道路中心線と道路縁から道幅をもった道路中心線データをつくる
概要
この記事では,道路中心線と道路縁の線データを用い,道路中心線ごとに道幅を計算する方法について述べます.以下3つの図で,太らせた領域の端と道路縁がおおむね一致していることから,方法は単純ですがそれっぽいデータが得られていることがわかります.
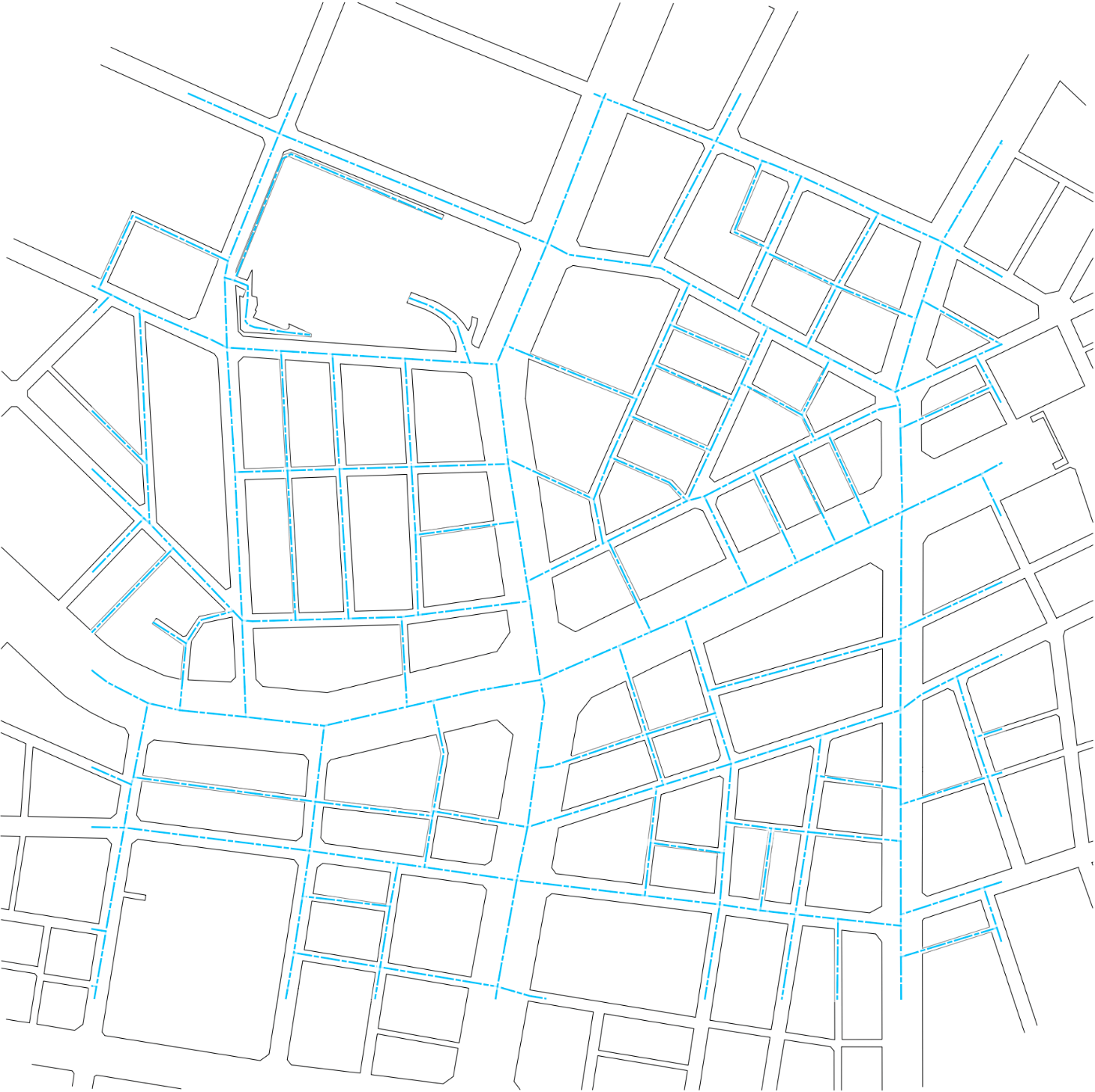
入力:シアン色の一点鎖線は道路中心線.黒い細線は道路縁.
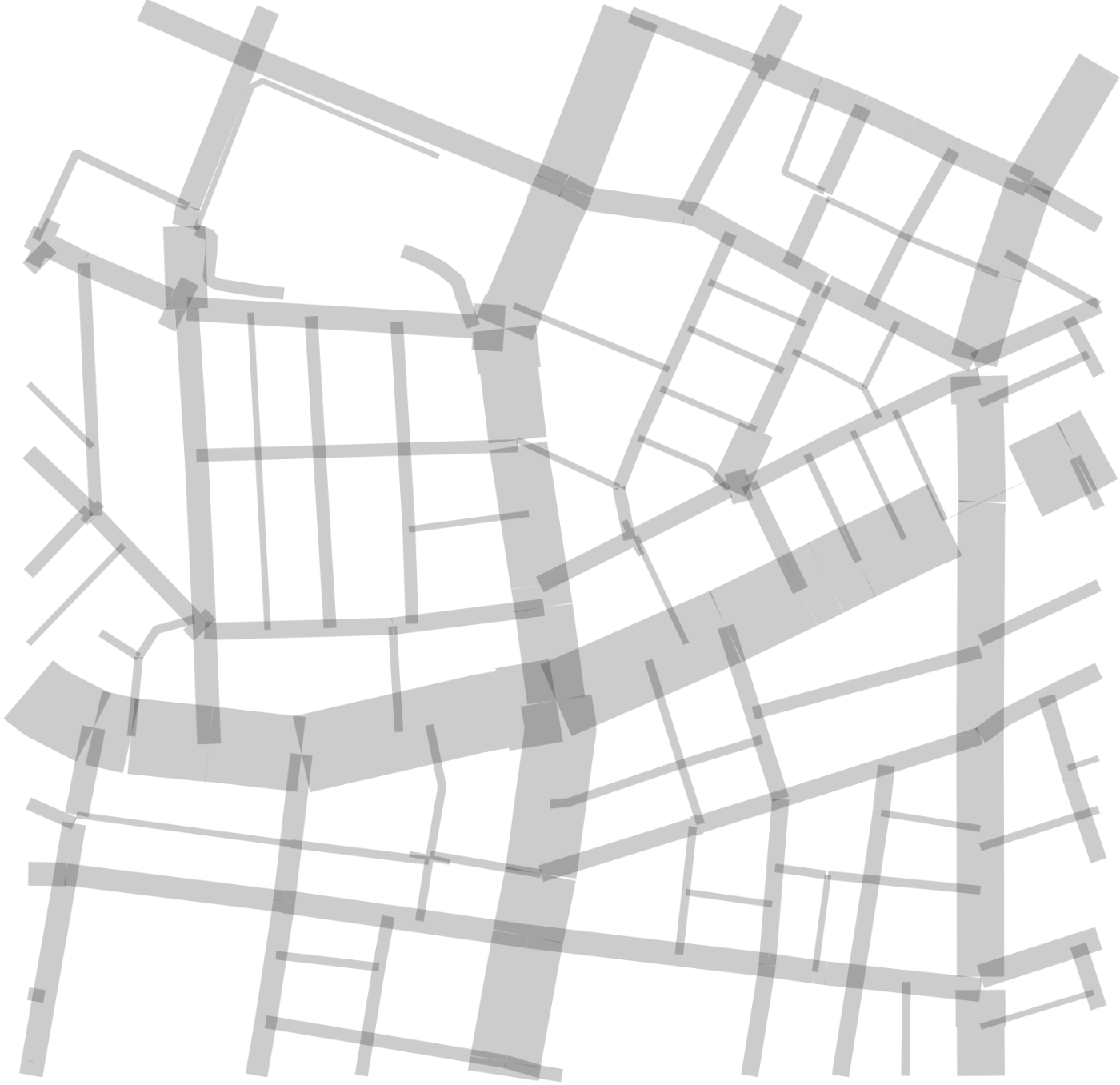
出力:道幅つきの道路中心線
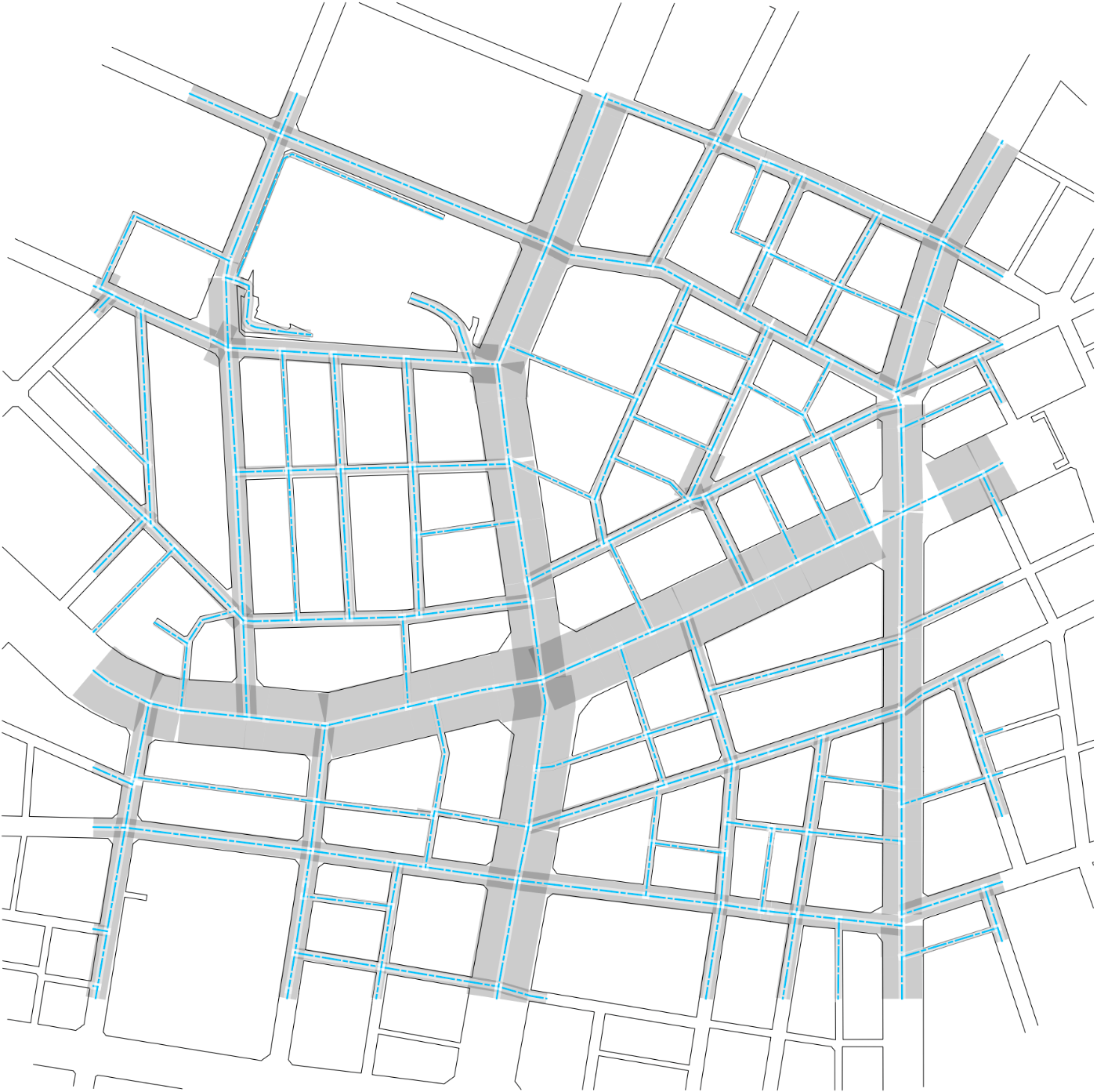
入力と出力を重ねたもの
使用するデータ
本稿では以下のデータを用います.
- 道路中心線:国土地理院ベクトルタイル提供実験のデータを用います.タイル番号は
{z, x, y}={16, 58211, 25803}です. - 道路縁:国土地理院の基盤地図情報のデータのうち,道路縁(RdEdg)を用います.2次メッシュの番号は
533946です.データが大きいので,道路中心線の凸包の50mバッファで切り抜きました.
データ処理の流れ
データの処理は以下のように行います.
- 道路中心線から一定間隔で点を発生させる,発生させた点からもとの道路中心線の法線方向にレイを飛ばして最も近くにある道路縁までの距離を測る.これをその点における道幅とする.
- 道路中心線のセグメントごとに道幅の中央値を求め,それを道幅とする.

白抜きの点は発生させた点.赤紫色の点は道路縁とレイの交点.黄色は計算された道幅.
もちろんこの方法に欠点がないわけではなく,たとえば次のような改良ができそうです.
- 道路縁に対して垂直から遠い角度でレイが当たった場合(図中
A),本来参照すべきでないものを見ているのでそのデータは除くべきではないか. - 中央値をとる処理を道路中心線のセグメントごとにするのは,道路セグメントの切り分けを人手(数値地図2500)に頼っておりややズルいので,一定の長さごとにすべきではないか.
とはいえ,(都心の整形な道路網で実行したからかもしれませんが)簡単な実装でもそれなりに良い結果が得られています.
実際のデータ処理
今回の処理は Google Colab で行いました.これが無料で使えるのはいい時代ですね.
ライブラリのインストールと読み込み
今回は geopandas を使います. geopandas はジオメトリの処理に shapely を使っているので, shapely も同時にインストールされます.データ処理に Google Colab を使う場合,必要に応じて FutureWarning 警告を握りつぶすことでブラウザのCPU負荷を抑えられます.
ライブラリのインストールと読み込み
!pip install geopandas
import geopandas as gpd
import shapely
import pandas as pd
import numpy as np
import math
import matplotlib.pyplot as plt
# (optional) Added to avoid high CPU usage while using colab
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
データの読み込みと投影変換
データを JGD2011 (EPSG:6677)に投影します.
ダウンロードしたデータの座標は緯度経度で表現されているため,そのまま計算すると長さをメートル単位で計算するなどの操作に苦労します.そこで,いったん平面に投影して座標をメートル単位に直します[1].このとき,投影の方法を特定するのにEPSG コードを利用するのが便利です.
データの読み込みと投影変換
road_center = gpd.read_file('./roadCenter.geojson')
road_center_proj = road_center.to_crs('EPSG:6677')
road_edge = gpd.read_file('./roadEdge_clipped.geojson')
road_edge_proj = road_edge.to_crs('EPSG:6677')
道路中心線から点を発生させる/その点での法線を求める
道路中心線の上に等間隔(今回は 1 m)に点を発生させます.点を発生させるだけなら shapely の interpolate で可能ですが,今回は法線を求めたいので[2],ついでに点の発生も書いてしまいます.
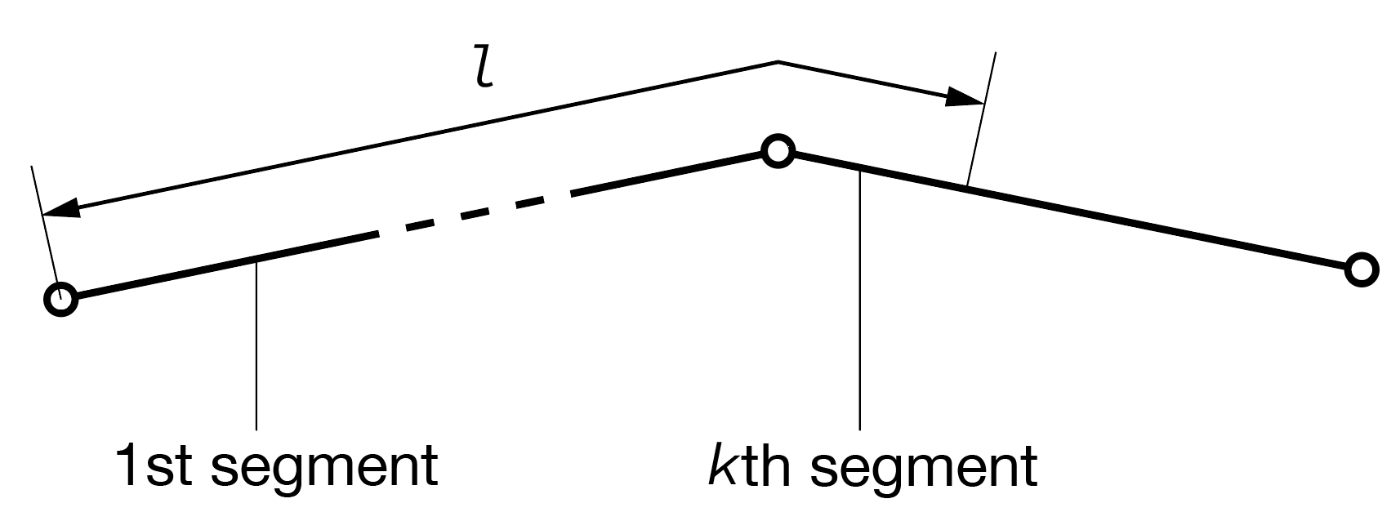
等間隔に点を発生させる・法線を求めるためには,端から長さlだけたどった点がどこにあるかがわかれば足ります.より詳しくいうと,
-
linestringのどのセグメントか(法線の特定に必要.折れ線なので,セグメント内では法線の向きは一定) - そのセグメントの端からどれだけの距離にあるか(座標の特定に必要)
が特定できる必要があります.
道路中心線データに含まれる個々のオブジェクトは,都市部ではほとんどの場合数個の線分からなるようなので端から探索していけば十分ですが,そこまで手間でもないので二分探索で書くことにしました[3].
linestring のある長さでの評価
# 個々のセグメントを取り出す
def get_segments(line_string):
starts = line_string.coords[:-1]
ends = line_string.coords[1:]
return list(zip(starts, ends))
# 線分ごとに長さを求める
def get_lengths(segments):
result = []
for segment in segments:
src = segment[0]
dst = segment[1]
dx = dst[0]-src[0]
dy = dst[1]-src[1]
result.append(np.sqrt(dx*dx + dy*dy))
return result
# 線分ごとに法線を求める
def get_normals(segments):
result = []
for segment in segments:
src = segment[0]
dst = segment[1]
dx = dst[0]-src[0]
dy = dst[1]-src[1]
len = np.sqrt(dx*dx + dy*dy)
normal = np.array([-dy, dx]) / len
result.append(normal)
return result
# 端からある長さ at_length の座標を求める
def get_point_at_length(cumulative_lengths, segments, lengths, at_length):
length = cumulative_lengths[-1]
if (at_length < 0 or at_length > length):
return np.nan
index = np.searchsorted(cumulative_lengths, at_length, side='left')
segment_end_length = cumulative_lengths[index]
segment_length = lengths[index]
segment = segments[index]
overrun = segment_end_length - at_length
overrun_dx = (segment[1][0] - segment[0][0]) * overrun / segment_length
overrun_dy = (segment[1][1] - segment[0][1]) * overrun / segment_length
return np.array([segment[1][0] - overrun_dx, segment[1][1] - overrun_dy])
# 端からある長さ at_length での法線を求める
def get_normal_at_length(cumulative_lengths, normals, at_length):
length = cumulative_lengths[-1]
# outside curve
if (at_length < 0 or at_length > length):
return np.nan
# find line segment
index = np.searchsorted(cumulative_lengths, at_length, side='left')
return normals[index]
### 端から一定間隔で法線と座標を求める
def evaluate_by_interval(line_string, interval=1.0):
length = line_string.length
n_points = math.floor(length/interval)
parameters = np.arange(0, length, interval)
segments = get_segments(line_string)
lengths = get_lengths(segments)
cumulative_lengths = np.cumsum(lengths)
normals = get_normals(segments)
getP = np.vectorize(lambda x: get_point_at_length(cumulative_lengths, segments, lengths, x), signature='()->(i)')
getN = np.vectorize(lambda x: get_normal_at_length(cumulative_lengths, normals, x), signature='()->(i)')
return ({
'curve_parameters':parameters,
'points':getP(parameters),
'normals':getN(parameters)
})
### 線データの上に等間隔に点を発生させる
def sample_line_string(df, id_column = 'rID', interval=1):
tmp = df[['geometry']].apply(lambda x: evaluate_by_interval(x['geometry'], interval), axis=1, result_type='expand')
tmp['rID'] = df['rID']
tmp = tmp.set_index(['rID']).apply(pd.Series.explode).reset_index()
return tmp
sampled_points = sample_line_string(road_center_proj)
求めた点と法線から線分を発生させ,道路縁と衝突する点のうち最も近いものを求める
(再掲)法線方向に線分を発生させて道路縁と衝突する点のうち最も近いものを求める
求めた点と法線からセグメントに垂直な方向に線分を発生させます.このとき,面倒なので発生させた線分を衝突させる相手の道路縁はgeopandas.GeoSeries.unary_union()でひとつのオブジェクトにしてしまいます.
衝突した要素のうち,発生元の点に最も近い点を求める必要があります. shapely では衝突を計算幾何学的に頑張って解いてくれるので,たまに線分と線分の intersection が線分として返ってくるなどのケースがあります.しかし,今回は単に最近傍の点がわかればよいので,それらのジオメトリの構成要素を一旦全部点に分解して,単に x 座標(または y 座標)だけをみて最近傍を取り出しています.
なお,衝突判定には今回の規模で1分ほどかかります.大規模なデータを処理する場合,少なくとも衝突判定だけでも頑張って高速化したほうがよいでしょう.
衝突した要素のうち,発生元の点に最も近い点を求める
road_edge_union = road_edge_proj['geometry'].unary_union
ray_length = 20
def compute_half_road_width(shape, point, normal, ray_length, invert_normal=False):
if (invert_normal):
normal = normal * -1
src = point
dst = point + normal * ray_length
ray = shapely.geometry.LineString([src, dst])
intersection = ray.intersection(shape)
if (intersection.is_empty):
return np.nan
coords = gpd.GeoSeries([intersection]).explode().apply(lambda x: x.coords).explode().reset_index(drop=True)
sortable = coords.apply(lambda x: x[0]-point[0]) if normal[0] > 0.7 else coords.apply(lambda x: x[1]-point[1])
abs_sortable = np.abs(sortable.values)
argmin = np.argmin(abs_sortable)
coord = coords[argmin]
distance = np.sqrt((coord[0]-point[0])**2 + (coord[1]-point[1])**2)
return distance
線分の両側について半道路幅(私の造語です)を求めます.
half_road_width_positive_side = sampled_points[['points', 'normals']].apply(lambda x: compute_half_road_width(
road_edge_union,
x['points'],
x['normals'],
ray_length,
invert_normal=False
), axis=1)
half_road_width_negative_side = sampled_points[['points', 'normals']].apply(lambda x: compute_half_road_width(
road_edge_union,
x['points'],
x['normals'],
ray_length,
invert_normal=True
), axis=1)
最後に,結果を集計します.点ごとに両側の半道路幅[4]を合計して道幅を求め,道路セグメントごとに中央値をとります.
道路セグメントごとに集計して中央値をとる
road_width_values = half_road_width_positive_side + half_road_width_negative_side
road_widths_at_points = sampled_points.copy()
road_widths_at_points['raytraced_width'] = road_width_values
road_widths = road_widths_at_points[['rID', 'raytraced_width']].groupby(['rID']).median()
プロット
道路中心線を求めた道幅の半分でバッファして,道路幅が正しく計算されているかをチェックします.道路幅が正しく求められていれば,道路中心線を道路幅でバッファした領域と道路縁がちょうど重なるか,少なくとも両側に同じだけズレる(道路中心線が両側の道路縁の中心にない場合)はずです.
結果を見るかぎり,簡単な処理の割によい結果が得られているように見えます.
結果のプロット
road_center_with_width = pd.merge(road_center_proj, road_widths, left_on='rID', right_on='rID')
# Buffer road center line for sanity check
road_center_nona = road_center_with_width.dropna(subset=['raytraced_width'])
road_center_buffered = road_center_nona.apply(lambda x: x['geometry'].buffer(x['raytraced_width']/2), axis=1)
fig, ax = plt.subplots(figsize=(12, 12))
gpd.GeoDataFrame({'geometry': road_center_buffered}).plot(ax=ax, color='#aaa')
road_edge_proj.plot(ax=ax)
road_center_with_width.plot(ax=ax, column='raytraced_width')
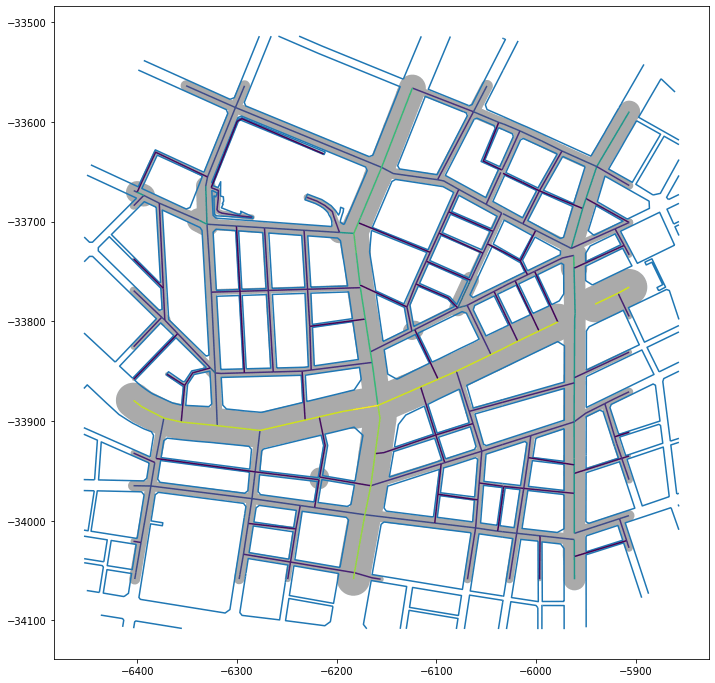
結論
道路縁と道路中心線から,レイトレースに似た手法で道幅つき道路中心線のデータを作ることができました.一方で,今回は Python のライブラリを使って簡単に書いたのでスピードは全く出ていません.今回のような数百メートル角を処理するだけでも1分少々かかってしまいます.すぐにできる改善策として,たとえばレイトレース部分に PyEmbree を使うだけでもかなりの高速化ができそうです[5].
今回の例に限らず Python と Jupyter Notebook で GIS を代替する方法では,GISでは面倒な処理を力任せにfor文で書くなどの蛮行が簡単にできることがあります.さらに,最近増えてきた Colab に代表されるマネージド Jupyter Notebook を使うことで,環境構築もほぼ不要でできます.困ったときの選択肢のひとつとして検討してみてはいかがでしょうか.
Discussion
大変参考になる記事、ありがとうございます。
よろしければ一点ご教示ください。
半道路幅を求めるところで、sampled_pointsという変数が出てきていますが、
どう定義しているのか、教えていただけないでしょうか。
ご指摘ありがとうございます.手元の Jupyter Notebook からコピペしたさいに,道路中心線の上に点を発生させる関数が抜けておりましたので,
sample_line_stringという関数を追記しました.追記ありがとうございました。
大変助かります!