C#でかな漢字変換を実装してみた
DotNetKKC
まだ試作版ですがC#でかな漢字変換するライブラリ「DotNetKKC」を作りました。一応動きます。
使い方はREADMEをお読みください。
この記事は使い方ではなく中身のアルゴリズムを説明しています。
背景
以前からVRChatで日本語を入力するアプリケーションを開発しています。
現在はかな漢字変換をGoogle CGI API for Japanese Inputで処理していますが、一度に取得できる候補が少ない点が問題となっていました。
現状かな漢字変換をC#から呼び出せるものは以下のようなものがありますが、制限やデメリットがあり実用にはあまり向いていません。
-
IFELanguage
Microsoftが提供しているIMEのAPI。相互変換を行えるのが特徴だがベストの変換候補しか返してくれない。 -
Windows.Data.Text.TextConversionGeneratorクラス
Microsoftが提供するUWP向けのクラス。TextPredictionGeneratorクラスで予測変換も対応しており比較的実用的だがUWP環境でしか使えない。 -
ImmGetConversionList
imm32.hにより提供されるWindows API。IME依存かつ入力システムが自前だと呼び出すのが難しい。 -
TsfSharp
IMEの後継であるText Service FrameworkをC#から操作できるようにしたライブラリ。複数の変換候補を取得できるほかちょっとした予測変換も返してくれるらしい。旧バージョンのIMEを有効にしていないと使えないなどの制限がある。 -
Yahoo かな漢字変換(v2)API
Yahooが提供しているかな漢字変換API。高機能だがオンライン環境が必須かつ1つのアプリケーションにつき300リクエスト/分に制限されている。 -
Google CGI API for Japanese Input
Googleが提供するかな漢字変換API。Googleのもつ辞書で高精度な変換が可能だがオンライン環境が必須、取得できる候補数が少ないといったデメリットがある。
このように既存のものでは難しいため自作しようという結論に至りました。
かな漢字変換の仕組みを理解する
以下の4つを順に説明していきます。
- Mozc辞書の構造
- トライによる単語の検索
- 変換の概要
- 前向きDP後ろ向きA*によるコスト計算
Mozc辞書の構造
DotNetKKCではGoogle Mozcで使用されているMozc辞書を採用しています。dictionary_ossの中にあるdictionary00.txtの最初の部分を見てみます。
あいあんと 1851 271 7284 アイアンと
一番左から変換前、左文脈ID、右文脈ID、生起コスト、変換候補の並びになっています。
詳細を説明します。
- 変換前
変換前のひらがなです。 - 文脈ID
文脈IDは品詞と似たようなものだと考えて良いと思います。以降「文脈ID」という単語が登場したら品詞を想像してください。使用用途は後述する連接コストが出てくる際に説明します。左文脈IDは左の単語から見た文脈ID、右文脈IDは右の単語から見た文脈IDです。
左の単語から見た文脈IDと右の単語から見た文脈IDが別れている理由は解釈が難しいですが、例として「県」という単語が含まれた「岩手県に行く」という文を考えてみましょう。
「県」という単語はそのままでは普通の名詞ですが、「岩手」という単語から接続する場合、「県」は単なる名詞ではなく接尾辞のように振る舞うと考えることができます。一方助詞「に」から見た場合、「県」単体の場合と「岩手/県」のように接続されている場合どちらに対しても「県」は単なる名詞として捉えることができます。
このように左の単語から見た場合と右の単語から見た場合で単語の働きが変化することがあるため、左文脈IDと右文脈IDのように別れていると考えられます。 - 生起コスト
生起コストとは単語の出現しやすさを数値化したものです。Mozc辞書では0以上の整数と決められており生起コストが小さいほど出現しやすい単語であることを示しています。 - 変換候補
変換前のひらがなに対応する変換候補です。
トライによる単語の検索
変換のために単語のリストを取得する必要があります。例として「かそうのせかい」という文を考えてみます。
コンピューターは「かそうのせかい」という文に対してどこで区切れば良いかわからないため、可能なすべての区切り方「か」「かそ」「かそう」...「う」「うの」「うのせ」...「せかい」「か」「かい」「い」に対応した単語を辞書から取得する必要があります。(実際に取得してみるとか、下、価、...、兎、宇野、鵜瀬、...、井、偉、威のようになり、全部で425個ありました。)これは愚直に実装すると膨大な計算量が必要です。
こういった単語の検索を高速におこなえるのがトライというデータ構造です。ほとんどの形態素解析システムはダブル配列やLOUDSといったトライの実装を採用しており、darts-cloneやmarisa-trieなどの実装が既にあります。
具体的なアルゴリズムに関してはこちらやこちら、こちらなどがとても参考になります。気になる方はぜひ読んでみてください。
DotNetKKC試作版ではAhoCorasickDoubleArrayTrieというライブラリを使用させていただきました。エイホ・コラシック法による高速な計算が特徴ですが、辞書サイズが大きくなるほか構築にもやや時間がかかります。
変換の概要
単語のリストが取得できたので変換の概要を説明します。実際には次の方針で変換候補を取得します。
- 考えられうるすべての変換候補を洗い出す。
- 生起コストと連接コストの合計が小さい順に変換候補を列挙する。
考えられうるすべての変換候補を洗い出す
これは単語のリストが取得できたので簡単に構築できます。いくつか例をあげると
- 仮想の世界
- 下層の世界
- 仮想のセカイ
- か創の世界
- か僧のセカイ
- 過疎兎能勢会
とにかく「かそうのせかい」と読むことができる変換をすべて列挙します。実際に「かそうのせかい」ですべての変換候補を列挙するとその数は100万以上あるようです。これを配列などで持つと効率が悪いため次の図のようなグラフ構造で表現します(ラティスと呼んでいます)。
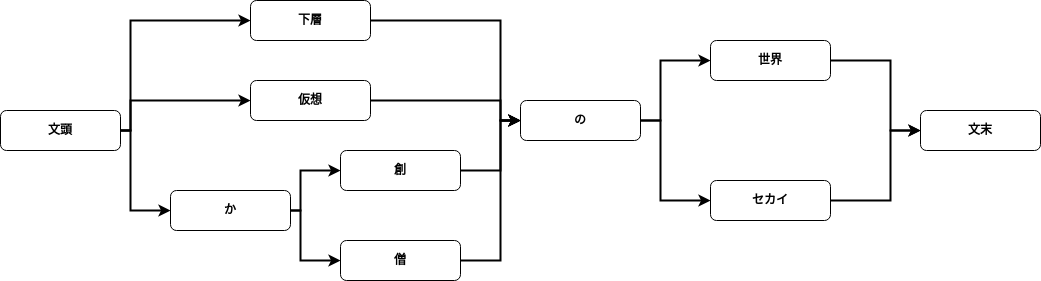
生起コストと連接コストの合計が小さい順に列挙する
新しい単語連接コストは単語の接続しやすさを数値化したものです。
例えば「岩手県に行く」という文は名詞⇨助詞⇨動詞の順に並んでおり、これは自然な文です。
これに対し「岩手県行く」という文はどうでしょうか。これは名詞⇨動詞の順に並んでおり、親しい間柄では登場しますが一般的には不自然な文です。
このように日本語には接続しやすい文脈IDと接続しにくい文脈IDがあります。これらの接続しやすさを数値化したものが連接コストです。連接コストが小さいほど接続しやすいことを表しています。
連接コストはdictionary_ossの中にあるconnection_single_column.txtに書かれています。
2670
0
6006
4729
︙
5805
5713
3839
一行目の2670は文脈IDの総数を表しています。そして二行目から連接コストが書かれています。
2670 //文脈IDの総数
0 //左の単語の右文脈ID:0、右の単語の左文脈ID:0の連接コスト
6006 //左の単語の右文脈ID:0、右の単語の左文脈ID:1の連接コスト
4729 //左の単語の右文脈ID:0、右の単語の左文脈ID:2の連接コスト
︙
5805 //左の単語の右文脈ID:2670、右の単語の左文脈ID:2668の連接コスト
5713 //左の単語の右文脈ID:2670、右の単語の左文脈ID:2669の連接コスト
3839 //左の単語の右文脈ID:2670、右の単語の左文脈ID:2670の連接コスト
実際に生起コストと連接コストをラティスに書き込むと次の図のようになります。生起コストを青で、連接コストを赤で示しました。

実は同じ単語でも文脈IDが異なる数種類の候補があります。例えば辞書を見ると「か」には3種類あることが分かります。
か, (325, 325, 0, か)
か, (577, 577, 17085, か)
か, (1381, 1381, 0, か)
つまり実際は「か」近辺の部分は以下の図のようになりますが、ここでは説明のため無視していきます。そのためこの後計算するコストはDotNetKKCを実行した場合のコストと異なる場合があります。

文頭から文末まで辿ってコストの合計を計算します。例えば「か創の世界」ではコストは次のように計算できます。
0 + 2822 + 0 + 2753 + 2809 + 3481 + 0 + 404 + 2890 + 0 + 0 = 15159

「か創の世界」ではコストは15159でした。同様にコストを計算して、小さい順に並べることで変換候補が得られます。以下のようになっていきます。
-
仮想の世界
0 + 2822 + 2753 + 2809 + 3481 + 404 + 2890 + 0 + 0 = 11950

-
下層の世界
0 + 1091 + 5463 + 2690 + 0 + 404 + 2890 + 0 + 0 = 12538

-
仮想のセカイ
0 + 1301 + 4171 + 3184 + 0 + 404 + 5889 + 0 + 0 = 14949

-
下層のセカイ
0 + 1091 + 5463 + 2690 + 0 + 404 + 5889 + 0 + 0 = 15537

このようにして変換候補が取得できます。
前向きDP後ろ向きA*によるコスト計算
コスト計算をプログラムで実装するわけですが、前述のとおり「かそうのせかい」という7文字でも変換候補の総数は100万を越えてきます。愚直な実装では時間がかかってしまうため、前向きDP後ろ向きA*によるコスト計算を行うことで計算時間を短縮します。
ここでは実際のDotNetKKC(試作版)の実装を用いて説明していきます。
Util.csでラティス、エッジ、ノードのクラスを定義しています。
重要なのはLatticeクラスで、Nodeから出るエッジを持つ変数outEdgesとNodeに入ってくるエッジを持つ変数inEdgesがあります。これらを用いてコスト計算をしていきます。
前向きDP
まず前向きDPから説明します。「前向き」は文頭から文末に向かっていくことを表しています。「DP」は動的計画法のことで、詳しい説明はしませんが大きな問題を小問題に分割して解くというものです。
前向きDPでは文頭ノードからあるノードまでの最小コストを算出しています。例えば先ほどの例では「の」に対応する最小コストは「仮想」を通った場合なので0 + 1301 + 4171 + 3184 + 0 = 8656になります。

これをConversion.csのSetBestCosts関数で行っています。
コスト計算に関しては基本的な動的計画法の実装と一緒なので説明は省きます。EDPCの解説記事やアルゴ式の練習問題などが参考になると思います。
後ろ向きA*
次に後ろ向きA*を説明します。「後ろ向き」は文末から文頭に向かっていくことを表しています。「A*」は経路探索アルゴリズムの一種で、「エースター」と読みます。ヒューリスティック関数を用いて実際のコストを計算しなくても最短経路を求めることができます。ここではヒューリスティック関数は文末ノードからのコスト+前向きDPで求めた最小コストを採用します。
実装部分を示します。
優先度付きキューを使用することでコスト順に並べて取り出せるようにしています。実際の動作の流れを見ていきます。
-
queueに文末ノードを追加queue.Enqueue((eos, eos.key, 0), eos.cost); -
文末ノードの左にあるエッジを探索
foreach (var edge in lattice.inEdges[item.Item1])最初に取り出されるのは「世界」に対応するノードだと分かります。
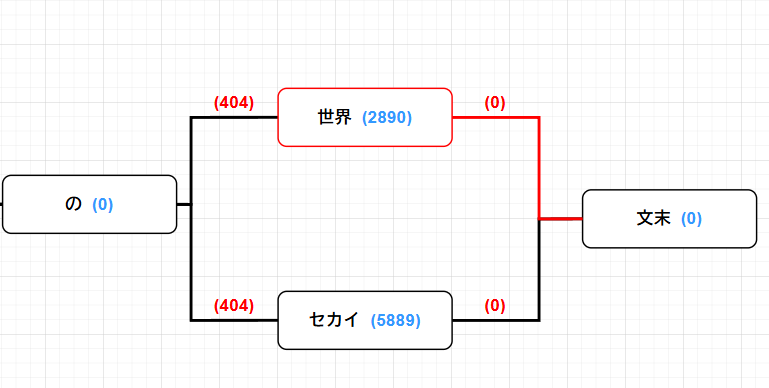
-
文末ノードからのコストを計算
double backwardCost = item.Item1.cost + item.Item3 + edge.cost;Item1.costが文末ノードのコスト、Item3は文末ノードからのコスト、edge.costは「文末」と「世界」をつなぐエッジのコストを表しています。計算するとここでは0+0+0で0です。 -
ヒューリスティックコストを計算
double heuristicCost = backwardCost + bestCosts[edge.fromNode];先ほど求めた文末ノードからのコストと前向きDPで求めた最小コストを足してヒューリスティックコストとします。「世界」ノードに対応する最小コストは
0 + 1301 + 4171 + 3184 + 0 + 404 + 2890 = 11950

なので、先ほど求めた文末ノードからのコスト0を足してヒューリスティックコストは11950となります。
-
キューに追加
queue.Enqueue((edge.fromNode, item.Item1.key + item.Item2, backwardCost), heuristicCost);「世界」に対応するノード、文字列「"世界"+""」、文末ノードからのコスト、ヒューリスティックコストをまとめてキューに追加します。現在キューには
[(「世界」ノード,"世界",0), 11950]が入っています。 -
文末ノードの左にあるエッジを探索
foreach (var edge in lattice.inEdges[item.Item1])次に取り出されるのは「セカイ」に対応するノードだと分かります。
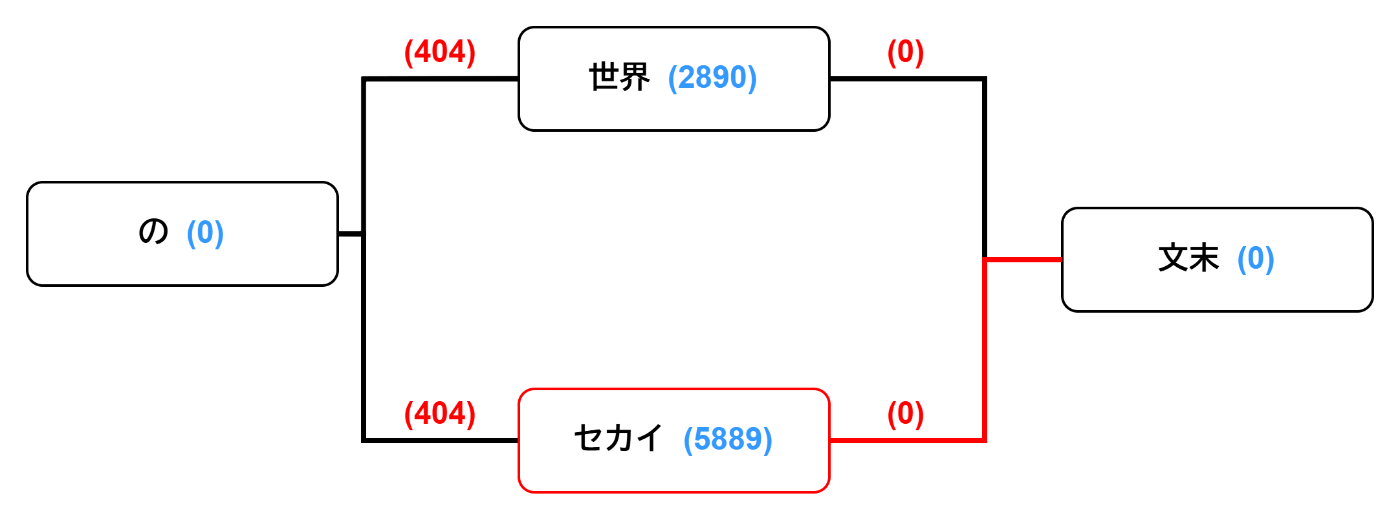
-
コスト計算
同様にコストを計算します。文末ノードからのコストは0、「セカイ」ノードに対応する最小コストは
0 + 1301 + 4171 + 3184 + 0 + 404 + 5889 = 14949

よってヒューリスティックコストは14949となります。
-
キューに追加
queue.Enqueue((edge.fromNode, item.Item1.key + item.Item2, backwardCost), heuristicCost);同様に「セカイ」に対応するノード、文字列「"セカイ"+""」、文末ノードからのコスト、ヒューリスティックコストをまとめてキューに追加します。現在キューには
[(「世界」ノード,"世界",0), 11950], [(「セカイ」ノード,"セカイ",0), 14949]の二つが入っています。 -
「世界」ノードの左にあるエッジを探索
優先度付きキューの働きによりヒューリスティックコストの小さい「世界」ノードが取り出されます。
foreach (var edge in lattice.inEdges[item.Item1])取り出されるのは「の」に対応するノードだと分かります。

-
文末ノードからのコストを計算
double backwardCost = item.Item1.cost + item.Item3 + edge.cost;Item1.costが「世界」ノードのコスト、Item3は文末ノードからのコスト、edge.costは「世界」と「の」をつなぐエッジのコストを表しています。
計算するとここでは2890+0+440で3330です。 -
ヒューリスティックコストを計算
double heuristicCost = backwardCost + bestCosts[edge.fromNode];先ほど求めた文末ノードからのコストと前向きDPで求めた最小コストを足してヒューリスティックコストとします。「の」ノードに対応する最小コストは
0 + 1301 + 4171 + 3184 + 0 = 8656
なので、先ほど求めた文末ノードからのコスト3330を足してヒューリスティックコストは11986となります。
-
キューに追加
queue.Enqueue((edge.fromNode, item.Item1.key + item.Item2, backwardCost), heuristicCost);同じく「の」に対応するノード、文字列「"の"+"世界"」、文末ノードからのコスト、ヒューリスティックコストをまとめてキューに追加します。現在キューには
[(「の」ノード,"の世界",3330), 11986], [(「セカイ」ノード,"セカイ",0), 14949]の二つが入っています。
以降この操作を繰り返していくことによりコストの小さい順に変換候補を取得することができるようになっています。
おわり
当初は春休み中に実装しようと思っていましたが、アルゴリズムの理解がネット検索では不十分だったり様々なイベントがあったりであまり開発が進んでいませんでした。しかしとりあえず動くところまでこぎつけたので良かったです。
以降時間があれば予測変換も実装していきたいと考えています。ただそのためにはAhoCorasickDoubleArrayにDFSによる検索を実装しないといけないのでまだまだ時間がかかりそうです(人が欲しい...)。
稚拙な文章でしたが最後までお読みいただきありがとうございました。フォローしていただけると開発の励みになりますのでもしよろしければお願いします。
参考にしたサイトや文献など
実装にあたり大変参考にさせていただきました。ありがとうございます。
-
徳永 拓之,日本語入力を支える技術:変わり続けるコンピュータと言葉の世界,技術評論社,2012
実装部分の確信が持てず最終的に読ませていただきました。特にヒューリスティックコストの妥当性について議論している部分で納得がいきました。 -
Mozcの辞書を使ってMeCabでかな漢字変換する
連接コストの理解に参考になりました。 -
Mozc辞書型式へのMeCabのコスト計算について
生起コスト、連接コストの理解に役立ちました。 -
工藤 拓 - MeCab 汎用日本語形態素解析エンジン
全体的な流れを理解するのに役立ちました。また単語の重複についても理解ができました。 -
アスペ日記
特に2012年に投稿されているブログがアルゴリズム理解に役立ちました。
Discussion