Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
Abst.
Webスケールデータでの学習は数ヶ月かかることもある。しかし、ほとんどの計算と時間は、既に学習済みの冗長でノイズの多いポイントや、学習不可能なポイントに浪費されている。学習を高速化するために、研究ではRHOLOSS(Reducible Holdout Loss Selection)を導入している。これは、モデルの汎化損失を最も低減する学習用のポイントを大まかに選択する、シンプルだが原理的なテクニックである。
その結果、RHO-LOSSは既存のデータ選択手法の弱点を緩和していた。最適化の文献にある手法は、一般的に「難しい」(例えば、損失の大きい)点を選択するが、そのような点はしばしばノイズが多い(学習可能ではない)かタスク関連度が低い。逆に、カリキュラム学習は「簡単な」点を優先するが、そのような点は一度学習すれば学習する必要はない。これに対し、RHO-LOSSは、学習可能で、学習に値する、まだ学習していないポイントを選択する。RHO-LOSSは先行技術よりはるかに少ないステップで学習し、精度を向上させ、幅広いデータセット、ハイパーパラメータ、アーキテクチャ(MLP、CNN、BERT)において学習を高速化することが可能。
大規模なウェブスクレイピング画像データセットClothing-1Mにおいて、RHO-LOSSは18倍少ないステップで学習し、均一なデータシャッフリングよりも2%高い最終精度に到達していた。
Intro.
現状の学習の課題として、どのデータポイントが最も有用であるかについて確証は得られていない。カリキュラム学習を含むいくつかの研究では、すべての点を均等に学習する前に、ラベルノイズの少ない簡単な点を優先することを提案している。 この方法は収束性と汎化性を向上させる可能性があるが、既に学習した点(redundant)をスキップするメカニズムが欠如している。
他の研究では、モデルにとって難しい点を学習することで、損失をさらに減らすことができない冗長な点を回避することを提案しているものもある。オンライン一括選択法は、高い損失または高い勾配ノルムを持つポイントを選択する手法を突っている。
研究では、困難な例を優先的に扱うことの2つの失敗例がを示されていた。
実世界のノイズの多いデータセットでは、高損失の例は誤ったラベルや曖昧なものである可能性がある。実際、制御された実験では、高損失または勾配ノルムによって選択された点は、圧倒的にノイズで破壊されたラベルを持つ点であった。実験結果は、この失敗例が性能を著しく低下させることを示している。さらに、あるサンプルは、テスト時に現れる可能性が低い異常な特徴を持つ点であるため、困難であることを示す。テストの損失を減らすためには、このようなポイントは学習する価値が低い。
このような限界を克服するために、還元可能なホールドアウト損失選択(reducible holdout loss selection; RHO-LOSS)を導入された。論文では、確率的モデリングに基づく選択関数を提案し、実際に学習することなく、各ポイントが未知データに対して学習した場合にどの程度損失を減らすかを定量化する。その結果、ホールドアウト損失を低減させる最適なポイントは、非ノイズ、非冗長、タスク関連であることが示される。最適な選択を近似的に行うために、効率的で実装が容易な選択関数、すなわち、削減可能なホールドアウト損失を導出する。
論文ではRHO-LOSSを7つのデータセットで広範囲に渡って実験している。一様サンプリングや最新のバッチ選択手法と比較して、必要な学習ステップの削減を評価する。評価対象は、我々の主要なアプリケーションであるClothing1Mであり、ノイズの多いウェブスクレイプされたラベルを含む大規模なベンチマークである。RHO-LOSSは、一様選択と比較して18倍少ないステップで目標精度に到達し、最終的には2%高い精度を達成しました(図1)。さらに、RHO-LOSSは、データセット、モダリティ、アーキテクチャ、ハイパーパラメータの選択において、一貫して先行技術を上回り、学習を高速化することができます。
これは、「難しい」点を選択する手法は、ノイズの多い、関連性の低い例を優先することを示していて、これに対し、RHO-LOSSは、ノイズが少なく、タスクに関連し、冗長でない、学習可能で学習価値のある、そしてまだ学習していない点を選択することを示した。
Background: Online Batch Selection
大きなバッチ
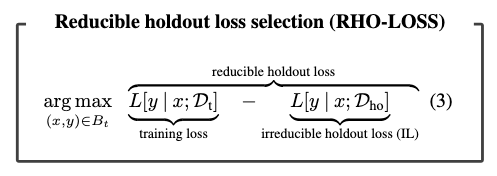
Reducible Holdout Loss Selection
損失や勾配ノルム選択など、これまでのオンライン一括選択法は、訓練セットの損失を最小化するような点を選択することを目的としている。その代わり、ホールドアウト集合の損失を最小化する点を選択することを目指す。すべての候補点で学習し、その都度ホールドアウト損失を評価するのはコストがかかりすぎるだろう。そこで、実際に学習することなく、現在のモデルを学習させた場合にホールドアウト損失を最も小さくするポイントを(近似的に)見つける方法を示す。
この点(
MLEやMAP推定のように
Deriving a tractable selection function. (選択関数の導出)
ここで、式(1)の項について、各候補点
ベイズ則と条件付き独立性
ここで、最終行の (x, y) に依存しない項を削除し、並べ替えて、損失
厳密なベイズ推論(DtまたはDhoの条件付け)はニューラルネットワークでは困難であるため(Blundell et al.、2015)、代わりにSGDでモデルを適合させました(近似1)。この近似の影響をセクション 4.1 で検討する。第一項の
式(2)の選択関数は扱いやすいが、新しい点を取得するたびに両項を更新しなければならないため、計算コストが多少か かります。しかし、ホールドアウトデータセットのみで学習させたモデル、
本手法では、ホールドアウト集合に対してモデルを学習させる必要があるが、最終的な近似によりそのコストは大幅に削減される。我々は、ターゲットモデルより小さく、精度の低い「irreducible lossモデル」(ILモデル)を用いてILを効率的に計算することができる(近似3)。このことを示し、4.1、4.2、4.3節で説明する。直感に反して、reducible holdout損失はそれゆえ負になりうる。さらに、1つのILモデルは多くのターゲットモデルの実行に再利用でき、そのコストを補填
することができる(セクション4.2)。例えば、図1の5つのターゲットアーキテクチャの40の種すべてを1つのResNet18 ILモデルで学習させました。さらに、このモデルは、各ターゲットモデルよりも37倍少ないステップ数で学習を行いました(到達精度は62%のみ)。第5章では、さらなる効率化の可能性について述べる。
以上より、Dt を学習させたモデルにおいて、式(1) のホールドアウト損失を最小化する点を選択することは、 以下の計算しやすい目標で近似することができる。
追加データ