データサイエンス100本ノック(SQL)21~30
新しく出てきた内容
集約関数
行数[count()]、 合計[sum()]、 最大値[max()]、
最小値[min()]、 平均値[avg()]、 分散[var_samp()]
中央値[percentile_cont (0.5) WITHIN GROUP (ORDER BY ) ]
最頻値[mode () WITHIN GROUP ( ORDER BY )]
distinct
group by句(グループごとにまとめる)
having(纏めた後の表に対する行の絞り込み)
追記
最近になってGCPのBigQueryでも回答を作ってみたので合わせてそのコードも記載する
基本的にPostgreSQLの下にGCPのコードを記していく
S-021:レシート明細テーブル(receipt)に対し、件数をカウントせよ。
PostgreSQL
select count(*) from receipt;
BigQuery
select count(*) from [データセット名].receipt;
104681
S-022:レシート明細テーブル(receipt)の顧客ID(customer_id)に対し、
ユニーク件数をカウントせよ。
PostgreSQL
select count(distinct customer_id) from receipt;
BigQuery
select count(distinct customer_id) from [データセット名].receipt;
8307
DISTINCT をつけて SELECT 文を実行すると、重複したデータは除外してデータを取得することができる。
S-023:レシート明細テーブル(receipt)に対し、店舗コード(store_cd)ごとに
売上金額(amount)と売上数量(quantity)を合計せよ。
PostgreSQL
select store_cd,
sum(amount) as sum_amount,
sum(quantity) as sum_quantity
from receipt
group by store_cd;
BigQuery
select store_cd,
sum(amount) as amount,
sum(quantity) as quantity
from [データセット名].receipt
group by store_cd;
group by 句でまとめることが出来る
S-024:レシート明細テーブル(receipt)に対し、顧客ID(customer_id)ごとに
最も新しい売上日(sales_ymd)を求め、10件表示せよ。
PostgreSQL
select customer_id,
max(sales_ymd) as max_sales_ymd
from receipt
group by customer_id
limit 10;
BigQuery
select customer_id,
max(sales_ymd) as max_sales_ymd
from [データセット名].receipt
group by customer_id
limit 10;
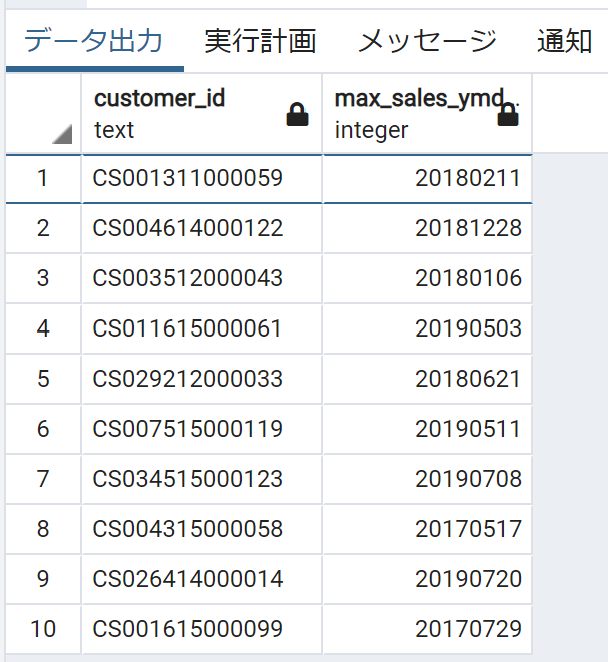
S-025:レシート明細テーブル(receipt)に対し、顧客ID(customer_id)ごとに
最も古い売上日(sales_ymd)を求め、10件表示せよ。
PostgreSQL
select customer_id,
min(sales_ymd) as min_sales_ymd
from receipt
group by customer_id
limit 10;
BigQuery
select customer_id,
min(sales_ymd) as min_sales_ymd
from [データセット名].receipt
group by customer_id
limit 10;
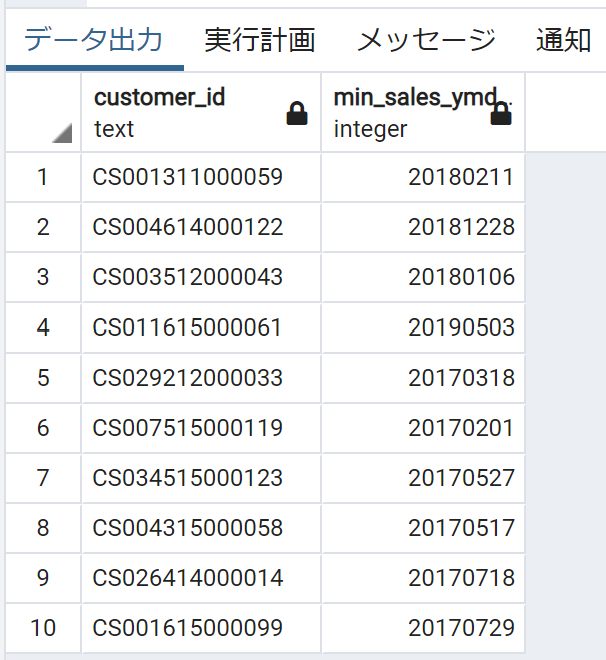
S-026:レシート明細テーブル(receipt)に対し、顧客ID(customer_id)ごとに
最も新しい売上日(sales_ymd)と古い売上日を求め、
両者が異なるデータを10件表示せよ。
PostgreSQL
select customer_id,
max(sales_ymd) as max_sales_ymd,
min(sales_ymd) as min_sales_ymd
from receipt
group by customer_id
having max(sales_ymd) != min(sales_ymd)
limit 10;
BigQuery
select customer_id,
max(sales_ymd) as max_sales_ymd,
min(sales_ymd) as min_sales_ymd
from [データセット名].receipt
group by customer_id
having max(sales_ymd) != min(sales_ymd)
limit 10;
S-027:レシート明細テーブル(receipt)に対し、店舗コード(store_cd)ごとに
売上金額(amount)の平均を計算し、降順でTOP5を表示せよ。
PostgreSQL
select store_cd,
avg(amount) as avg_amount
from receipt
group by store_cd
order by avg_amount desc
limit 5;
BigQuery
select store_cd,
avg(amount) as avg_amount
from [データセット名].receipt
group by store_cd
order by avg_amount desc
limit 5;
S-028:レシート明細テーブル(receipt)に対し、店舗コード(store_cd)ごとに
売上金額(amount)の中央値を計算し、降順でTOP5を表示せよ。
PostgreSQL
select store_cd,
percentile_cont(0.5) within group (order by amount) as median
from receipt
group by store_cd
order by median desc
limit 5;
BigQuery
select distinct store_cd,
percentile_cont(amount, 0.5) over(partition by store_cd)
as amount_50per
from [データセット名].receipt
order by amount_50per desc
limit 5;
postgresqlには中央値を直接求めるものが無いので、percentile_cont()を使って求める。
・percentile_cont () WITHIN GROUP (ORDER BY )
S-029:レシート明細テーブル(receipt)に対し、店舗コード(store_cd)ごとに
商品コードの最頻値を求めよ。
-- コード例2:mode()を使う簡易ケース(早いが最頻値が複数の場合は一つだけ選ばれる)
PostgreSQL
select store_cd,
mode() within group (order by product_cd)
from receipt
group by store_cd;
BigQuery
select store_cd,
approx_top_count(product_cd, 1) as mode
from [データセット名].receipt
group by store_cd;
最頻値を求める:mode () WITHIN GROUP ( ORDER BY )
S-030:レシート明細テーブル(receipt)に対し、店舗コード(store_cd)ごとに
売上金額(amount)の標本分散を計算し、降順にTOP5を表示せよ。
PostgreSQL
select store_cd,
var_samp(amount) as var_amount
from receipt
group by store_cd
order by var_amount desc
limit 5;
BigQuery
select store_cd,
var_samp(amount) as var_amount
from [データセット名].receipt
group by store_cd
order by var_amount desc
limit 5;
var_samp() = variance() どちらでも良い
Discussion