Athenaを使ってCSVファイルを読み込んでみよう
はじめに
大量のデータがテキストやCSVなどの形式で用意されている場合、それらの検索や集計を手動で行うのは少し大変になります。ExcelやGoogleスプレッドシートなどに取り込む方法もありますが、複雑な条件になってくると、これらのツールでも難しいところがあります。データベースの操作を行うSQLを使用すればある程度容易になりますが、そのためにデータベースを作り、csvファイルを格納する仕組むを構築する必要があります。
そこで、Amazon Athenaというサービスを利用することで、CSVファイルをそのままデータベースのテーブルとして扱い、SQLを使ってデータの検索などを行うことができます。物理的なデータベースを作成する必要はなく、CSVファイルをAmazon S3のバケット(AWSが用意しているストレージ領域)に格納するだけで、データの参照が可能となります。
この記事では、S3バケットに格納したCSVファイルを、Athenaから検索するための方法を紹介します。
この記事で扱う内容
この記事では、手動で作成したテスト用のCSVファイルをS3バケットに格納し、それをAthenaのテーブルから参照して、データの検索を行う流れを、ハンズオン形式で紹介しています。

この記事の対象者
AWSについて多少の知識や興味があり、データの分析を行ってみたい方を対象にしています。
記事を読む上で前提となる知識はありませんが、データベースの操作に使うSQLという言語については説明を省略しています。ただし、SQLを知らない場合も読める内容はなっています。
またハンズオンを実施する上で、AWSアカウントを所有していることを前提としています。
1. csvファイルをS3バケットに格納
まずは、Athenaで抽出するためのCSVファイル格納するためのS3バケットを作成し、そこにCSVファイルを格納していきます。
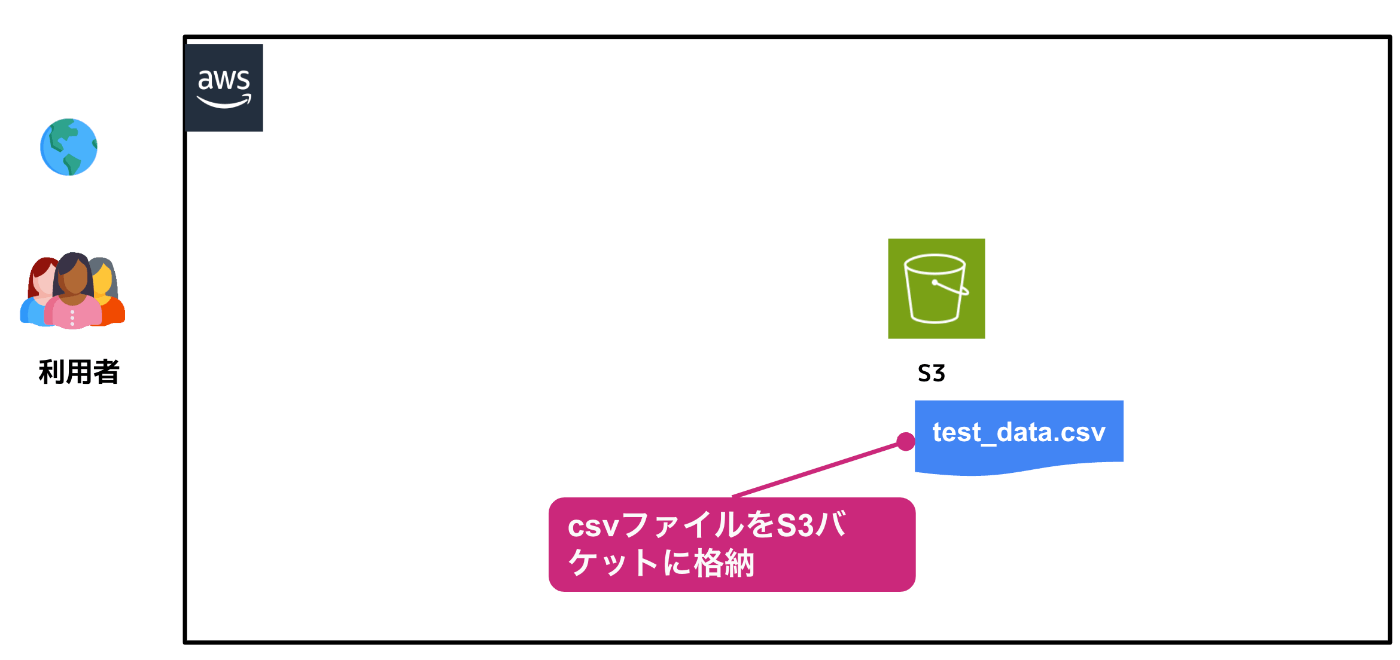
1.1 CSVファイルの準備
まずは、Athanaで抽出を行うためのcsvファイルを作成します。以下のようなcsvファイルを作成し、test_data.csvというファイル名で保存します。
id,name,birthday,mail_address
1,テスト太郎,1983/01/01,test1@gmail.com
2,テスト二郎,1993/01/01,test2@gmail.com
3,テスト三郎,2003/01/01,test3@gmail.com
1.2 S3バケットの作成
CSVファイルを格納するために、S3バケットを作成していきます。今回はS3がメインの記事ではないため、S3の細かい説明は省略しています。
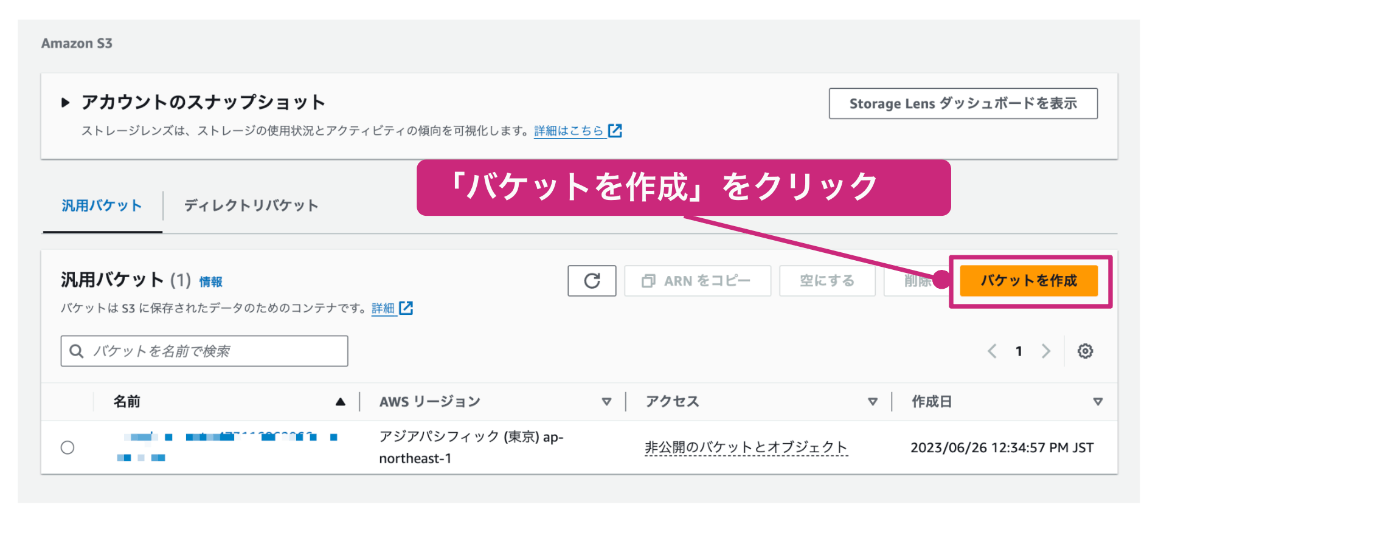
AWS管理コンソールにて、右上の検索ボックスにS3と入力し、表示されるメニューからS3を選択します。

S3バケットの一覧画面が表示されるので、「バケットを作成」をクリックします。
バケット名を入力します。バケット名は任意の文字越で構いませんが、全世界で他のユーザと重ならないような名前にする必要があります。ここでは、aws-athena-test-20231224という名称にしています。

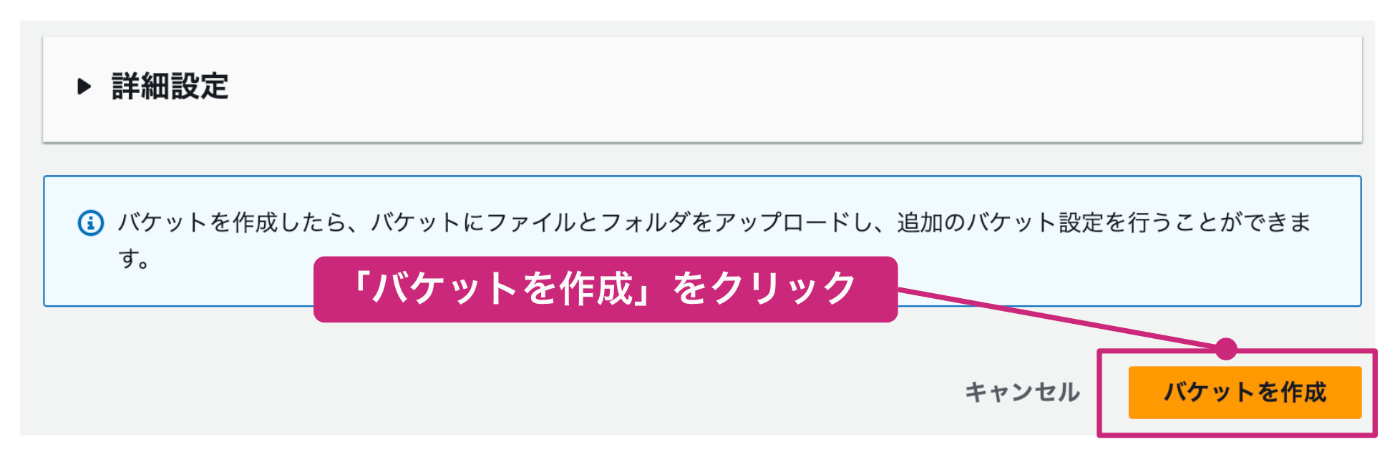
バケット名以外の項目は、デフォルトの内容で構いません。入力が完了したら画面の一番下までスクロールし、「バケットを作成」をクリックします。
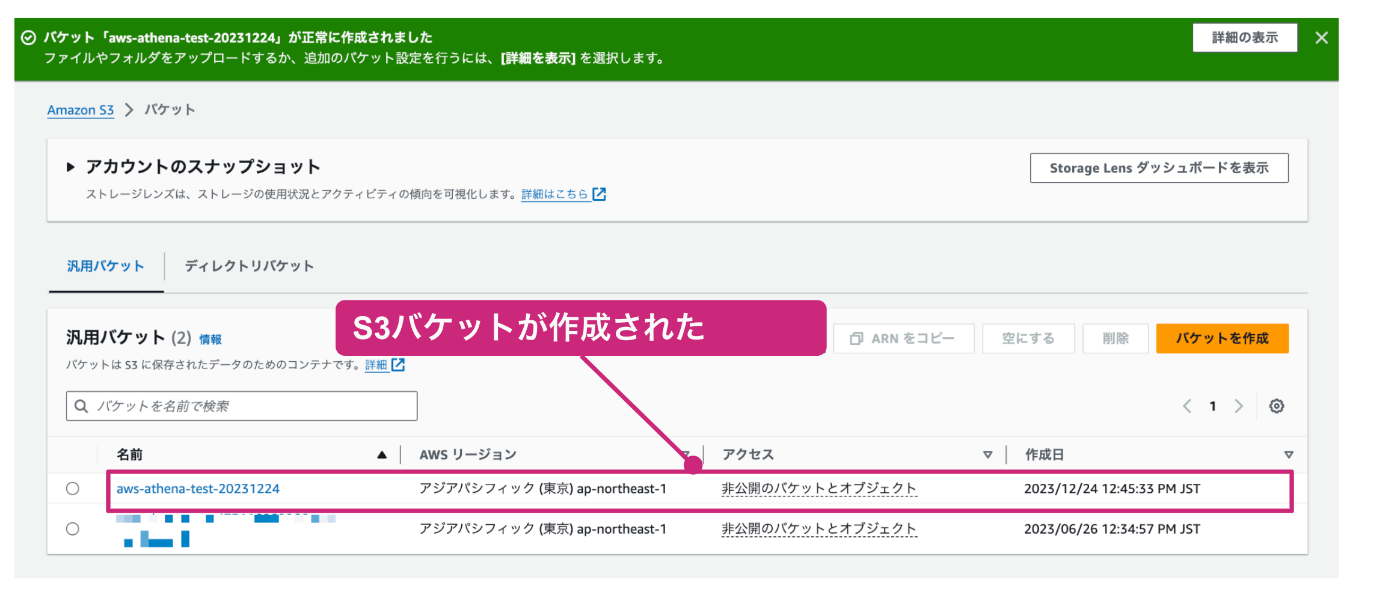
S3バケットの一覧が表示されるので、正常終了のメッセージが表示され、S3バケットが作成されていれば成功です。
1.3 csv格納フォルダを作成
S3バケットが作成されたので、次にデータを格納するためのフォルダを作成します。厳密にはフォルダを作成しなくてもAthenaからの参照ができますが、Athenaではフォルダ単位でデータの格納先を指定するため、事前にフォルダを作成しておくと便利です。
S3バケットの一覧から、先程作成したバケット名をクリックします。
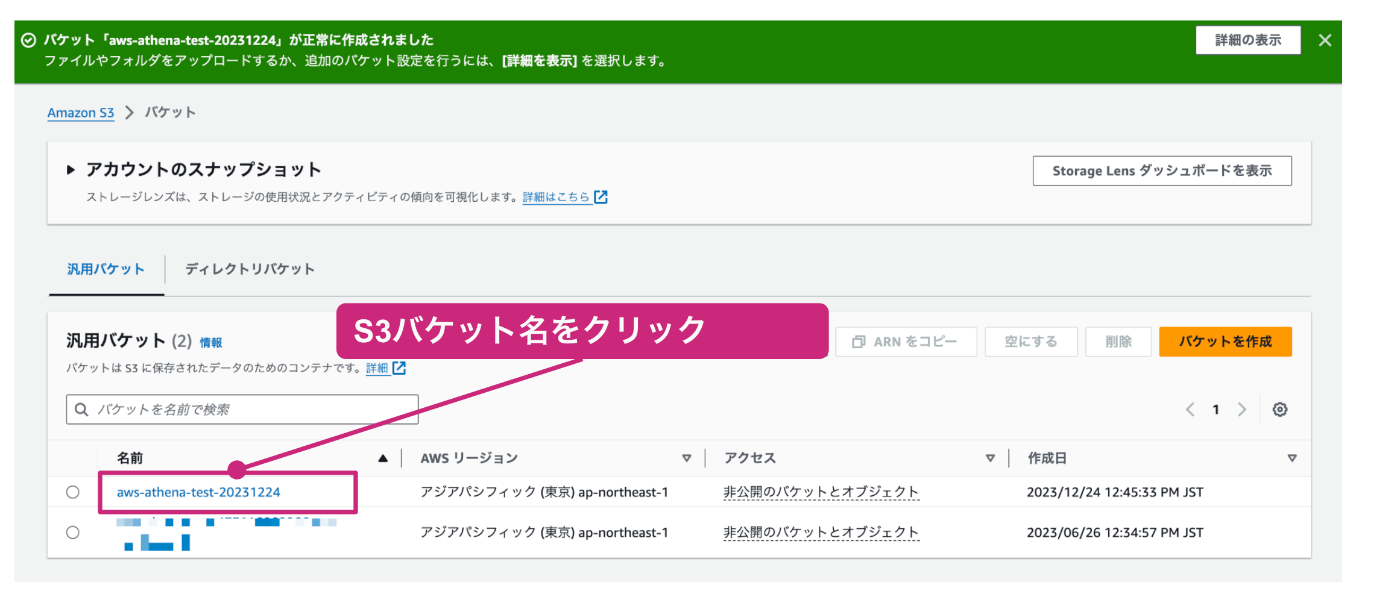
S3バケットの詳細画面が表示されるので、「フォルダの作成」をクリックします。
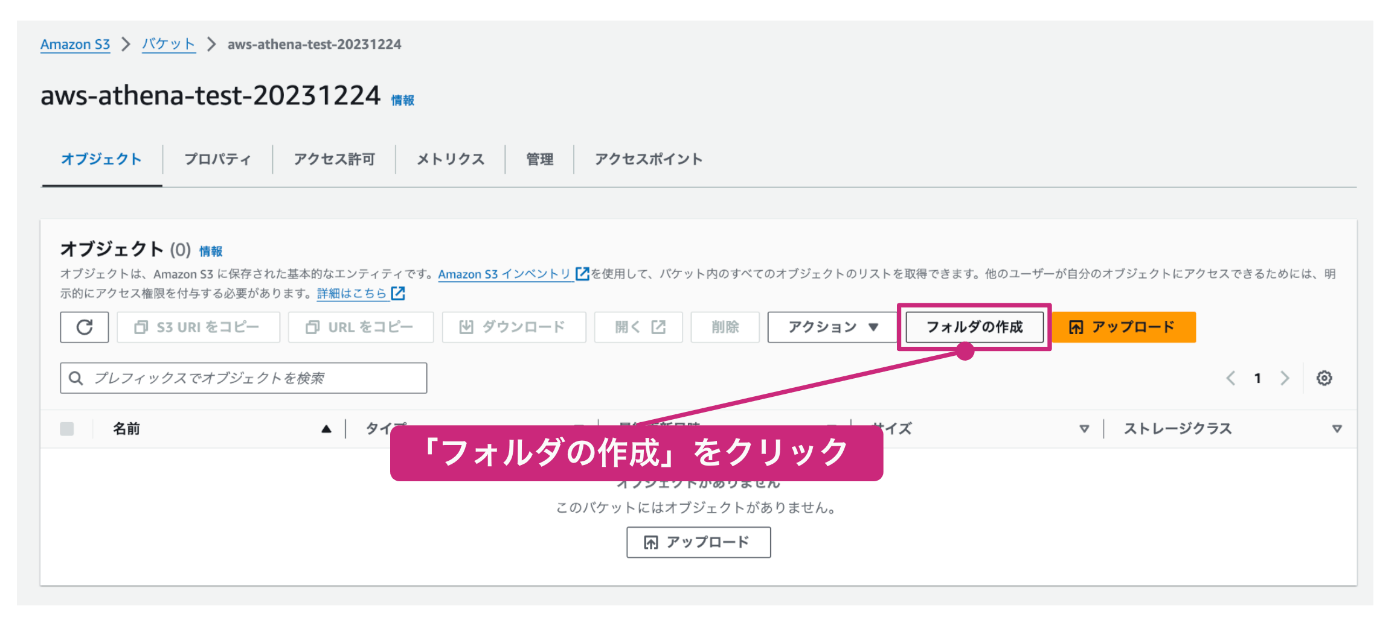
任意のフォルダ名を入力します。ここではcsv_dataというフォルダ名にしています。他の項目はデフォルトのままで構いませんので、入力が完了したら「フォルダの作成」をクリックします。
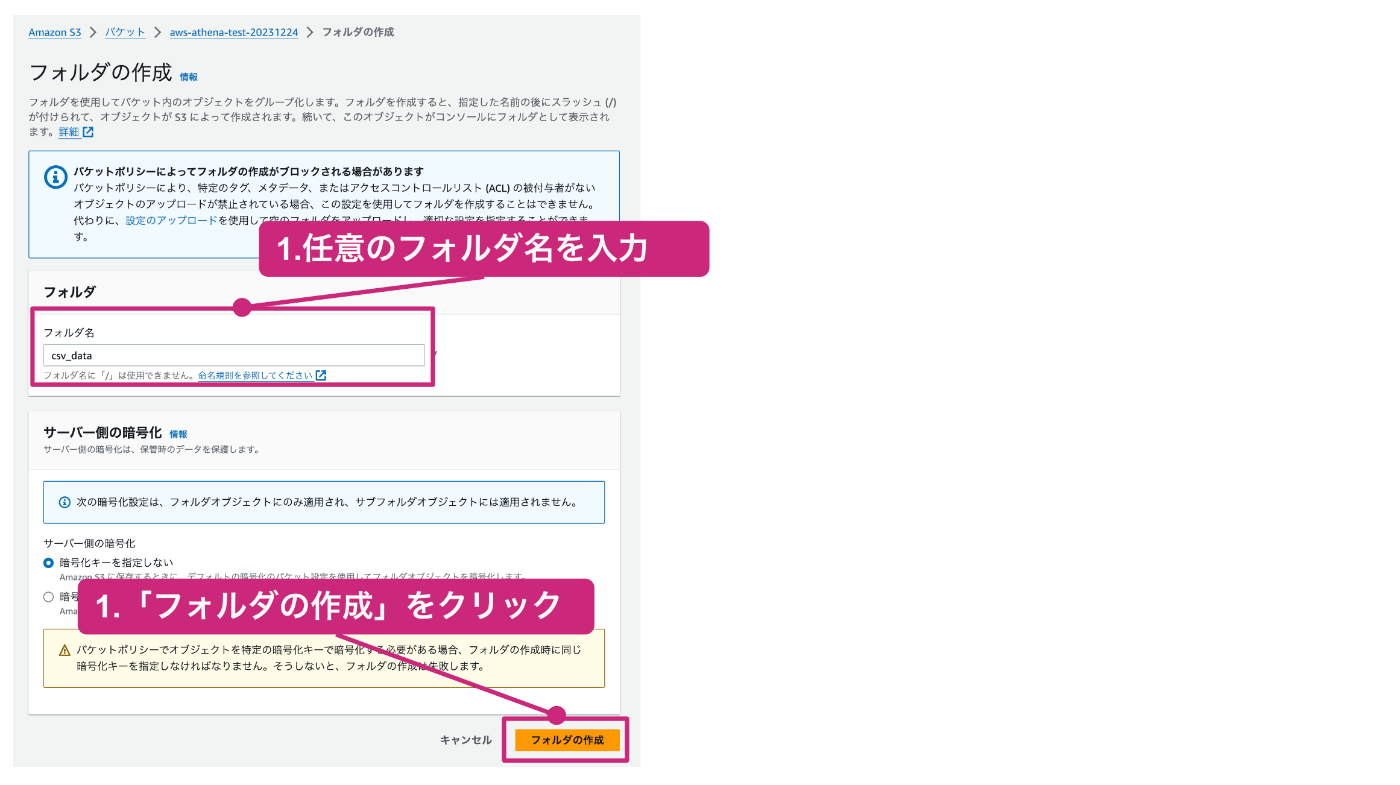
以下のように、csv_dataというフォルダが作成されたら成功です。
1.4 CSVファイルのアップロード
続いて、先程作成したcsvファイルをS3バケットにアップロードしていきます。
まずはcsv_dataのフォルダをクリックして、詳細画面を開きます。
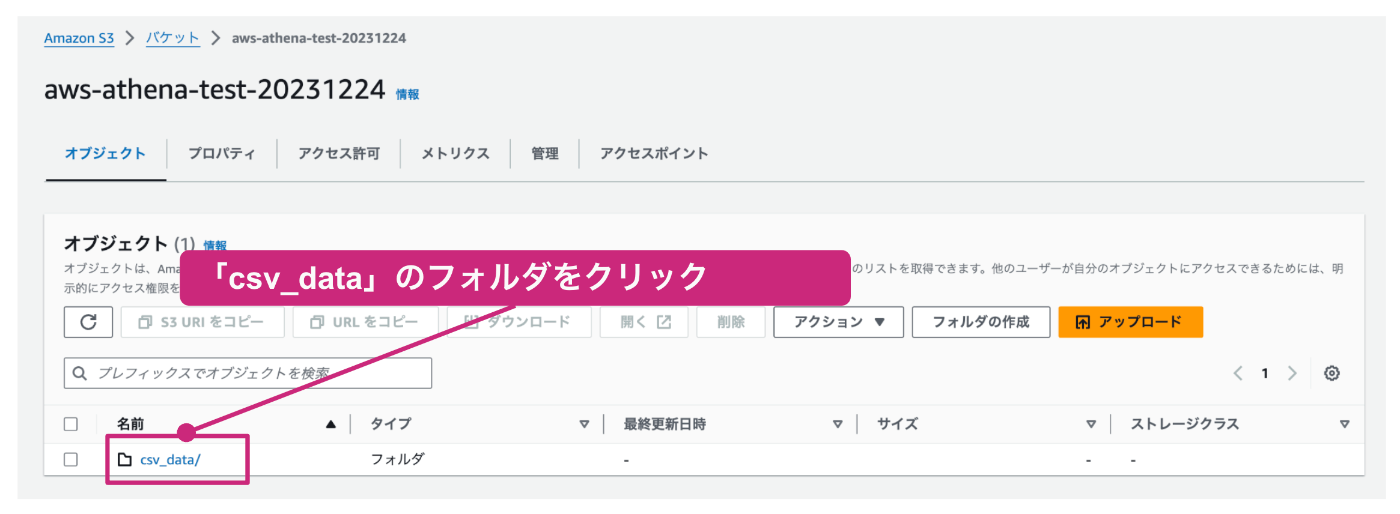
csv_dataフォルダの詳細画面が開かれている状態で、「アップロード」をクリックします。
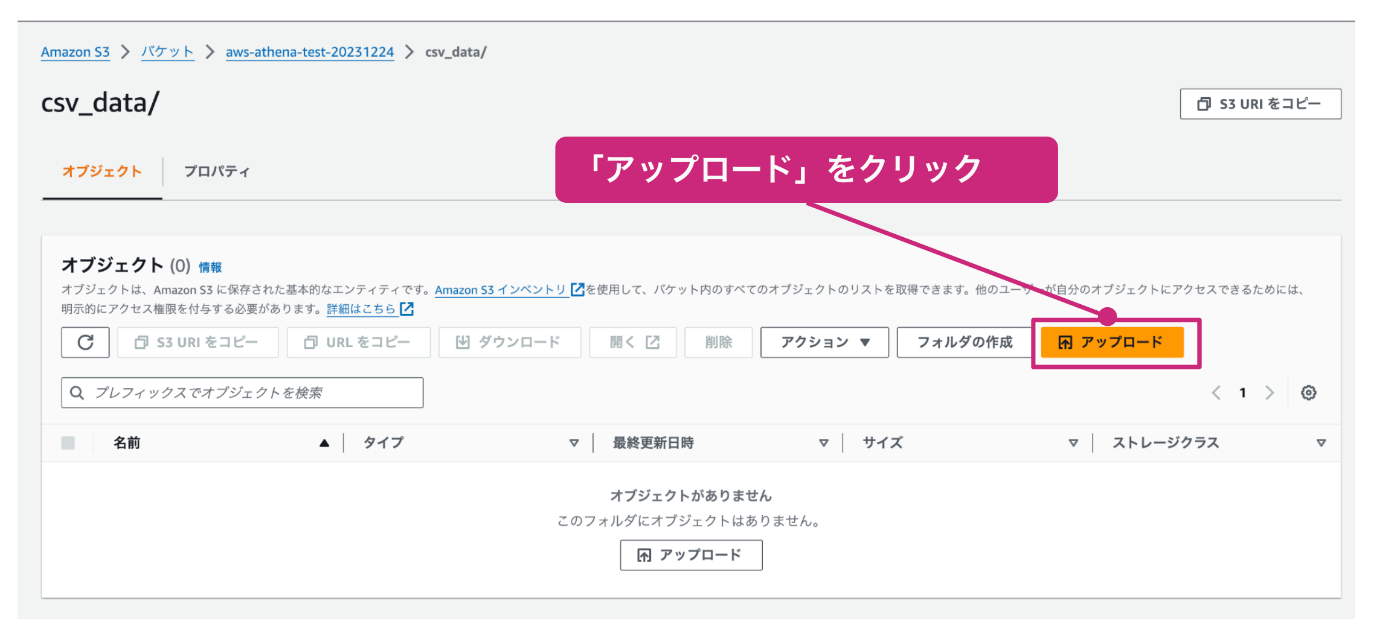
「ファイルを追加」をクリックすると、ファイルを選択する画面が表示されるので、作成したtest_data.csvを選択します。その後、「アップロード」をクリックします。

以下のように、正常終了のメッセージが表示され、test_data.csvがアップロードされれば成功です。
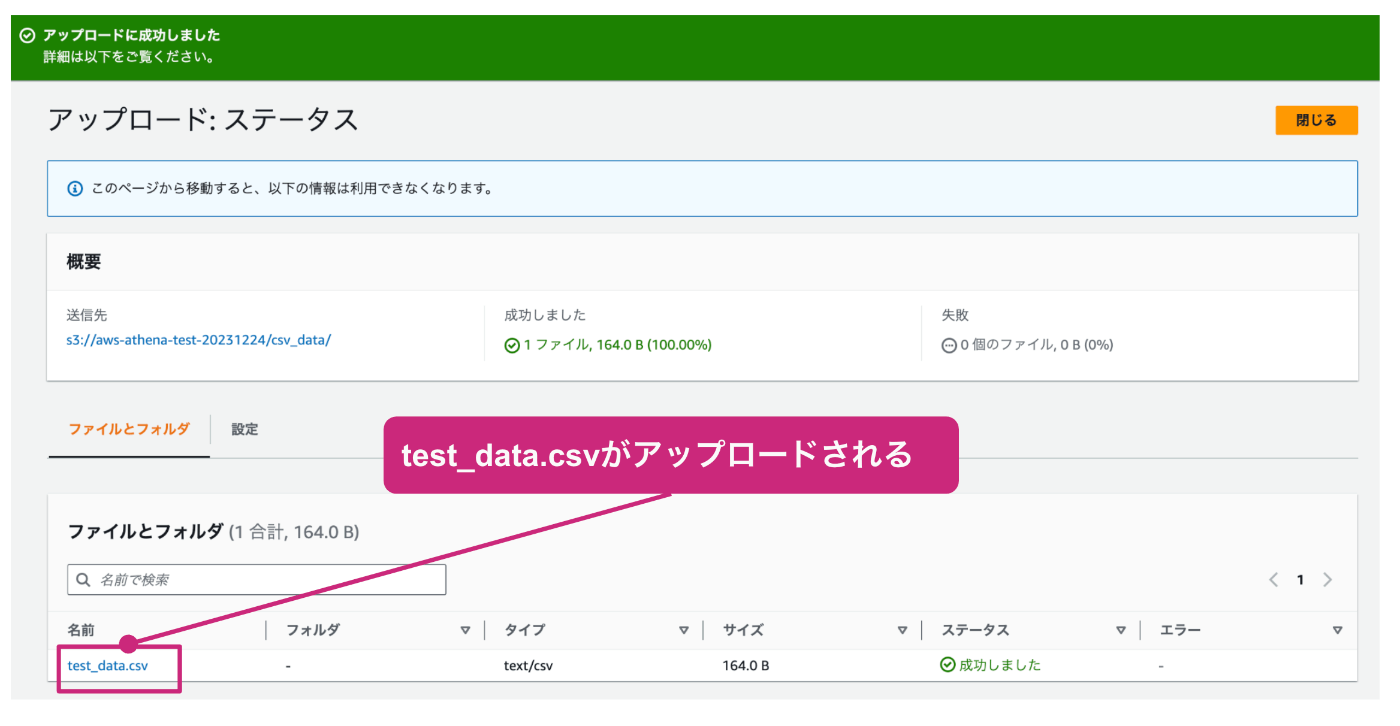
以上の操作で、Athenaから参照するためのcsvの容易が完了しました。
2. Athenaのテーブルを定義
続いて、Athenaで参照するためのテーブルを定義し、実際にデータの検索を行っていきたいと思います。

2.1 クエリエディタを選択
AWS管理コンソールにて、右上の検索ボックスにAthenaと入力し、表示されるメニューからAthenaと入力します。

左側のメニューから「クエリエディタ」を選択します。

2.2 SQLの作成
Athenaのテーブルは、SQLを使用して作成することができます。以下のようなCreate TableのSQLを用意してテーブルを作成します。基本は通常のSQL文と同じ構文ですが、一部Athena特有の設定などが記載されています。
CREATE EXTERNAL TABLE IF NOT EXISTS test_table (
`id` int,
`name` string,
`birthday` date,
`mail_address` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://aws-athena-test-20231224/csv_data/'
TBLPROPERTIES ('skip.header.line.count'='1');
SQLの解説を行っていきたいと思います。
CREATE EXTERNAL TABLE IF NOT EXISTS test_table (
`id` int,
`name` string,
`birthday` date,
`mail_address` string
)
これは通常のSQLのCreate文と同様の文法となります。
CREATE EXTERNAL TABLEは、外部のデータソースに格納されたデータに対して、テーブルを作成するコマンドです。今回はS3バケットに保存されたデータソース(CSVファイル)を参照するため、この記載となります。
IF NOT EXISTSは、テーブルがまだ存在していない場合のにみ、テーブルの作成を行います。
test_tableはテーブル名となります。今回はtest_tableという名前にしていますが、別のテーブル名にしたい場合は、ここを変更する必要があります。
id intなどの部分は、項目の定義です。CSVファイルの項目に合わせて記載することで、Athena側で項目と値を紐づけしてくれます。
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
これは、Hiveにおけるデータの設定を表します。Hiveは、Apacheによって開発されたデータ処理の仕組みの一つで、Athenaにおいてもデータ読み込みに利用されます。
ROW FORMAT SERDEは、テーブルの行をどのように読み込むかを指定します。
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'は、Hiveの読み込み方法の一つで、CSVファイルなどのシンプルなテキスト区切りのフォーマットを効率的に処理できる読み込み方法です。
つまり、この指定により「CSVファイルを効率的に読み込む」という読み込み方法の指定が行われています。
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://aws-athena-test-20231224/csv_data/'
TBLPROPERTIES ('skip.header.line.count'='1');
この部分は、Hiveでテーブルを作成する際に使用できる「オプション」を示しています。
WITH SERDEPROPERTIESは、データの読み書きに関する詳細を定義できます。'serialization.format' = ',': は、データをテーブルに書き込む際の区切り文字を「カンマ」として定義します。'field.delim' = ','は、ファイルを読み込む際の区切り文字を「カンマ」として定義します。これらの指定により、今回のような「カンマ区切り」のCSVファイルを読み込むことができます。
LOCATION 's3://aws-athena-test-20231224/csv_data/'は、読み込みを行うデータの格納場所を定義しています。今回はs3://aws-athena-test-20231224/というバケットの、csv_dataというフォルダにデータが格納されていることを表しています。aws-athena-test-20231224は、ご自身のS3バケット名に変更していただく必要があります。
TBLPROPERTIES ('skip.header.line.count'='1');は、最初の1行を読み飛ばすという設定です。今回、最初の1行目はタイトル行としているため、この設定が必要になります。
2.3テーブルを作成するSQLを実行する
SQLの用意ができたので、そのSQLを実行して、テーブルの作成を行っていきます。
クエリエディタの右中央部分にSQLを記載するエディタがあるので、そこに先程作成したCreate TableのSQLを記載します。その後、「実行」をクリックします。
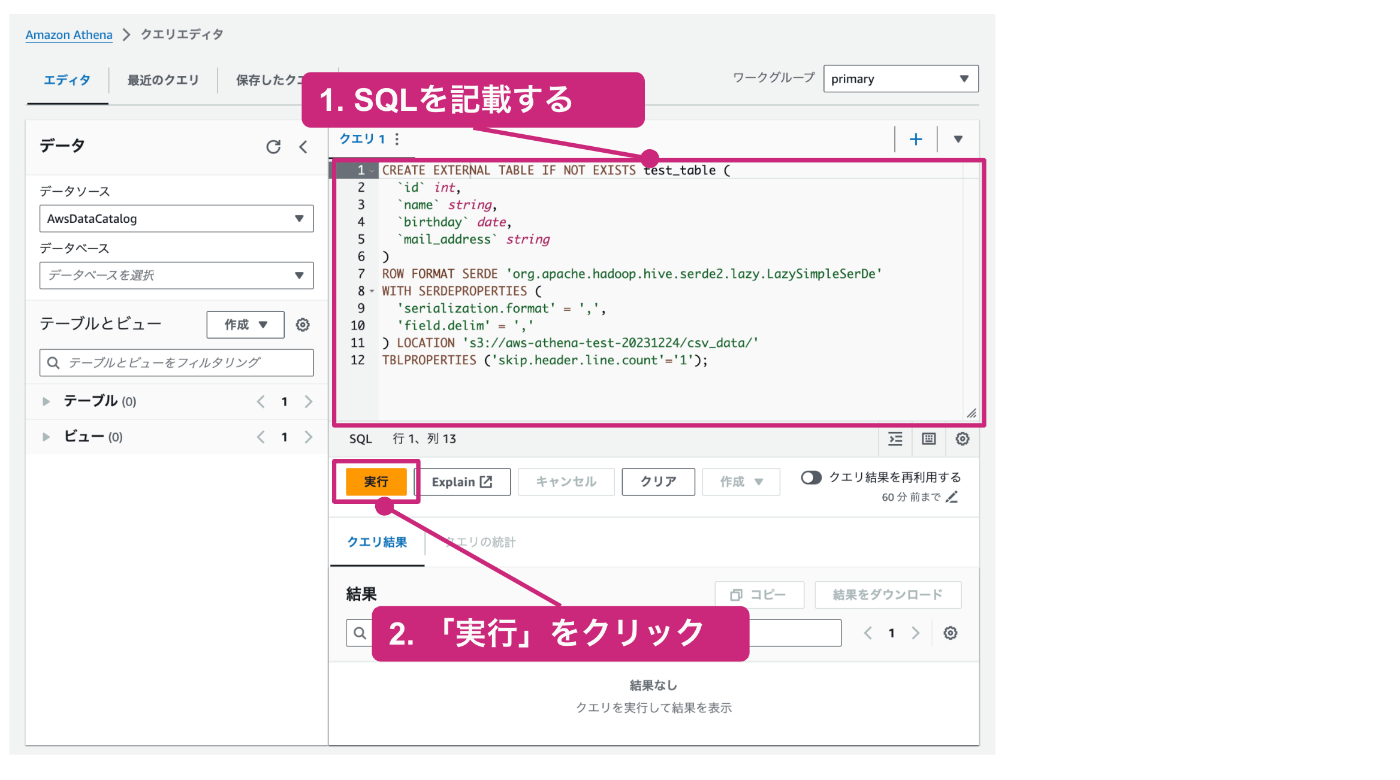
正常に終了すると、下記画面のように正常終了のメッセージが表示され、右側のテーブルの一覧に、test_tableが表示されます。
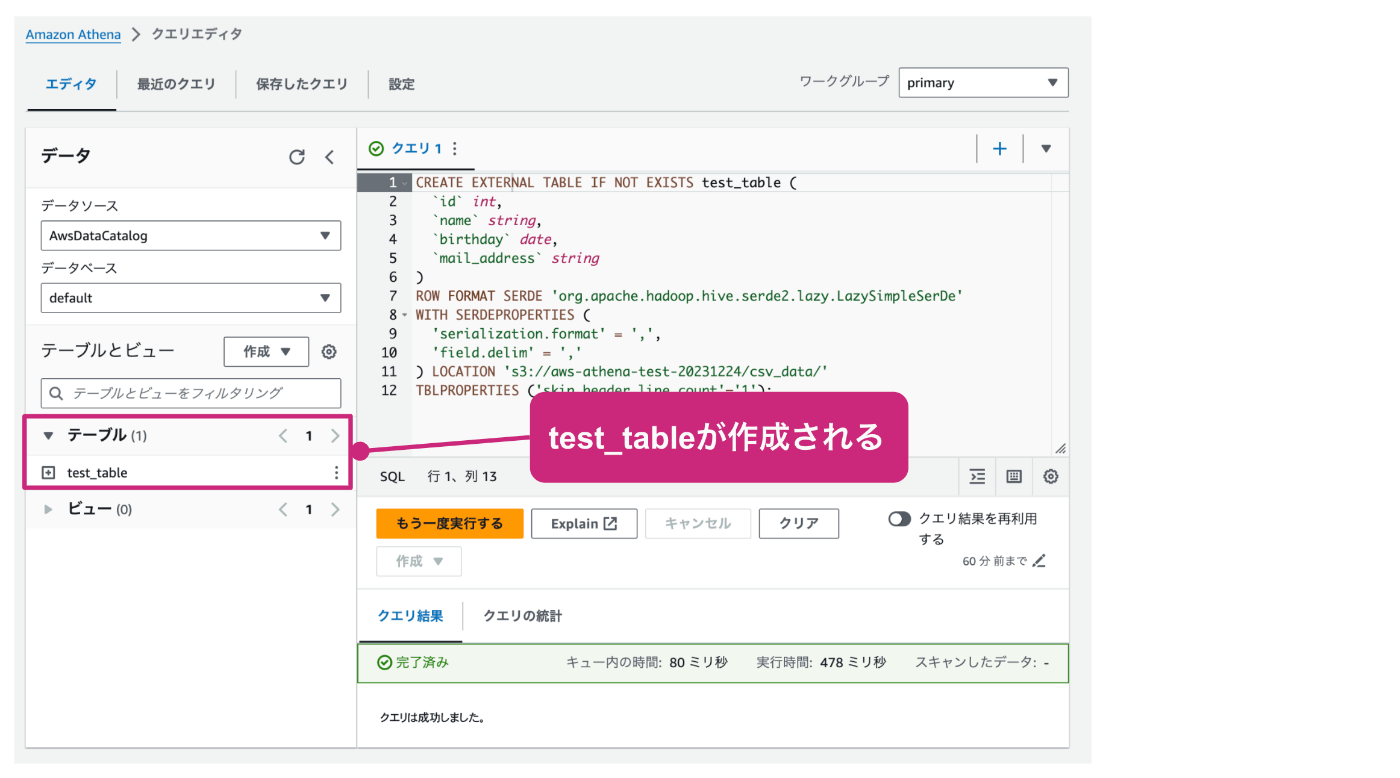
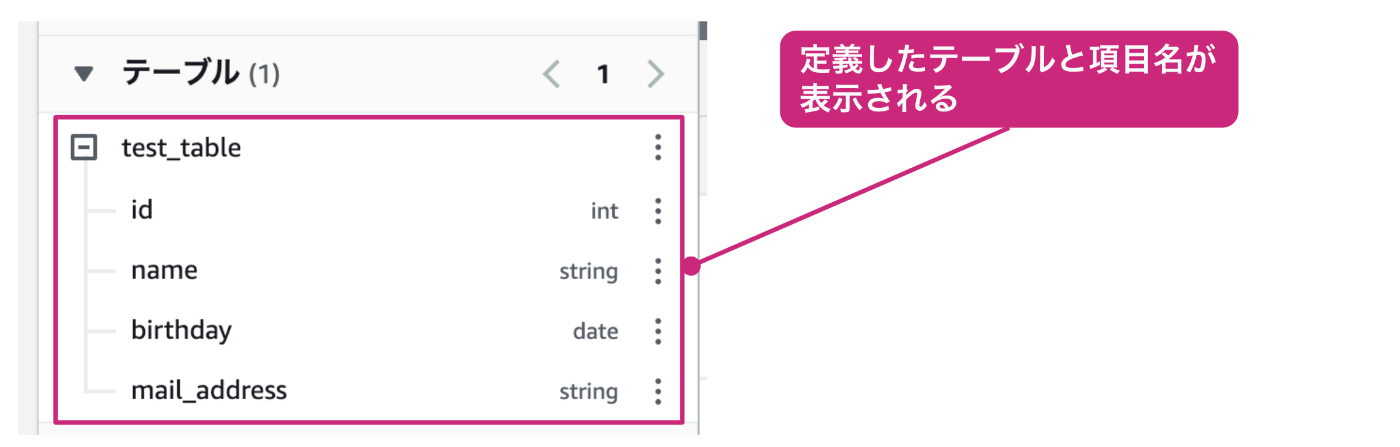
また、テーブル名の右側にある + の記号をクリックすると、テーブルが展開され、定義した項目の通りに項目名が表示されることを確認できます。
2.4 データを抽出してみる
テーブルのデータが無事に抽出されているかを確認するために、実際にSelectのSQLを実行して結果を確認してみます。SelectのSQLは、通常のSQL文の内容で問題ありません。
下記のSQLを実行し、test_tableのデータを全件表示してみます。
select * from test_table;
右中央にあるエディタ部分に、上記のSQLを記載し、「実行」をクリックします。

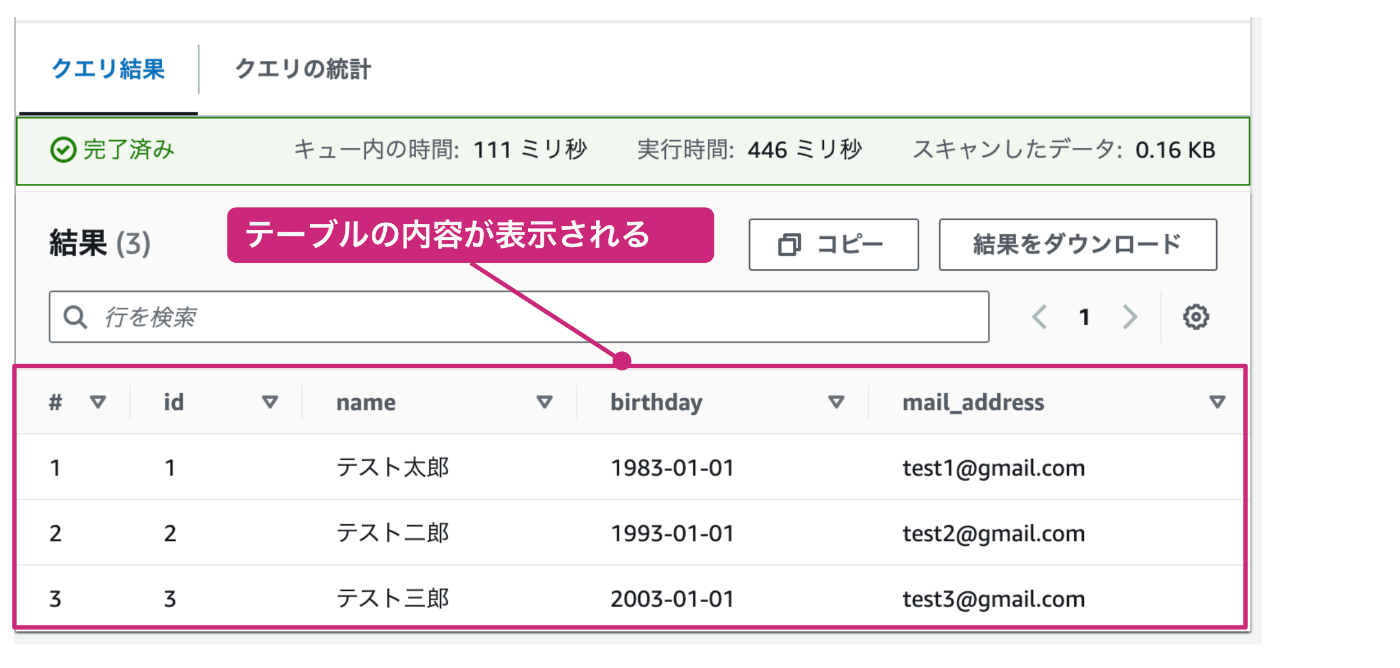
正常に実行されると、下部分にテーブルの内容が表示されます。この内容が、用意したcsvファイルの内容と一致していれば、ここまでの操作が無事完了したこととなります。
3.リソースを削除する
AWSのリソースはそのまま保持していると料金が発生してしまうため、最後にリソースの削除を行っていきます。なお今回は練習用のため削除を行いますが、実際の運用で使用したい場合は、当然ながら削除しなくても問題ありません。
3.1 Athenaのテーブルを削除
まずは、作成したAthenaのテーブルを削除します。テーブルの削除は、SQLのDrop文を作成することで実施できます。
以下のようなDropのSQLを用意しました。これを実行していきたいと思います。
drop table test_table;
エディタ部分に上記のSQLを記載し、「実行」をクリックします。
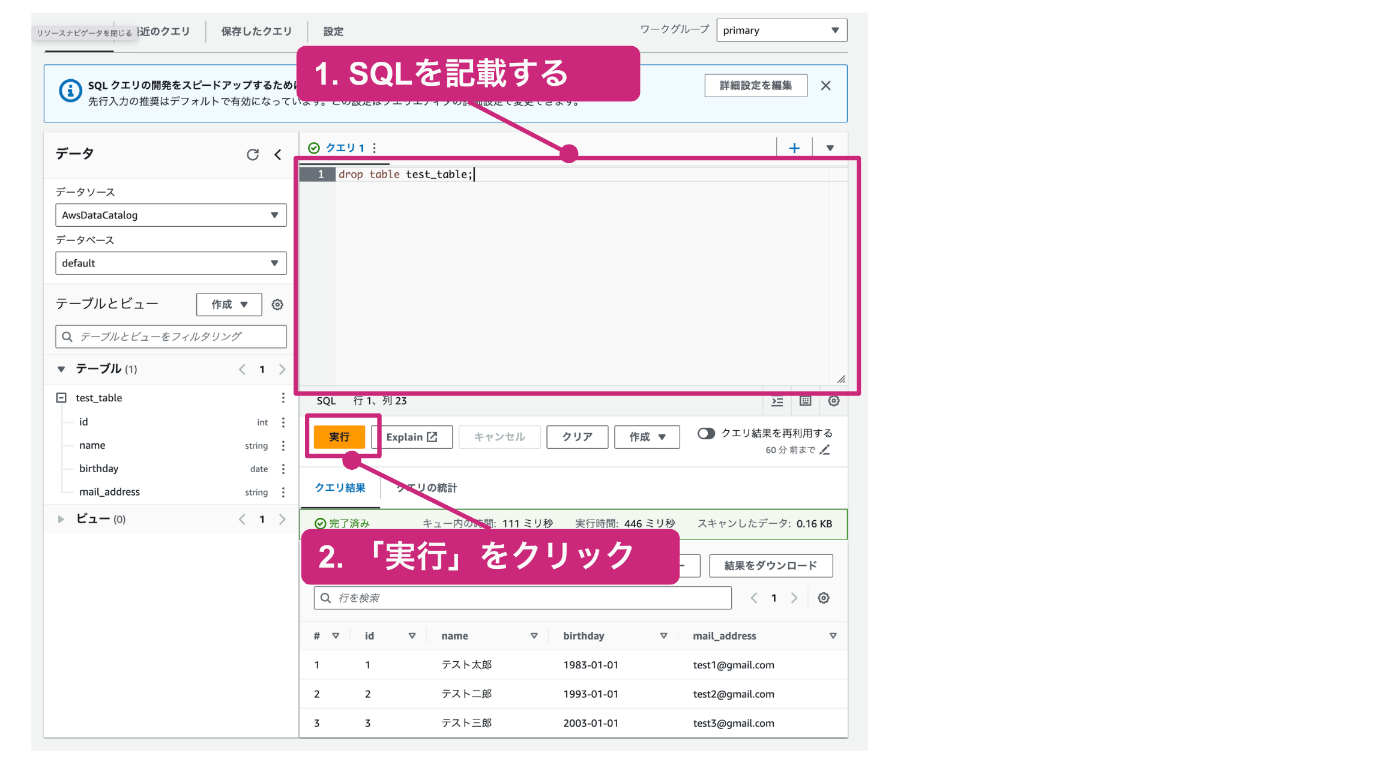
正常に実行されると、左側にあるテーブルの一覧から、test_tableが削除されます。
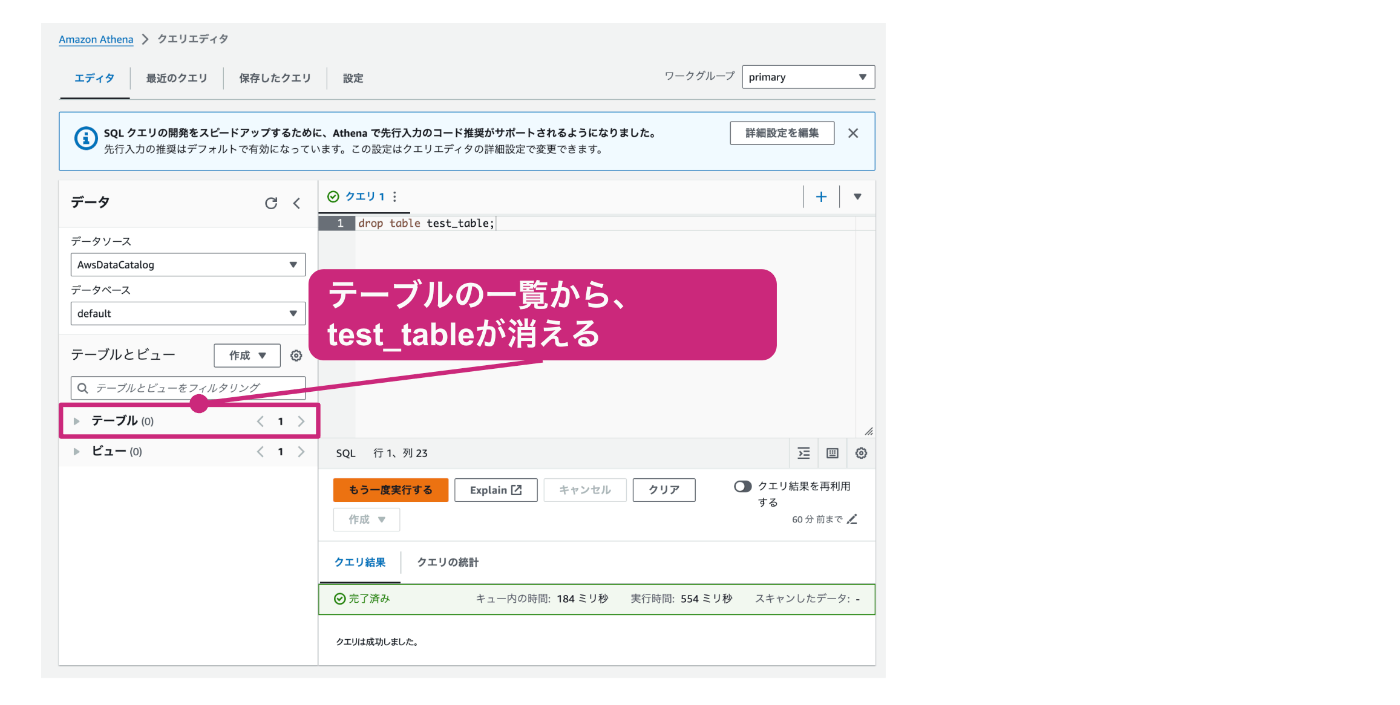
以上の操作で、Athenaのテーブルを削除することができました。
3.2 S3バケットを空にする
続いて、S3バケットに格納されているデータを削除していきます。
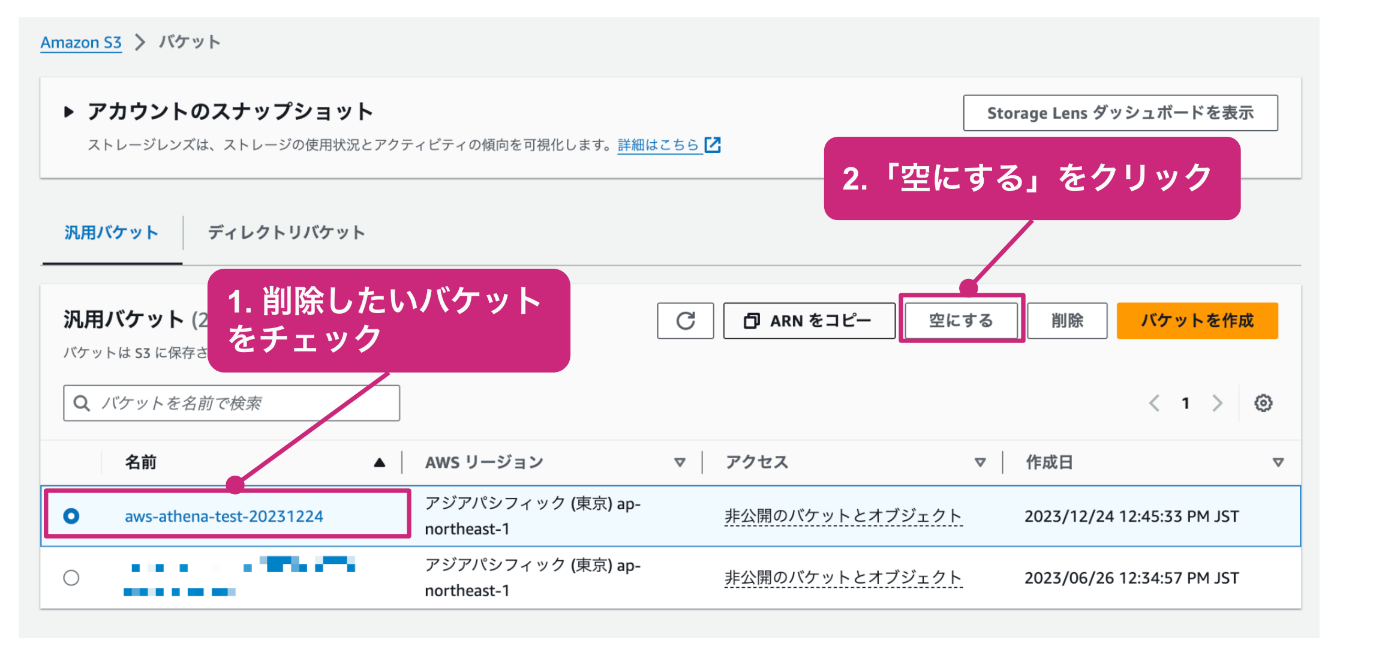
S3バケットの一覧を開き、削除したいバケットをチェックし、「空にする」をクリックします。
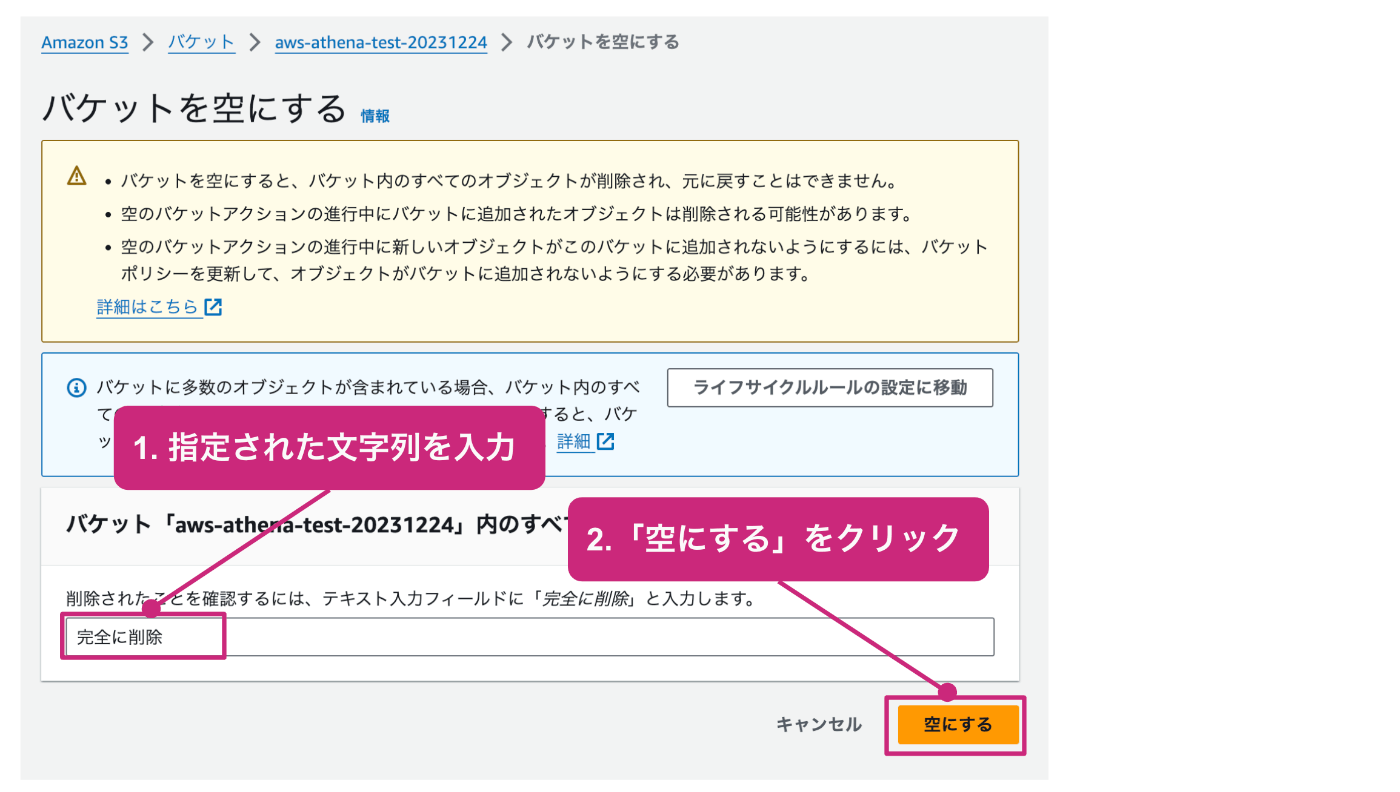
確認用のテキストの入力を促されるので、指定された文字列を入力した上で、「空にする」をクリックします。
正常に終了すると、以下のように正常終了を示すメッセージが表示されます。
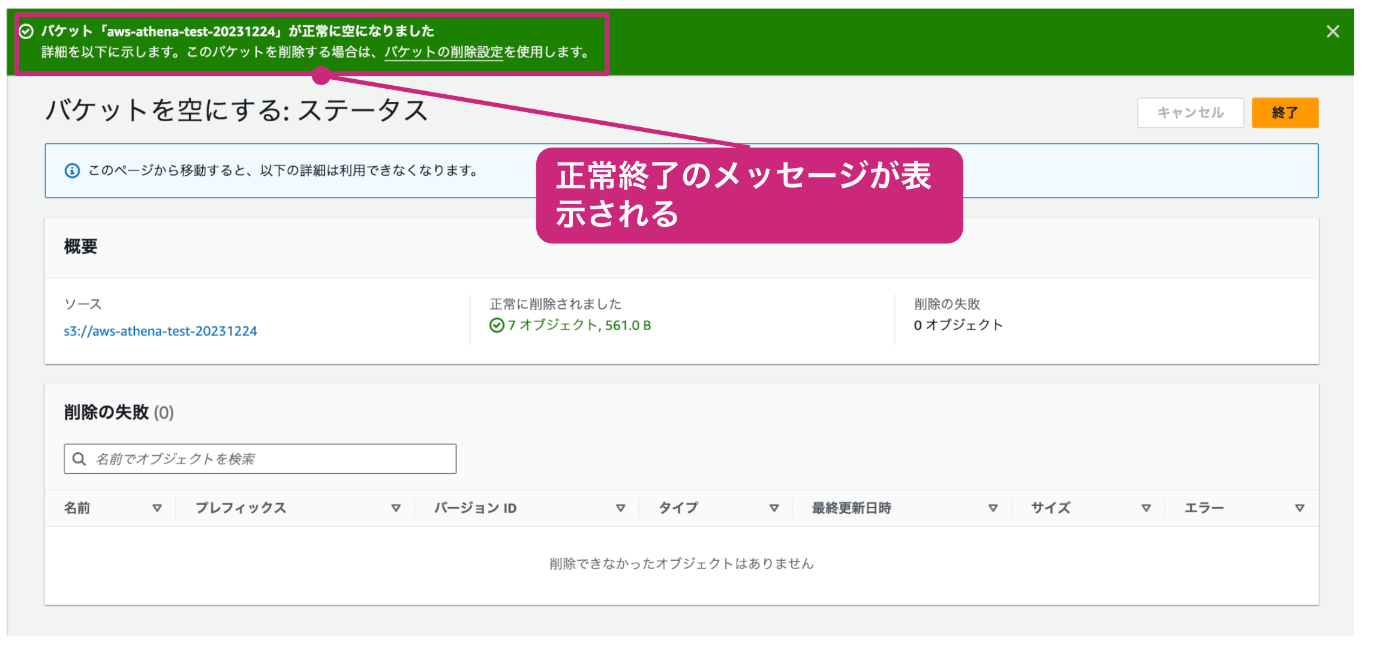
以上の操作で、S3バケットの中にあるデータを空にすることができました。
3.3 S3バケットを削除する
続いて、S3バケットを削除していきます。
空にしたときと同じように、削除したいバケットをチェックし、「削除」をクリックします。
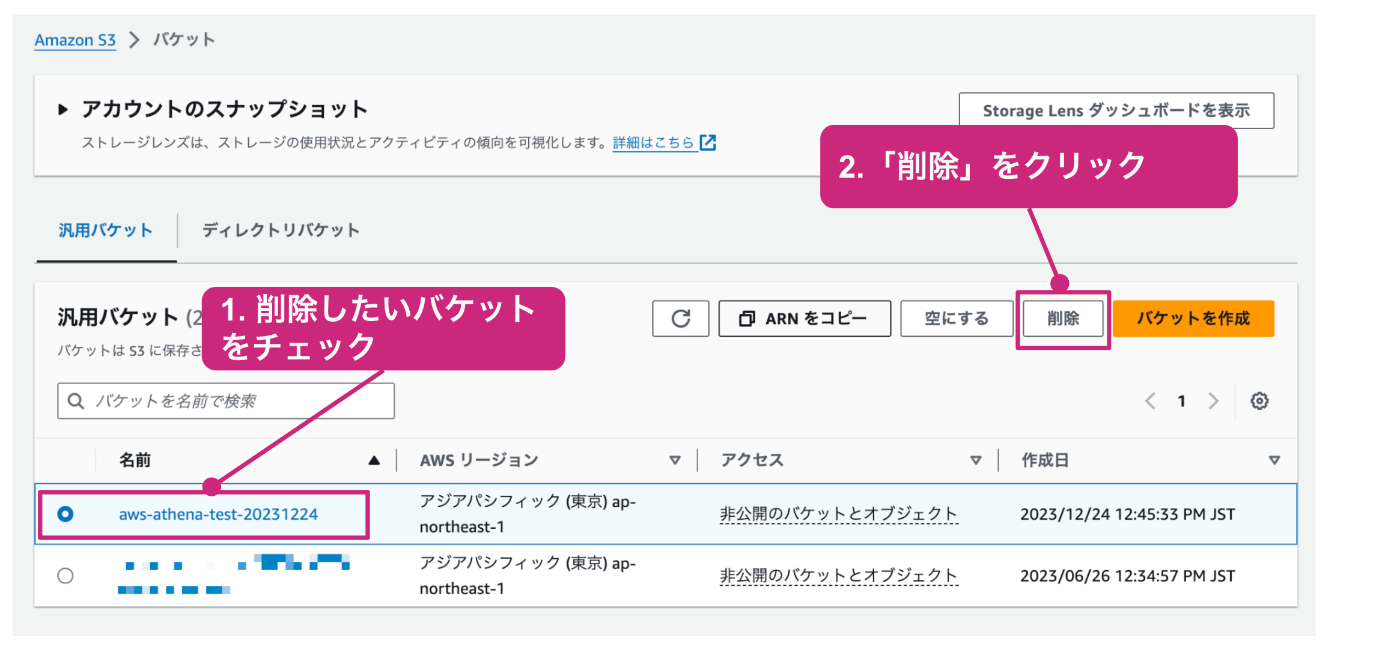
確認用のテキストの入力を促されるので、指定された文字列を入力した上で、「削除」をクリックします。
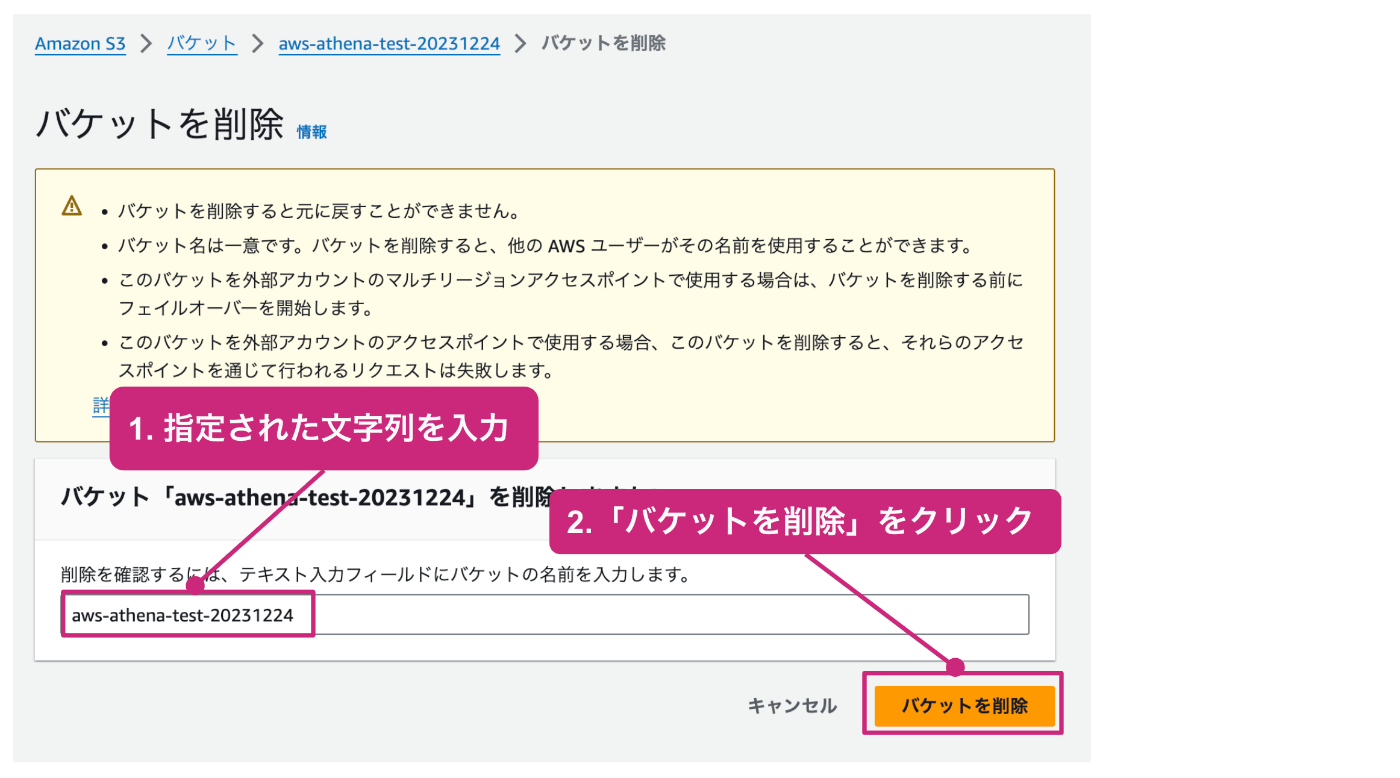
正常に終了すると、以下のように正常終了を示すメッセージが表示されます。

以上の操作で、S3バケットを削除することができました。
4. より改善するために
以上で、Athenaを使用してS3バケットに保存したCSVファイルを参照する方法を扱いました。この内容はまだ実運用に耐えられる内容ではないため、最後にもう少し機能改善ができる案を紹介したいと思います。
4.1 CSVファイルの自動生成
今回はCSVファイルを手動で用意しましたが、実際には外部のデータソースから自動でデータを取得する方が便利です。
例えば、AWS Glueを使用することで、外部データベースからデータを取得し、それをS3バケットにCSV形式で保存することが可能です。
また、Salesforce、Datadog、Googleスプレッドシート、BigQueryなどの外部プラットフォームからデータを連携する際には、Amazon AppFlowのようなツールを利用することで、画面上での設定のみで簡単にシステムを構築できます。
これらの仕組みを活用することで、Athenaに自動的にデータを用意することが可能になります。
4.2 権限の整理
Athenaのテーブルに対する権限設定では、AWS IAMを用いて「このユーザにはAthena全体の検索権限を付与する/しない」といった基本的な制御を行うことができます。しかし、実際の運用ではよりきめ細かい制御が必要になることがあります。例えば、「このユーザ特定のデータだけは閲覧できないようにする」といった制御が求められる場合です。このような細かい制御は、IAMだけでは実現が難しいことがあります。
この問題を解決するために、AWS Lake Formationというサービスを利用することができます。Lake Formationでは、テーブルやカラムなどの単位で、ユーザごとに「閲覧できる/できない」といった制御を行うことが可能です。また、新規作成、更新、削除などの操作に対する権限も、同様にテーブルやカラム単位で細かく設定できます。
この機能を利用することで、機密レベルの異なるデータが混在する環境でも、適切なアクセス制御が実現可能になります。
4.3 BIツールの活用
今回はSQLを使用して文字ベースの検索結果を表示していますが、データの解析を行う際には、グラフなど可視化された表現がより理解しやすいです。BIツール(business intelligenceツール)を活用することで、このような可視化を容易に行うことができます。また、レポートの生成やダッシュボードの作成など、様々な機能が利用できます。
AWSでは、Amazon QuickSightというサービスを利用することで、データの可視化を行いやすくなります。また、AWS以外のサービスでは、Tableau、Looker、Power BIなどのBIツールがAthenaと連携可能です。
これらのサービスを利用することで、Athenaで抽出したデータをグラフなどのわかりやすい形式で表現することが可能になります。
まとめ
以上で、S3に格納したCSVファイルをAthenaで参照する方法を説明しました。基本的な内容ではありますが、AWSを用いてデータ分析を行う一例をイメージしていただければ幸いです。
Discussion