kaggleコンペ①(コンペの概要把握~ベースモデルの構築まで)
はじめに
勉強してきたことのまとめとしてkaggleコンペに挑戦したので、備忘録としてデータの分析、モデル構築、ファイルの提出といった一連の流れをまとめて見ました。
技術ブログを初めて書くので上手く書けていないかもしれません。
挑戦するkaggleコンペ
人工呼吸器の呼吸予測コンペ
概要:
新型コロナウイルスの流行に伴いひっ迫した医療体制を改善することを目指し、人工呼吸器を自動的に制御する方法を開発したい。しかし、開発には莫大な費用が発生する。
そこで、このコンペを通じて患者ごとの肺の違いなどについて考慮したシミュレーションデータを獲得し、少しでも開発にかかる費用を少なくしたい。
そうすれば自動的に人工呼吸器を制御する方法を開発出来る可能性が高くなるので、結果として医師の負担を減らすこともでき医療体制の充実に繋がる。
このような背景からこのコンペが行われている。
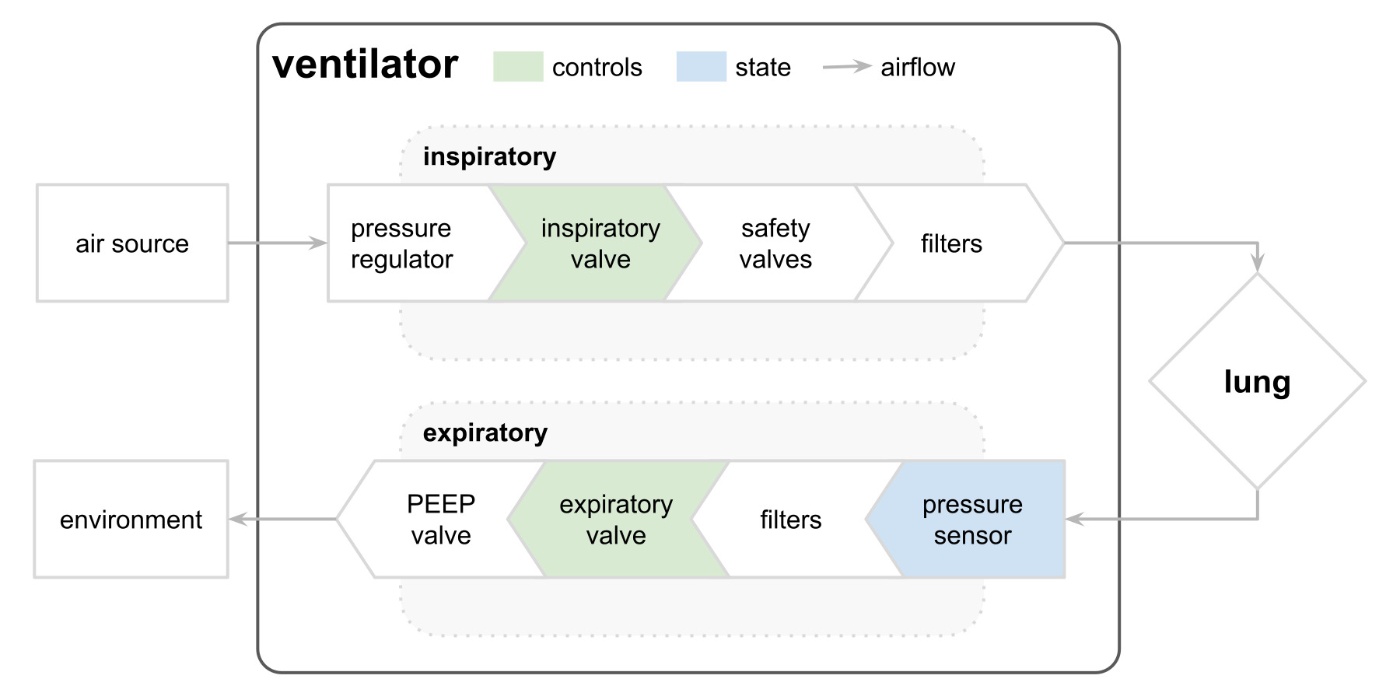
呼吸中の呼吸回路の気道内圧を予測する。
評価指標:各呼吸の吸気段階で予測した圧力と実際に測定された圧力の間の平均絶対誤差(MAE)。0に近いほど良い。
データ概要
訓練データ train.csv #6036000 行 × 8 列 80名
テストデータ test.csv #4024000 行 × 7 列 80名
提出用ファイル sample.submission.csv #4024000 行 × 2 列
列一覧
id:1行ごとの単位
breath_id:呼吸実験ごとの単位
R:気道がどの程度制限されているかを示す肺属性(単位:cmH2O/L/S)。
物理的には、流量(時間当たりの空気量)の変化に対する圧力の変化を表している。
直感的には、ストローで風船を膨らませるようなイメージ。
ストローの直径を変えることでRを変化させることができ、Rが大きいほど吹きにくくなる。
C:肺の適合性を示す肺属性(単位:mL/cmH2O)。
物理的には、圧力の変化に対する体積の変化を表している。
直感的には、Rと同じ風船の例だと想像しやすい。
風船のラテックス(≒ゴム)の厚さを変えることでCを変化させることができる。
Cが大きいほどラテックスが薄く、吹きやすい。
time_step:実験している時の秒数。
u_in:吸気バルブの入力を制御している時の値。0~100の範囲で設定出来る。
(0が完全に閉じていて空気を入れない。100は完全に開いている。)
u_out:探索用バルブの入力を制御している時の値。0または1のいずれか。
(0は閉じているので空気を排出できない。1は開いている。)
pressure(目的変数):呼吸回路で測定された気道の圧力で、単位はcmH2O。
データの分析
データの型
train.dtypes
id int64
breath_id int64
R int64
C int64
time_step float64
u_in float64
u_out int64
pressure float64
欠損値
train.isnull().sum()
id 0
breath_id 0
R 0
C 0
time_step 0
u_in 0
u_out 0
pressure 0
欠損値はないので欠損値に関する前処理は行わなくても大丈夫そう
pandas_profilingで分析
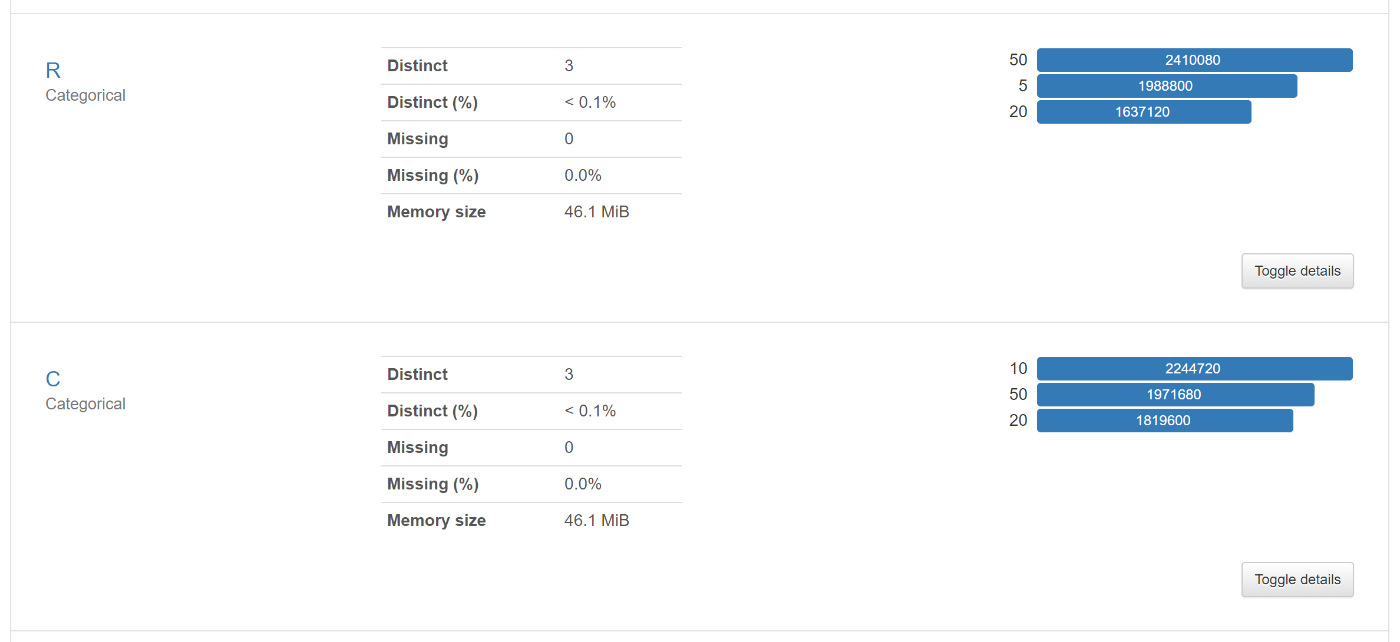
RとCはユニークな値が3個しかない(「5,20,50」と「10,20,50」)
:数値ではあるがカテゴリー変数に近いように思える。
相関係数(ピアソンの相関係数)
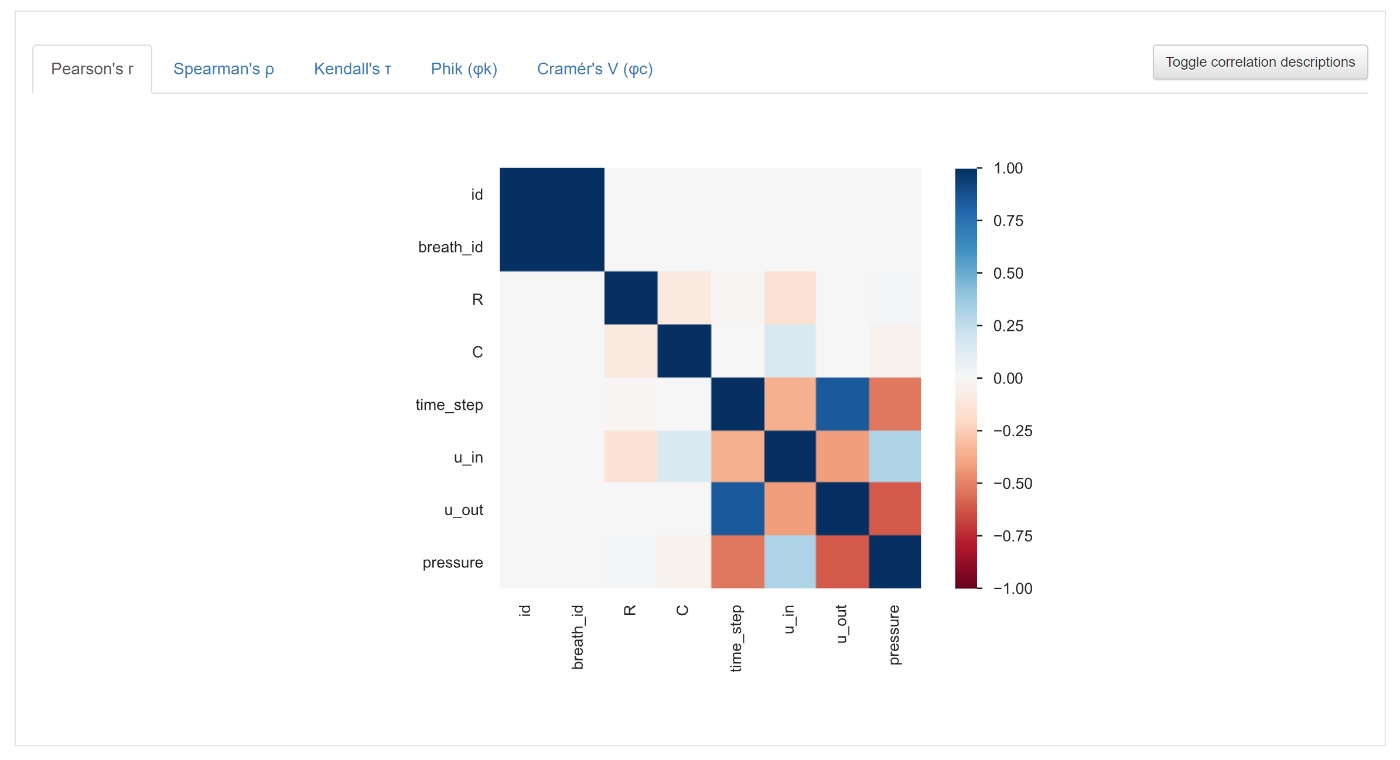
色の濃いところ程、相関が強い
ベースラインモデルの構築
import pandas as pd
import lightgbm as lgb
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
train = pd.read_csv('train.csv', index_col=0) #6036000 rows × 8 columns
test = pd.read_csv('test.csv', index_col=0) #4024000 rows × 7 columns
X = train.drop(columns=['pressure']) #6036000 rows × 4 columns
y = train.pressure #6036000 rows × 1 columns
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=24)
#Python API
lgb_train = lgb.Dataset(data=X_train, label=y_train)
lgb_val = lgb.Dataset(data=X_val, label=y_val, reference=lgb_train)
param = { 'objective':'regression', #目的関数:回帰
'task':'train',
'boosting':'gbdt',
'num_iterations':100, # 木の数 defalut 100
'learning_rate':0.1, # 学習率 default 0.1
'metric':{'rmse'}, # 評価指標 : (平均二乗誤差の平方根)
'num_leaves':31, # 木の分岐の個数(葉の数) default 31
'min_data_in_leaf':20, # default 20
'max_depth':-1, # 木構造の深さを限定するための変数 defaultの-1は上限無し
'verbose':0, # 学習途中の中継的な情報を表示するかしないか
'seed':42 }
bst = lgb.train( params=param,
train_set=lgb_train,
valid_sets=[lgb_train,lgb_val],
valid_names=['train','valid'],
num_boost_round=200,
early_stopping_rounds=50 )
y_pred = bst.predict(X_val)
mean_absolute_error(y_val, y_pred) #2.1158400403297306
テストデータ
t_pred = bst.predict(test)
sample_submit = pd.read_csv('sample_submission.csv', index_col=0)
sample_submit['pressure'] = t_pred
sample_submit.to_csv('ベースライン.csv')
提出時のスコア:4.190
計算時間が少なく精度も良くなりやすいらしいので、モデルとしてはLightGBMを使用しました。
使用したライブラリ
Pandas, Pandas-Profiling, LightGBM, Scikit-learn
Discussion