LLVM IR 入門: プログラミング言語にとってのエスペラント語
この記事は原著者である Pat Shaughnessy 氏の許可を得て公開しています。
元の記事: LLVM IR: The Esperanto of Computer Languages
また、記事には一定意訳が含まれます。
LLVM IR 入門: プログラミング言語にとってのエスペラント語
英語を外国語として学ばなければならない人は少し可哀想です。
英語の文法は一貫性がなく習得が難しいからです。
そのうえスペルについてはさらにひどく、時には自分の母語の欠点について、つい謝りたくなることすらあります。
それに加えて、大人になってから外国語を学ぶというのはそれだけでも非常に難しいことです。
その点、エスペラント語はまったく異なります。
この言語は 1873 年に Ludwik Zamenhof によって考案されました。
学びやすさを意識し、論理的で一貫性のある語彙と文法を備えています。
Zamenhof はエスペラント語を世界共通の第二言語にすることを目指していたのです。
コンピューターもまた、外国語を学ばなければならないのです。
私たちがプログラムをコンパイルして実行するたびに、コンパイラはコードを「別の言語」、つまり対象のプラットフォームのネイティブな機械語に翻訳します。
実のところ、コンパイラは「翻訳器」と呼ばれるべきだったのかもしれません。
そしてコンパイラもまた私たちと同じように、一貫性のない文法や語彙、さらにはプラットフォーム特有の仕様に悩まされているのです。
最近のコンパイラは人工的な機械語へとコードを翻訳するようになっています。
これらの言語はより単純で一貫性があり、なおかつ強力でありながら実際のマシンでは動作しない言語です。
その代表的な存在が LLVM IR です。
この LLVM IR によってコンパイラを書くことも、それが生成するコードを読むこともずっと簡単になりました。
LLVM IR はコンパイラにとって共通の第二言語になりつつあります。
一行だけ LLVM IR を覗いてみる
Low Level Virtual Machine (LLVM) プロジェクトは、コンパイラの開発者がターゲットプラットフォームとして扱いやすい仮想マシンを設計するという革新的なアイデアに基づいて始まりました。
LLVM チームは intermediate representation (IR) と呼ばれる特別な命令セットを設計しました。
Rust、Swift、Clang ベースの C など、近年の多くのモダンな言語は、まず最初にユーザーのコードを LLVM IR に変換します。
その後、その IR を LLVM がサポートする任意のターゲットプラットフォームの機械語に変換するために LLVM フレームワークを使用します。

LLVM はコンパイラにとって非常に頼もしい存在です。
コンパイラ開発者は、各プラットフォームの命令セットの詳細を気にすることなく開発を行えます。
それに、LLVM が自動的に対象のプラットフォーム毎に最適化もしてくれます。
また、 LLVM は機械語の構造やそれを CPU がどう実行するのかに関心がある人間にとっても魅力的な存在です。
実際、LLVM の命令セットは実際の機械語よりもずっと理解しやすいからです。
それでは実際に見てみましょう。
これは Crystal から生成してみた LLVM IR のサンプルです。
%57 = call %"Array(Int32)"* @"*Array(Int32)@Array(T)::unsafe_build:Array(Int32)"(i32 610, i32 2), !dbg !89
一見してこのコードは全くシンプルでも読みやすくも無いように見えるかもしれません。
でも、ちょっと待ってください。
複雑さの大半は Crystal に由来するもので、 LLVM 自体の構文が原因の部分はそれほど多くありません。
この記事の後半ではこのコードが何をしているのかを見ていきます。
見た目は複雑そうに見えますが、実際はとてもシンプルなことがわかるでしょう。
Call 命令
先ほど提示したコードは LLVM IR における関数呼び出しの例です。
このコードを生成するために、簡単な Crystal プログラムを書いてから下記のコマンドを実行しました
$ crystal build array_example.cr --emit llvm-ir
--emit オプションは Crystal に array_example.ll ファイルを生成させる指示を出すものです。
このファイルには先ほどの行を含む数千行のコードが出力されます。
Crystal のコードには後ほど触れるとして、まずはこの LLVM のコードが何を意味しているのかを見ていきましょう。
LLVM Language Reference Manual には call 命令を含むすべての LLVM IR 命令が記載されています。
例えば、 call 命令の構文は以下のとおりになります。
<result> = [tail | musttail | notail ] call [fast-math flags] [cconv] [ret attrs] [addrspace(<num>)]
<ty>|<fnty> <fnptrval>(<function args>) [fn attrs] [ operand bundles ]
今回の call 命令では、これらのオプションの多くは使用されていません。
そこで不要な部分を取り除くと、以下のような基本形になります。
<result> = call <ty> <fnptrval>(<function args>)
それぞれの要素を右から見ていきましょう。
-
<result>は戻り値を保存する先(レジスタ)を表します。 -
<ty>は関数の戻り値の型です。 -
<fnptrval>は呼び出す関数を指すポインタです。 -
<function args>はその関数に渡す引数です。
では、それぞれの項目が何を意味しているのか、これから順を追って解説していきましょう。
無限のレジスタを持つ CPU
call 命令を左から順に読み解いていきましょう。

= の左側にある %57 トークンは右側の関数呼び出しの結果をどこに保存すべきかを LLVM に指示しています。
これは通常の変数ではなく、 LLVM において「レジスタ」と呼ばれるものです。
レジスタは本来プロセッサに搭載されている物理的な回路のことで、計算途中の値など一時的なデータの保存に使われます。
メモリと比べてはるかに高速にアクセスできるため、演算装置と同じチップ上に配置されています。
一方で、RAM に値を保存するにはチップ間でのデータ転送を必要とするので、レジスタに値を保存するのに比べて処理速度は遅くなります。
とはいえ、CPU に搭載されたレジスタには限りがあるためすべてのデータをレジスタに保存するわけにはいきません。
そのため、コンパイラは「よく使われる値だけをレジスタに保持し、それ以外はより低速なメモリに退避させる」といった選別を常に行っています。
実際の CPU では使えるレジスタに限りがありますが、それとは対照的に LLVM の仮想 CPU ではレジスタが無限に使えます。
そのため、コンパイラは単純にレジスタに値を保存すれば済みます。
空いているレジスタを探す必要も、すでに使われている値を退避させる必要もありません。
こうした煩雑な処理は、従来の機械語では避けられないものでした。
今回のサンプルコードでは Crystal コンパイラは 56 個の値を既に仮想レジスタに保存していたため、この行ではその次のレジスタである %57 が使われています。
LLVM における構造体型(structure type)
call 命令を左から順に見ていくと、次に示されるのは関数の戻り値の型です。

この Array(Int32) という型名は、 LLVM ではなく Crystalのコンパイラによって生成されたものです。
つまり、これは私の Crystal プログラムで定義された型なのです。
この名前はどんなものでもよく、LLVM を使う他のコンパイラでは全く異なる名前が生成されることもあります。
この LLVM コードを生成するのに使った Crystal のサンプルプログラムは以下のとおりです。
arr = [12345, 67890]
puts arr[1]
上記のプログラムをコンパイルすると、Crystal は新しい配列 arr へのポインタを返す call 命令を生成します。
arr は整数の配列であるため、Crystal はジェネリック型 Array(Int32) を使っています。
実際のコンピューター上で動く機械語では、その機械がサポートする型しか使えません。
たとえば、Intel x86 の機械語では 16, 32, 64 ビットといった幅の異なる整数を扱うことができ、x86 CPU はそれぞれのサイズに対応したレジスタを備えています。
一方、LLVM IR はもっと強力で、C の構造体や Crystal / Swift のオブジェクトのような "structure type" をサポートしています
%"..." という構文はダブルクオートの中の文字列が structure type の名前であることを示しており、C 言語と同様に後ろのアスタリスクは戻り値の型がその構造体へのポインタであることを示しています。
先ほどのサンプルの LLVM のプログラムでは Array(Int32) を下記のように定義していました。
%"Array(Int32)" = type { i32, i32, i32, i32, i32* }
LLVM IR の structure type を使用すると、構造体やオブジェクトへのポインタを作成したり、オブジェクトの中の値へアクセスしたりできるようになります。
このおかげでコンパイラを書くことが随分楽になりました。
私のサンプル内での call 命令は、4 つの 32 ビット整数の値とそれに続く 32 ビット整数値へのポインタを含むオブジェクトへのポインタを返します。
これらの整数値はいったいなんなのでしょうか?
上記ではこの関数呼び出しが新しい配列を返すと述べましたが、具体的にどういう意味なのでしょうか?
LLVM 自身は何もそれに対する答えを持っていません。
それらの値が何か、そしてそれらがこのプログラム内で何をすべきかを理解するには Crystal コンパイラーについて学ばなければいけません。
Crystal standard libraryを読めば Crystal が配列をどのように実装しているかがわかるでしょう。
訳注:ソースコード内のコメントを日本語訳しています
class Array(T)
include Indexable::Mutable(T)
include Comparable(Array)
# 線形探索やその他の最適化を行っても良いとみなされる小さな配列のサイズ。
private SMALL_ARRAY_SIZE = 16
# この配列のサイズ
@size : Int32
# @buffer の容量
# `@buffer` は shift 操作によって移動するため、
# 実際のメモリ領域は `@buffer - #offset_to_buffer` から始まります。
# 実際の容量は内部メソッドである `remaining_capacity` によっても取得できます。
@capacity : Int32
# 実際に buffer のメモリ領域が割り当てられるまでのオフセット。
# リサイズするときには再割当ての必要がある。
# シフトのときには `@buffer` と共にこの値が加算される。
# もとのバッファ(最初に確保されたメモリ領域)にアクセスするには `@buffer - @offset_to_buffer` を計算する必要がある。
# この処理は `root_buffer` メソッドとして実装されている。
@offset_to_buffer : Int32 = 0
# 配列の中で、現在アクセス可能な最初の要素が格納されている位置を示すバッファ。
@buffer : Pointer(T)
# 64 ビット環境では、 `Array` の内部構造は下記のように配置される。
# - type_id : Int32 # 4 bytes -|
# - size : Int32 # 4 bytes |- 8 バイトに詰めて配置される
#
# - capacity : Int32 # 4 bytes -|
# - offset_to_buffer : Int32 # 4 bytes |- 8 バイトに詰めて配置される
#
# - buffer : Pointer # 8 bytes |- さらに 8 バイトで合計 24 バイト
ソースコード内のコメントは説明的で完璧です。
Crystal の開発チームはスタンダードライブラリのドキュメンティングに時間を取って、どのようにそれぞれのクラスを使用するべきかだけでなく、Array(T) のように内部実装についても良く説明しています。
この場合では Array(Int32) に対応する LLVM 構造体の中の 4 つの i32 の値が、配列のサイズや容量などの情報を保持していることがわかります。
関数
call 命令で呼び出す関数は返り値の型の次に現れます。

これ(@"*Array(Int32)@Array(T)::unsafe_build<Int32>:Array(Int32) の部分)はなかなか複雑な構文ですね。どういう関数か確認してみましょう
これを理解するには段階的な説明が必要です。
まずは @"..." と書かれている部分について解説しましょう。
これは単に LLVM プログラム内での「グローバル識別子」を示しています。
そのため、サンプル中の call 命令は単にグローバル関数を呼び出しているだけです。
LLVM プログラム内ではすべての関数はグローバルで、class や module などの概念は存在しません。
あのひたすらに長い識別子にはどういう意味があるのでしょうか?
LLVM はこうした複雑な名前を気にしません。
foo や bar のような名前であったとしても同じように扱います。
しかし、Crystal にとってはこの名前は重要な意味を持ちます。
LLVM コードは人間が読むことを想定していないため、Crystal は関数名に多くの情報を埋め込んでいるのです。
その結果、Crystal は関数名を複雑に修飾(マングリング)し、元の関数名にさまざまな情報を加えた上で新しい名前を生成します。
そうして、Crystal は関数ごとにユニークな名前へと書き換えます。
また、Crystal では他の静的型付け言語と同様に、違う引数や返り値の型が違う関数は別の関数として認識されます。
なので、Crystal で下記のように書くと
def foo(a : Int32)
puts "Int: #{a}"
end
def foo(a : String)
puts "String: #{a}"
end
foo(123)
#=> Int: 123
foo("123")
#=> String: 123
... 2 つの別の foo 関数を定義することになります。
引数の a の型が違うからですね。
Crystal はユニークな関数名を生成するために、引数の情報や返り値の情報や型も関数名として埋め込みます。
その結果かなり複雑な関数名が生成されるというわけですね。
詳しくみていきましょう。

-
Array(Int32)@Aray(T)これはレシーバーの型です。これはunsafe_build関数がジェネリッククラスであるArray(T)の関数であることを示します。そして、今回のケースでは、レシーバーは 32 ビット整数の配列を保持しているArray(Int32)クラスになります。Crystal は両方の名前をマングリングされた関数名に埋め込みます。 -
unsafe_buildこれは Crystal が呼び出している関数名です。 -
Int32- これらは関数の引数の型です。今回のケースでは、Crystal は一つの Int を渡します。 -
Array(Int32)- これは返り値の型です。Int32 の配列を返します。
以前の投稿でも説明した通り、Crystal コンパイラは内部的に配列リテラル [12345, 67890] を新しい配列オブジェクトを生成・初期化するコードへと書き換えています。
__temp_621 = ::Array(typeof(12345, 67890)).unsafe_build(2)
__temp_622 = __temp_621.to_unsafe
__temp_622[0] = 12345
__temp_622[1] = 67890
__temp_621
このコード中では Crystal は unsafe_build を呼び出し、新しい配列のサイズである 2 を渡しています。
そして、この unsafe_build 呼び出しがプログラム中の他の unsafe_build 関数と区別されるように、コンパイラは先程みたようなマングリングされた名前を生成します。
Arguments
最後に、関数名のあとの LLVM IR の命令は関数呼び出しの引数を示します。

LLVM IM は他の大半の言語と同じように関数呼び出しの引数をカッコを使って囲います。
そして、それぞれの値には型が先行します。610 は i32、2 も i32 になります。
でもちょっと待ってください。
先程見た配列を生成するための展開語の Crystal のコードでは、unsafe_build の呼び出しに 2 という1つの値が渡されていました。
そして、上記のマングリングされた関数名を見ても、この関数よびだしには i32 型の引数がひとつだけあることがわかります。
しかし、LVM IR のコードでは 610 も渡されていることがわかります。
610 は何を意味しているのでしょうか?
610 は配列には存在しませんし、610 は配列の要素でもありません。
一体何が起こっているのでしょうか。
Crystal はオブジェクト指向型の言語です。
つまり、関数は必要に応じてクラスに関連付けられる仕組みになっています。
オブジェクト指向の用語で言えば、関数を呼び出すことを「レシーバーにメッセージを送る」と表現します。
今回の例では usafe_build がメッセージにあたり、::Array(typeof(12345,67890)) がそのレシーバーになります。
実際、この関数はクラスメソッドであり、配列のインスタンスではなく Array(Int32) クラスそのものに対して unsafe_build を呼び出しています。
しかし、LLVM IR ではシンプルなグローバル関数のみが存在しており、オブジェクト指向の概念は存在しません。
LLVM の仮想マシンは、関数に渡された引数をただのデータとして扱います。
その引数が「どのクラスのオブジェクトか」「どのメソッドか」といった情報は考慮せず、単なる数値やポインタとして扱います。
ただ Crystal コンパイラが指定したとおりに、そのデータを引数として関数に渡し、実行するだけです。
(※訳注:この段落はかなり意訳しています)
一方で、 Crystal は何らかの方法でオブジェクト指向的な振る舞いを実現しなければなりません。
特に unsefe_build 関数はどのクラス(=レシーバー)に対して呼び出されたのかに応じて、その振る舞いを変える必要があります。
例えば、
::Array(typeof(12345,67890)).unsafe_build(2)
上記の場合は2つの Int の配列を返す必要があるのに対して、
::Array(typeof("abc", "def")).unsafe_build(2)
上記の場合は2つの String の配列を返す必要があります。
これらは LLVM IR でどのように実現されているのでしょうか?
このオブジェクト指向の動作を実装するために、Crystal はレシーバーを隠れた特別な引数として関数呼び出しに渡します。
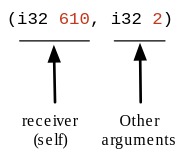
このレシーバー引数はレシーバーオブジェクトの参照かポインタになっており、通常は self として知られています。
ここでは 610 を参照もしくは Array(Int32) クラスに対応するタグとして渡しています。
そして、この 2 が unsafe_build の実際の引数です。
LLVM IR のコードを読むと Crystal が全てのオブジェクトに対する関数呼び出しでこっそり self 引数を渡しているのがわかります。
そして各関数の内部では self――――すなわちそのメソッドが実行されているオブジェクトのインスタンス――――へのアクセスが可能になります。
Rust のように、関数呼び出しに self を明示的に渡すことが求められる言語も存在しますが、Crystal ではこの処理が自動的かつ暗黙的に行われます。
コンパイラの仕組みを学ぶ
LLVM IR はコンパイラ開発者向けに設計されたシンプルな言語で、白紙のキャンバスのような存在です。
大半の LLVM の命令は非常にシンプルで理解しやすく、先ほどみた call 命令の基本構文も全く難しくはありませんでした。
難しかったのは Crystal コンパイラが実際にどうやってコードを生成しているかを理解することです。
LLVM の構文自体はわかりやすいものに対し、Crystal の実装のほうがはるかに複雑でした。
これこそが LLVM IR の構文を学ぶべき理由になります。
LLVM の命令の動作をじっくり学べば、好きな言語のコンパイラが生成するコードを読み解けるようになるでしょう。
そしてそれができるようになれば、コンパイラの仕組みやプログラムが実行時に実際に行っている処理についてより深く理解できるようになるはずです。
Discussion