1. はじめに: AI活用を阻む「複雑なExcel」の壁
こんにちは、Labdemyで長期インターンをしているガルシアです!
インターン業務の一環で、「社内に散在するExcelファイルからAIが利用可能なナレッジベースを構築する」という課題に取り組む機会があり、その過程で得られた知見を共有したいと思います。
この課題に取り組む上で、特に大きな壁となったのが、ビジネス現場で多用される「複雑なExcelファイル」の解析でした。AIアプリケーション(RAGなど)の精度は、データソースの前処理品質に大きく左右されます。特にビジネス現場で多用されるExcelファイルは、情報の宝庫であると同時に、その複雑な構造からナレッジベース化における大きな壁となりがちです。
例えば、以下のような帳票を例に見てみましょう。
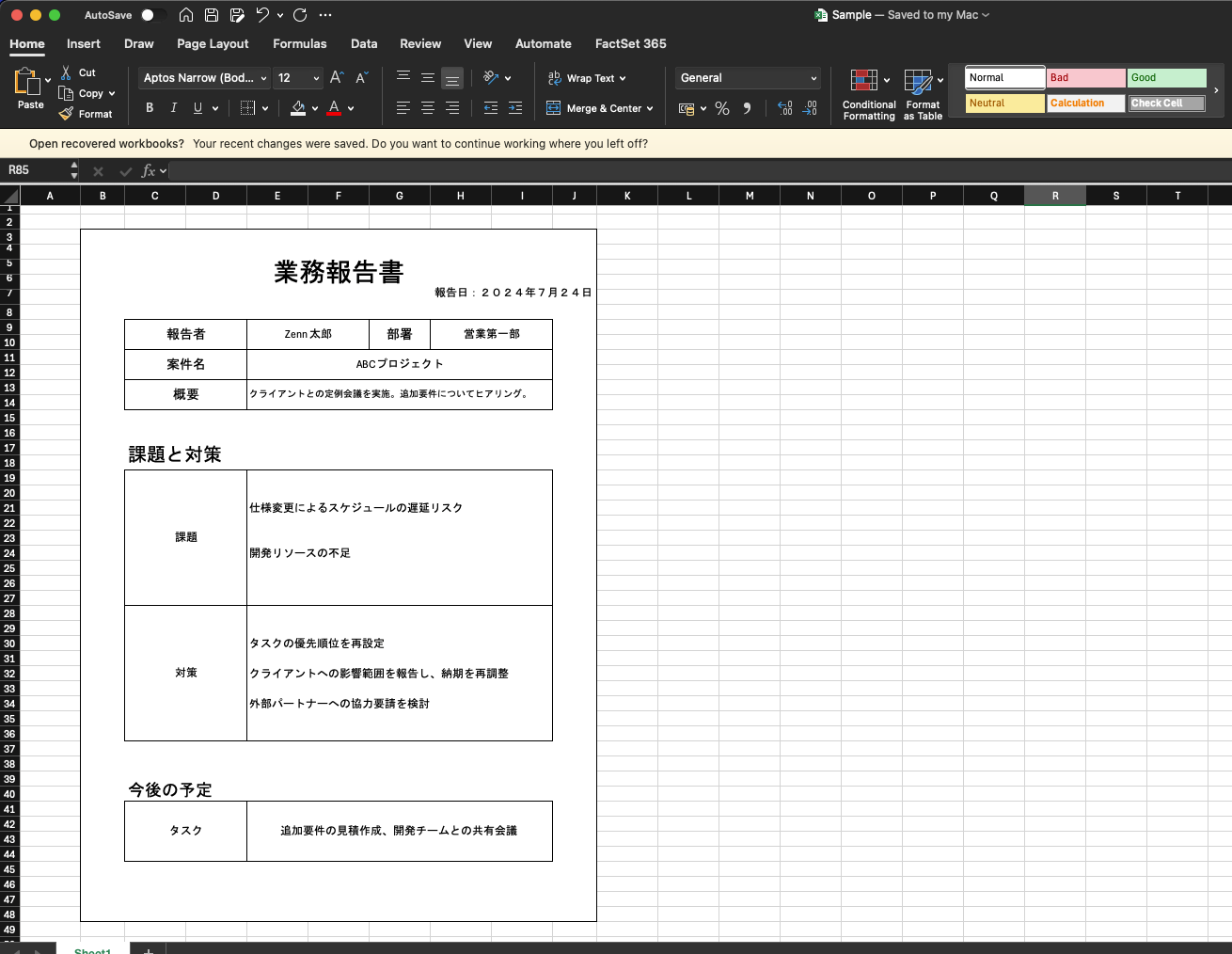
このExcelファイルの何が問題なのか?
この帳票は人間にとっては非常に見やすいですが、プログラムで解析するには以下の様な課題を抱えています。
-
多用されるセル結合: 「業務報告書」というタイトルや「課題と対策」といった見出しが複数のセルにまたがっています。これにより、どのセルがどのデータに対応するのかを機械的に判断することが困難になります。
-
複雑なレイアウト: 「課題と対策」セクションのように、大見出し(課題と対策)の下に、さらに小見出し(課題、対策)が配置される階層構造になっています。このため、どのデータがどの見出しに対応するのかを単純なプログラムで正しく紐付けることが困難です。
-
視覚的なグルーピング: 罫線や空白行によって情報のまとまりが表現されていますが、これらの視覚的な情報は通常のライブラリでは無視されてしまいます。
この記事では、この課題を解決するために、AI文書解析ライブラリ「Docling」がいかに有効であるか、その技術的な背景と具体的な活用法を解説します。
2. Doclingとは何か? - AI/OCRを活用した高精度コンバーター
Doclingは、PDF、Word、Excelといった多様なドキュメント形式を解析し、AIアプリケーション(特にRAG)で活用しやすいように変換するためのオープンソースライブラリです。
その最大の特徴は、単にテキストを抽出するだけでなく、AIとOCR(光学式文字認識)技術を駆使して文書の視覚的なレイアウトや論理構造を理解し、それを保持したまま変換する点にあります。
-
レイアウト解析: Doclingは、セルの位置や大きさ、罫線、結合情報などを総合的に分析し、人間が目で見るのと同じようにテーブルやセクションの構造を認識します。
-
高精度なデータ抽出: 組み込まれたAI/OCRエンジンにより、PDFやスキャンされた画像であっても、テーブル、フォーム、キーバリューペア(KVP)を正確に情報抽出できます。
-
構造化された出力: 解析結果を、視覚構造を忠実に再現したHTMLや、JSON、CSVといった構造化データとして出力します。
Doclingは「人間が作成した視覚的なドキュメント」と「プログラム(特にLLM)が解釈しやすい構造化データ」との間の高性能な翻訳機として機能します。HTMLへの変換は、その強力な機能の一つであり、特にWebページの構造に慣れ親しんだLLMにとって、最も文脈を理解しやすい形式の一つと言えるでしょう。
3. 実装: DoclingによるExcelからHTMLへの変換
Doclingの基本的な使い方は非常にシンプルです。DocumentConverterクラスを利用して数行で変換が完了します。
from docling.document_converter import DocumentConverter
def convert_excel_to_html(file_path: str) -> str:
"""Doclingを使用してExcelファイルをHTMLに変換する"""
converter = DocumentConverter()
result = converter.convert(file_path)
# 変換結果からHTMLコンテンツを返す
return result.document.export_to_html()
この関数によって、複雑なExcelファイルは、そのレイアウト構造を保持した単一のHTML文字列に変換されます。
実際に、先ほどの帳票ExcelファイルをDoclingでHTMLに変換し、ブラウザで表示すると以下のようになります。元のExcelのレイアウトが忠実に再現されていることがわかります。

HTML
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Sample</title>
<meta name="generator" content="Docling HTML Serializer">
<style>
html {
background-color: #f5f5f5;
font-family: Arial, sans-serif;
line-height: 1.6;
}
body {
max-width: 800px;
margin: 0 auto;
padding: 2rem;
background-color: white;
box-shadow: 0 0 10px rgba(0,0,0,0.1);
}
h1, h2, h3, h4, h5, h6 {
color: #333;
margin-top: 1.5em;
margin-bottom: 0.5em;
}
h1 {
font-size: 2em;
border-bottom: 1px solid #eee;
padding-bottom: 0.3em;
}
table {
border-collapse: collapse;
margin: 1em 0;
width: 100%;
}
th, td {
border: 1px solid #ddd;
padding: 8px;
text-align: left;
}
th {
background-color: #f2f2f2;
font-weight: bold;
}
figure {
margin: 1.5em 0;
text-align: center;
}
figcaption {
color: #666;
font-style: italic;
margin-top: 0.5em;
}
img {
max-width: 100%;
height: auto;
}
pre {
background-color: #f6f8fa;
border-radius: 3px;
padding: 1em;
overflow: auto;
}
code {
font-family: monospace;
background-color: #f6f8fa;
padding: 0.2em 0.4em;
border-radius: 3px;
}
pre code {
background-color: transparent;
padding: 0;
}
.formula {
text-align: center;
padding: 0.5em;
margin: 1em 0;
background-color: #f9f9f9;
}
.formula-not-decoded {
text-align: center;
padding: 0.5em;
margin: 1em 0;
background: repeating-linear-gradient(
45deg,
#f0f0f0,
#f0f0f0 10px,
#f9f9f9 10px,
#f9f9f9 20px
);
}
.page-break {
page-break-after: always;
border-top: 1px dashed #ccc;
margin: 2em 0;
}
.key-value-region {
background-color: #f9f9f9;
padding: 1em;
border-radius: 4px;
margin: 1em 0;
}
.key-value-region dt {
font-weight: bold;
}
.key-value-region dd {
margin-left: 1em;
margin-bottom: 0.5em;
}
.form-container {
border: 1px solid #ddd;
padding: 1em;
border-radius: 4px;
margin: 1em 0;
}
.form-item {
margin-bottom: 0.5em;
}
.image-classification {
font-size: 0.9em;
color: #666;
margin-top: 0.5em;
}
</style>
</head>
<body>
<div class='page'>
<table><tbody><tr><th rowspan="3" colspan="3">業務報告書</th></tr><tr></tr><tr></tr></tbody></table>
<table><tbody><tr><th rowspan="2" colspan="3">報告日:2024年7月24日</th></tr><tr></tr></tbody></table>
<table><tbody><tr><th rowspan="2" colspan="2">報告者</th><th rowspan="2" colspan="2">Zenn 太郎</th><th rowspan="2">部署</th><th rowspan="2" colspan="2">営業第一部</th></tr><tr></tr><tr><td rowspan="2" colspan="2">案件名</td><td rowspan="2" colspan="5">ABCプロジェクト</td></tr><tr></tr><tr><td rowspan="2" colspan="2">概要</td><td rowspan="2" colspan="5">クライアントとの定例会議を実施。追加要件についてヒアリング。</td></tr><tr></tr></tbody></table>
<table><tbody><tr><th rowspan="2" colspan="3">課題と対策</th></tr><tr></tr><tr><td rowspan="9" colspan="2">課題</td><td rowspan="3" colspan="5">仕様変更によるスケジュールの遅延リスク</td></tr><tr></tr><tr></tr><tr><td>None</td></tr><tr><td rowspan="2" colspan="5">開発リソースの不足</td></tr><tr></tr><tr><td>None</td></tr><tr><td>None</td></tr><tr><td>None</td></tr><tr><td rowspan="9" colspan="2">対策</td><td>None</td></tr><tr><td rowspan="2" colspan="5">タスクの優先順位を再設定</td></tr><tr></tr><tr><td rowspan="2" colspan="5">クライアントへの影響範囲を報告し、納期を再調整</td></tr><tr></tr><tr><td rowspan="2" colspan="5">外部パートナーへの協力要請を検討</td></tr><tr></tr><tr><td>None</td></tr><tr><td>None</td></tr></tbody></table>
<table><tbody><tr><th rowspan="2" colspan="3">今後の予定</th></tr><tr></tr><tr><td rowspan="4" colspan="2">タスク</td><td rowspan="4" colspan="5">追加要件の見積作成、開発チームとの共有会議</td></tr><tr></tr><tr></tr><tr></tr></tbody></table>
</div>
</body>
</html>
4. HTMLをLLMで構造化する
Doclingで生成されたHTMLは、情報抽出ステップで効果を発揮します。
Step 1: LLMのためのHTML前処理(軽量化)
Doclingが出力するHTMLには、罫線やフォントの色などを定義する<style>タグが含まれています。これはブラウザでの表示には有用ですが、LLMに構造とテキスト内容を渡すのが目的の場合、ノイズとなり、余計なトークン(APIコスト)を消費してしまいます。
そこで、LLMに渡す直前にBeautifulSoupを使い、これらの不要なタグを除去する一手間を加えることを強く推奨します。
from bs4 import BeautifulSoup
def clean_html_for_llm(html_content: str) -> str:
"""LLMへの入力用に、HTMLから不要なタグ(style, script)を削除する"""
soup = BeautifulSoup(html_content, 'html.parser')
# styleタグをすべて検索して削除
for s in soup.select('style'):
s.decompose()
# scriptタグも通常は不要なため削除
for s in soup.select('script'):
s.decompose()
return str(soup)
この処理により、APIコストを削減し、LLMがより重要な構造タグに集中できるため、抽出精度の向上が期待できます。
Step 2: LLMによる構造化データ抽出
次に、軽量化したクリーンなHTMLをLLM(例: Gemini)に渡し、情報を構造化します。
from google import genai
# APIキーを設定(実際にご自身のキーを設定してください)
# genai.configure(api_key="YOUR_API_KEY")
client = genai.Client()
# ① DoclingでExcelをHTMLに変換し、軽量化
html_from_docling = convert_excel_to_html("path/to/your/excel.xlsx")
cleaned_html = clean_html_for_llm(html_from_docling)
# ② LLMにHTMLを解釈させ、構造化データを抽出
prompt = f"""
以下のHTMLコンテンツは、Excel帳票を変換したものです。
このHTMLのテーブル構造を解釈し、報告書の内容をJSON形式でまとめてください。
JSON以外の説明文は不要です。
HTMLコンテンツ:
{cleaned_html}
"""
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=prompt
)
print(response.text)
このパイプラインを実行すると、LLMはHTMLの構造を正確に解釈し、以下のようなJSON形式の文字列を返します。
```json
{
"タイトル": "業務報告書",
"報告日": "2024年7月24日",
"基本情報": {
"報告者": "Zenn 太郎",
"部署": "営業第一部",
"案件名": "ABCプロジェクト",
"概要": "クライアントとの定例会議を実施。追加要件についてヒアリング。"
},
"課題と対策": {
"課題": [
"仕様変更によるスケジュールの遅延リスク",
"開発リソースの不足"
],
"対策": [
"タスクの優先順位を再設定",
"クライアントへの影響範囲を報告し、納期を再調整",
"外部パートナーへの協力要請を検討"
]
},
"今後の予定": {
"タスク": "追加要件の見積作成、開発チームとの共有会議"
}
}
```
5. まとめ
複雑なExcelファイルをAIで活用する上で、Doclingは以下の点で強力なソリューションとなります。
- 構造の維持: セル結合や複雑なレイアウトを持つExcelの視覚的構造を、LLMが解釈可能なHTML形式で忠実に保持する。
- 前処理の簡素化: 結合情報を手動で解析するような複雑な前処理ロジックを実装する必要がない。
- 高精度な情報抽出: 構造化されたHTMLは、続くLLMによるJSONへの変換タスクの精度を大幅に向上させる。
Pandasやその他のライブラリでExcelファイルの解析に苦戦している場合、Doclingを導入することで、AIアプリケーションの前処理パイプラインを大幅に改善・簡素化できる可能性があります。
この記事が、同じような課題に直面している方々の参考になれば幸いです!

Discussion