💫
Apache Sparkのことはじめ

これはなに?
Apache Sparkについて、触り始めたのでそのメモです。
環境準備
以下の記事を参考に、DockerでJupyterLabとpyspark環境を立ち上げます。
docker run -it -p 8888:8888 jupyter/pyspark-notebook
コマンド調査
データフレームを作成+集計
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg
# SparkSessionを使用してDataFrameを作成する
spark = (SparkSession
.builder
.appName("AuthorsAges")
.getOrCreate())
# DataFrameを作成する
data_df = spark.createDataFrame([
("Brooke", 20), ("Denny", 31), ("Jules", 30),
("TD", 35), ("Brooke", 25)
], ["name", "age"])
# 同じnameでグループ化し、それらのageでaggregateし、averageを算出する
avg_df = data_df.groupBy("name").agg(avg("age"))
# 最後に実行結果を表示する
avg_df.show()
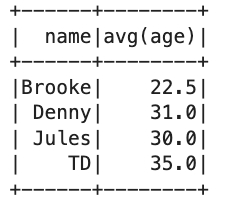
スキーマを定義してDataFrameを作成
# スキーマを定義する
from pyspark.sql import SparkSession
# DDLを使用してデータのスキーマを定義する
schema = "`ID` INT, `First` STRING, `Last` STRING, `Url` STRING, `Published` STRING, `Hits` INT, `Campaigns` ARRAY<STRING>"
# 静的データを作成する
data = [[1, "Jules", "Damji", "https://tinyurul.1", "1/4/2016", 4535, ["twitter", "LinkedIn"]]]
if __name__ == "__main__":
# SparkSessionを作成する
spark = (SparkSession
.builder
.appName("Example-3_6")
.getOrCreate())
blogs_df = spark.createDataFrame(data, schema)
blogs_df.show()
print(blogs_df.printSchema())

行 Row
# 行 Row
from pyspark.sql import Row
blog_row = Row(6, "Reynold", "Xin",["Twitter", "LinkedIn"])
print(blog_row[1])
blog_row[3][0]
Rowオブジェクトを使用して、DataFrameを作成
# Rowオブジェクトを使用して、DataFrameを作成できる
rows = [Row("MZ", "CA"), Row("RX", "CA")]
authors_df = spark.createDataFrame(rows, ["Authors", "State"])
authors_df.show()

参考
【環境構築】
Discussion