Snowpark for Pythonを使用したデータエンジニアリングとMLの入門
はじめに
Snowflake公式QuickStartの「Snowpark for Pythonを使用したデータエンジニアリングとMLの入門」をやってみました!
このQuickstartの推しポイント
Snowflakeの環境設定から始まり、データのモデリング、自動データパイプライン化、機械学習、最後はデータアプリケーションのデプロイまで一通り揃っている点です。
詳しくは以下の「Quickstart内の開発の流れ」のとおりです。
Quickstart内の開発の流れ
- 環境の設定:ステージとテーブルを使用して、S3からSnowflakeに未加工データを取り込み、整理します。
- データエンジニアリング:Snowpark for Python DataFramesを活用して、グループ化、集約、ピボット、結合などのデータ変換を実行し、下流のアプリケーション用のデータを準備します。
- データパイプライン:Snowflakeタスクを使用して、データパイプラインコードを、統合された監視を備えた運用パイプラインに変換します。
- 機械学習:データを準備し、SnowflakeでSnowpark MLを使用してMLトレーニングを実行し、Snowparkユーザー定義関数(UDF)としてモデルを展開します。
- Streamlitアプリケーション:Pythonを使用してインタラクティブなアプリケーションを構築し(ウェブ開発の経験は不要)、さまざまな広告費予算のROIの可視化を支援します。
Snowparkとは
主要な機能
-
Snowpark API
Sparkやスケーラブルなpandasでモデル化されたDataFrameを使用して、クエリの記述やデータ変換を行えます(パブリックプレビュー中)。 -
Snowpark ML API
Snowflake MLのMLライフサイクル全体にわたって、モデルや特徴量の開発と運用のための統合されたAPIへのアクセスを可能にするPythonライブラリです。 -
サポート言語(Python、Java、Scala)
ユーザー定義関数とストアドプロシージャを使用して、Python、Java、Scalaのカスタムコードを記述、実行できます。 -
Snowparkコンテナサービス
Snowflakeマネージドのインフラストラクチャ内で、コンテナイメージを登録、展開、実行できます(パブリックプレビュー中)。
詳しくは公式ドキュメントをご確認ください。
Streamlitとは
Streamlitは、開発者がデータアプリケーションをすばやく簡単に作成、共有、デプロイできるようにする、純粋なPythonのオープンソースアプリケーションフレームワークです。
詳しくは、Streamlitのドキュメントをご確認ください。
Quickstartで学習する内容
- Snowpark DataFramesとAPIを利用してデータを分析し、データエンジニアリングタスクを実行する方法
- 厳選されたSnowflake AnacondaチャネルからオープンソースのPythonライブラリを使用する方法
- SnowflakeでSnowpark MLを使用してMLモデルをトレーニングする方法
- オンライン推論とオフライン推論のそれぞれに、スカラーおよびベクトル化されたSnowpark Pythonユーザー定義関数(UDF)を作成する方法
- Snowflakeタスクを作成してデータパイプラインを自動化する方法
- ユーザー入力に基づく推論にスカラーUDFを使用するStreamlitウェブアプリケーションを作成する方法
前提条件
- Gitがインストールされていること
- Python 3.9がインストールされていること
- ORGADMINによって有効化されたAnacondaパッケージを持つSnowflakeアカウント。
Snowflakeアカウントをお持ちでない場合は、無料トライアルアカウントに登録できます。
アカウント管理者の役割を持つSnowflakeアカウントを利用可能なこと。
もしくはデータベース、スキーマ、テーブル、ステージ、タスク、ユーザー定義関数、ストアドプロシージャを作成できる権限を有するアカウントを利用可能なこと
環境構築
ウェアハウス、データベース、スキーマを作成
USE ROLE ACCOUNTADMIN;
CREATE OR REPLACE WAREHOUSE DASH_L;
CREATE OR REPLACE DATABASE DASH_DB;
CREATE OR REPLACE SCHEMA DASH_SCHEMA;
USE DASH_DB.DASH_SCHEMA;
S3にあるデータをテーブルCAMPAIGN_SPENDに作成
CREATE or REPLACE file format csvformat
skip_header = 1
type = 'CSV';
CREATE or REPLACE stage campaign_data_stage
file_format = csvformat
url = 's3://sfquickstarts/ad-spend-roi-snowpark-python-scikit-learn-streamlit/campaign_spend/';
CREATE or REPLACE TABLE CAMPAIGN_SPEND (
CAMPAIGN VARCHAR(60),
CHANNEL VARCHAR(60),
DATE DATE,
TOTAL_CLICKS NUMBER(38,0),
TOTAL_COST NUMBER(38,0),
ADS_SERVED NUMBER(38,0)
);
COPY into CAMPAIGN_SPEND from @campaign_data_stage;
S3にあるデータをテーブルMONTHLY_REVENUEに作成
CREATE or REPLACE stage monthly_revenue_data_stage
file_format = csvformat
url = 's3://sfquickstarts/ad-spend-roi-snowpark-python-scikit-learn-streamlit/monthly_revenue/';
CREATE or REPLACE TABLE MONTHLY_REVENUE (
YEAR NUMBER(38,0),
MONTH NUMBER(38,0),
REVENUE FLOAT
);
COPY into MONTHLY_REVENUE from @monthly_revenue_data_stage;
過去6か月間の予算割り当てとROIを保持するテーブルBUDGET_ALLOCATIONS_AND_ROIを作成
CREATE or REPLACE TABLE BUDGET_ALLOCATIONS_AND_ROI (
MONTH varchar(30),
SEARCHENGINE integer,
SOCIALMEDIA integer,
VIDEO integer,
EMAIL integer,
ROI float
)
COMMENT = '{"origin":"sf_sit-is", "name":"aiml_notebooks_ad_spend_roi", "version":{"major":1, "minor":0}, "attributes":{"is_quickstart":1, "source":"streamlit"}}';
INSERT INTO BUDGET_ALLOCATIONS_AND_ROI (MONTH, SEARCHENGINE, SOCIALMEDIA, VIDEO, EMAIL, ROI)
VALUES
('January',35,50,35,85,8.22),
('February',75,50,35,85,13.90),
('March',15,50,35,15,7.34),
('April',25,80,40,90,13.23),
('May',95,95,10,95,6.246),
('June',35,50,35,85,8.22);
ストアドプロシージャ、UDF、MLモデルファイル用の内部ステージの作成
CREATE OR REPLACE STAGE dash_sprocs;
CREATE OR REPLACE STAGE dash_models;
CREATE OR REPLACE STAGE dash_udfs;
GitHubレポジトリの複製とSnowpark for Pythonの準備
GitHubレポジトリの複製
ローカルマシンの任意のディレクトリにてgit cloneを実施する
$ git clone https://github.com/Snowflake-Labs/sfguide-getting-started-dataengineering-ml-snowpark-python.git
Snowpark for Python(とstreamlit)のインストール
私の場合snowflake.coreがインストールされていなかったので一緒にインストールしました。
pip install snowflake-ml-python streamlit snowflake.core
scikit-learnのバージョンをSnowflakeサポートバージョンと合わせる
(venv) kyamisama % pip freeze | grep scikit-learn
scikit-learn==1.5.2
(venv) kyamisama % pip install scikit-learn==1.5.1
(venv) kyamisama % pip freeze | grep scikit-learn
scikit-learn==1.5.1
modelトレーニング時にscikit-learnバージョン不一致が起きていると次の警告が出ます。
InconsistentVersionWarning: Trying to unpickle estimator GridSearchCV from version 1.5.1 when using version 1.5.2. This might lead to breaking code or invalid results. Use at your own risk. For more info please refer to:
Quickstartプロジェクト概要
Snowpark for Python、Snowpark ML、Streamlitを使用して、検索、動画、ソーシャルメディア、電子メールなど、複数のチャネルで変動する広告費予算の将来のROI(Return On Investment)を予測する線形回帰モデルを学習するためのデータ分析とデータ準備タスクを実行します。
学習データを作成後、さまざまな広告費予算のROIを可視化するインタラクティブなWebアプリケーションをデプロイします。
データエンジニアリング
ここからはローカルにクローンしたQuickstart用のレポジトリ内のNotebookを使って、Pythonコードを実行していきます。
備忘録的にSnowparkを使ったデータ操作の説明を記載しています。
※Quickstart内でもコードの説明はされています
SnowflakeテーブルからSnowpark DataFramesへのデータのロード
まずキャンペーン費用データをロードしましょう。このテーブルには、検索エンジン、ソーシャルメディア、Eメール、動画などのデジタル広告チャネルにおける日々の支出を示すために集計された広告クリックデータが含まれています。
snow_df_spend = session.table('campaign_spend')
Snowpark DataFrames で探索的データ分析を実行する
Dataframe型で取り込んだsnow_df_spendを使って、YEAR(DATE), MONTH(DATE), CHANNEL ごとに TOTAL_COST の合計を計算し、snow_df_spend_per_channelに格納します。
snow_df_spend_per_channel = snow_df_spend.group_by(year('DATE'), month('DATE'),'CHANNEL').agg(sum('TOTAL_COST').as_('TOTAL_COST')).\
with_column_renamed('"YEAR(DATE)"',"YEAR").with_column_renamed('"MONTH(DATE)"',"MONTH").sort('YEAR','MONTH')
snow_df_spend_per_channel.show(10)
---------------------------------------------------
|"YEAR" |"MONTH" |"CHANNEL" |"TOTAL_COST" |
---------------------------------------------------
|2012 |5 |search_engine |516431 |
|2012 |5 |video |516729 |
|2012 |5 |email |517208 |
|2012 |5 |social_media |517618 |
|2012 |6 |video |501098 |
|2012 |6 |social_media |504679 |
|2012 |6 |email |501947 |
|2012 |6 |search_engine |506497 |
|2012 |7 |search_engine |522780 |
|2012 |7 |video |522762 |
---------------------------------------------------
Snowpark DataFramesを使用して、複数のテーブルからデータをピボットおよび結合する
続いてCHANNELごとのPIVOTテーブルを作成します。
snow_df_spend_per_month = snow_df_spend_per_channel.pivot('CHANNEL',['search_engine','social_media','video','email']).sum('TOTAL_COST').sort('YEAR','MONTH')
snow_df_spend_per_month = snow_df_spend_per_month.select(
col("YEAR"),
col("MONTH"),
col("'search_engine'").as_("SEARCH_ENGINE"),
col("'social_media'").as_("SOCIAL_MEDIA"),
col("'video'").as_("VIDEO"),
col("'email'").as_("EMAIL")
)
snow_df_spend_per_month.show()
---------------------------------------------------------------------------
|"YEAR" |"MONTH" |"SEARCH_ENGINE" |"SOCIAL_MEDIA" |"VIDEO" |"EMAIL" |
---------------------------------------------------------------------------
|2012 |5 |516431 |517618 |516729 |517208 |
|2012 |6 |506497 |504679 |501098 |501947 |
|2012 |7 |522780 |521395 |522762 |518405 |
|2012 |8 |519959 |520537 |520685 |521584 |
|2012 |9 |507211 |507404 |511364 |507363 |
|2012 |10 |518942 |520863 |522768 |519950 |
|2012 |11 |505715 |505221 |505292 |503748 |
|2012 |12 |520148 |520711 |521427 |520724 |
|2013 |1 |522151 |518635 |520583 |521167 |
|2013 |2 |467736 |474679 |469856 |469784 |
---------------------------------------------------------------------------
snow_df_spend_per_monthをSPEND_PER_MONTHテーブルとして保存します。
snow_df_spend_per_month.write.mode('overwrite').save_as_table('SPEND_PER_MONTH')
続いて、月次収益(MONTHLY_REVENUEテーブル)を使ってYEAR、MONTHごとの収益の合算値を抽出します。
snow_df_revenue = session.table('monthly_revenue')
snow_df_revenue_per_month = snow_df_revenue.group_by('YEAR','MONTH').agg(sum('REVENUE')).sort('YEAR','MONTH').with_column_renamed('SUM(REVENUE)','REVENUE')
snow_df_revenue_per_month.show()
---------------------------------
|"YEAR" |"MONTH" |"REVENUE" |
---------------------------------
|2012 |5 |3264300.11 |
|2012 |6 |3208482.33 |
|2012 |7 |3311966.98 |
|2012 |8 |3311752.81 |
|2012 |9 |3208563.06 |
|2012 |10 |3334028.46 |
|2012 |11 |3185894.64 |
|2012 |12 |3334570.96 |
|2013 |1 |3316455.44 |
|2013 |2 |2995042.21 |
---------------------------------
最後、入力特徴(チャネルごとのコストなど)とターゲット変数(収益など)をモデルトレーニングのために1つのテーブルにロードできるように、変換されたキャンペーン支出データとこの収益データを結合してみます。
結合キーは["YEAR","MONTH"]です。
snow_df_spend_and_revenue_per_month = snow_df_spend_per_month.join(snow_df_revenue_per_month, ["YEAR","MONTH"])
snow_df_spend_and_revenue_per_month.show()
----------------------------------------------------------------------------------------
|"YEAR" |"MONTH" |"SEARCH_ENGINE" |"SOCIAL_MEDIA" |"VIDEO" |"EMAIL" |"REVENUE" |
----------------------------------------------------------------------------------------
|2012 |5 |516431 |517618 |516729 |517208 |3264300.11 |
|2012 |6 |506497 |504679 |501098 |501947 |3208482.33 |
|2012 |7 |522780 |521395 |522762 |518405 |3311966.98 |
|2012 |8 |519959 |520537 |520685 |521584 |3311752.81 |
|2012 |9 |507211 |507404 |511364 |507363 |3208563.06 |
|2012 |10 |518942 |520863 |522768 |519950 |3334028.46 |
|2012 |11 |505715 |505221 |505292 |503748 |3185894.64 |
|2012 |12 |520148 |520711 |521427 |520724 |3334570.96 |
|2013 |1 |522151 |518635 |520583 |521167 |3316455.44 |
|2013 |2 |467736 |474679 |469856 |469784 |2995042.21 |
----------------------------------------------------------------------------------------
snow_df_spend_and_revenue_per_monthをSPEND_AND_REVENUE_PER_MONTHテーブルとして保存する。
snow_df_spend_and_revenue_per_month.write.mode('overwrite').save_as_table('SPEND_AND_REVENUE_PER_MONTH')
Snowflake Tasksを使用したデータ準備の自動化
SPEND_AND_REVENUE_PER_MONTHやSPEND_PER_MONTHの2テーブルを作成するデータ処理をストアドプロシージャを作成します。
SPEND_PER_MONTHテーブルのストアドプロシージャ
変換を実行するストアドプロシージャを作成します。
ストアドプロシージャ内の処理は上記で実行したデータ処理と同じです。
def campaign_spend_data_pipeline(session: Session) -> str:
snow_df_spend_t = session.table('campaign_spend')
snow_df_spend_per_channel_t = snow_df_spend_t.group_by(year('DATE'), month('DATE'),'CHANNEL').agg(sum('TOTAL_COST').as_('TOTAL_COST')).\
with_column_renamed('"YEAR(DATE)"',"YEAR").with_column_renamed('"MONTH(DATE)"',"MONTH").sort('YEAR','MONTH')
snow_df_spend_per_month_t = snow_df_spend_per_channel_t.pivot('CHANNEL',['search_engine','social_media','video','email']).sum('TOTAL_COST').sort('YEAR','MONTH')
snow_df_spend_per_month_t = snow_df_spend_per_month_t.select(
col("YEAR"),
col("MONTH"),
col("'search_engine'").as_("SEARCH_ENGINE"),
col("'social_media'").as_("SOCIAL_MEDIA"),
col("'video'").as_("VIDEO"),
col("'email'").as_("EMAIL")
)
snow_df_spend_per_month_t.write.mode('overwrite').save_as_table('SPEND_PER_MONTH')
SPEND_AND_REVENUE_PER_MONTHテーブルのストアドプロシージャ
変換を実行するストアドプロシージャを作成します。
ストアドプロシージャ内の処理はSPEND_AND_REVENUE_PER_MONTHテーブルを作成した時に実行したデータ処理と同じです。
def monthly_revenue_data_pipeline(session: Session) -> str:
snow_df_spend_per_month_t = session.table('spend_per_month')
snow_df_revenue_t = session.table('monthly_revenue')
snow_df_revenue_per_month_t = snow_df_revenue_t.group_by('YEAR','MONTH').agg(sum('REVENUE')).sort('YEAR','MONTH').with_column_renamed('SUM(REVENUE)','REVENUE')
snow_df_spend_and_revenue_per_month_t = snow_df_spend_per_month_t.join(snow_df_revenue_per_month_t, ["YEAR","MONTH"])
snow_df_spend_and_revenue_per_month_t.write.mode('overwrite').save_as_table('SPEND_AND_REVENUE_PER_MONTH')
お好みで作成したストアドプロシージャを定期的に呼び出すTASKを作成し、自動データパイプラインを作成します。
気になる方は以下クイックスタートよりサンプルコードを参照してください。
親タスク
def campaign_spend_data_pipeline(session: Session) -> str:
# DATA TRANSFORMATIONS
# Perform the following actions to transform the data
# Load the campaign spend data
snow_df_spend_t = session.table('campaign_spend')
# Transform the data so we can see total cost per year/month per channel using group_by() and agg() Snowpark DataFrame functions
snow_df_spend_per_channel_t = snow_df_spend_t.group_by(year('DATE'), month('DATE'),'CHANNEL').agg(sum('TOTAL_COST').as_('TOTAL_COST')).\
with_column_renamed('"YEAR(DATE)"',"YEAR").with_column_renamed('"MONTH(DATE)"',"MONTH").sort('YEAR','MONTH')
# Transform the data so that each row will represent total cost across all channels per year/month using pivot() and sum() Snowpark DataFrame functions
snow_df_spend_per_month_t = snow_df_spend_per_channel_t.pivot('CHANNEL',['search_engine','social_media','video','email']).sum('TOTAL_COST').sort('YEAR','MONTH')
snow_df_spend_per_month_t = snow_df_spend_per_month_t.select(
col("YEAR"),
col("MONTH"),
col("'search_engine'").as_("SEARCH_ENGINE"),
col("'social_media'").as_("SOCIAL_MEDIA"),
col("'video'").as_("VIDEO"),
col("'email'").as_("EMAIL")
)
# Save transformed data
snow_df_spend_per_month_t.write.mode('overwrite').save_as_table('SPEND_PER_MONTH')
# Register data pipelining function as a Stored Procedure so it can be run as a task
session.sproc.register(
func=campaign_spend_data_pipeline,
name="campaign_spend_data_pipeline",
packages=['snowflake-snowpark-python'],
is_permanent=True,
stage_location="@dash_sprocs",
replace=True)
campaign_spend_data_pipeline_task = """
CREATE OR REPLACE TASK campaign_spend_data_pipeline_task
WAREHOUSE = 'DASH_L'
SCHEDULE = '3 MINUTE'
AS
CALL campaign_spend_data_pipeline()
"""
session.sql(campaign_spend_data_pipeline_task).collect()
子タスク
def monthly_revenue_data_pipeline(session: Session) -> str:
# Load revenue table and transform the data into revenue per year/month using group_by and agg() functions
snow_df_spend_per_month_t = session.table('spend_per_month')
snow_df_revenue_t = session.table('monthly_revenue')
snow_df_revenue_per_month_t = snow_df_revenue_t.group_by('YEAR','MONTH').agg(sum('REVENUE')).sort('YEAR','MONTH').with_column_renamed('SUM(REVENUE)','REVENUE')
# Join revenue data with the transformed campaign spend data so that our input features (i.e. cost per channel) and target variable (i.e. revenue) can be loaded into a single table for model training
snow_df_spend_and_revenue_per_month_t = snow_df_spend_per_month_t.join(snow_df_revenue_per_month_t, ["YEAR","MONTH"])
# SAVE in a new table for the next task
snow_df_spend_and_revenue_per_month_t.write.mode('overwrite').save_as_table('SPEND_AND_REVENUE_PER_MONTH')
# Register data pipelining function as a Stored Procedure so it can be run as a task
session.sproc.register(
func=monthly_revenue_data_pipeline,
name="monthly_revenue_data_pipeline",
packages=['snowflake-snowpark-python'],
is_permanent=True,
stage_location="@dash_sprocs",
replace=True)
monthly_revenue_data_pipeline_task = """
CREATE OR REPLACE TASK monthly_revenue_data_pipeline_task
WAREHOUSE = 'DASH_L'
AFTER campaign_spend_data_pipeline_task
AS
CALL monthly_revenue_data_pipeline()
"""
session.sql(monthly_revenue_data_pipeline_task).collect()
機械学習
モデルトレーニングのために特徴量を準備する
# データをロードする
snow_df_spend_and_revenue_per_month = session.table('spend_and_revenue_per_month')
# 欠損値のある行を削除する
snow_df_spend_and_revenue_per_month = snow_df_spend_and_revenue_per_month.dropna()
# モデリングに不要な列を除外する
snow_df_spend_and_revenue_per_month = snow_df_spend_and_revenue_per_month.drop(['YEAR','MONTH'])
# MARKETING_BUDGETS_FEATURESというSnowflakeテーブルに特徴を保存する
snow_df_spend_and_revenue_per_month.write.mode('overwrite').save_as_table('MARKETING_BUDGETS_FEATURES')
snow_df_spend_and_revenue_per_month.show()
SnowflakeでSnowpark MLを使用してMLモデルをトレーニングする
機械学習用コード
# 交差検証用の定数の設定
## データセットを10個に分割し、それぞれを検証用データとして使用し、モデルを評価
CROSS_VALIDATION_FOLDS = 10
## 多項式特徴量の次数を設定
POLYNOMIAL_FEATURES_DEGREE = 2
# トレーニングデータとテストデータの作成
## データをランダムに分割して、トレーニング用(80%)とテスト用(20%)に分ける
train_df, test_df = session.table("MARKETING_BUDGETS_FEATURES").random_split(weights=[0.8, 0.2], seed=0)
# 数値列の前処理
## 前処理する数値型の列を指定
numeric_features = ['SEARCH_ENGINE','SOCIAL_MEDIA','VIDEO','EMAIL']
## PolynomialFeatures: 特徴量を多項式に変換。
## StandardScaler: 各特徴量を標準化(平均0、分散1)
numeric_transformer = Pipeline(steps=[('poly',PolynomialFeatures(degree = POLYNOMIAL_FEATURES_DEGREE)),('scaler', StandardScaler())])
# カラムの結合と前処理の統合
## 'num': 数値型の列に対して、numeric_transformer を適用
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features)])
# モデルパイプラインの構築
## preprocessor: データの前処理ステップ
## classifier: 学習アルゴリズムとして線形回帰(LinearRegression)を使用
pipeline = Pipeline(steps=[('preprocessor', preprocessor),('classifier', LinearRegression())])
parameteres = {}
# グリッドサーチによる最適化
## GridSearchCV: モデルのハイパーパラメータを調整するためのツール。ここではデフォルトのパラメータを使用
### cv: 交差検証の分割数(10分割)
### label_cols: 目的変数(ラベル)として使用する列(REVENUE)
### output_cols: モデルの予測結果を格納する列(PREDICTED_REVENUE)
### verbose: ログの詳細度。
model = GridSearchCV(
estimator=pipeline,
param_grid=parameteres,
cv=CROSS_VALIDATION_FOLDS,
label_cols=["REVENUE"],
output_cols=["PREDICTED_REVENUE"],
verbose=2
)
# モデルの学習と評価
## fit: トレーニングデータを用いてモデルを学習
## score: R2スコア(決定係数)を計算。値が1に近いほどモデルの説明力が高い
model.fit(train_df)
train_r2_score = model.score(train_df)
test_r2_score = model.score(test_df)
# 学習結果を表示
print(f"R2 score on Train : {train_r2_score}")
print(f"R2 score on Test : {test_r2_score}")
R2 score on Train : 0.9951076702244089
R2 score on Test : 0.9069318156071831
MLモデルを登録し、Snowpark ML Model Registryから推論に使用する
学習済みモデルをSnowflakeモデルレジストリに記録する
モデルレジストリでは、モデルをオブジェクトとしてSnowflakeのスキーマに保存することができます。デフォルトでは、セッションのデータベースとスキーマが使用されることに注意してください。
registry = Registry(session)
MODEL_NAME = "PREDICT_ROI"
mv = registry.log_model(model,
model_name=MODEL_NAME,
version_name="v1",
metrics={"R2_train": train_r2_score, "R2_test":test_r2_score},
comment='Model pipeline to predict revenue',
options={"relax_version": False}
)
推論
モデルが記録されると、新しいデータに対する推論に使用することができます。
まず、いくつかのサンプルデータでSnowpark DataFrameを作成し、新しい予測値を得るためにログされたモデルを呼び出します
test_df = session.create_dataframe([[250000,250000,200000,450000],[500000,500000,500000,500000],[8500,9500,2000,500]],
schema=['SEARCH_ENGINE','SOCIAL_MEDIA','VIDEO','EMAIL'])
mv.run(test_df, function_name='predict').show()
推論の結果として、PREDICTED_REVENUEの1,2行目が負の値になっているのが気になりますね。
原因として考えられるのは、モデルが適切に学習できていない点ですね。
------------------------------------------------------------------------------
|"SEARCH_ENGINE" |"SOCIAL_MEDIA" |"VIDEO" |"EMAIL" |"PREDICTED_REVENUE" |
------------------------------------------------------------------------------
|250000 |250000 |200000 |450000 |-12735698.047846342 |
|8500 |9500 |2000 |500 |-107984.61196421506 |
|500000 |500000 |500000 |500000 |3180176.674854816 |
------------------------------------------------------------------------------
データアプリケーションのデプロイ
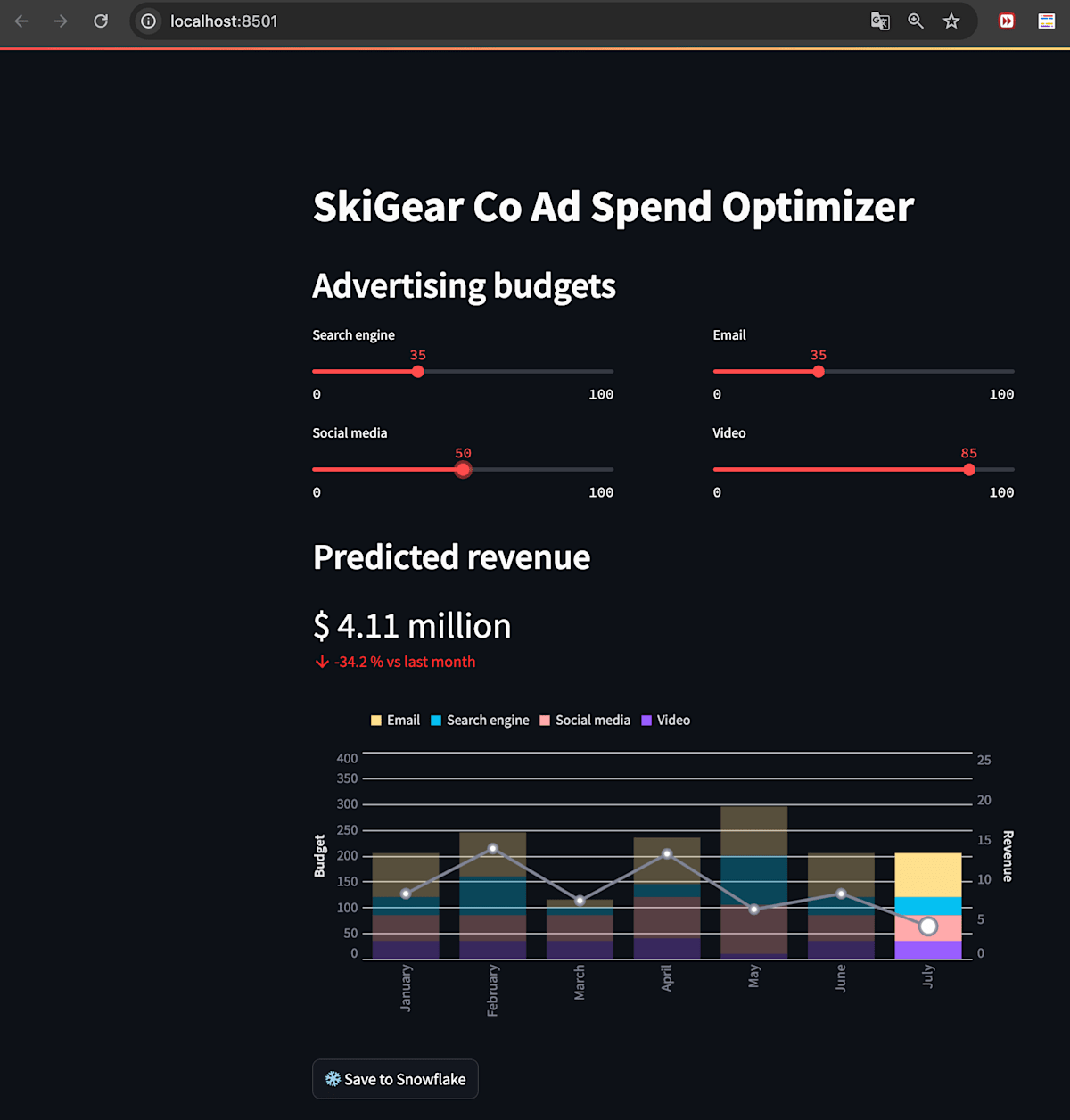
一応最後、収益を予測するデータアプリケーションをStreamlitでデプロイするとこんな感じになります。
budgetsスライダーを増減することで、予測収益グラフで予測した結果を描画してくれます。
streamlit run Snowpark_Streamlit_Revenue_Prediction.py
最後に
初めてSnowparkを使って、データ操作からMLのモデル作成、Streamlitを使ったデータアプリケーションを体験してみました。
データのクレンジングから学習用データを作成するフェーズはSQLでもできると思いますが、やっぱりPythonでの直感的なコードで実現できるのは大きなメリットだと感じました。
他にもストアドプロシージャやTASKを作成するAPIも提供されており、いつもSQLでやっていることをPythonで実現できるようになっています。
こうなると、SQLとPythonどっちで開発するのがいいか問題が出ると思いますが、以前SnowflakeのイベントでSnowpark詳しい人が「SQLでできることはSQLでやり、どうしもてプログラミング的な処理が必要な場合にSnowparkを利用する」と言ってました。
是非、SQLとプログラミング言語をいい感じに使い分けて、より良い開発ライフを送りましょう!
Discussion