Snowflakeデータロード時の豆知識


今回は外部テーブルからデータをロードする際に欲しいデータを抽出する方法を試したいともいます。
前回の記事の続きです。
特定のカラムを指定してロードする
前回記事で使用したデータを使用します。
今回想定するケース
ORDER_IDとAMOUNTの2つのカラムを指定しロードしてみます。
テーブルの作成
CREATE OR REPLACE TABLE OUR_FIRST_DB.PUBLIC.ORDERS_EX (
ORDER_ID VARCHAR(30),
AMOUNT INT
)
カラムを指定したロード
Snowflakeはデータのロード時に絡む指定をする際はエイリアス指定する必要があります。
詳細はドキュメントを参照ください。
COPY INTO OUR_FIRST_DB.PUBLIC.ORDERS_EX
FROM (select s.$1, s.$2 from @MANAGE_DB.external_stages.aws_stage s)
file_format= (type = csv field_delimiter=',' skip_header=1)
files=('OrderDetails.csv');
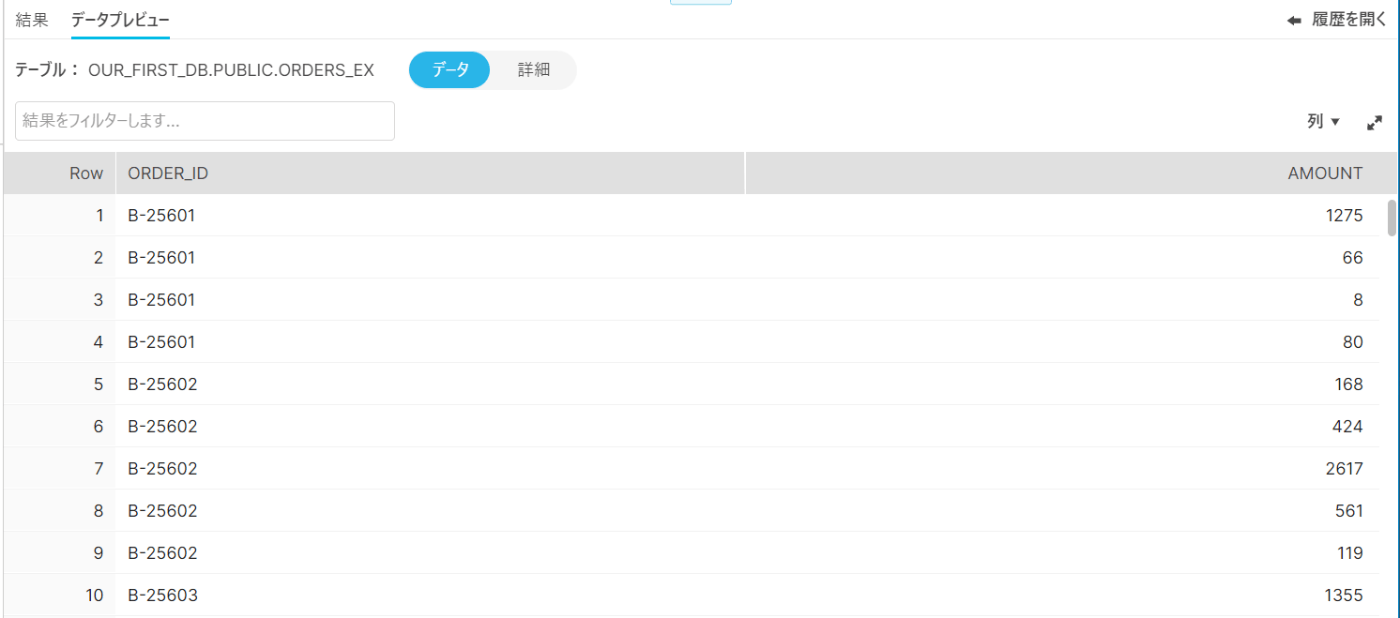
確認
ロードした結果は下記の通り、ORDER_IDとAMOUNTのみロードされている。
データ型を変換し条件指定を含んだロード
今回想定するケース
OrderDetails.csvの3カラム目のPROFITの値で0以下の場合、PROFITABLE_FLAGにnot profitableを入れ、0以上の場合はprofitableを書き込む。
テーブルの作成
先ほど作成したテーブルORDERS_EXにPROFITABLE_FLAG VARCHAR(30)を追加し、再作成します。
CREATE OR REPLACE TABLE OUR_FIRST_DB.PUBLIC.ORDERS_EX (
ORDER_ID VARCHAR(30),
AMOUNT INT,
PROFIT INT,
PROFITABLE_FLAG VARCHAR(30)
)
変換と条件指定したロード
CASE WHENは条件式関数であり、ここでは$3の値が0以下ならnot~で0以上ならprofitableをPROFITABLE_FLAGに書き込む
その際CAST関数で$3の値を数値型に変換している。
COPY INTO OUR_FIRST_DB.PUBLIC.ORDERS_EX
FROM (select
s.$1,
s.$2,
s.$3,
CASE WHEN CAST(s.$3 as int) < 0 THEN 'not profitable' ELSE 'profitable' END
from @MANAGE_DB.external_stages.aws_stage s)
file_format= (type = csv field_delimiter=',' skip_header=1)
files=('OrderDetails.csv');
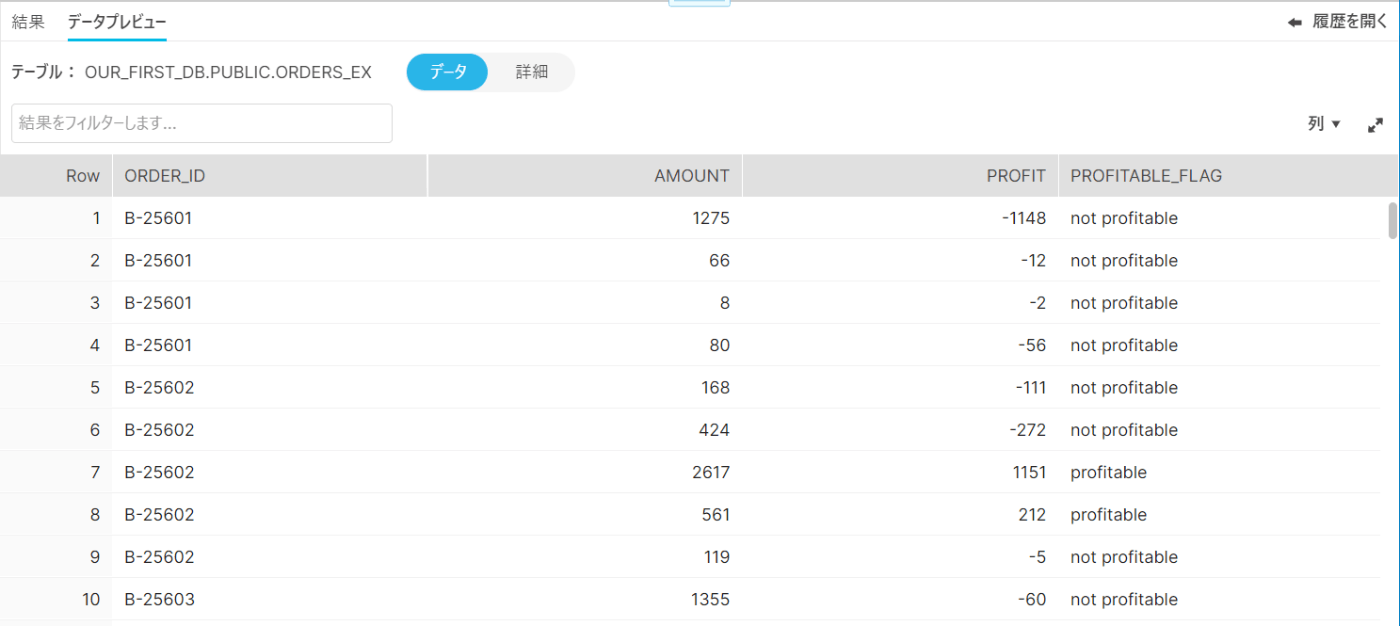
確認
コマンドの結果通りにロードされていることを確認する。
フィールド値の加工
今回想定するケース
OrderDetails.csvのCATEGORYカラムのフィールド値の先頭5文字だけを取得します。
テーブルの作成
CREATE OR REPLACE TABLE OUR_FIRST_DB.PUBLIC.ORDERS_EX (
ORDER_ID VARCHAR(30),
AMOUNT INT,
PROFIT INT,
CATEGORY_SUBSTRING VARCHAR(5)
)
先頭5文字抽出ロード
5文字抽出のためにsubstring関数を利用しています。
詳しくはドキュメントを参照ください。
COPY INTO OUR_FIRST_DB.PUBLIC.ORDERS_EX
FROM (select
s.$1,
s.$2,
s.$3,
substring(s.$5,1,5)
from @MANAGE_DB.external_stages.aws_stage s)
file_format= (type = csv field_delimiter=',' skip_header=1)
files=('OrderDetails.csv');
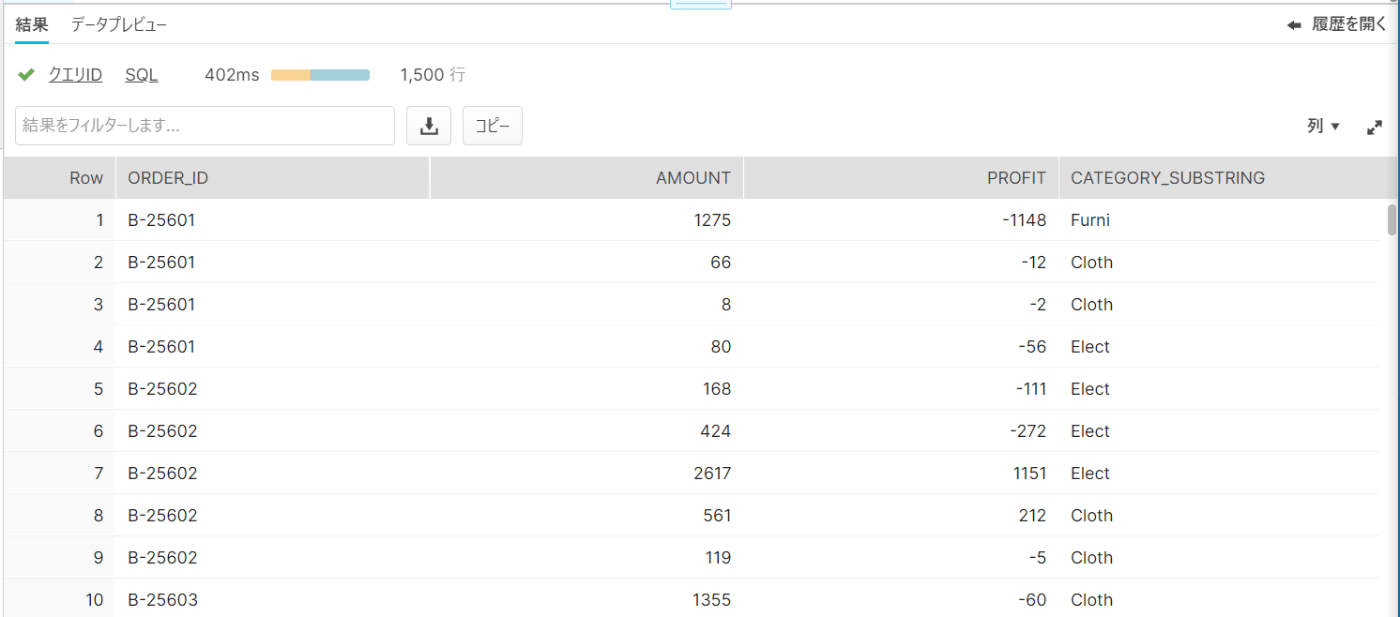
確認
CATEGORY_SUBSTRINGを確認するとすべて先頭5文字のみ抽出されています。
指定したカラムのみロードし、それ以外はNULLにする
今回想定するケース
下記カラムがあるとし、その中でORDER_IDとPROFITのみロードしたい
| ORDER_ID | AMOUNT | PROFIT | PROFITLABEL_FLAG |
|---|
テーブルの作成
CREATE OR REPLACE TABLE OUR_FIRST_DB.PUBLIC.ORDERS_EX (
ORDER_ID VARCHAR(30),
AMOUNT INT,
PROFIT INT,
PROFITABLE_FLAG VARCHAR(30)
)
カラムを指定しロード
1行目の(ORDER_ID,PROFIT)でカラムを指定している
COPY INTO OUR_FIRST_DB.PUBLIC.ORDERS_EX (ORDER_ID,PROFIT)
FROM (select
s.$1,
s.$3
from @MANAGE_DB.external_stages.aws_stage s)
file_format= (type = csv field_delimiter=',' skip_header=1)
files=('OrderDetails.csv');
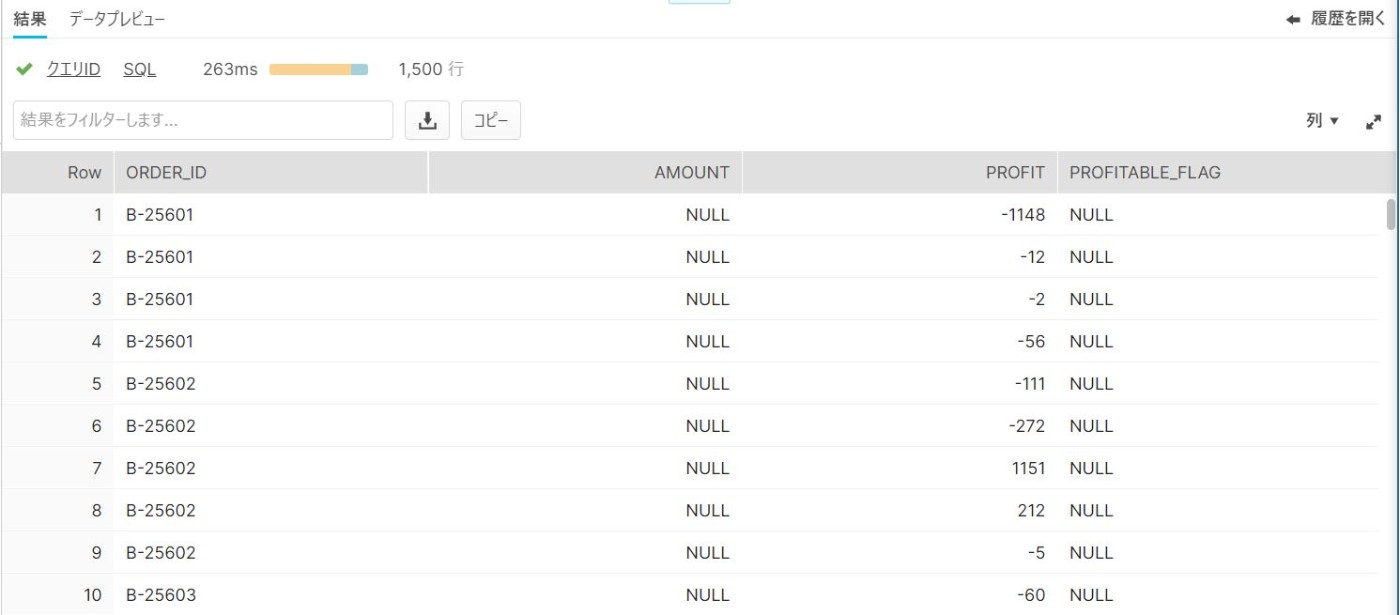
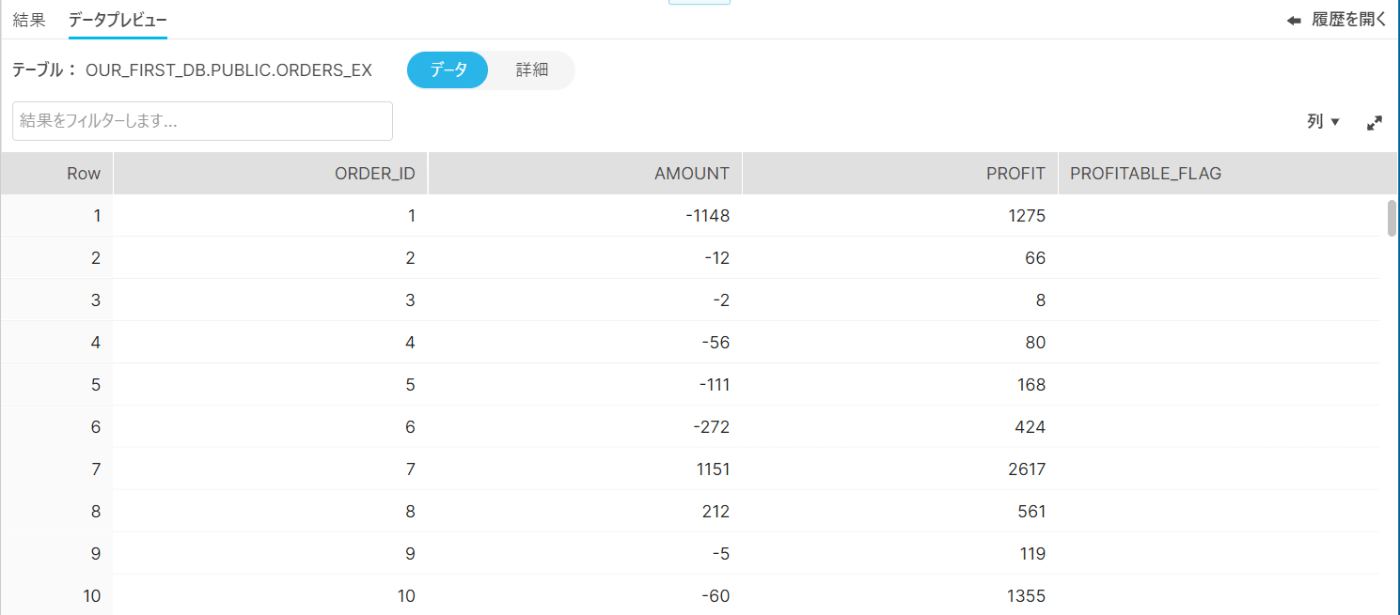
結果
コマンド通りの結果となっている。
自動インクリメントロード
今回想定するケース
1からの連番で番号を振りなおしてみます。
テーブルの作成
ORDER_IDカラムに自動インクリメントを設定します。
CREATE OR REPLACE TABLE OUR_FIRST_DB.PUBLIC.ORDERS_EX (
ORDER_ID number autoincrement start 1 increment 1,
AMOUNT INT,
PROFIT INT,
PROFITABLE_FLAG VARCHAR(30)
)
データのロード
COPY INTO OUR_FIRST_DB.PUBLIC.ORDERS_EX (PROFIT,AMOUNT)
FROM (select
s.$2,
s.$3
from @MANAGE_DB.external_stages.aws_stage s)
file_format= (type = csv field_delimiter=',' skip_header=1)
files=('OrderDetails.csv');
結果
Discussion