半沢直樹にも登場した「Kubernetes」ってなに?
はじめに
ここ数年、クラウドやバックエンドの領域で Kubernetes という言葉を耳にする機会が増えてきました。「なんとなく難しそう」という印象だけ持っていて、詳しくは知らないという方も多いのではないでしょうか。
実は以前、ドラマ「半沢直樹」のスペシャル版でもこの Kubernetes が登場しました。IT企業を舞台にしたシーンで障害対応中、ITエンジニア役の吉沢亮さんが「Kubernetes止めてください」と言い、まわりのエンジニアたちが「えっ、なに…?」と戸惑うような場面が描かれていました。当時は「なんだかよくわからないけど、すごいエンジニアが高度なことをしている」技術の象徴として扱われていたように思います。
このドラマが放送されたのは2020年ですが、2025年の今では Kubernetes はより身近な存在となりつつあります。実際、エンジニアとして働き始めたばかりの方でも、いきなり Kubernetes で環境構築を任されるケースも珍しくありません。
今回は、そんな「なんとなく難しそうな技術」である Kubernetes について、できるだけわかりやすく、噛み砕いて紹介していきます。
1. そもそもKubernetesってなに?
1.1 Kubernetesとは
まず最初に、そもそも Kubernetes とは何なのかを説明します。
Kubernetes(クバネティス)は、コンテナの管理を自動化するためのシステムです。
専門的には「コンテナ・オーケストレーション」と呼ばれる領域のツールで、以下のような役割を担います:
- コンテナの起動や停止の自動化
- コンテナ同士の通信や連携の管理
- コンテナの数の自動調整(スケーリング)
- 障害が発生したコンテナの自動復旧
- コンテナの状態を監視・ログの取得
つまり、たくさんのコンテナを使ってシステムを構築・運用する際に、それらを効率的かつ安定的に管理するための仕組みが Kubernetes です。
1.2 コンテナとは
Kubernetes を理解するうえで欠かせないのが、「コンテナ」という仕組みです。
コンテナとは、アプリケーションの実行に必要な設定やミドルウェアなどを一つのパッケージにまとめて、軽量かつ独立して動作させることができる仮想化技術です。
従来は、一つのサーバにOSをインストールし、その中に複数のアプリケーションを動かしていました。しかしこの方法では、ミドルウェアやアプリケーション同士が干渉し合って、動作に支障が出ることもありました。また、環境の違い(ローカル、テスト、本番など)によって、同じアプリケーションがうまく動かないこともあります。
そこで登場したのがコンテナです。
システム構成を「イメージ」という形で定義し、そのイメージからコンテナを起動することで、どこでも同じ構成でアプリケーションを動かすことができます。これにより、開発環境で動いたアプリが、本番環境でもそのまま動く、という安定性を実現できます。
さらに、コンテナには「軽量で高速」という特徴もあります。
同じ仮想化技術として「ハイパーバイザー型の仮想マシン(VirtualBoxやVMwareなど)」もありますが、これらはOSごと仮想化するため、起動に時間がかかり、リソースも多く必要になります。
一方、コンテナではホストOSのカーネルを共有するため、高速かつ省リソースで起動・実行が可能です。これにより、スケーラブルで効率的なシステム運用が実現できるのです。
以上のような経緯で、現在はアプリケーションの動作にコンテナが利用されるケースが増えています。
2. Kubernetesが使われる「マイクロサービス」を理解しよう
続いて、Kubernetes がもっとも活用されている領域である マイクロサービス について理解していきましょう。
マイクロサービスを知ることで、「Kubernetes を導入すべきかどうか」という技術選定の判断がしやすくなります。また、どのようなシステムで Kubernetes が活躍するのか、利用シーンを具体的にイメージできるようになることで、Kubernetes そのものへの理解も深まります。
2.1 モノリシックな構成
まず、マイクロサービスが登場する以前に多く採用されていた「モノリシック構成」について説明します。
モノリシック構成とは、一つの動作環境にシステムのすべての機能が詰め込まれている構成のことです。たとえば、ユーザーインターフェースを担当する「フロントエンド」、ビジネスロジックを処理する「バックエンド」、さらにデータベースやWebサーバなどのミドルウェア、LinuxなどのOSといったすべての要素が一体化して動作します。
具体例としては、PHPの Laravel、Ruby on Rails、Javaの Spring フレームワークなどが、モノリシック構成を採りやすい技術スタックといえます。
モノリシックには、構成がシンプルで管理しやすいという利点があります。しかし一方で、すべての機能が密接に結びついているため、一部の変更が他の部分に思わぬ影響を及ぼすという課題もあります。たとえば、バックエンドで使用しているライブラリを更新したら、直接関係のないフロントエンドにまで影響が出るといったケースが挙げられます。
また、フロントエンドとバックエンドで異なる技術を使いたくても、システム全体が一体化しているためにそれが難しいという課題もあります。たとえば、フロントエンドだけを最新のフレームワークに移行したい場合でも、バックエンドとの結合が強すぎて、他の部分に影響が出てしまい、容易に切り替えることができません。このような課題から、より柔軟で独立性の高いシステム構成が求められるようになりました。

2.2 フロント・バックエンド分離構成
モノリシック構成とマイクロサービス構成の中間的な形として、フロント・バックエンド分離構成があります。
この構成では、フロントエンドとバックエンドを別々の技術や役割で構築します。両者の連携は、HTTPベースのAPIを通じて行います。
APIとは、機能間でデータのやり取りを行うためのインターフェースのことで、REST APIやgRPCなどの種類があります。つまり、フロントエンドとバックエンドは直接的な依存を持たず、APIの仕様(リクエストとレスポンスの形式)のみを共有してやり取りします。
このようにAPIを介してやり取りすることで、フロントエンドとバックエンドの疎結合が実現されます。たとえば、フロントエンドをReactやVueなどの最新フレームワークに変更しても、APIの仕様が変わらなければバックエンド側には影響がありません。また、フロントとバックで異なる技術スタックを採用したり、開発チームを分けて並行して開発を進めることも容易になります。
ただし、この段階ではバックエンド側がまだ一枚岩の構造であることが多く、機能間の変更が他の部分に影響を及ぼすリスクは残ります。こうした課題をさらに解決するために、次に紹介するマイクロサービス構成が検討されるようになります。

2.3 マイクロサービス
フロント・バックエンド分離構成をさらに発展させた形が「マイクロサービス」です。
この構成では、フロントエンドとバックエンドの分離に加えて、バックエンドの各機能(たとえば「認証」「予約管理」「通知」など)をそれぞれ独立した API として分割します。
それぞれのサービスは独立して開発・デプロイが可能であり、機能間の疎結合をさらに強化することができます。
このような構成により、以下のような利点があります:
- 開発チームを機能単位で分けられる
- 一部のサービスだけを個別に更新・スケーリングできる
- 障害が起きても、他の機能に影響しにくい
そして、このマイクロサービスを効率よく運用するための仕組みが Kubernetes です。
マイクロサービスでは、多数のコンテナを立ち上げ、それぞれを別々に管理する必要があります。しかし、手動でそれを行うのは、コスト・難易度ともに非常に高くなります。
そこで Kubernetes を使うことで、各コンテナの配置・監視・スケーリング・障害対応などを自動化し、柔軟で拡張性のあるマイクロサービス構成を効率的に管理することができます。

3. Kubernetesの構成要素
続いて、Kubernetesをより理解していくために、Kubernetesの構成要素を見ていきたいと思います。
3.1 Pod
まずは、Kubernetesの最小の実行単位であるPodを説明します。Podは、一つ以上のコンテナを内包しており、コンテナを実行するための単位です。アプリケーションを動かす一つの「箱」のようなイメージです。

3.2 Node
次に、Podを実行する場所であるNodeについて説明します。Nodeは物理サーバや仮想マシンのようなもので、Kubernetes内でPodを実行する役割を持ちます。1つのNodeには、リソース(CPUやメモリ)の範囲内で複数のPodを同時に動かすことができます。

3.3 Service
続いて、複数のPodへのアクセスの入口を提供するServiceを説明します。マイクロサービスを運用する際には、同じ機能に対して複数のPodを並行して稼働させることが一般的です。その入口となるのがServiceであり、外部や他のサービスから安定してアクセスするための「窓口」のような役割を果たします。
Podは定期的に再起動されることがあり、その際にIPアドレスが変わる場合でも、Serviceを介することで接続先を意識せずに通信を継続できます。

3.4 Deployment
続いて、Podの数や更新方法を管理するDeploymentについて説明します。Deploymentは、どのようなPodを、いくつ、どのように稼働させるかといった運用ルールに従い、Podの管理と更新を行う「コントローラ」の役割を持ちます。
Deploymentを使うことで、Kubernetesは自動的にPodの数を維持し、異常があれば再作成するなどの自己修復機能も実現されます。運用管理を自動化するための基本的な仕組みの一つです。後述するヘルスチェックやローリングデプロイといった機能を持ちます。

3.5 マニフェスト
最後に、Kubernetesに「どのような構成で動作してほしいか」を伝えるための設定ファイルであるマニフェストを説明します。マニフェストは、DeploymentやServiceなどのKubernetesリソースを、どのように作成・構成・維持するかを記述したYAML形式のファイルです。
たとえば、どのコンテナイメージを使うのか、Podを何個動かすのか、どのポートを開放するのかなどを、マニフェストに明記します。Kubernetesはこのマニフェストをもとに、定義された通りの状態(あるべき姿)を自動的に実現しようとします。
Kubernetesを使ってマニフェストを適用することで、Kubernetes上にリソースが作成・更新されます。Kubernetesの操作は、基本的にこのマニフェストを通じて行われます。

4. Kubernetesの主な役割を理解しよう
続いて、Kubernetesの主な役割について説明していきます。
4.1 コンテナのスケジューリングと起動の自動化
まず、Kubernetes の代表的な役割のひとつは、コンテナの配置と起動の自動化です。
1つのコンテナを起動するだけであれば、Docker のようなツールでも十分に対応できます。しかし、複数のコンテナを組み合わせて構成されたシステムを効率よく管理・起動するためには、Kubernetesのようなコンテナ・オーケストレーションツールが必要になります。
前述の通り、Kubernetes ではあらかじめ「ノード」として複数のサーバを登録しておきます。この「ノード」は、実際にコンテナを実行するサーバであり、Kubernetes がそれらをまとめて管理します。そして、Kubernetes は各ノードのリソース状況をもとに、どのノードにどのPodを起動し、どのコンテナと紐づけるかを自動で判断します。
また、Pod の起動順序や必要な CPU・メモリのリソース量、他のサービスとの依存関係なども設定できます。これらの情報は、YAML形式で記述された「マニフェストファイル」 に定義し、Kubernetes に読み込ませることで適用されます。
このように、マニフェストファイルでインフラ構成を宣言的に定義することで、人的ミスの防止やリソースの有効活用が可能となり、より安定した運用を実現できます。
4.2 ヘルスチェックと自己修復
次に紹介するKubernetesの重要な機能が、ヘルスチェックと自己修復です。
ヘルスチェックとは、起動中のコンテナが正常に動作しているかを定期的に監視し、異常があれば自動で検知する仕組みです。
異常を検知した場合には、Kubernetes が自動でコンテナの再起動や切り離し、**必要に応じて別のノードへの再スケジューリング(再配置)**などの対応を行い、システムの自己修復を試みます。
これらの動作は、マニフェストファイル内でヘルスチェックの設定を記述することで柔軟に制御できます。
たとえば、「応答がなければ5秒後に再試行する」「一定回数失敗したら既存の Pod を削除し、新しい Pod を自動で再作成する」などの細かいルールも定義可能です。
このような仕組みにより、人の手を介さなくてもサービスの健全性を保つことができ、システム全体の可用性と信頼性を向上させることができます。

4.3 ロードバランシング
次に紹介する Kubernetes の機能が、ロードバランシングです。
ロードバランシングとは、Serviceが持つ主な機能であり、ユーザーからのリクエストを複数のコンテナ(Pod)に適切に振り分ける仕組みです。
Serviceはユーザーからのアクセスを受け付け、裏側に存在する複数のPodに対して、バランスよくリクエストを分配します。
このような機能は AWS などのクラウドサービスにも備わっていますが、Kubernetesの特徴は、コンテナ単位・マイクロサービス単位で柔軟にロードバランシングを構成・管理できる点にあります。
これにより、ユーザーから見たときに常に安定した接続が保たれ、サービス全体の可用性とスケーラビリティが向上します。
なお、どの種類のPodにリクエストを送るかという定義は、**マニフェストファイル(Serviceの設定)**で行います。

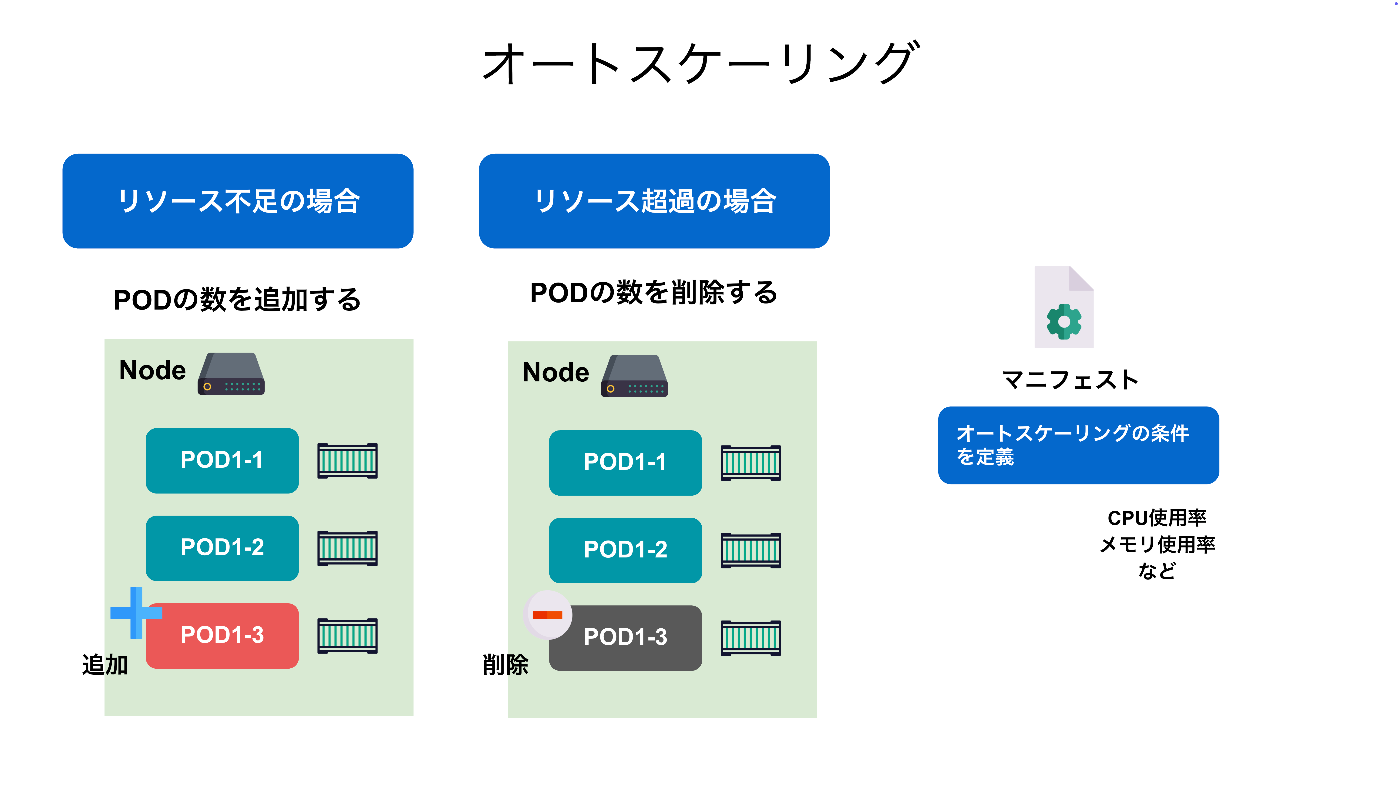
4.4 オートスケーリング
次に紹介する Kubernetes の特徴的な機能が、**オートスケーリング(自動スケーリング)**です。
さ
スケーリングとは、サーバ(ここではコンテナ)のアクセス数や負荷に応じて、コンテナの数を自動で増減させる機能です。
これにより、アクセスが集中しているときは処理性能を確保し、逆に利用が少ないときはリソースを節約することで、パフォーマンスとコストの最適化が可能になります。
Kubernetes では、マニフェストファイル内でスケーリングの条件や上限値を定義することができます。
たとえば、CPU使用率が70%を超えたらコンテナを1つ追加し、30%を下回ったら1つ削減する、といった細かいルールを設定できます。ベースとなる最小数や最大数も指定できるため、無駄のないリソース管理が実現できます。
オートスケーリング自体は AWS などのクラウドサービスでも提供されていますが、Kubernetes の強みは、これを複数のコンテナやマイクロサービス単位で柔軟に管理できる点にあります。
これにより、システム全体を自動で拡張・縮小しながら、高い安定性と効率性を保つことが可能になります。
4.5 デプロイの効率化
Kubernetes では、アプリケーションの更新時に「ローリングアップデート」と呼ばれる方法で、サービスを停止せずに段階的にデプロイを行うことができます。
これは、古いバージョンのコンテナを少しずつ停止しながら、新しいバージョンのコンテナを順番に立ち上げていく仕組みです。これにより、ユーザーへの影響を最小限に抑えた、安全かつ自動化されたデプロイが実現できます。
このデプロイ方式は Kubernetes の標準機能として組み込まれており、特別なツールや外部サービスは不要です。また、万が一問題が発生した場合も、簡単なコマンドで以前のバージョンにロールバックすることができます。
他にもローリングアップデートを行えるサービスもありますが、Kubernetes では次のような点でより柔軟な制御が可能です:
- 一度にどれくらいのコンテナを更新するか、何個のコンテナを並行して動かすかなど、アップデートの進め方を細かく調整できる
- ロールバック操作がよりシンプルで早く実行でき、手戻りが容易
- ヘルスチェックのタイミングや条件も柔軟に設定できるため、失敗を早期に検知
このように、Kubernetes のローリングアップデートは、開発と運用の負担を大きく減らし、継続的なリリースを柔軟に実現できる仕組みです。
5. Kubernetesを習得する方法
最後に、Kubernetesを習得するにはどうすればよいかを説明します。短期的に見れば、Kubernetes自体の入門書を購入して学習すれば、基本的な操作は習得できると思います。しかし、前述の通り、KubernetesではPodやNode、Service、Deploymentなどの要素を正しくマニフェストファイルに定義し、ヘルスチェック、ロードバランシング、オートスケーリングなどの機能を組み合わせる必要があります。
そのため、非常に幅広い知識が求められ、Kubernetesの操作だけを覚えても、本当の意味で「Kubernetesを使いこなせている」とは言えません。そのため、下記のような要素を段階的に組み合わせていくことが、Kubernetes習得の大きな近道になります。
5.1 バックエンドの開発スキルを習得
まず最初に求められるのは、バックエンドの開発スキルです。Kubernetes は主にバックエンドのアプリケーションをデプロイして運用するための基盤であるため、実際に動作させる API などについての理解が不可欠です。
インフラに強いエンジニアでも Kubernetes の理解が難しいことがありますが、その多くはバックエンド開発の経験が不足していることが原因です。そのため、Kubernetes 上で動作させたい 言語 や フレームワーク を用いて、簡単な API を開発・実行できる程度のスキルを身につけておくと、以降の理解がスムーズになります。
5.2 サーバのスキルを習得
続いて求められるのが、サーバに関するスキルです。具体的には、Linux などの OS、Nginx などの Web サーバ、MySQL や PostgreSQL などのデータベース、そしてそれらを接続するネットワークの知識が挙げられます。
Kubernetes の操作は高度に抽象化されており、基本的な操作だけであれば、これらの知識がなくても扱うことは可能です。しかし、Kubernetes を正しく設定し、トラブルシューティングやチューニングを行うには、これらの知識が不可欠です。十分な理解がない場合、効率的で安定した設計や運用を行うことは難しいでしょう。
5.3 コンテナのスキルを習得
続いて求められるのは、コンテナのスキルです。Kubernetes は コンテナを扱うオーケストレーションツールのひとつであるため、コンテナ の理解は必須と言えます。
Docker などのツールを使用し、自作した API を実際に動作させる程度のスキルが求められます。その過程で、サーバ に関するスキルも必要になります。
コンテナの理解がないと、設計やトラブル発生時の原因特定、パフォーマンス改善が難しくなります。
5.4 Kubernetesの習得
ここまで理解を深めて、ようやく Kubernetes を本格的に学習する段階に入ります。実際に Kubernetes のリソース定義や運用知識を習得するフェーズであり、学習全体の中心となる項目です。
バックエンド開発、サーバ、コンテナ のスキルという土台を固めたうえで Kubernetes を学習することで、理解の深さが大きく変わってきます。この時点では、Kubernetes の入門書や解説資料も、十分に理解できるレベルになっているはずです。
まとめ
この記事では、Kubernetesとは何か、その背景と登場の理由、具体的な役割、そして「なぜ難しいのか」という観点までを整理してきました。
Kubernetesは、コンテナ時代のインフラ運用を支える代表的な技術です。従来の仮想サーバによる運用と比べて、より柔軟にスケーラブルで、自己修復性を持ったシステム構築を可能にするという大きな強みがあります。コンテナの配置、起動、自動回復、スケーリング、ロードバランシング、ローリングアップデートといった機能が、宣言的な設定によって統一的に制御できる点も、Kubernetesの魅力です。
一方でその反面、Kubernetesには「学ぶことが多い」「設計が難しい」「必要以上に導入されることがある」といったハードルも存在します。単なる技術の習得にとどまらず、インフラ・アプリの両面からシステム全体を俯瞰して設計できる視点が求められるため、導入には慎重さも必要です。
とはいえ、Kubernetesは一時的な流行ではなく、今後のインフラ運用の基盤として着実に定着していく技術であり、学んで損はない分野です。自分の知識や経験を活かしながら、段階的に学びを積み重ねていくことで、他では得られない大きなスキル価値が得られるでしょう。今後の学習や実践に向けて、Kubernetesを正しく理解し、自信を持って扱えるようになっていきましょう。
Discussion