GPT-4V と Segment Anything で楽々アノテーション
これは GO Inc. Advent Calendar 2023 の 12 日目の記事です。
私 kzykmyzw は GO 株式会社でコンピュータビジョンに関する研究開発から実装までを担当しており、本記事もコンピュータビジョンに関連しますが、会社での業務とは無関係です。あまり専門的に深い話はしませんが、ある程度知識のある方を対象としていますのでコンピュータビジョンに関する一般的な用語は解説せずに使います。
はじめに
2023 年の 9 月頃に画像認識が可能な GPT-4V(ision) が ChatGPT 経由で使えるようになり、2023 年 11 月 6 日に行われた Open AI DevDay で API 経由でも使えるようになったことが発表されました。主な使い方はやはり画像を自然言語で説明させることかと思いますが、普段は物体検出やセマンティックセグメンテーション(以下セマセグ)といったタスクに取り組むことが多い私としては、そういったタスクにも GPT-4V を活用したいところです。
ただ、物体検出やセマセグに GPT-4V を活用するには、GPT-4V から画像中の所望の物体に関して位置や形状といった詳細な回答を引き出す必要があります。これを画像とプロンプトだけで実現するのは困難だと思っていたのですが、ブログネタを探して調べていたところ、10 月にマイクロソフトから SoM (Set-of-Mark) という興味深いプロンプト手法が提案されているのを見つけました。
 Set-of-Mark Prompting(図は論文より引用)
Set-of-Mark Prompting(図は論文より引用)
これは上図右のように元画像に対して画像中の物体ごとに色を分けたり ID 番号を描画したりした画像を作り(これをマーキングと呼びましょう)、これを GPT-4V に入力することで説明性能の向上やそれぞれの物体の区別が可能になるというものです。
これをやるにはまず画像からそれぞれの物体の領域を抽出しないといけないのですが、ここで使える技術として 2023 年の 4 月に Meta から発表された SAM (Segment Anything Model) があります。これはその名の通り、画像中の物体であればなんでもセグメンテーションできるというモデルなのですが、あくまでも物体の領域がわかるだけでその物体がなんであるかまではわかりません。
さて、ここでブログのタイトルにつなげますが、安直な私は、1. 画像から SAM で各物体をセグメンテーション、2. 得られた各領域をマーキング、3. マーキングした画像を GPT-4V に入力して所望の物体の領域(ID 番号)を答えさせる、とすれば任意の物体に対するセマセグのアノテーションが自動化できるんじゃね?と思ってしまいました。図にすると以下のような感じです。
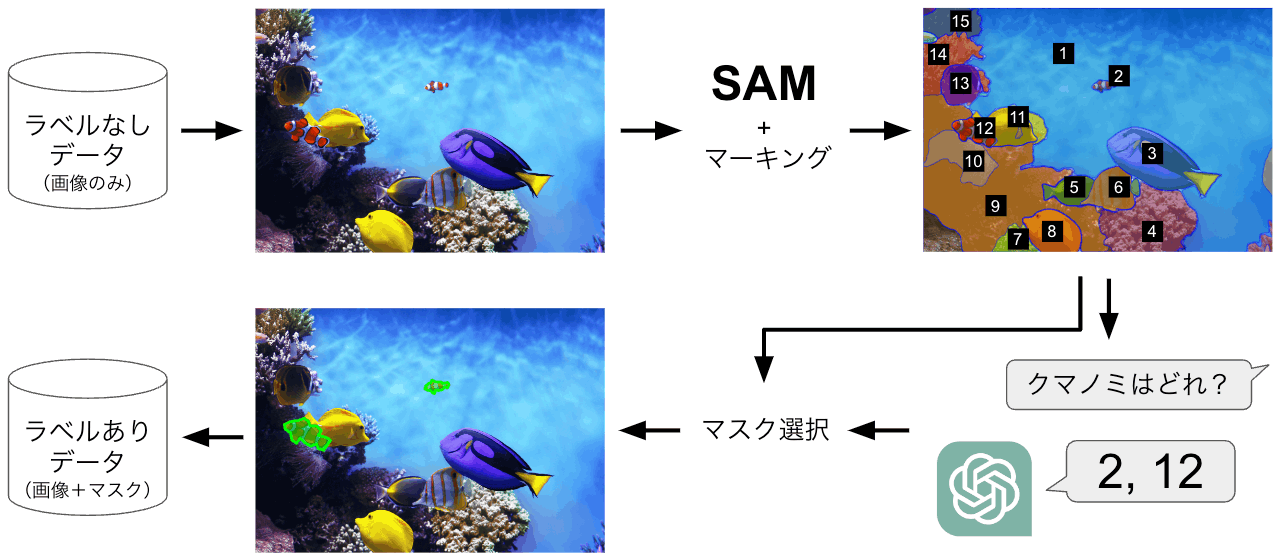 GPT-4V と SAM を使ったセマセグの自動アノテーション(画像は SAM のデモより引用)
GPT-4V と SAM を使ったセマセグの自動アノテーション(画像は SAM のデモより引用)
そもそもこれでセマセグが解けるならアノテーションは不要では、という気もしますが、特に現段階の GPT-4V をセマセグ目的でシステムに組み込んで運用するのは安定性やコスト、レスポンス速度などの観点でハードルが高いように思います。
では実際にそれぞれのパーツを作っていきます。対象とする物体はなんでもいいのですが、比較的簡単そうな物体でみんな大好き「ピザ」にしましょう。データセットは COCO を使います。(以降登場する画像は基本的に COCO の画像です)
SAM によるセグメンテーション
SAM でセグメンテーションを行うにはプロンプトを入力する必要がありますが、ここでのプロンプトはテキストではなく(技術的にはテキストも可のようですが)、対象物体を指示するための点の座標や物体を囲むバウンディングボックスです。しかしここで手動で物体をクリックしたり囲んだりしたのでは自動とはならないため、下図右上のように画像全体にグリッド状に配置した点をプロンプトとします(図中のグリッド間隔は実際とは異なります)。こうすることで画像中の物体全てがセグメンテーションされます。使い方は SAM のサンプル notebook に従えばOKです。
 SAM によるセグメンテーション
SAM によるセグメンテーション
結果は上図左下のようになりました。悪くないですが、ちょっと過剰に物体が分割されていますね。1 つのピザを 1 つの領域(マスク)として欲しいのですが、ピザの上に乗った具まで丁寧に分割されてしまっています。それぞれのマスクを見てみると、ピザ全体のマスクもちゃんと得られており、その上に具のマスクが乗っているような格好でした。そこで、他の大きいマスクの内部に包含されるようなマスクは削除することとしました。これで上図右下のようにマスクをいい感じの粒度にできました。
マーキング
続いて SAM で得られた各領域をマーキングしていきます。これには色々なやり方があると思いますが、ひとまず各領域に適当な ID 番号を振り、黒い矩形の中に白でその ID 番号を記載したものを各領域に描画してみます。ここで、非常に地味な話なのですが、各領域のどこに矩形を描画するのかという問題が出てきます。例えばマスクの中心(マスクされた領域の座標の平均)に描画することが考えられると思いますが、ある 2 つのマスク 1 と 2 が下図左のような形状であった場合、マスク 2 の中心がマスク 1 の内部に入り込んでしまい、下図右のように適切なマーキングができません。
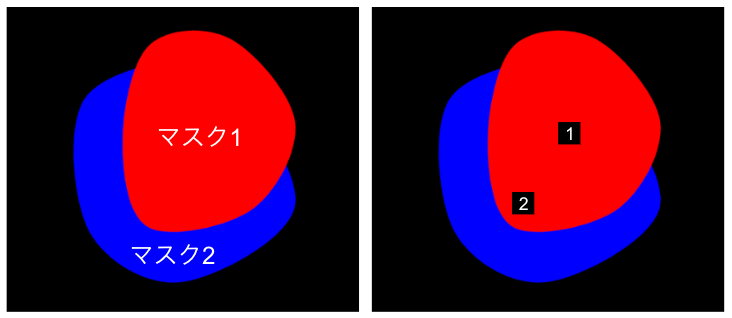 マスク中心への ID 番号の描画
マスク中心への ID 番号の描画
そこで、画像中にある領域が与えられたとき、領域内部の各画素について、最も近い領域境界までの距離を求めてマップを作る距離変換という技術を使います。これにより、マスク 1 と 2 から下図左のようなマップが得られ、マップの最大値(領域境界から最も遠い点)に矩形を描画することで下図右のようにいい感じの結果が得られます。距離変換は OpenCV の distanceTransform 関数を使うと簡単です。
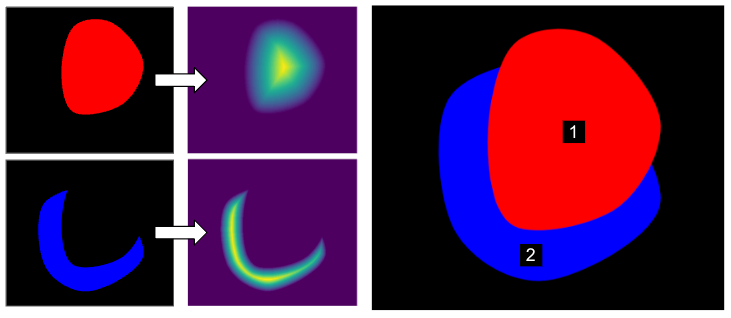 領域境界からの距離が最大となる点への ID 番号の描画
領域境界からの距離が最大となる点への ID 番号の描画
次は色分けです。これも色々なやり方があり、そもそも色分けしないことも考えられますし、領域ごとにランダムに色を塗る(ただし元画像をある程度透過させる)、あるいは境界線を描画するといったことも考えられます。そこで今回は以下 4 つのパターンで試してみることとしました。
 今回試したマーキング方法
今回試したマーキング方法
GPT-4V への入力
さていよいよマーキングした画像を GPT-4V に入力します。もちろん ChatGPT 経由でもいいですが、多数の画像を効率的に処理するために API を使います。GPT-4V を API から使用する際に指定するモデル名は gpt-4-vision-preview です。名前の通りまだプレビュー版のようで、こちらにあるように結構厳しめのレート制限があります。例えば有料会員が 5 ドル払うと Tier 1 という一番下のランクになるのですが、記事執筆時点での Tier 1 における制限は以下の通りです。API 利用で支払った額が増えるほど Tier が上がり制限が緩くなります。今回、私は個人利用でこれまでにあまりお金も払っていないので Tier 1 なのですが、RPD 500 という制限、つまり 1 日に 500 件しかリクエストを投げられないというのがキツかったです。
- RPM (requests per minute): 80
- RPD (requests per day): 500
- TPM (tokens per minute): 10,000
また料金についてはこちらで計算できますが、画像サイズによって変動し例えば 512 x 512 ならば 1 枚あたり 0.00255 ドル(約 0.37 円)、1,024 x 1,024 ならば 0.00765 ドル(約 1.12 円)です。実際にはこれに入力プロンプトや GPT-4V の回答のトークン数に応じて金額が加算されますが、今回のような用途ではそれらは軽微です。
API 経由で GPT-4V に画像を渡す方法は公式ドキュメントに従います。プロンプトですが、私はプロンプトエンジニアリングというものを全くやったことがないのでとりあえず何も考えずに適当に日本語で作文したものを ChatGPT で英訳したものを使います。画像に描画した各領域の ID 番号のうち、ピザに相当するものを答えさせます。なお画像中にピザがない場合は -1 と答えるよう指示します。以下は画像へのマーキングを ID 番号+色分け+境界線で行なった場合のプロンプトです。
In this image, each visual area is color-coded and outlined, with IDs written in white numbers inside black squares near the center of each area. Locate the area(s) corresponding to pizza within this image and provide all their IDs. Please respond with only the IDs (non-negative integers). If there are no pizzas present in the image, please output '-1'.
試しにピザが写っている画像とそうでない画像で試した結果がこちらです。画像が小さくわかりづらいですが、左の画像ではピザに相当する領域の ID 番号である 14 を、右の画像ではピザが存在しないため -1 を正しく回答することができています。いい感じです。ちなみにリクエストを投げてからレスポンスが帰ってくるまでの時間は 3 秒ほどでした。

実験
ここからは GPT-4V と SAM による自動アノテーションが人間によるアノテーションと比較してどの程度のものなのかを評価するための実験をしていきます。
まず予備実験として、小さなデータセットを使ってマーキングのところで述べた 4 種類のマーキング方法(ID 番号のみ、ID 番号+色分け、ID 番号+境界線、ID 番号+色分け+境界線)のどれがベストかを調べます。評価用データとして、COCO に付与されている真値を元にピザが写っている画像を 100 枚、ピザが写っていない画像を 100 枚選んだ 200 枚を使います。評価尺度は、ピザが写っているか否かの判定精度 (accuracy) と、SAM によるマスクのうち GPT-4V がピザであると判定したマスクと人間による真値マスクとの IoU です。なお後者についてはピザが写っている画像(100 枚)のみで計算しています。結果は以下の通りです。
| ID 番号のみ | ID 番号+色分け | ID 番号+境界線 | ID 番号+色分け+境界線 | |
|---|---|---|---|---|
| accuracy | 0.98 | 0.96 | 0.97 | 0.94 |
| IoU | 0.48 | 0.51 | 0.50 | 0.53 |
accuracy と IoU で傾向が異なるためなんとも言えませんが、ピザが写っているか否かの判定はそこそこ高精度にできそうなので IoU で判断すると ID 番号+色分け+境界線が最も良さそうです。ちなみに、一応 GPT-4V がデタラメに答えているわけではないことを確認するために、ランダムな ID 番号のマスクで IoU を計算すると 0.19 と大幅に小さい値になりました。
さて今度は本格的な実験として、実際にセマセグのモデルを学習してみます。先の予備実験にて、画像にピザが写っているか否かの判定はほぼできそうなことがわかったので、GPT-4V のレート制限と費用の関係上、ここからはピザが写っている画像のみを対象としていきます。自動アノテーションで作ったデータセットと、人間によるアノテーションで作ったデータセット(オリジナルの COCO)のそれぞれでセマセグのモデルを学習し、得られたモデルの精度を比較します。
ピザが写っている画像を学習用に 1,500 枚、検証用に 400 枚用意し、学習データにのみ自動アノテーションを実施します(検証用の真値は人間によるアノテーションを使います)。画像へのマーキング方法は予備実験でベストだった ID 番号+色分け+境界線です。セマセグのモデルとしては segmentation_models.pytorch から DeepLabV3 を使いました。学習後のモデルの精度は以下の通りです。
| 人間によるアノテーション で学習したセマセグモデル |
自動アノテーション で学習したセマセグモデル |
|
|---|---|---|
| IoU | 0.82 | 0.71 |
うーん、人間によるアノテーションで学習した場合と比べて自動アノテーションで学習した場合はだいぶモデルの精度が落ちていますね… 原因調査のために、自動アノテーションで作成されたマスクをいくつか実際に見てみましょう。
 自動アノテーションの成功例
自動アノテーションの成功例
 自動アノテーションの失敗例
自動アノテーションの失敗例
特にうまくいかなかった例を見てみると、ピザの近くにある物体を誤って抽出する、複数のピザがある場合に一部を見逃す、1 つのピザの一部しか抽出できない、などのエラーがあるようです。こうしたエラーを含むデータで学習した結果、先ほどのような精度低下が起きたと思われます。
これらのエラーは、SAM で得られたマスクの後処理やマーキング方法の工夫、また GPT-4V に入力する際のプロンプトエンジニアリングによりある程度解決できそうですが、今回はより簡単に、学習時のロスが大きいデータはエラーを含む可能性が高いと判断して除外を試みます。自動アノテーションで作成したデータセットで学習したモデルで全データを推論し、ロスが大きい上位 50% を削除します。残ったデータセットで再度学習した結果は以下のようになりました。
| 人間によるアノテーション で学習したセマセグモデル |
自動アノテーション で学習したセマセグモデル |
|
|---|---|---|
| IoU | 0.79 | 0.76 |
まだ人間によるアノテーションで学習した場合には及ばないですが、自動アノテーションの方は精度が改善し、両者の差がかなり小さくなりました。自動アノテーションであっても、うまく高品質なデータを選定することができれば、人間によるアノテーションに近いものは得られそうです。マスク領域だけを再度 GPT-4V に見せて、本当にピザかどうかを判定させてもいいかもしれません。
おわりに
今回はピザというかなりメジャーかつ形状や見た目にあまり多様性がない物体を選んだためか、GPT-4V と SAM を使ってセマセグのアノテーションを自動化するという試みはまずまずの結果となりました。ただ今回のアプローチは、一般的な公開データセットで事前に学習できないようなレアな物体を対象とするケースなどでより効果を発揮すると思うので、そういったケースにどれだけ対応できるかは気になるところです。あとやはり、高度なコンテキストの理解や理解した結果を言語化するという GPT-4V の本来の力を使っていないので、GPT-4V の無駄使い感がありますね…
個人的には、GPT-4V のような大規模な視覚言語モデルがいきなり既存のコンピュータビジョンのモデルを駆逐するようなことにはならないと感じていますが、今回試したように既存のパイプラインのどこかを効率化したり強化したりするような用途にはすぐにでも使えるのではないかと思っています。今後も様々な使い道を検討していきたいところです。
最後に宣伝ですが、私は、今回のように AI 開発における「データ」の作成や取り扱い、改善といったテーマで情報を共有することを目的として Data-Centric AI Community を運営しています。定期的な勉強会の開催が主な活動内容ですが、次回の第 5 回勉強会が 12/20(水)の開催となりますので、ご興味ある方はぜひご参加をよろしくお願いいたします!今後の勉強会で発表いただける方も随時募集しております。

Discussion