はじめに
この記事は株式会社LabBase テックカレンダー Advent Calendar 2023 11日目の記事です。
株式会社LabBaseでエンジニアをしている渡辺創です。
今回は GPT と Knowledge Graph を使って、自動で技術キーワードの類義語辞書をつくることができるか試してみたのでそれについて書いていきたいと思います。
背景
LabBase就職というサービスを提供しており、研究に取り組んでいる学生が研究概要を登録してくれています。研究を頑張っている学生を採用したい企業の方が研究内容と募集内容のマッチングによって、就職活動・採用活動を支援するサービスとなっています。
企業の人事の方が学生の研究内容をキーワードで検索するのですが、ユーザは自分の語彙の中でしか検索することができないので、その語彙を拡張する方法の1つとして、ユーザに類義語を提案しようと考えています。
探索
実際に探索するにあたり、以下のサイトやブログ、書籍を参考にしました
JSTさんのシソーラス
ストックマークさんのKnowledge Graphに関するブログ
Building Knowledge Graphs
上記の参考文献を読んで、以下がとりあえず試す上での要点と考えました。
- どのようなノードを用意するとよいのか
- どのような関係を用意するとよいのか
ChatGPTをつかいながら、どのようなノードと関係が必要か考えます。
こちらの論文を使って、どんなキーワードが抽出されたかをみます。
ChatGPTにキーワード抽出をお願いすると、以下のキーワードが抽出されました
Convolutional Neural Networks,
Model Scaling,
Compound Coefficient,
EfficientNet Models,
etc
このキーワードたちと subclass_of という関係を使うと、どのような Knowledge Graph ができあがるのか調べてみました。
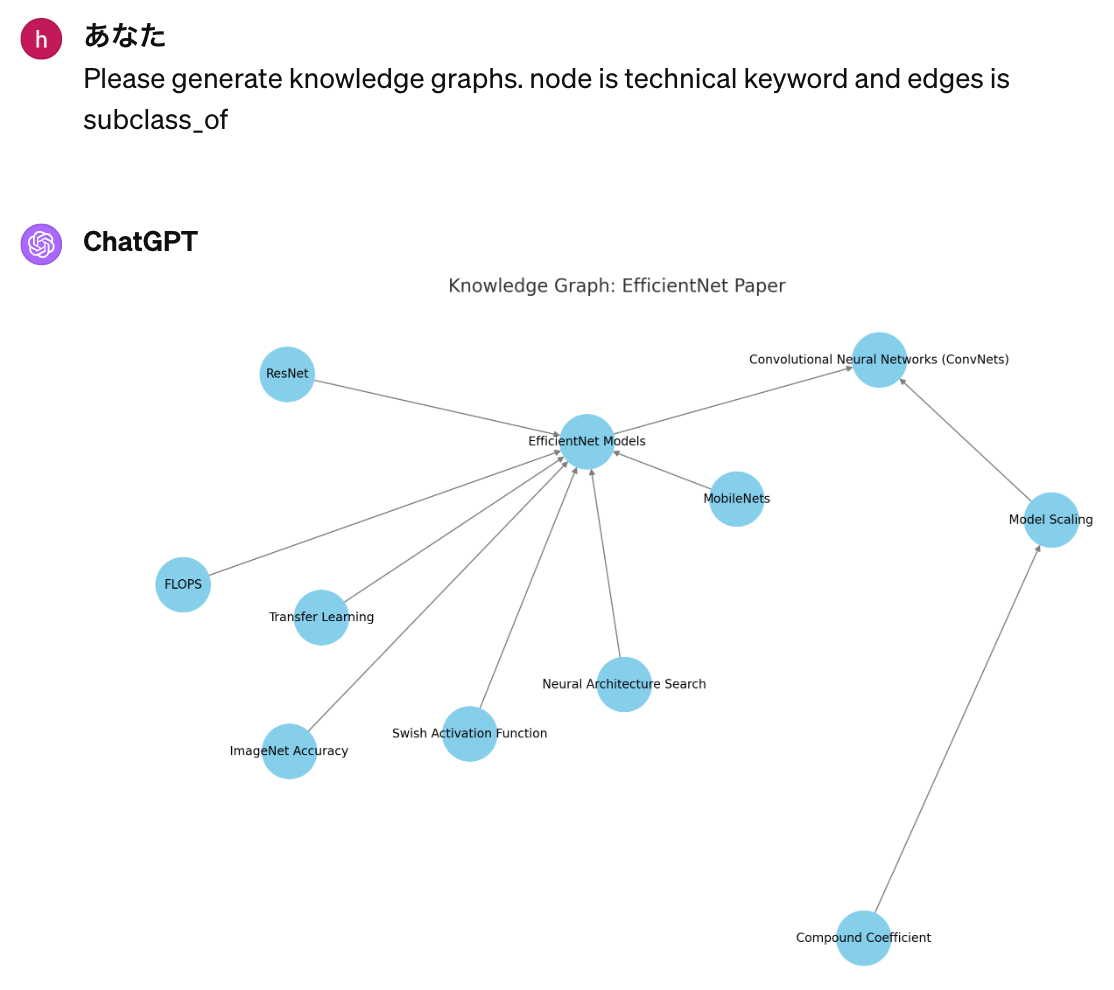
よくできているなと思いつつ、最上位が Convolutional Neural Networks になっていて、もう少しキーワードをまとめる軸があると良さそうだと感じたので、科学研究費助成事業の審査区分を参考にカテゴリとキーワードというノードを用意することにしました。
例えば、知覚情報処理関連という小区分には以下のキーワードが紐づいています。
パターン認識,
画像処理,
コンピュータビジョン,
etc
それに合わせて、キーワードを抽出してくる元データもkakenの研究課題に変更しました。
つまり、知覚情報処理に関する研究課題をデータとして用意し、そこからキーワードを抽出して、Knowledge Graph を構築していきます。 Category と Keyword は KEYWORD_OF でつながれ、 KEYWORD 同士は SUBCLASS_OF でつながれる想定です。
具体例としては、知覚情報処理に関する研究課題から以下のキーワードが抽出された場合は以下のような関係が抽出されます。
抽出されたキーワード
機械学習
コンピュータビジョン
画像解析
抽出された関係
機械学習 FIELD_OF 知覚情報処理
コンピュータビジョン FIELD_OF 知覚情報処理
画像解析 SUBCLASS_OF コンピュータビジョン
データの用意
ここからは実際にプログラムで処理して、自動で Knowledge Graph を構築していきます。
知覚情報処理に関する研究課題15件程度を利用する。
カラムは多くあるが、今回は研究課題名と研究開始時の研究の概要のみを利用する。
# Load the CSV file into a DataFrame
source_df = pd.read_csv('data/kaken_paper_test.csv')
# Combine the columns '研究課題名' and '研究概要' into a single column
source_df['combined'] = source_df['研究課題名'] + ' ' + source_df['研究開始時の研究の概要']
キーワードの抽出
今回キーワード抽出はGPT-3.5をFine-Tuningしたモデルを使いました。どんなデータでなぜそうしたのかはまた別のブログで書きたいと思います。
def extract_keyword(data_frame:pd.DataFrame):
# キーワード抽出を行う
instruction = """
入力を与えるので、入力から技術的なキーワードを抽出し、以下の形式で表示してください。
# 形式
キーワード1, キーワード2, ..., キーワードn
#入力
"""
extracted_keywords = []
for index, row in tqdm.tqdm(data_frame.iterrows()):
content = instruction + row['combined']
completion = openai.chat.completions.create(
model="ft:gpt-3.5-turbo-0613:labbase:info-manual-data:7vS79ZFi",
temperature=0,
messages=[
{"role": "system", "content": "あなたは優秀な研究者です。自分の専門分野に精通しています。"},
{"role": "user", "content": content }
]
)
keywords = completion.choices[0].message.content
# キーワードを追加
extracted_keywords.append({
'id': index,
'paper_title': row['研究課題名'],
'paper_overview': row['研究開始時の研究の概要'],
'keywords': keywords
})
return extracted_keywords
関係の抽出
関係の抽出はこちらのコードでおこないました。
def extract_triple(keywords: list):
# キーワード抽出を行う
system_prompt = """
あなたは優秀な研究者です。自分の専門分野に精通しています。
# 回答ルール
- triple はjson形式として、要素にnode1とnode1_labelとedgeとnode2とnode2_labelを持ちます。
- nodeのtypeはCategoryとKeywordから選択してください。
- edgeはSUBCLASS_OFとKEYWORD_OFから選択してください。
- ユーザが提供するカテゴリとキーワードを分析し、ナレッジグラフを構築するためのtripleをJSON形式の配列で出力してください。
- 出力はそのままjsonファイル形式で保存できる形で出力してください。
# 期待されるJSONレスポンス
{"triples":[{"node1":"keywordA","node1_label":"Keyword","edge":"KEYWORD_OF","node2":"categoryA","node2_label":"Category"},...]}
# 例
## カテゴリ
知識情報処理
## キーワード
コンピュータビジョン、画像解析
## レスポンス
{"triples":[{"node1":"コンピュータビジョン","node1_label":"Keyword","edge":"KEYWORD_OF","node2":"知覚情報処理","node2_label":"Category"},{"node1":"画像解析","node1_label":"Keyword","edge":"SUBCLASS_OF","node2":"コンピュータビジョン","node2_label":"Keyword"},]}
"""
instruction = """
# カテゴリ
知識情報処理
# 期待されるJSONレスポンス
{"triples":[{"node1":"keywordA","node1_label":"Keyword","edge":"KEYWORD_OF","node2":"categoryA","node2_label":"Category"},...]}
# キーワード
"""
end_instruction = """
カテゴリとキーワードを分析し、ナレッジグラフを構築するための全てのtripleをJSONの配列形式で出力してください。出力はそのままJSONファイルで保存できる形です。
"""
content = instruction + ','.join(keywords) + end_instruction
completion = openai.chat.completions.create(
model="gpt-4-1106-preview",
temperature=0.0,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": content}
],
response_format={"type": "json_object"}
)
data = completion.choices[0].message.content
return data['triples']
triples.json には以下が生成されたデータの一部です。
[
{"node1": "パターン認識", "node1_label": "Keyword", "edge": "KEYWORD_OF", "node2": "知識情報処理", "node2_label": "Category"},
{"node1": "画像処理", "node1_label": "Keyword", "edge": "KEYWORD_OF", "node2": "知識情報処理", "node2_label": "Category"},
{"node1": "コンピュータビジョン", "node1_label": "Keyword", "edge": "KEYWORD_OF", "node2": "知識情報処理", "node2_label": "Category"}
]
Cipherクエリの生成
最後にNeo4jというグラフデータベースにデータをいれるためのクエリをつくっていきます。
まず、ノード生成用のCipherクエリを作ります。
def generate_create_node_query(node_list:list, node_type:str):
file_name = "data/" + node_type + ".txt"
text_file = open(file_name, "wt")
for node in node_list:
query = "CREATE (:" + node_type + " {name: '" + node + "'})"
text_file.write(query + "\n")
text_file.close()
使う時は以下のような形で使います。
# デフォルトのカテゴリとキーワードの読み込み
with open('data/default_nodes.json') as f:
default_data = json.load(f)
# デフォルトカテゴリとデフォルトキーワードを抽出する
default_keywords = [item for item in default_data['keyword']]
default_categories = [item for item in default_data['category']]
keywords = default_keywords + extracted_keywords
# ノードのCipherクエリを生成
generate_create_node_query(default_categories, "Category")
generate_create_node_query(keywords, "Keyword")
default_nodes.json の中身は以下です。
{"category": ["知識情報処理"], "keyword":["パターン認識","画像処理","コンピュータビジョン"]}
次に関係をつくる用のCipherクエリを作ります。
def generate_create_edge_query(triple_list:list):
file_name = "data/Edge.txt"
text_file = open(file_name, "wt")
for triple in triple_list:
node1 = triple['node1']
node1_label = triple['node1_label']
edge = triple['edge']
node2 = triple['node2']
node2_label = triple['node2_label']
match_query = "MATCH (node1:" + node1_label + " {name: '" + node1 + "'})" + ",(node2:" + node2_label + " {name: '" + node2 + "'})"
merge_query = "MERGE (node1)-[roles:" + edge + "]->(node2)"
text_file.write(match_query + "\n")
text_file.write(merge_query + ";\n")
使う時は以下のような形で使います。
# triples の読み込み
with open('data/triples.json') as f:
triples = json.load(f)
# triples用の Cipherクエリの生成
generate_create_edge_query(triples)
それぞれ以下のようなクエリが生成されます。生成されたクエリの一部を抽出ししてます。
Category.txt
CREATE (:Category {name: '知識情報処理'})
Keyword.txt
CREATE (:Keyword {name: 'パターン認識'})
CREATE (:Keyword {name: '画像処理'})
CREATE (:Keyword {name: 'コンピュータビジョン'})
Edge.txt
MATCH (node1:Keyword {name: 'パターン認識'}),(node2:Category {name: '知識情報処理'})
MERGE (node1)-[roles:KEYWORD_OF]->(node2);
MATCH (node1:Keyword {name: '画像処理'}),(node2:Category {name: '知識情報処理'})
MERGE (node1)-[roles:KEYWORD_OF]->(node2);
MATCH (node1:Keyword {name: 'コンピュータビジョン'}),(node2:Category {name: '知識情報処理'})
MATCH (node1:Keyword {name: '画像処理'}),(node2:Keyword {name: 'コンピュータビジョン'})
MERGE (node1)-[roles:SUBCLASS_OF]->(node2);
Neo4jでのデータ確認
81のノードと80個の関係が生成されました。
全体像としてはこのような形のグラフになっています。
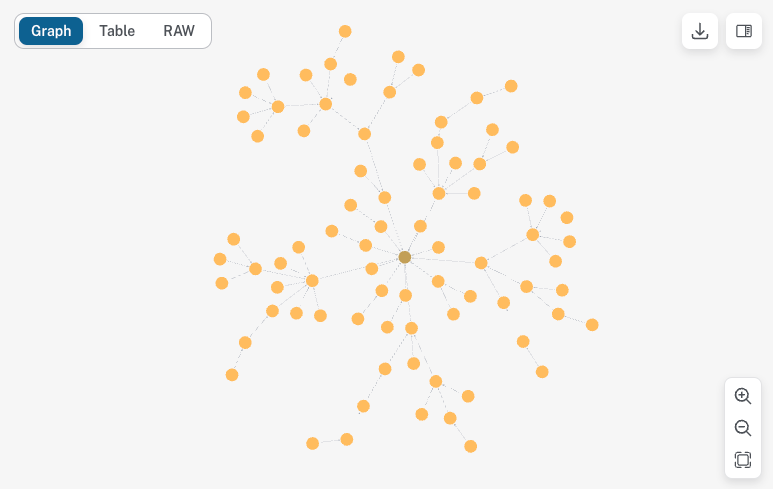
機械学習周辺はこんな感じです。
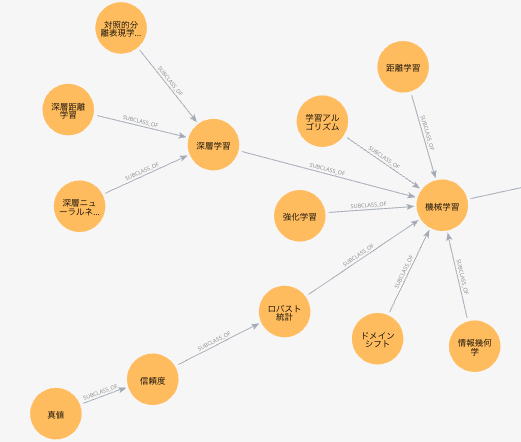
画像処理周辺はこんな感じです。
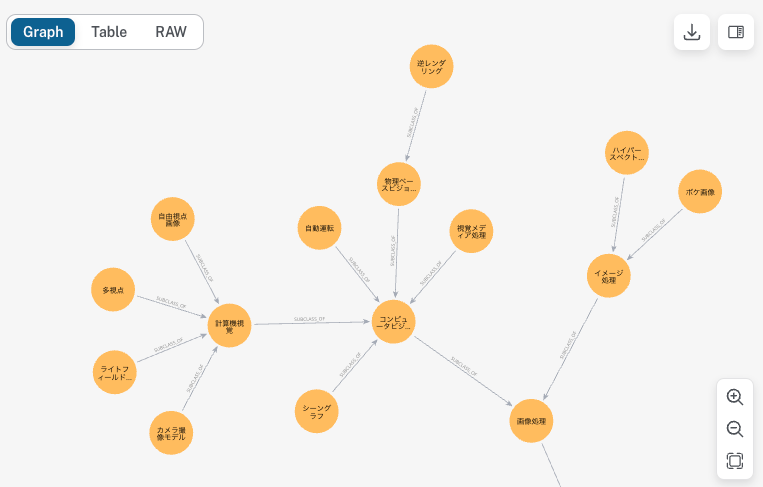
深さに制限加えた方が良さそうだったり、親子関係が微妙だったりもしますが、雰囲気良さそうなものができました。
ユーザが強化学習という検索キーワードをつかったと仮定して、親要素と、その親に紐づく子要素を全て出すときは以下のクエリで周辺の単語を類義語として取得することができました。

15個ほどの研究課題で多くの類義語が出せるので、処理を工夫しつつよく使われるようなものを残していくと良いデータが作ることができそうだなと感じました。
おわりに
最後までお読みいただき、ありがとうございます!ソースコードも少し整えたらgithubに上げる予定です。
LabBaseでは、GPTを活用した推薦の実装や検証を実際に手を動かしながら、進めているのでご興味ある方がいらっしゃいましたら、ぜひ渡辺のTwitterまでお気軽にお声がけください!!
明日は https://qiita.com/yuma140902 さんです。お楽しみに!

Discussion