😽
『Python』EDINET上の財務情報を取得・アプリで可視化➁





はじめに
大まかな流れは下の図の通りです。

ここでは➀で取得した書類から実際に財務諸表の数値を取り出しデータフレームとしてcsvに保存するまでの工程を取り扱います。
➀ではXBRLとPDFの形式でそれぞれ書類を取得しましたが、ここではその中のXBRL形式で取得した有価証券報告書を使用します。
ちなみに、XBRL形式では以下のように表されています。
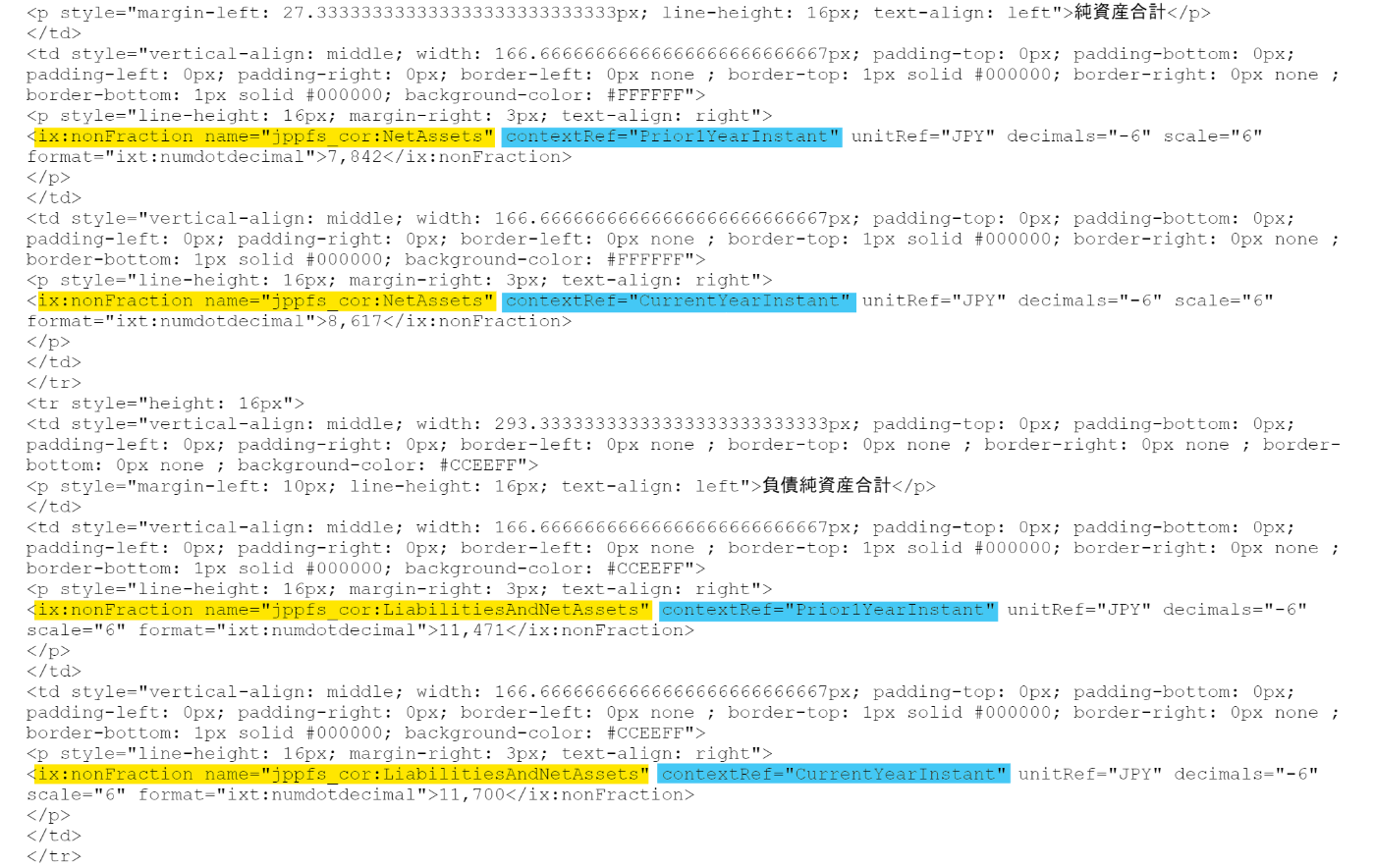
今回マーカーで引いた部分を使用することで数値を取り出すことが出来ます。
実行したコード
ライブラリのインポート
!pip install edinet_xbrl
from google.colab import drive
drive.mount('/content/drive')
import os
os.chdir('/content/drive/My Drive/スクレイピング/EDINET')
import glob
import pandas as pd
from datetime import datetime
from decimal import Decimal, ROUND_HALF_UP
from edinet_xbrl.edinet_xbrl_parser import EdinetXbrlParser
関数・変数読み込み
def get_one_xbrl_data(path, key, context_ref):
parser = EdinetXbrlParser()
# 指定したxbrlファイルをパースする(データを解析し必要なデータを取り出すこと)
xbrl_file_path = path
edinet_xbrl_object = parser.parse_file(xbrl_file_path)
# データの取得
data = edinet_xbrl_object.get_data_by_context_ref(key, context_ref)
if data is not None:
return data.get_value()
# パスを通す
def path(edinetCode, doctypecode):
doc_id = summary.query(f'edinetCode=="E{edinetCode}" and docTypeCode=="{doctypecode}"').docID.values[0] # 文書IDを取得
date = summary.query(f'edinetCode=="E{edinetCode}" and docTypeCode=="{doctypecode}"').submitDateTime.values[0] # 提出日を取得
file_path = save_path + zip_path + doc_id + '_' + date[:10] + '/' + '/XBRL/PublicDoc/*.xbrl' # XBRLを取得
file_path = glob.glob(file_path)[0]
return file_path
csv_path, zip_path = 'submitted_summary_csv/', 'zip/'
doctypecode, column = 120, 'seqNumber'
取得した財務諸表の数値をリストに纏める関数
# 連結財務諸表 financial_statements
def f_s(Assets, LiabilitiesAndNetAssets, pl_flow, cf_flow, cf_stock, period, stock_key):
# 連結貸借対照表
bs = []
for key in Assets: # 資産
current = get_one_xbrl_data(file_path, key=key, context_ref=period[0])
current = 0 if current is None else current # 財務諸表の数値が空欄の時は0を入れるようにする
current = int(Decimal(current).quantize(Decimal('1E6'), rounding=ROUND_HALF_UP)) // 1000000 # 単位を百万円に変換している(四捨五入)
bs.append(current)
for key in LiabilitiesAndNetAssets: # 負債・純資産
current = get_one_xbrl_data(file_path, key=key, context_ref=period[0])
current = 0 if current is None else current
current = int(Decimal(current).quantize(Decimal('1E6'), rounding=ROUND_HALF_UP)) // 1000000
bs.append(current)
# 連結損益計算書
pl = []
for key in pl_flow:
current = get_one_xbrl_data(file_path, key=key, context_ref=period[1])
current = 0 if current is None else current
current = int(Decimal(current).quantize(Decimal('1E6'), rounding=ROUND_HALF_UP)) // 1000000
pl.append(current)
# 連結キャッシュフロー計算書
cf = []
for key in cf_flow: # フロー項目
current = get_one_xbrl_data(file_path, key=key, context_ref=period[1])
current = 0 if current is None else current
current = int(Decimal(current).quantize(Decimal('1E6'), rounding=ROUND_HALF_UP)) // 1000000
cf.append(current)
for context_ref in cf_stock: # ストック項目(期首残高・期末残高)
current = get_one_xbrl_data(file_path, key=stock_key, context_ref=context_ref)
current = 0 if current is None else current
current = int(Decimal(current).quantize(Decimal('1E6'), rounding=ROUND_HALF_UP)) // 1000000
cf.append(current)
return bs, pl, cf
取得する財務諸表の項目を設定
current = ['CurrentYearInstant', 'CurrentYearDuration']
prior = ['Prior1YearInstant', 'Prior1YearDuration']
save_path = './rakus/'
edinetCode = 31878
csv_l = ['2018-06-25_summary.csv', '2019-06-24_summary.csv', '2020-06-29_summary.csv', '2021-06-28_summary.csv', '2022-06-27_summary.csv']
# 流動資産合計、有形固定資産合計、無形固定資産合計、投資その他の資産合計、固定資産合計、資産合計
A = ['jppfs_cor:CurrentAssets', 'jppfs_cor:PropertyPlantAndEquipment', 'jppfs_cor:IntangibleAssets', 'jppfs_cor:InvestmentsAndOtherAssets', 'jppfs_cor:NoncurrentAssets', 'jppfs_cor:Assets']
# 流動負債合計、固定負債合計、負債合計、株主資本合計、その他の包括利益累計額合計、純資産合計、負債純資産合計
LNA = ['jppfs_cor:CurrentLiabilities', 'jppfs_cor:NoncurrentLiabilities', 'jppfs_cor:Liabilities', 'jppfs_cor:ShareholdersEquity', 'jppfs_cor:ValuationAndTranslationAdjustments', 'jppfs_cor:NetAssets', 'jppfs_cor:LiabilitiesAndNetAssets']
# 売上高、売上原価、売上総利益、販売費及び一般管理費、営業利益、営業外収益、営業外費用、経常利益、特別利益、特別損失、税金等調整前当期純利益、法人税等合計、当期純利益
pl = ['jppfs_cor:NetSales', 'jppfs_cor:CostOfSales', 'jppfs_cor:GrossProfit', 'jppfs_cor:SellingGeneralAndAdministrativeExpenses', 'jppfs_cor:OperatingIncome', 'jppfs_cor:NonOperatingIncome', 'jppfs_cor:NonOperatingExpenses', 'jppfs_cor:OrdinaryIncome', 'jppfs_cor:ExtraordinaryIncome', 'jppfs_cor:ExtraordinaryLoss', 'jppfs_cor:IncomeBeforeIncomeTaxes', 'jppfs_cor:IncomeTaxes', 'jppfs_cor:ProfitLoss']
# 小計、利息及び配当金の受取額、利息の支払額、法人税等の支払額、営業CF、投資CF、財務CF、現金及び現金同等物に係る換算差額、現金及び現金同等物の増減額
cf_flow = ['jppfs_cor:SubtotalOpeCF', 'jppfs_cor:InterestAndDividendsIncomeReceivedOpeCFInvCF', 'jppfs_cor:InterestExpensesPaidOpeCFFinCF', 'jppfs_cor:IncomeTaxesPaidOpeCF', 'jppfs_cor:NetCashProvidedByUsedInOperatingActivities', 'jppfs_cor:NetCashProvidedByUsedInInvestmentActivities', 'jppfs_cor:NetCashProvidedByUsedInFinancingActivities', 'jppfs_cor:EffectOfExchangeRateChangeOnCashAndCashEquivalents', 'jppfs_cor:NetIncreaseDecreaseInCashAndCashEquivalents']
# 現金及び現金同等物の期首残高、現金及び現金同等物の期末残高
cf_stock = ['Prior1YearInstant', 'CurrentYearInstant']
stock_key = 'jppfs_cor:CashAndCashEquivalents'
有価証券報告書から実際に数値を取得しリストにまとめる
# 2018年3月期
summary = pd.read_csv(f'{save_path}{csv_path}{csv_l[0]}', dtype=object)
summary[column] = summary[column].astype(int)
file_path = path(edinetCode, doctypecode)
bs_p4, pl_p4, cf_p4 = f_s(A, LNA, pl, cf_flow, cf_stock, current, stock_key)[0], f_s(A, LNA, pl, cf_flow, cf_stock, current, stock_key)[1], f_s(A, LNA, pl, cf_flow, cf_stock, current, stock_key)[2]
cf_stock = ['Prior2YearInstant', 'Prior1YearInstant']
bs_p4_p, pl_p4_p, cf_p4_p = f_s(A, LNA, pl, cf_flow, cf_stock, prior, stock_key)[0], f_s(A, LNA, pl, cf_flow, cf_stock, prior, stock_key)[1], f_s(A, LNA, pl, cf_flow, cf_stock, prior, stock_key)[2]
# 2019年3月期
cf_stock = ['Prior1YearInstant', 'CurrentYearInstant']
summary = pd.read_csv(f'{save_path}{csv_path}{csv_l[1]}', dtype=object)
summary[column] = summary[column].astype(int)
file_path = path(edinetCode, doctypecode)
bs_p3, pl_p3, cf_p3 = f_s(A, LNA, pl, cf_flow, cf_stock, current, stock_key)[0], f_s(A, LNA, pl, cf_flow, cf_stock, current, stock_key)[1], f_s(A, LNA, pl, cf_flow, cf_stock, current, stock_key)[2]
# 2020年3月期
summary = pd.read_csv(f'{save_path}{csv_path}{csv_l[2]}', dtype=object)
summary[column] = summary[column].astype(int)
file_path = path(edinetCode, doctypecode)
bs_p2, pl_p2, cf_p2 = f_s(A, LNA, pl, cf_flow, cf_stock, current, stock_key)[0], f_s(A, LNA, pl, cf_flow, cf_stock, current, stock_key)[1], f_s(A, LNA, pl, cf_flow, cf_stock, current, stock_key)[2]
# 2021年3月期
summary = pd.read_csv(f'{save_path}{csv_path}{csv_l[3]}', dtype=object)
summary[column] = summary[column].astype(int)
file_path = path(edinetCode, doctypecode)
bs_p1, pl_p1, cf_p1 = f_s(A, LNA, pl, cf_flow, cf_stock, current, stock_key)[0], f_s(A, LNA, pl, cf_flow, cf_stock, current, stock_key)[1], f_s(A, LNA, pl, cf_flow, cf_stock, current, stock_key)[2]
# 2022年3月期
summary = pd.read_csv(f'{save_path}{csv_path}{csv_l[4]}', dtype=object)
summary[column] = summary[column].astype(int)
file_path = path(edinetCode, doctypecode)
bs_curr, pl_curr, cf_curr = f_s(A, LNA, pl, cf_flow, cf_stock, current, stock_key)[0], f_s(A, LNA, pl, cf_flow, cf_stock, current, stock_key)[1], f_s(A, LNA, pl, cf_flow, cf_stock, current, stock_key)[2]
数値をまとめたリストをデータフレームに変換し連結する
rakus_bs = pd.DataFrame(
data = [bs_p4_p, bs_p4, bs_p3, bs_p2, bs_p1, bs_curr],
index = ['2017-03-31', '2018-03-31', '2019-03-31', '2020-03-31', '2021-03-31', '2022-03-31'],
columns = ['流動資産合計', '有形固定資産合計', '無形固定資産合計', '投資その他の資産合計', '固定資産合計', '資産合計', '流動負債合計', '固定負債合計', '負債合計', '株主資本合計', 'その他の包括利益累計額合計', '純資産合計', '負債純資産合計']
)
rakus_pl = pd.DataFrame(
data = [pl_p4_p, pl_p4, pl_p3, pl_p2, pl_p1, pl_curr],
index = ['2017-03-31', '2018-03-31', '2019-03-31', '2020-03-31', '2021-03-31', '2022-03-31'],
columns = ['売上高', '売上原価', '売上総利益', '販売費及び一般管理費', '営業利益', '営業外収益', '営業外費用', '経常利益', '特別利益', '特別損失', '税金等調整前当期純利益', '法人税等合計', '当期純利益']
)
rakus_cf = pd.DataFrame(
data = [cf_p4_p, cf_p4, cf_p3, cf_p2, cf_p1, cf_curr],
index = ['2017-03-31', '2018-03-31', '2019-03-31', '2020-03-31', '2021-03-31', '2022-03-31'],
columns = ['小計', '利息及び配当金の受取額', '利息の支払額', '法人税等の支払額', '営業活動によるキャッシュフロー', '投資活動によるキャッシュフロー', '財務活動によるキャッシュフロー', '現金及び現金同等物に係る換算差額', '現金及び現金同等物の増減額', '現金及び現金同等物の期首残高', '現金及び現金同等物の期末残高']
)
rakus_df = pd.concat(objs=[rakus_bs, rakus_pl, rakus_cf], keys=['連結B/S', '連結P/L', '連結C/F'], axis=1)
rakus_df = rakus_df.T.reset_index()
rakus_df = rakus_df.rename(columns={'level_0': '財務諸表', 'level_1':'科目'})
rakus_df = rakus_df.set_index('財務諸表').set_index('科目', append=True).T
rakus_df['date'] = rakus_df.index
rakus_df['date'] = pd.to_datetime(rakus_df['date'])
rakus_df = rakus_df.set_index('date').T
以上のコードを実行した場合下のようなデータフレームを生成できるはず。
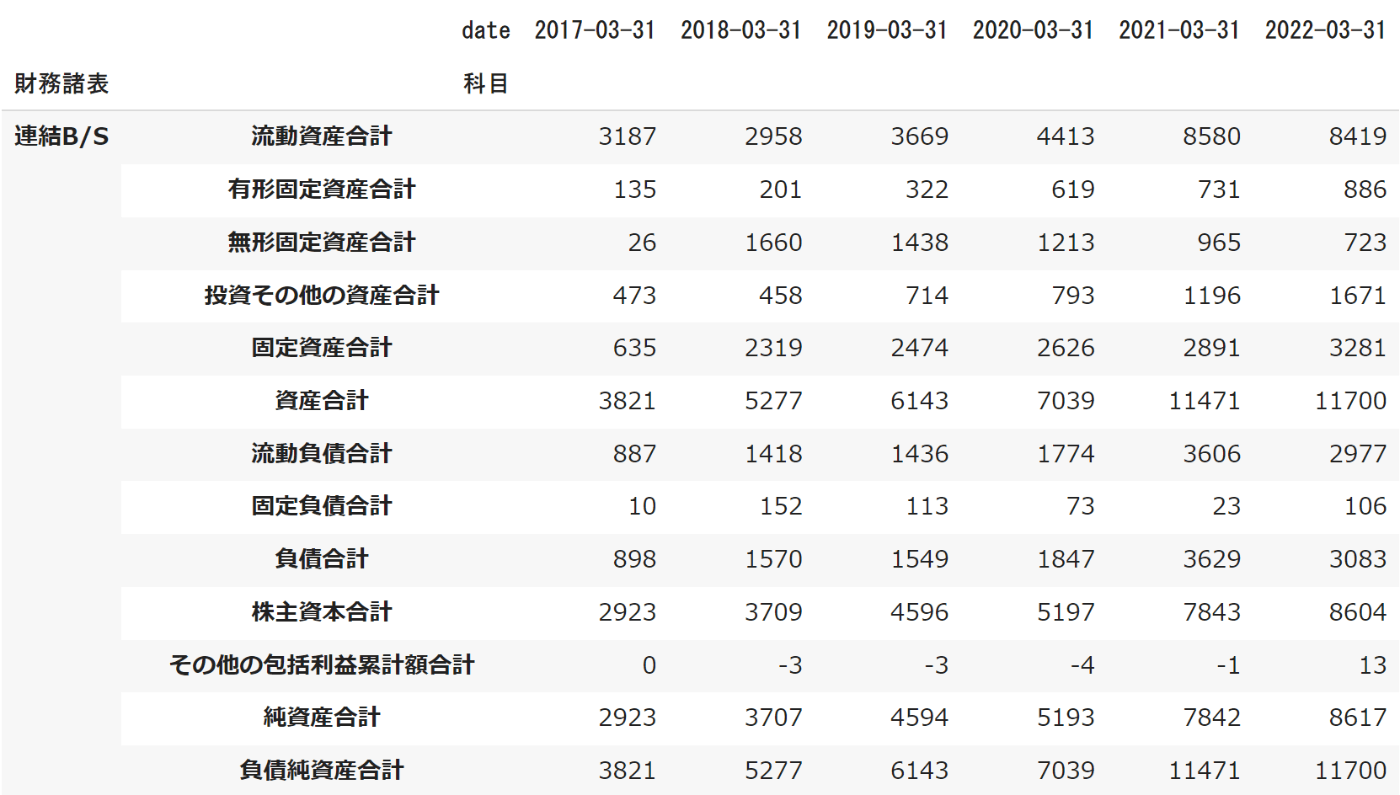
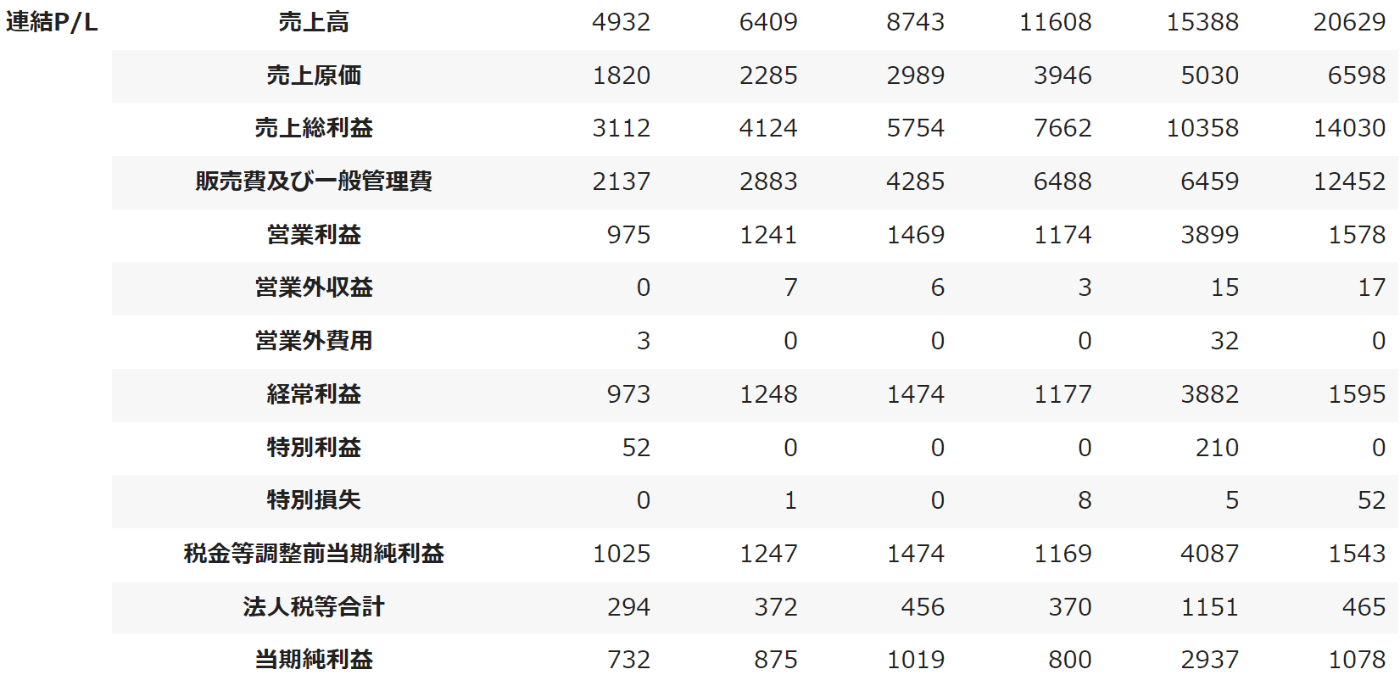
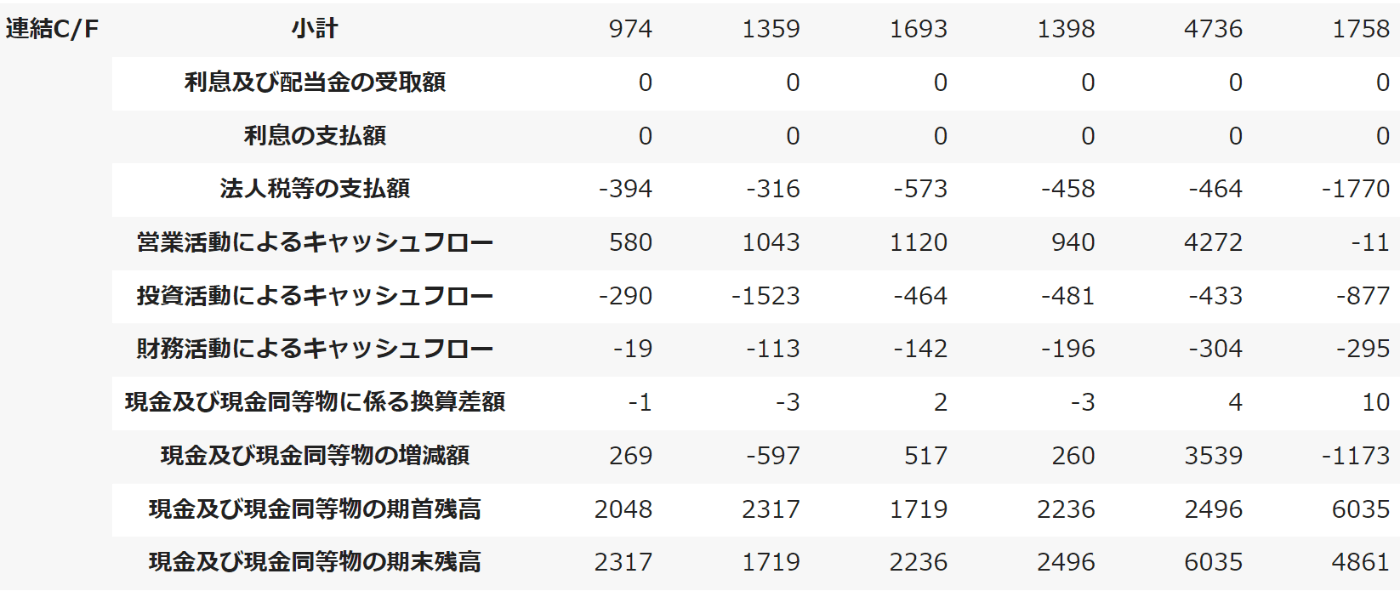
後は下のコードでCSVとしてGoogle Drive保存し、ローカル環境にダウンロードすればOK
rakus_df.to_csv(f'{save_path}rakus_fs.csv')
次回は、ダウンロードしたCSVを使いStreamlitでアプリを作成する工程に取り組みます。
Discussion