はじめに
Domain Modeling Made Functional: Tackle Software Complexity with Domain-Driven Design and F# を読んだので、気になったことをまとめます。
私の DDD の知識と経験は趣味プロダクトで素振りしてみた程度、関数型プログラミングは勉強中という感じなので、間違った解釈をしているかもしれませんがご容赦を。
本書は F#で記載されていますが、自分のメモでは TypeScript に翻訳してサンプルコードを書いています。
肝心の関数型プログラミングのテクニックを駆使してパイプラインを作っていくアプローチについては自分なりに理解できたので、この記事ではあまり触れていません。興味がある方は、ぜひ本書を読んでみてください。
⇨ 祝!翻訳書が発売されました!
関数型ドメインモデリング
Part1 Understanding the Domain
ビジネス・イベントを通してドメインを理解する
データ構造よりもビジネス・イベントに注目し、イベントストーミングを使ってドメインを発見することが書かれていました。
例として受注システムを題材にどのようにモデリングを進めるか具体的に記載されていてわかりやすかったです。
ここでは本書で使用される用語について解説されていました。
- ワークフロー: ビジネスプロセスの一部を詳細に記述したもの。
- コマンド: 命令形で記述される。ドメインイベントを発生させる。Command: “Place an order”
- ドメインイベント: 変更できない記録。常に過去形で記述される。ビジネスプロセスの起点となる。Domain Event: “Order placed"
ざっくり言うと、ワークフローは関数で、引数がコマンドで、返り値がドメインイベントという感じですかね。
type Workflow = Command -> DomainEvent
まずは全体像を掴んでコンテキストを理解し、ドメイン分割を進める。そのためにイベントストーミングを使うというのは良いアプローチだなと思いました。
後の章では特定のワークフローを掘り下げる流れが紹介されています。
データベース駆動設計の衝動と戦う
ステークホルダーにヒアリングしながらワークフローを掘り下げる際に、データベース駆動設計への衝動に抗うことが書かれていました。
DDD ではデータベース内のデータ表現を気にすることなく、ドメインをモデリングすることに集中するべきだということですね。
理由として常にデータベースの視点から設計していると、データモデルに合わせて設計を歪めてしまうことが挙げられていました。
ただ、データモデルを考えるタイミングで隠れていたイベントが見つかることがあるので、その場合はドメインモデルを見直す必要があるかもしれません。個人的にはドメインモデルとデータモデルは業務に関する気づきを相互に得られるので、どちらかを先に考えるというよりは並行して考えるのが良いと思っています。
※この場合のイベントはイミュータブルデータモデルにおけるイベントのことを指しています。
クラス駆動設計の衝動と戦う
ステークホルダーにヒアリングしながらワークフローを掘り下げる際に、クラス駆動設計への衝動に抗うことが書かれていました。
理由として現実世界には存在しない人工的なクラスを作成してしまう懸念が挙げられていました。
おそらくクラス駆動設計とは、開発者による技術的な考えをドメインモデルに反映させてしまうことを指しているのだと思います。
業務で使用されない独自用語を作成してコードに持ち込むと理解が難しくなるというのはわかる気がします。
ドメインの文書化
シンプルなテキストベースの言語を使ってドメインを文書化することが書かれていました。
利点としてドメイン・エキスパートに見せて一緒に作業することができるということが挙げられていました。
業務の流れをヒアリングする際に自然言語で時系列で可視化してはいましたが、このような形式で文書化すると設計に必要な情報がまとめられていて効率が良さそうです。
// ワークフロー
コンテキスト境界: Order-Taking(受注)
ワークフロー: "Place order"(注文する)
トリガー:
"Order form received" event (受注イベント)
主要引数:
An order form (注文フォーム)
他引数:
Product catalog (商品カタログ)
出力イベント:
"Order Placed" event (注文完了イベント)
副作用:
An acknowledgment is sent to the customer (顧客に確認が送信される)
along with the placed order (注文完了イベントと一緒に)
// データ構造
bounded context: Order-Taking
data Order =
CustomerInfo
AND ShippingAddress
AND BillingAddress
AND list of OrderLines
AND AmountToBill
data OrderLine =
Product
AND Quantity
AND Price
data CustomerInfo = ???
data BillingAddress = ???
上記の"Place order"(注文する)の内部の処理をステップごとに分解していくと、例えば以下のように表現できます。
workflow "Place Order" =
input: OrderForm
output:
OrderPlaced event (put on a pile to send to other teams)
OR InvalidOrder (put on appropriate pile)
// step 1
do ValidateOrder
If order is invalid then:
add InvalidOrder to pile
stop
// step 2
do PriceOrder
// step 3
do SendAcknowledgmentToCustomer
// step 4
return OrderPlaced event (if no errors)
境界コンテキスト内の構造
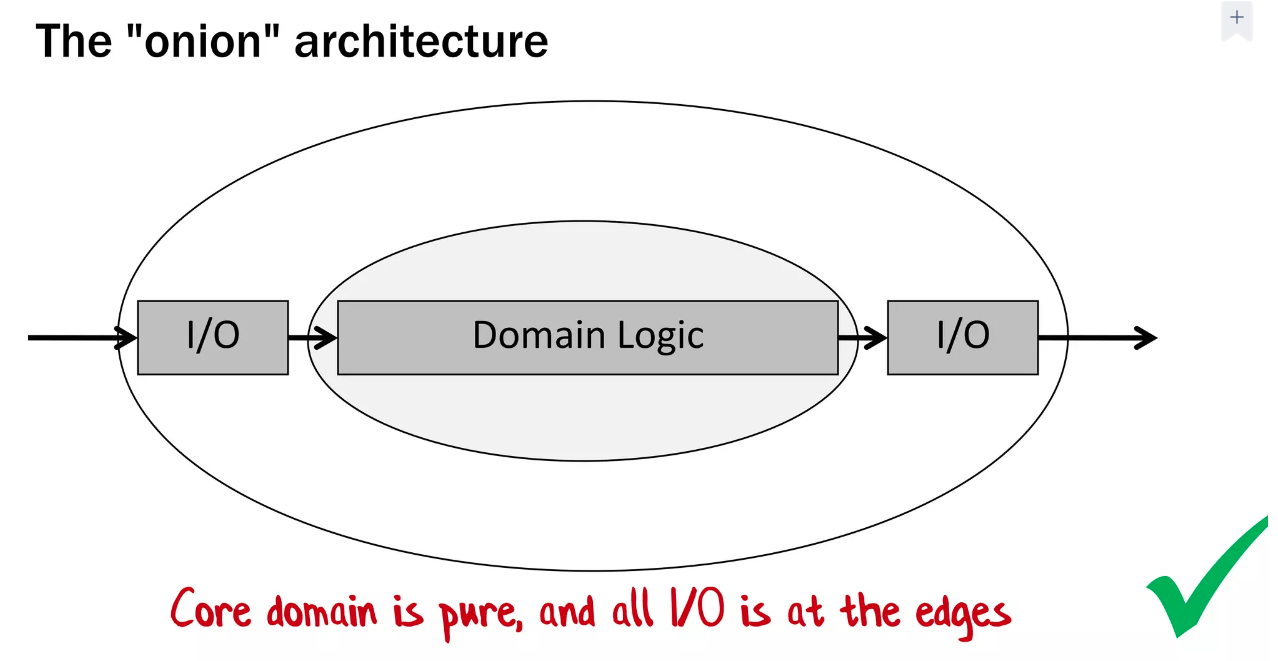
ドメインロジックを中心においたオニオンアーキテクチャが提示されていました。
関数は明示的な依存関係を持ち、副作用を避ける。具体的にはデータベースやファイルシステムを読み書きする関数はコアドメインでは避けようとのことでした。
これについては関数型の DDD に限った話ではないですね。
Part2 Modeling the Domain
型によるドメインモデリング
F#の型システムを使って、ドメインモデルを表現しつつ、ドメインエキスパートや開発者以外でも読んで理解できるようにすることが書かれていました。
たしかに開発者以外でも理解しやすそうです。個人的には文章だけだと流れが掴みづらい気がするので、処理の流れは図化した方が全体を踏まえて理解してもらいやすいと思いました。
プリミティブな値をラッパーした単純型や AND や OR を使用した複雑な型の作り方が紹介されていました。ここは言語によって実装方法が異なる部分だと思います。
バリューオブジェクト,エンティティ,集約についても紹介されており、これら DDD の基本的な概念は関数型でも変わらないということがわかりました。
ドメインにおける整合性と一貫性
型システムを使ってビジネスルールを文書化する方法について具体例が記載されていました。
例えば、下記のようなビジネスルールがあるとします。
- 検証メールは、検証されていないメールアドレスにのみ送信する必要がある(既存顧客へのスパムを避けるため)
- パスワードリセットのメールは、確認済みのメールアドレスにのみ送信する(セキュリティ侵害を防ぐため)
上記を表現する際にこのようにコードを書くかもしれません。
type CustomerEmail = {
emailAddress : EmailAddress
isVerified : boolean
}
ただ、isVerified を変更するルールがコード上から読み取りづらいです。
また、開発者が誤って未検証のメールアドレスでも isVerified を true にしてしまう可能性もあります。
より良いアプローチとして、ドメインエキスパートが未検証と検証済みのメールアドレスを別々の概念として捉えている場合、それぞれ別の型として表現することが挙げられていました。
type CustomerEmail = UnverifiedEmailAddress | VerifiedEmailAddress
このようにすることで、2 つの異なる型があり、それぞれ異なる振る舞いがあることがわかりやすくなりました。
下記のようなワークフローでは検証済みのメールアドレスのみ受け付けることが型によって表現されているため、開発者が誤って未検証のメールアドレスを渡すことを防ぎやすくなりました。
type SendPasswordResetEmail = (verifiedEmailAddress: VerifiedEmailAddress) => ...
ただ、TypeScript の場合は構造的部分型を採用しているため、シグネチャが同じだとエラーになりません。UnverifiedEmailAddress と VerifiedEmailAddress のデータの構造が同じだった場合は一工夫必要になります。
例えば、下記のように discriminated unionを使って判別可能な型を作成することができます。
type EmailAddress = string; // 本来はEmailアドレスのバリューオブジェクトを作成するべきですが、簡略化のためにstring型を使用します。
type UnverifiedEmailAddress = {
kind: "unverified";
email: EmailAddress;
};
type VerifiedEmailAddress = {
kind: "verified";
email: EmailAddress;
};
function createUnverifiedEmailAddress(email: EmailAddress): UnverifiedEmailAddress {
return {
kind: "unverified",
email: email
};
}
function createVerifiedEmailAddress(unverifiedEmailAddress: UnverifiedEmailAddress): VerifiedEmailAddress {
// 実際にはメールアドレスを検証するロジックがここに必要です。
return {
kind: "verified",
email: unverifiedEmailAddress.email
};
}
// 使用例
const unverifiedEmail = createUnverifiedEmailAddress("test@example.com");
const verifiedEmail = createVerifiedEmailAddress(unverifiedEmail);
この振る舞いによって型を分けるというアプローチは関数型特有のものではなさそうです。
個人的にぜひ採用したいアプローチではあるのですが、I/O の境界ではプリミティブな値になるため、ドメインオブジェクトへの変換処理が必要になります。
振る舞いが異なる状態が 1 つであれば変換処理は簡単ですが、状態が増えていくと掛け合わせに伴い複雑になりそうです。
ここは実際にコードを書いてみないとわからないところだと思うので、また別の機会に素振りした際の所感を書こうと思います。
ワークフローをパイプラインとしてモデル化する
ビジネスプロセスは一連の小さな "パイプ"から構築され、それぞれの小さなパイプが 1 つの変換を行い 、小さなパイプを接着して大きなパイプラインを作ります。
関数型プログラミングの原則に従って、パイプラインの各ステップがステートレスで副作用がないように設計するべきと書かれていました。
ワークフローへの入力
ワークフローへの入力は 常に DTO からシリアライズされたドメインオブジェクトである必要があると書かれていました。
例えば Web アプリケーションの場合、Controller でリクエスト情報を受け取ることもありますが、その型はドメインオブジェクトではないのでワークフローに渡す前にドメインオブジェクトに変換する必要がある感じしょうか
const Controller = (req: Request) => {
// 必要に応じてリクエストに対するバリデーションを行う
...
// reqをドメインオブジェクトに変換する
const unvalidatedOrder = parseUnvalidatedOrder(req)
// ワークフローを呼び出す
const result = workflow(unvalidatedOrder)
...
}
また、ワークフローの本当の入力はリクエストを処理するために必要なものを全て含んだコマンドとも書かれていました。
type PlaceOrder = {
orderForm: UnvalidatedOrder // ドメインオブジェクト
timeStamp: DateTime
userId: string
}
const Controller = (req: Request) => {
// 必要に応じてリクエストに対するバリデーションを行う
...
// reqをコマンドに変換する
const placeOrder = parsePlaceOrder(req)
// ワークフローを呼び出す
const result = workflow(placeOrder)
...
}
ドメインオブジェクト以外の情報が必要ない場合は、必ずコマンドを使うべきなのでしょうか?
自分は状況に合わせて使えば良いと理解しました。
Part3 Implementing the Model
Part3 では Part2 で発注ワークフローのモデル化を踏まえて、関数型プログラミングアプローチを使って実装する方法が紹介されていました。
依存関係の注入
IoC コンテナを使わない形での依存関係の解決方法が紹介されていました。
関数型プログラミングでは、依存関係を明示的なパラメーターとして渡したいというのが前提にあるようです。
依存が多い場合は受け渡しの記述が煩雑になりますが、あらかじめ依存関係を組み込んだ関数を渡すことで記述量を減らすことができます。
const placeOrder = () => {
const endPoint = "...";
const credentials: "...";
const checkAddressExists = (unvalidatedAddress: UnvalidatedAddress) => {
// your checkAddressExists logic here using endPoint and credentials
}
const validateOrder = (
checkAddressExists: CheckAddressExists
) => {
// set up the steps in the workflow and return a function
return function (unvalidatedOrder: UnvalidatedOrder) {
// compose the pipeline from the steps ...
};
}
// create the workflow
const validatedOrder = validateOrder(checkAddressExists)(unvalidatedOrder);
...
}
シリアライゼーションと永続化
ワークフローをできる限り純粋な関数にするために、永続化やシリアライゼーションはワークフローの外側で行うべきと書かれていました。
とはいえ、ワークフローをビジネスロジックを含むドメイン中心の部分と I/O 関連のコードを含む「エッジ」部分に分けるとも書かれており、ワークフローに I/O 関連のコードを含めても良いのか?と混乱しました。
ただ、ワークフローを純粋関数として捉えることを重視しているっぽいので、Controller や UseCase はワークフローを呼び出す存在として扱うべきなのかもしれません。
下記のコードでは applyPayment をワークフローとして扱うと解釈しました。
// command handler at the edge of the bounded context
const payInvoice = (payInvoiceCommand: PayInvoiceCommand): void {
// Load from DB
const invoiceId = payInvoiceCommand.InvoiceId;
const unpaidInvoice = loadInvoiceFromDatabase(invoiceId); // I/O
// Call into pure domain
const payment = payInvoiceCommand.payment; // Pure
const paymentResult = applyPayment(unpaidInvoice, payment); // Pure
// Handle result
if (paymentResult.kind === "FullyPaid") {
markAsFullyPaidInDb(invoiceId); // I/O
postInvoicePaidEvent(invoiceId); // I/O
} else if (paymentResult.kind === "PartiallyPaid") {
updateInvoiceInDb(paymentResult.updatedInvoice); // I/O
}
}
リポジトリパターン
リポジトリパターンはオブジェクト指向設計の中で永続性を隠すための良い方法なので、全てを関数としてモデル化して、永続性をエッジに押しやれば必要なくなると書かれていました。
また、その場合何十ものメソッドを持つ単一のインターフェースを持つ代わりに、I/O アクセスごとに個別の関数を定義できるので保守しやすいよね的なことも添えられていました。
これについては正直ピンときていないです。Part2 の型によるドメインモデリングの章で集約が紹介されており、集約単位で永続化するならリポジトリパターンは必要では?と思いました。
まとめ
F#と関数型プログラミングを勉強しながら読み進めることができました。
個人的には TypeScript や Rust で実践してみたいと思います。
また、複雑さを解消する手段として振る舞いに応じて型を分ける方法は、関数型 DDD に限定されないアプローチとして取り組んでいきたいです。

Discussion