Elasticsearchの検索周りのAPI調べてみた
Elasticsearchアーキテクチャ
こちらの資料が非常にまとまってわかりやすいので、気になる方はご確認ください。
ざっくり構成と登場人物
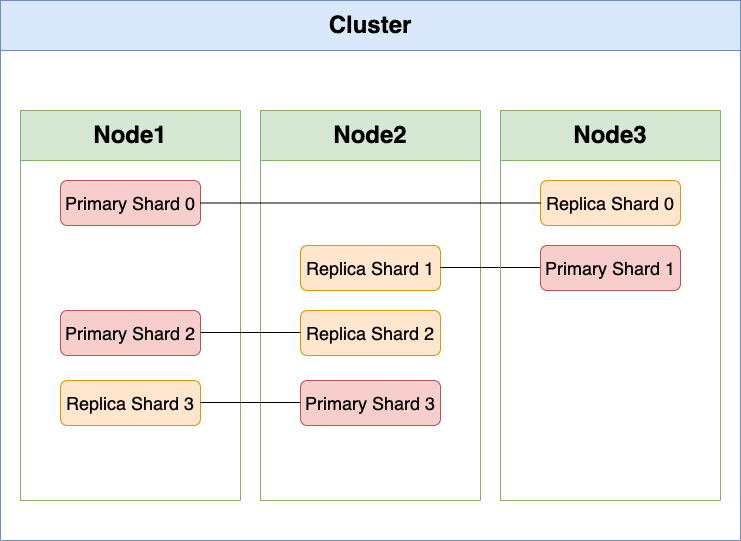
Cluster
Clusterは、1つ以上のNodeの集まりです。
Node
NodeはElasticsearchのインスタンスで、データを保存する役割を担います。
複数のNodeを使用することで、限られたディスク容量でも大規模なデータを扱えるようになります。
Nodeはクラスタに所属し、クラスタ内でデータを分散保存します。
通常、1つのクラスタを運用することが多く、複数のクラスタを使う場合は論理的な分け方や異なる構成が理由です。
ノードはクラスタに自動的に参加し、単一ノードでも使用可能ですが、可用性や拡張性の面で問題があります。
Shard
Shardはインデックスのデータを分割保存する単位。
-
データの分割と分散: シャードは、インデックス内のデータを複数の部分に分けて、各部分を個別にノードに格納するための単位です。これにより、大量のデータを1台のノードではなく、複数のノードに分散して格納することができ、スケーラビリティが向上します。
-
パフォーマンス向上: シャードは並列処理を可能にします。クエリやインデックス操作(データの追加、更新、削除など)は、複数のシャードに分散して実行されるため、大量のデータに対する処理能力が向上します。これにより、検索クエリのパフォーマンスが向上し、大規模なデータセットに対しても高速な処理が可能になります。
-
データの冗長性と可用性の確保: Elasticsearchでは、シャードの複製(レプリカ)を作成できます。これにより、シャードの冗長コピーを他のノードに保存しておき、1つのノードが故障した場合でも、データの可用性を保つことができます。レプリカシャードは、検索クエリの処理にも利用されるため、システム全体の負荷分散にも貢献します。
-
スケーラビリティの確保: シャードは、クラスタ内のノードを追加することで、データを水平方向にスケールできます。例えば、インデックスのシャードを複数のノードに分散することで、大きなインデックスでも十分なストレージ容量を確保し、検索パフォーマンスを維持できます。
Primary Shard
Primary Shardは、インデックスの書き込みと参照処理で使用されます。
Replica Cluster
Replica ShardはPrimary Shardのコピーです。
APIリクストを送信する際の事前準備
APIキーの生データをcurlに含めていると、見た目が長くなってしまうので環境変数に登録しておきます。
export API_KEY="blpYVjNK****************ZlSVo0a29MazJmUQ=="
よく使うAPIリクエスト
クラスタのヘルス状態を確認するリクエスト
コマンドの意味として、_clusterはアクセスしたいAPIを指し、healthはコマンドを意味しています。
$ curl -X GET http://localhost:9200/_cluster/health \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json" | jq
{
"cluster_name": "docker-cluster",
"status": "green",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 31,
"active_shards": 31,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"unassigned_primary_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100.0
}
シャードの一覧を確認するリクエスト
curl -X GET "http://localhost:9200/_cat/shards?v" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json"
ノードの一覧を確認するリクエスト
リクエストエンドポイントに「v」を指定することで、ヘッダーを追加できます。
その場合、クエリパラメータの開始を示す記号「?」を付けて、環境によってはリクエストエンドポイントを「"」で囲う必要があります。
$ curl -X GET "http://localhost:9200/_cat/nodes?v" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json"
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
172.19.0.2 17 79 0 2.15 2.11 2.02 cdfhilmrstw * 497b4c441b76
インデックス(indices)の一覧を確認するリクエスト
$ curl -X GET "http://localhost:9200/_cat/indices?v" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json"
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size dataset.size
green open .internal.alerts-transform.health.alerts-default-000001 3ZZViiw9QpqdRLiByu7vWQ 1 0 0 0 249b 249b 249b
green open .internal.alerts-observability.logs.alerts-default-000001 76rySWp_RqGltTwlygoZnw 1 0 0 0 249b 249b 249b
green open .internal.alerts-observability.uptime.alerts-default-000001 EsNFuZ5vQoi8a2QbLXb0dA 1 0 0 0 249b 249b 249b
green open .internal.alerts-ml.anomaly-detection.alerts-default-000001 _6JEIEoHRRufmMr13PoXog 1 0 0 0 249b 249b 249b
green open .internal.alerts-observability.slo.alerts-default-000001 1SdU85vWRU2dkkSJBoI5Dg 1 0 0 0 249b 249b 249b
green open .internal.alerts-default.alerts-default-000001 TQ3fbT7IT6OTE8ragudlkQ 1 0 0 0 249b 249b 249b
green open .internal.alerts-observability.apm.alerts-default-000001 en9gTEQnQKCZ9zicU2kE1Q 1 0 0 0 249b 249b 249b
green open .internal.alerts-observability.metrics.alerts-default-000001 Hi4Dd78cTFS-EKsOutoyWg 1 0 0 0 249b 249b 249b
green open .internal.alerts-ml.anomaly-detection-health.alerts-default-000001 ndXFIz0FQQGm_fMdELixuQ 1 0 0 0 249b 249b 249b
green open .internal.alerts-observability.threshold.alerts-default-000001 0SnoXu_LQ-K7KjqUGZWdAQ 1 0 0 0 249b 249b 249b
green open .internal.alerts-security.alerts-default-000001 gpwUjsj4RBWykZPr_MoydQ 1 0 0 0 249b 249b 249b
green open .internal.alerts-stack.alerts-default-000001 hiwZS1wmSliTdV-e5IQAbA 1 0 0 0 249b 249b 249b
システムインデックスを表示するには「&expand_wildcards=all」をリクエストエンドポイントに追加指定することで確認することができます。
これらはElasticsearchとKibanaの両方で様々なものを格納するために使用されるインデックスです。
インデックス名の先頭のピリオドは、 そのインデックスがシステムインデックスであることを示し、 デフォルトで非表示になることを意味します。
$ curl -X GET "http://localhost:9200/_cat/indices?v&expand_wildcards=all" -H "Authorization: ApiKey "${API_KEY}"" -H "Content-Type: application/json"
インデックスの作成
試しにpagesというインデックスを作成してみる
$ curl -X PUT http://localhost:9200/pages \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json"
{"acknowledged":true,"shards_acknowledged":true,"index":"pages"}
結果として、1シャード、1レプリカシャードで作成されました。
作成したpagesインデックスを確認する。
$ curl -X GET "http://localhost:9200/_cat/indices?v" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json"
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size dataset.size
~略~
green open .internal.alerts-observability.metrics.alerts-default-000001 Hi4Dd78cTFS-EKsOutoyWg 1 0 0 0 249b 249b 249b
yellow open pages ZnlKfdnbTIm_FMdC8JHeuA 1 1 0 0 227b 227b 227b
green open .internal.alerts-ml.anomaly-detection-health.alerts-default-000001 ndXFIz0FQQGm_fMdELixuQ 1 0 0 0 249b 249b 249b
~略~
補足説明
ステータスがyellowな理由はインデックスにはレプリカシャードが含まれていますが、そのシャードはどのノードにも割り当てられていないためです。
割り当てられない原因は、 レプリカシャードがプライマリシャードと同じノードに割り当てられないからです。
さらに、現在の環境はシングルノード構成のため割り当てるノード先がありません。
現在の状態としては、レプリカシャードは割り当て待ちの状態になっています。
この状態でノードがダウンすると、作成したpagesインデックスデータが失われます。
ここでシャードの一覧を確認してみると、1つ目のpagesインデックスがプライマリシャードに属しており、2つ目のpagesインデックスはレプリカシャードに属しています。
2つ目のpagesインデックスのステータスを確認すると、「UNASSIGNED」となっています。
$ curl -X GET "http://localhost:9200/_cat/shards?v" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json"
index shard prirep state docs store dataset ip node
~略~
pages 0 p STARTED 0 249b 249b 172.19.0.2 497b4c441b76
pages 0 r UNASSIGNED
~略~
インデックスの削除
先ほど作成したpagesインデックスを削除します。
$ curl -X DELETE http://localhost:9200/pages \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json"
{"acknowledged":true}%
インデックスの作成(シャードとレプリカシャードの指定)
インデックスを作成するときにシャードとレプリカシャードの指定する方法です。
今回はproductsというインデックス名で作成してみました。
$ curl -X PUT http://localhost:9200/products \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json"
-d '{"settings": {"number_of_shards": 2, "number_of_replicas": 2}}'
{"acknowledged":true,"shards_acknowledged":true,"index":"products"}
インデックスに対してドキュメントの追加
$ curl -X POST http://localhost:9200/products/_doc \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json" \
-d '{"name":"Coffee Maker", "price": 64, "in_stock": 10}'
{
"_index": "products",
"_id": "xJX24JUBd1DpRfTqB3DX",
"_version": 1,
"result": "created",
"_shards": {
"total": 3,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
"_shards"の"successful"の値が1となっているのは、シングルノードにも関わらずporductsインデックスを作成する際にシャードの複数設定を入れてしまったからですね。
また"_id"の値を任意に指定できます。
リクエスト例は以下のとおりです。
$ curl -sX PUT http://localhost:9200/products/_doc/100 \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json" \
-d '{"name":"Toaster", "price": 49, "in_stock": 4}' | jq
{
"_index": "products",
"_id": "100",
"_version": 2,
"result": "updated",
"_shards": {
"total": 3,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
複数JSONデータを一括でドキュメントに登録するリクエスト
複数行にまたがるJSONデータを取り込みたい場合は_bulkオプションを指定することで登録可能。
$ curl -X POST "http://localhost:9200/test_index/_bulk" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json" \
-d '
{"index": {"_index": "test_index", "_id": 1}}
{"id": 1,"title": "タイトル「あいうえお」 aIuEo","name": 461,"body": "「あいうえお」 aIuEo pjqCC"}
{"index": {"_index": "test_index", "_id": 2}}
{"id": 2,"title": "タイトル「かきくけこ」 KaKiKuKeKo","name": 570,"body": "「かきくけこ」 KaKiKuKeKo bad"}
{"index": {"_index": "test_index", "_id": 3}}
{"id": 3,"title": "タイトル「さしすせそ」 SaSiSuSeSo","name": 412,"body": "「さしすせそ」 SaSiSuSeSo qfVoF"}
{"index": {"_index": "test_index", "_id": 4}}
{"id": 4,"title": "タイトル「たちつてと」 TaTiTuTeTo","name": 182,"body": "WqDOp 「たちつてと」 TaTiTuTeTo"}
'
{"errors":false,"took":401,"items":[{"index":{"_index":"test_index","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1,"status":201}},{"index":{"_index":"test_index","_id":"2","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":1,"_primary_term":1,"status":201}},{"index":{"_index":"test_index","_id":"3","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":2,"_primary_term":1,"status":201}},{"index":{"_index":"test_index","_id":"4","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":3,"_primary_term":1,"status":201}}]}
jsonファイルを指定したドキュメント登録リクエスト
文字列でもファイルでも、共通して、フォーマットが決まっているので、そこは注意です。
またファイルで指定する場合は、ファイルの最終行に改行が必要になります。
$ curl -sX POST "http://localhost:9200/test_index/_bulk" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json" \
--data-binary @test_index.json
{"errors":false,"took":200,"items":[{"index":{"_index":"test_index","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1,"status":201}},{"index":{"_index":"test_index","_id":"2","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":1,"_primary_term":1,"status":201}},{"index":{"_index":"test_index","_id":"3","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":2,"_primary_term":1,"status":201}},{"index":{"_index":"test_index","_id":"4","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":3,"_primary_term":1,"status":201}}]}
{"index": {"_index": "test_index", "_id": 1}}
{"id": 1,"title": "タイトル「あいうえお」 aIuEo","name": 461,"body": "「あいうえお」 aIuEo pjqCC"}
{"index": {"_index": "test_index", "_id": 2}}
{"id": 2,"title": "タイトル「かきくけこ」 KaKiKuKeKo","name": 570,"body": "「かきくけこ」 KaKiKuKeKo bad"}
{"index": {"_index": "test_index", "_id": 3}}
{"id": 3,"title": "タイトル「さしすせそ」 SaSiSuSeSo","name": 412,"body": "「さしすせそ」 SaSiSuSeSo qfVoF"}
{"index": {"_index": "test_index", "_id": 4}}
{"id": 4,"title": "タイトル「たちつてと」 TaTiTuTeTo","name": 182,"body": "WqDOp 「たちつてと」 TaTiTuTeTo"}
<<改行入れる>>
<<改行入れる>>
ドキュメント検索APIリクエスト
ドキュメントのIDを指定した検索
インデックス名/_doc/ドキュメントIDを指定することで取得可能
$ curl -sX GET "http://localhost:9200/products/_doc/100" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json" | jq
{
"_index": "products",
"_id": "100",
"_version": 2,
"_seq_no": 1,
"_primary_term": 1,
"found": true,
"_source": {
"name": "Toaster",
"price": 49,
"in_stock": 4
}
}
【MATCH】クエリを使った全文検索
MATCHクエリを使うことで全文検索が行えます。
$ curl -sX GET "http://localhost:9200/test_index/_search" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json" \
-d '{"query": {"match": {"body": "あいうえお"}}}' | jq
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 6.019864,
"hits": [
{
"_index": "test_index",
"_id": "1",
"_score": 6.019864,
"_source": {
"id": 1,
"title": "タイトル「あいうえお」 aIuEo",
"name": 461,
"body": "「あいうえお」 aIuEo pjqCC"
}
}
]
}
}
"_source"の特定の値を指定する方法
$ curl -sX GET "http://localhost:9200/test_index/_search" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json" \
-d '{"_source": ["body"],"query": {"match": {"body": "あいう"}}}' | jq
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 3.6119184,
"hits": [
{
"_index": "test_index",
"_id": "1",
"_score": 3.6119184,
"_source": {
"body": "「あいうえお」 aIuEo pjqCC"
}
}
]
}
}
複数単語の検索リクエスト時にAND条件を使用する方法(デフォルトOR)
まずは、新たなにドキュメントを追加します。
url -X POST "http://localhost:9200/test_index/_bulk" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json" \
-d '
{"index": {"_index": "test_index", "_id": 5}}
{"id": 5,"title": "タイトル「なにぬねの」 NaNiNuNeNo","name": 461,"body": "「なにぬねの」 NaNiNuNeNo 「はひふへほ」 HaHiHuHeHo"}
{"index": {"_index": "test_index", "_id": 6}}
{"id": 6,"title": "タイトル「はひふへほ」 HaHiHuHeHo","name": 570,"body": "「なにぬねの」 NaNiNuNeNo 「はひふへほ」 HaHiHuHeHo"}
{"index": {"_index": "test_index", "_id": 7}}
{"id": 7,"title": "テスト test 7","name": 461,"body": "「なにぬねの」 NaNiNuNeNo"}
{"index": {"_index": "test_index", "_id": 8}}
{"id": 8,"title": "テスト test 8","name": 570,"body": "「はひふへほ」 HaHiHuHeHo"}
'
"bodu"の検索キーワードとして「なにぬねの」、「はひふへほ」の2つを指定します。
$ curl -sX GET "http://localhost:9200/test_index/_search" \
-H "Authorization: ApiKey ${API_KEY}" \
-H "Content-Type: application/json" \
-d '{
"_source": ["body"],
"query": {
"match": {
"body": "なにぬねの はひふへほ"
}
},
"fields": [],
"track_scores": false
}' | jq '.hits.hits[]._source.body'
以下の出力結果より、なにぬねの はひふへほ どちらか一方が含まれるドキュメント全て検索ヒットしました。
つまりElasticsearchはデフォルトでOR演算処理を行います。
"「なにぬねの」 NaNiNuNeNo 「はひふへほ」 HaHiHuHeHo"
"「なにぬねの」 NaNiNuNeNo 「はひふへほ」 HaHiHuHeHo"
"「なにぬねの」 NaNiNuNeNo"
"「はひふへほ」 HaHiHuHeHo"
続けてAND演算の処理を見てみます。
MATCHクエリにはoperatorというパラメータがあり、これを使用することでAND処理にすることができます。
$ curl -sX GET "http://localhost:9200/test_index/_search" \
-H "Authorization: ApiKey ${API_KEY}" \
-H "Content-Type: application/json" \
-d '{
"_source": ["body"],
"query": {
"match": {
"body": {
"query": "なにぬねの はひふへほ",
"operator": "and"
}
}
},
"fields": [],
"track_scores": false
}' | jq '.hits.hits[]._source.body'
"「なにぬねの」 NaNiNuNeNo 「はひふへほ」 HaHiHuHeHo"
"「なにぬねの」 NaNiNuNeNo 「はひふへほ」 HaHiHuHeHo"
SQL APIを使ったクエリ
$ curl -sX POST "http://localhost:9200/_sql" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json" \
-d '{"query": "SELECT * FROM test_index"}' | jq
{
"columns": [
{
"name": "body",
"type": "text"
},
{
"name": "id",
"type": "long"
},
{
"name": "name",
"type": "long"
},
{
"name": "title",
"type": "text"
}
],
"rows": [
[
"「あいうえお」 aIuEo pjqCC",
1,
461,
"タイトル「あいうえお」 aIuEo"
],
[
"「かきくけこ」 KaKiKuKeKo bad",
2,
570,
"タイトル「かきくけこ」 KaKiKuKeKo"
],
[
"「さしすせそ」 SaSiSuSeSo qfVoF",
3,
412,
"タイトル「さしすせそ」 SaSiSuSeSo"
],
[
"WqDOp 「たちつてと」 TaTiTuTeTo",
4,
182,
"タイトル「たちつてと」 TaTiTuTeTo"
],
[
"「なにぬねの」 NaNiNuNeNo 「はひふへほ」 HaHiHuHeHo",
5,
461,
"タイトル「なにぬねの」 NaNiNuNeNo"
],
[
"「なにぬねの」 NaNiNuNeNo 「はひふへほ」 HaHiHuHeHo",
6,
570,
"タイトル「はひふへほ」 HaHiHuHeHo"
],
[
"「なにぬねの」 NaNiNuNeNo",
7,
461,
"テスト test 7"
],
[
"「はひふへほ」 HaHiHuHeHo",
8,
570,
"テスト test 8"
]
]
}
複数のクエリを1つのリクエストで実行する方法
_msearchを利用することで、複数のリクエストを実行できます。
書き方はbulkと似ていますが、何故か、1行目のヘッダー{ }に空白行を入れないとエラーになる。。。。
The final line of data must end with a newline character \n. Each newline character may be preceded by a carriage return \r. When sending requests to this endpoint the Content-Type header should be set to application/x-ndjson.
$ curl -X GET "localhost:9200/_msearch?pretty"
-H 'Content-Type: application/x-ndjson'
-H "Authorization: ApiKey ${API_KEY}" -d'
{ }
{"query" : {"match" : { "body": "はひふへほ"}}}
{ }
{"query" : {"match" : { "body": "なにぬねの"}}}
{ }
{"query" : {"match" : { "body": "あいうえお"}}}
'
解析系
文字列がどのようにElasticsearchで解析されるか
$ curl -sX GET "http://localhost:9200/test_index/_analyze?pretty" -H "Authorization: ApiKey ${API_KEY}" -H "Content-Type: application/json" -d '{
"text": "「なにぬねの」 NaNiNuNeNo 「はひふへほ」 HaHiHuHeHo"
}'
以下結果より、Elasticsearchのデフォルトのアナライザーは日本語を1文字づつ解析しています。
またアルファベットは半角スペースごとに解析されていますね。英語の構造的に単語間は半角スペースで区切られているので、その影響かもしれません。
{
"tokens" : [
{
"token" : "な",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<HIRAGANA>",
"position" : 0
},
{
"token" : "に",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<HIRAGANA>",
"position" : 1
},
{
"token" : "ぬ",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<HIRAGANA>",
"position" : 2
},
{
"token" : "ね",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<HIRAGANA>",
"position" : 3
},
{
"token" : "の",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<HIRAGANA>",
"position" : 4
},
{
"token" : "naninuneno",
"start_offset" : 8,
"end_offset" : 18,
"type" : "<ALPHANUM>",
"position" : 5
},
{
"token" : "は",
"start_offset" : 20,
"end_offset" : 21,
"type" : "<HIRAGANA>",
"position" : 6
},
{
"token" : "ひ",
"start_offset" : 21,
"end_offset" : 22,
"type" : "<HIRAGANA>",
"position" : 7
},
{
"token" : "ふ",
"start_offset" : 22,
"end_offset" : 23,
"type" : "<HIRAGANA>",
"position" : 8
},
{
"token" : "へ",
"start_offset" : 23,
"end_offset" : 24,
"type" : "<HIRAGANA>",
"position" : 9
},
{
"token" : "ほ",
"start_offset" : 24,
"end_offset" : 25,
"type" : "<HIRAGANA>",
"position" : 10
},
{
"token" : "hahihuheho",
"start_offset" : 27,
"end_offset" : 37,
"type" : "<ALPHANUM>",
"position" : 11
}
]
}
EXPLAINを使った検索結果の詳細を見る
$ curl -sX GET "http://localhost:9200/test_index/_search" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json" \
-d '{"explain": true,"query": {"match": {"body": "なにぬねの"}}}' | jq
実行結果は長文になるため、見るべきポイントのみ紹介しておきます。
"description": "weight(body:な in 0) [PerFieldSimilarity], result of:",
上記はElasticsearch が body フィールド内の「な」という単語に対してスコアを計算する過程で、PerFieldSimilarity を使用していることを示しており、その計算に基づいてスコアが導かれることを説明しています。
具体的には、単語の出現頻度(TF)、ドキュメント中の単語の重要度(IDF)などがスコア計算に影響を与えます。
以下のとある"_explanation"を例に説明すると、まずElasticsearchは検索キーワードが検索対象とどれだけ関連性が高いかをスコアで判断しています。
"value": 1.0520585,の値がスコアの値です。
ではこのスコアはどのように算出されているのか、"score(freq=1.0), computed as boost * idf * tf from:"に記載の通りの計算式で算出されています。
-
boost:
ブースト値は、検索クエリやインデックス設定で指定される補正値です。特定のドキュメントやフィールドが他のものよりも重要である場合、この値を使ってそのドキュメントやフィールドのスコアを増加させます。 -
idf (Inverse Document Frequency):
IDFは、特定の単語がインデックス内でどれだけ稀少かを測る指標です。一般的に、珍しい単語ほど高いIDF値を持ちます。 -
tf (Term Frequency):
TFは、特定の単語がドキュメント内でどれだけ頻繁に出現するかを示します。頻繁に出現する単語は、そのドキュメントの重要な単語と見なされます。
"_explanation": {
"value": 1.0520585,
"description": "weight(body:naninuneno in 0) [PerFieldSimilarity], result of:",
"details": [
{
"value": 1.0520585,
"description": "score(freq=1.0), computed as boost * idf * tf from:",
"details": [
{
"value": 2.2,
"description": "boost",
"details": []
},
{
"value": 0.9444616,
"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details": [
{
"value": 3,
"description": "n, number of documents containing term",
"details": []
},
{
"value": 8,
"description": "N, total number of documents with field",
"details": []
}
]
},
{
"value": 0.50632906,
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details": [
{
"value": 1.0,
"description": "freq, occurrences of term within document",
"details": []
},
{
"value": 1.2,
"description": "k1, term saturation parameter",
"details": []
},
{
"value": 0.75,
"description": "b, length normalization parameter",
"details": []
},
{
"value": 6.0,
"description": "dl, length of field",
"details": []
},
{
"value": 8.0,
"description": "avgdl, average length of field",
"details": []
}
]
}
]
}
]
}
},
検索キーワードの一致箇所を教えてくれる
highlightを使用すると、検索結果の 1 つ以上のフィールドからハイライトされたスニペットを取得して、クエリが一致する場所をユーザーに示すことができます。
curl -sX GET "http://localhost:9200/test_index/_search" \
-H "Authorization: ApiKey "${API_KEY}"" \
-H "Content-Type: application/json" \
-d '{"query": {"match": {"body": "あいうえお"}}, "highlight": {"fields": {"body": {}}}}' | jq
以下出力結果より、"highlight"部分で"body"の「あいうえお」にヒットしたと教えてくれます。
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 9.4416065,
"hits": [
{
"_index": "test_index",
"_id": "1",
"_score": 9.4416065,
"_source": {
"id": 1,
"title": "タイトル「あいうえお」 aIuEo",
"name": 461,
"body": "「あいうえお」 aIuEo pjqCC"
},
"highlight": {
"body": [
"「<em>あ</em><em>い</em><em>う</em><em>え</em><em>お</em>」 aIuEo pjqCC"
]
}
}
]
}
}
補足
jqコマンドを使って"_source"の特定の値のみ表示させるリクエスト
$ curl -sX GET "http://localhost:9200/test_index/_search" \
-H "Authorization: ApiKey ${API_KEY}" \
-H "Content-Type: application/json" \
-d '{
"_source": ["body"],
"query": {
"match": {
"body": "いうえ"
}
},
"fields": [],
"track_scores": false
}' | jq '.hits.hits[]._source.body'
"「あいうえお」 aIuEo pjqCC"
elasticsearchはデフォルトで大文字小文字を区別しない動作となる
$ curl -sX GET "http://localhost:9200/test_index/_search" \
-H "Authorization: ApiKey ${API_KEY}" \
-H "Content-Type: application/json" \
-d '{
"_source": ["body"],
"query": {
"match": {
"body": "AIUEO"
}
},
"fields": [],
"track_scores": false
}' | jq '.hits.hits[]._source.body'
"「あいうえお」 aIuEo pjqCC"
$ curl -sX GET "http://localhost:9200/test_index/_search" \
-H "Authorization: ApiKey ${API_KEY}" \
-H "Content-Type: application/json" \
-d '{
"_source": ["body"],
"query": {
"match": {
"body": "aiueo"
}
},
"fields": [],
"track_scores": false
}' | jq '.hits.hits[]._source.body'
"「あいうえお」 aIuEo pjqCC"
$ curl -sX GET "http://localhost:9200/test_index/_search" \
-H "Authorization: ApiKey ${API_KEY}" \
-H "Content-Type: application/json" \
-d '{
"_source": ["body"],
"query": {
"match": {
"body": "AIueo"
}
},
"fields": [],
"track_scores": false
}' | jq '.hits.hits[]._source.body'
"「あいうえお」 aIuEo pjqCC"
Discussion