メルカリの適正価格推定
はじめに
商品や物の本当の価値を知るのは難しいと思います。
たとえば、以下のセーターの1つは335ドル、もう1つは9.99ドルです。どっちがどれなのかわかりますか?

オンラインで販売されている製品の数を考慮すると、製品の価格設定はさらに難しくなります。衣料品は季節ごとの価格動向が強く、ブランド名の影響を強く受けますが、電子機器は製品の仕様に基づいて価格が変動します。
日本最大のコミュニティ駆動のショッピングアプリは、この問題を抱えていると思います。売り手はメルカリのマーケットプレイスに何でも、またはあらゆるものを置くことができるので、売り手に適切な価格提案を提供するのは難しいです。
#Mercari Price Suggestion Challengeについて

Mercari Price Suggestion Challengeとは、実際に出品された商品データから商品の「適正価格」を推定するコンペです。商品データには商品名、商品説明、商品の状態、さらにブランド名やカテゴリ名などが含まれており、これらを基に機械学習を用いて販売価格の予測をします。
商品のデータセットは北米版メルカリより公開されているので誰でも手に入ります。
今回このデータを用いて適正価格の推定を行いたいと思います。
#データの種類

train.tsvには実際に出品された150万件の商品データがあります。北米版メルカリのデータのため表記は全て英語です。商品は8つのカラムから説明されております。
| カラム | 説明 |
|---|---|
| train_id | ユーザー投稿のID |
| name | 商品名 |
| item_condition_id | 商品の状態 |
| category_name | 商品のカテゴリ |
| brand_name | ブランド名 |
| price | 販売価格(ドル) |
| shipping | 送料負担(出品者or購入者) |
| item_description | 商品の説明 |
これらのデータをtrainとtestに分け、機械学習により販売価格の予想をします。
システム構成
- データの取得
- trian.tsv (データファイル)
- データの前処理
- 欠損処理と型変換
- 商品名、カテゴリー名から出現回数によるベクトル化
- 商品説明の特徴量抽出
- ブランド名のラベリング
- 商品状態、送料負担の量的変数化
- モデル構築
- ハイパーパラメータの最適化
- Ridge + LightGBM
- モデル評価
- データフレーム化
- 可視化
- 全体評価
実行環境はGoogle Colaboratory上で行います。データ数がものすごく多いのでGPU環境でないと時間がかかってしまいます。
Goggle Colboratoryについてはこちらを参考にしてください。
Google Colaboratory概要と使用手順(TensorFlowもGPUも使える)
精度評価方法

RSMLEは対数正規分布に近い分布、実測値と予測値の誤差を幅ではなく比率や割合として表現したい場合に用いられる。
上の図を見てみると商品価格のヒストグラムは対数正規分布のような形をしてます。
また、例えば
(1000, 5000)と(100000, 104000)の誤差の幅はお互い4000ですが、誤差の比率は異なり、この違いは大きいです。
という点から推定価格はRMSLEによる評価方法が向いてそうです。
データの前処理
train.tsvだけでなくtest.tsvも公開されているのですが、それには正解ラベルがないため、train.tsvから1万件ほど取り除いたデータをテストデータとします。
全体のデータ(1482535, 8) -> (train_df(1472535, 8), test_df(10000, 7))
##欠損処理と型変換
カテゴリ、ブランド、商品説明には空欄が多く存在します。機械学習では欠損処理をするのが普通なので以下の関数で空欄を埋めます。欠損処理を行った結果、ブランドの"missing"は全体の42%を占めていました。
def handle_missing_inplace(dataset):
dataset['category_name'].fillna(value="Other", inplace=True)
dataset['brand_name'].fillna(value='missing', inplace=True)
dataset['item_description'].fillna(value='None', inplace=True)
型変換行う前にブランドのカッティング処理を行います。ブランドの種類は約5000種類ほど存在するので出現回数が極端に少ないブランド名は学習する上であまり役に立たないので空欄と同じ"missing"を入れます。
pop_brands = df["brand_name"].value_counts().index[:NUM_BRANDS]
df.loc[~df["brand_name"].isin(pop_brands), "brand_name"] = "missing"
半分ほど削ったところ4回を最低限出現回数となりました。

テキストデータをカテゴリー型へ変換させます。これは後の処理でダミー変数化などを行うためです。
def to_categorical(dataset):
dataset['category_name'] = dataset['category_name'].astype('category')
dataset['brand_name'] = dataset['brand_name'].astype('category')
dataset['item_condition_id'] = dataset['item_condition_id'].astype('category')
##CountVectrizerによるテキスト特徴量抽出
商品名、カテゴリ名に対してCountVectorizerを適応します。CountVectorizerとは、簡単に言うと出現回数に応じてベクトル化されます。例えば 'MLB Cincinnati Reds T Shirt Size XL'、'AVA-VIV Blouse'、'Leather Horse Statues'という3つの商品名に対してCountVectorizerを行うと以下のようにベクトル化されます。

また、商品名は出品者入力のため単語の誤字脱字や、特定の文章しか出てこない固定の単語や数字が存在する可能性があります。これらを考慮し、CountVectorizerにオプションmin_dfを追加します。min_dfとは出現回数がmin_df%以下の単語は排除するといったものになります。
count_name = CountVectorizer(min_df=NAME_MIN_DF)
X_name = count_name.fit_transform(df["name"])
count_category = CountVectorizer()
X_category = count_category.fit_transform(df["category_name"])
TfidfVectorizerによるテキスト特徴量抽出
TfidfVectorizerとはCountVectorizerとは違い、単語の出現回数だけでなく単語のレア度も考慮します。例えば「です」「ます」といったどの文章にも存在する単語だったり、英語では「a」「the」のような冠詞は出現回数が大きく、CountVectorizerではこのような単語に大きく引きずられてしまいます。そうではなく単語の重要度に着目してベクトル化を行いたい場合に用いられます。
つまり、TfidfVecotrizerとは「ある文書内での出現頻度が高く、かつ、他の文書での出現頻度が低い語に高い重要度を与えるように重み付けを行う」ことです。
以上の点から、商品説明にはTfidfVectorizerによるベクトル化を行います。

すると上図のような表になり、冠詞や接続詞に強くtfidf値がついてしまっています。このような単語はやはり学習する上で意味を持たないのでstop_word='english'を指定します。
次に左図はtfidf値の下位10個を表示しています。
tfidf値が極端に小さい値はあまり意味がないので削除します。また、単語を一つに対してtfidfをとるのではなく連続した単語に対してtfidfをとるようにします。
例えば「an apple a day keeps the doctor away」(一日一個のリンゴで医者いらず)ということわざでn-gram設定してみます。
n-gram(1, 2)
{'an': 0, 'apple': 2, 'day': 5, 'keeps': 9, 'the': 11,'doctor':7,'away': 4,
'an apple': 1, 'apple day': 3, 'day keeps': 6, 'keeps the': 10,
'the doctor': 12, 'doctor away': 8}
n-gram(1, 3)
{'an': 0, 'apple': 3, 'day': 7, 'keeps': 12, 'the': 15, 'doctor': 10,'away': 6,
'an apple': 1, 'apple day': 4, 'day keeps': 8, 'keeps the': 13,'the doctor': 16,
'doctor away': 11, 'an apple day': 2, 'apple day keeps': 5, 'day keeps the': 9,
'keeps the doctor': 14, 'the doctor away': 17}
このようにn-gram範囲が増えるほどより細かく文章の特徴を捉え、有為なデータの取得をします。こうしてオプション追加により右図のようになりました。

最終的に出来上がったtfidfが下図のようになります。tfidf値が一番高いものが”description”となっており、これは”Not description yet”(概要記載なし)が影響していることがわかります。"new"や"used"といった新品、中古も値段に影響を与えていることがわかります。

tfidf_descp = TfidfVectorizer(max_features = MAX_FEAT_DESCP,
ngram_range = (1,3),
stop_words = "english")
X_descp = tfidf_descp.fit_transform(df["item_description"])
LabelBinarizerによる2値化
先ほども述べましたがブランドの種類は約5000種類存在し、カッティング処理の結果、ブランドは約2500種類となりました。
これらを 0 or 1 でラベリングします。データ数が多いのでsparse_output=Trueにして実行します。
label_brand = LabelBinarizer(sparse_output=True)
X_brand = label_brand.fit_transform(df["brand_name"])
ダミー変数化
ダミー変数とは、数字ではないデータを数字に変換する手法のことです。具体的には、数字ではないデータを「0」と「1」だけの数列に変換します。
ここでは商品の状態、送料負担についてダミー変数化を行います。
X_dummies = scipy.sparse.csr_matrix(pd.get_dummies(df[[
"item_condition_id", "shipping"]], sparse = True).values, dtype=int)
以上で全てのカラムについて処理が行えましたので全ての配列を結合し、モデルにかけます。
X = scipy.sparse.hstack((X_dummies,
X_descp,
X_brand,
X_category,
X_name)).tocsr()
モデル学習
パラメーター説明
全てのパラメータは説明仕切れないので一部のパラメータを簡単にまとめます。
Ridgeパラメータ
| option | desc |
|---|---|
| alpha | 過学習を防ぐ正規化の度合い |
| max_iter | 学習の反復の最大回数 |
| tol | tol以上のスコア上昇を条件とする |
alpha
与えられたデータに過度に適合してしまい、与えた学習データに対しては小さな誤差となるモデルが構築できるが、未知データに対する適切な予測がうまくできないことを「過学習」と言います。
そこで、パラメータの学習に制限を設けることで過学習を防ぐことができます。そのような制限を「正規化」と言います。
LightGBMパラメータ
| option | description |
|---|---|
| n_esimators | 決定木の構成数 |
| learning_rate | 各木の重み |
| max_depth | 各木の最大の深さ |
| num_leaves | 葉の数 |
| min_child_samples | 末端ノードに含まれる最小のデータ数 |
| n_jobs | 並列処理数 |
learning_rate
- 一般的にあげると精度上昇するが過学習しやすくなる
- 小さすぎると計算負荷が大きく処理に時間がかかる。
n_estimatiors
- ランダムフォレストでもっとも大切なパラメータ
ハイパーパラメータの最適化
Ridge
まずはalphaの最適値を探索します。
alphaを0.05~75の範囲で動かし、精度への影響を可視化
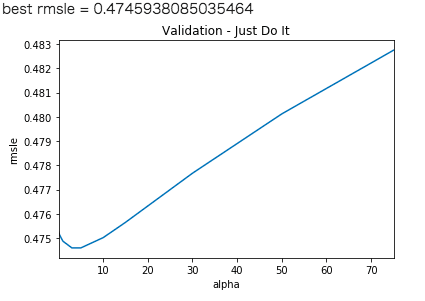
図よりalpha=3.0のとき最小値 RMSLE 0.4745938085035464 が得られました。
次に最大探索回数max_iterをあらゆる範囲で検証してみた結果、精度上昇が得られなかった。また、tol値も上げればあげるほど精度はよくなかったです。

以上からRidgeのパラメータはalpha=3でモデル作成します。
LGBM
LGBMのパラメータ調整はドキュメントなどを参考にしました。
LGBMのパラメータ調整の第一歩としてlearning_rateとn_estimatiorsの設定から始めるのが定石らしいです。
精度を高めるにはlearning_rateを小さく、n_estimatiorsを大きくするそうです。
learning_rateを0.05~0.7の範囲で動かしn_estimatiorsを調節します。
次に、learning_rateとn_estimatiorsを設定したらnum_leavesを動かしていきます。
(num_leaves = 20)
RMSLE 0.4620242411418184
↓
(num = 31)
RMSLE 0.4569169142862856
↓
(num = 40)
RMSLE 0.45587232757584967
全体的にnum_leavesを増やすと精度もよくなることがわかりました。ここでいう全体的にとは他のパラメータを調節した場合でもということです。
しかし、各パラメータを調節していく中で、num_leavesをあげすぎると過剰適合を起こし、返って良いスコアが出ないことがあった。他のパラメータとうまく調節する必要がありました。
learning_rate = 0.7 max_depth = 15, num_leaves = 30のとき
RMSLE 44.650714399639845
最終的に出来上がったLGBMモデルは以下のようになります
lgbm_params = {'n_estimators': 1000, 'learning_rate': 0.4, 'max_depth': 15,
'num_leaves': 40, 'subsample': 0.9, 'colsample_bytree': 0.8,
'min_child_samples': 50, 'n_jobs': 4}
モデル評価
予測値の算出にはRideg+LGBMで行います。RidgeよりもLGBMの方がスコアが良いのですが二つのモデルを組み合わせるのとで、より精度をあげることができます。
Ridge
RMSL error on dev set: 0.47459370995217937
LGBM
RMSL error on dev set: 0.45317097672035855
Ridge + LGBM
RMSL error on dev set: 0.4433081424824549
この精度は30ドルの商品に対して、推定値の誤差範囲は18.89 ~ 47.29です。
priceがRidge+LGBMによる予測値、real_priceが実測値になります。誤差が10ドル以内に収まったものは10000件のテストデータ中7553件ほどありました。

logをとった残差プロット

実際の価格と予測価格の分布

単純に差分をとっただけですが、予測値と実測値に100ドル以上の差額がある商品は90件ほど存在します。このデータセットは2、3年前のデータなので当時比較的新しい商品であるApple Watchなどの商品はデータ数が少なくうまく予測できていないことがわかります。
また、、個人の価値観による値段設定のため必ずしも全てはうまく予測できないです。実際にcoachのバッグが9ドルほどで売られていました…

完成したコード
import numpy as np
import pandas as pd
import scipy
from sklearn.linear_model import Ridge
from lightgbm import LGBMRegressor
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.preprocessing import LabelBinarizer
NUM_BRANDS = 2500
NAME_MIN_DF = 10
MAX_FEAT_DESCP = 10000
print("Reading in Data")
df = pd.read_csv('train.tsv', sep='\t')
print('Formatting Data')
shape = df.shape[0]
train_df = df[:shape-10000]
test_df = df[shape-10000:]
target = test_df.loc[:, 'price'].values
target = np.log1p(target)
print("Concatenate data")
df = pd.concat([train_df, test_df], 0)
nrow_train = train_df.shape[0]
y_train = np.log1p(train_df["price"])
def handle_missing_inplace(dataset):
dataset['category_name'].fillna(value="Othe", inplace=True)
dataset['brand_name'].fillna(value='missing', inplace=True)
dataset['item_description'].fillna(value='None', inplace=True)
print('Handle missing')
handle_missing_inplace(df)
def to_categorical(dataset):
dataset['category_name'] = dataset['category_name'].astype('category')
dataset['brand_name'] = dataset['brand_name'].astype('category')
dataset['item_condition_id'] = dataset['item_condition_id'].astype('category')
print('Convert categorical')
to_categorical(df)
print('Cut')
pop_brands = df["brand_name"].value_counts().index[:NUM_BRANDS]
df.loc[~df["brand_name"].isin(pop_brands), "brand_name"] = "missing"
print("Name Encoders")
count_name = CountVectorizer(min_df=NAME_MIN_DF)
X_name = count_name.fit_transform(df["name"])
print("Category Encoders")
count_category = CountVectorizer()
X_category = count_category.fit_transform(df["category_name"])
print("Descp encoders")
tfidf_descp = TfidfVectorizer(max_features = MAX_FEAT_DESCP,
ngram_range = (1,3),
stop_words = "english")
X_descp = tfidf_descp.fit_transform(df["item_description"])
print("Brand encoders")
label_brand = LabelBinarizer(sparse_output=True)
X_brand = label_brand.fit_transform(df["brand_name"])
print("Dummy Encoders")
X_dummies = scipy.sparse.csr_matrix(pd.get_dummies(df[[
"item_condition_id", "shipping"]], sparse = True).values, dtype=int)
X = scipy.sparse.hstack((X_dummies,
X_descp,
X_brand,
X_category,
X_name)).tocsr()
print("Finished to create sparse merge")
X_train = X[:nrow_train]
X_test = X[nrow_train:]
model = Ridge(solver='auto', fit_intercept=True, alpha=3)
print("Fitting Rige")
model.fit(X_train, y_train)
print("Predicting price Ridge")
preds1 = model.predict(X_test)
def rmsle(Y, Y_pred):
assert Y.shape == Y_pred.shape
return np.sqrt(np.mean(np.square(Y_pred - Y )))
print("Ridge RMSL error on dev set:", rmsle(target, preds1))
def rmsle_lgb(labels, preds):
return 'rmsle', rmsle(preds, labels), False
train_X, valid_X, train_y, valid_y = train_test_split(X_train, y_train, test_size=0.3, random_state=42)
lgbm_params = {'n_estimators': 1000, 'learning_rate': 0.4, 'max_depth': 15,
'num_leaves': 40, 'subsample': 0.9, 'colsample_bytree': 0.8,
'min_child_samples': 50, 'n_jobs': 4}
model = LGBMRegressor(**lgbm_params)
print('Fitting LGBM')
model.fit(train_X, train_y,
eval_set=[(valid_X, valid_y)],
eval_metric=rmsle_lgb,
early_stopping_rounds=100,
verbose=True)
print("Predict price LGBM")
preds2 = model.predict(X_test)
print("LGBM RMSL error on dev set:", rmsle(target, preds2))
preds = (preds1 + preds2) / 2
print("Ridge + LGBM RMSL error on dev set:", rmsle(target, preds))
test_df["price1"] = np.expm1(preds1)
test_df['price2']=np.exp(preds2)
test_df['price']= np.expm1(preds)
test_df['real_price'] = np.expm1(target)
まとめ
適正価格の推定を行った結果、予想以上に良いスコアが得られました。前処理の部分でmin_dfの値や、n-gramの範囲設定などを変えたり、文章をただtfidfにかけるだけでなくもっと細かな修正を加えたりすれば精度はもう少しよくなったのかなと思います。
Discussion