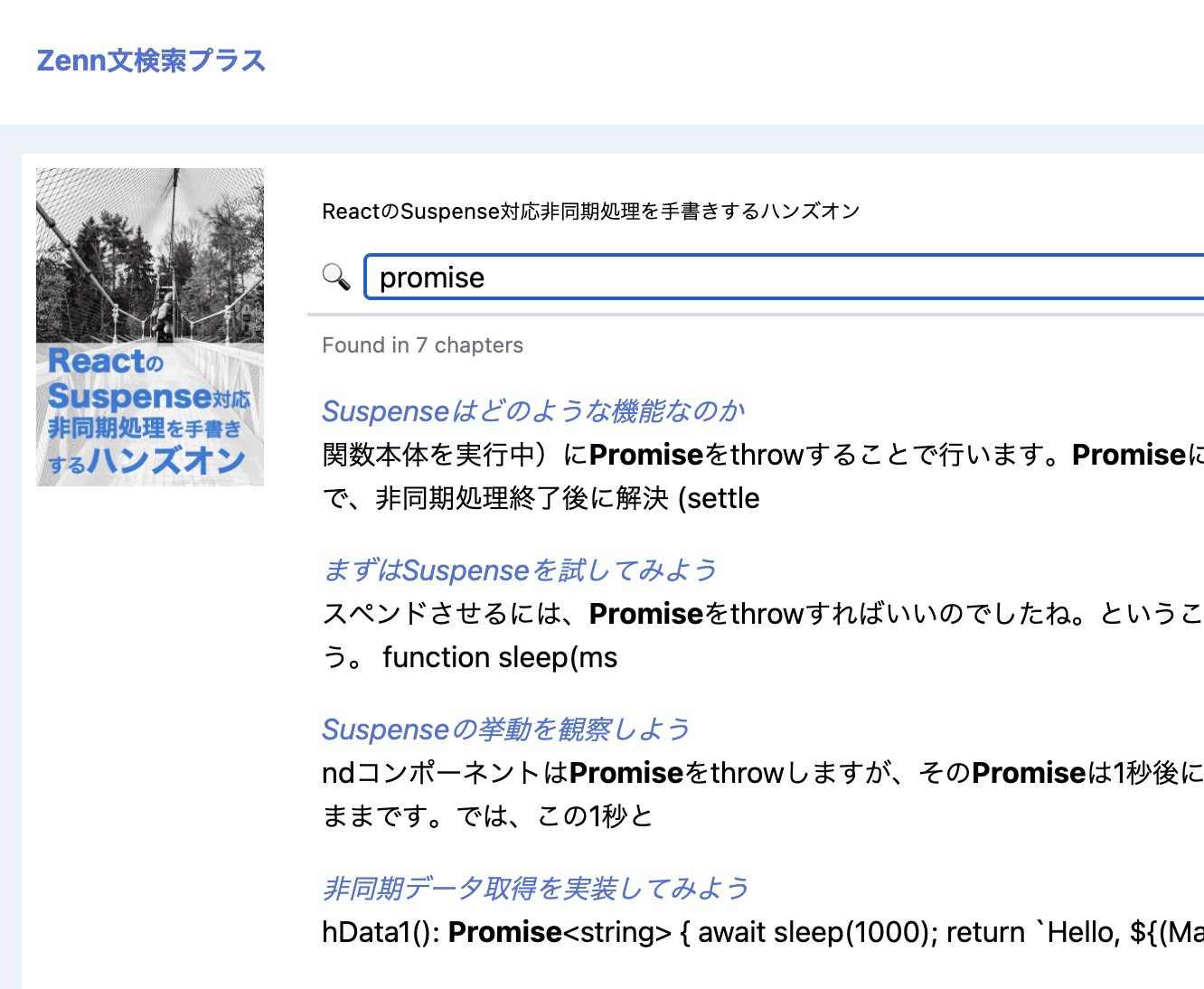
(「ReactのSuspense対応非同期処理を手書きするハンズオン」を”promise” で検索した様子)
ここもCloud Functionsを呼び出しているだけで特別なことはしていないのですが、先程説明した description に一致した結果をboldフォント表示に置き換えてハイライトを表現しています。
// 雑ハイライト処理
const headRegex = new RegExp('(' + input.split(/\s/).shift() + ')', 'igm')
const index = (file.description || ``).search(headRegex)
const description = index > -1
? file.description.slice(index-10, index+90).replace(headRegex, "<strong>$1</strong>")
: (file.description || ``).slice(0, 100)
input.split(/\s/) を通しているのはAND検索に対応しているためです。
以上で「Zennの本を全文検索できるサイト」ができました。このサイトは便利そうなので他の人でも使えるようにできるのでしょうか?
問題点
しかしこのサイトを一般公開する場合、データの更新について短期間に繰替えしクロールし続けないと古い情報が参照されてしまう問題が存在します(一般的なクローラー開発に顕在する問題でもあります)。
例えば「クロール時点で無料公開されていたが、翌日に非公開になった」「本自体が削除された」などがあった時に適切に対応しないといけません。
利用規約で禁止されている「有料コンテンツに支払いなくアクセスする行為」がキャッシュを使った二次配布を通じて第三者に提供されてしまうというリスクがあります。
第4条(禁止事項)
何らかの手段により、本サービス上の有料コンテンツに支払いなくアクセスする行為
https://zenn.dev/terms
これらはすべての本を対象にする必要があるため、遅延なく行うのは難しいですし、「削除申請機能を付ける」「手動で再取得開始できるボタンを付ける」などのオプションが考えられるのですが、どれも問題を迂回するものでしかありません。
そしてZenn内部APIを利用したものなので仕様変更によりクロールは中断される可能性が高いです。
なので私はこのサイトを私的利用の範囲に留めることにしました。
おわりに
Google Drive APIを使うと簡易的な全文検索機能を持つアプリケーションがお手軽に開発できます。
今回クローズドな環境で「Zennの本を全文検索したい」の目的は達成することはできましたが、一般公開して継続的に運用するのは難しいため断念しました。
公式でその機能が提供されるか、Zenn APIが公開されるのを待ちます。
Discussion