SimCTG: テキスト生成におけるContrastive学習推論の解説・実装
はじめに
こんにちは、わっしーです。
画像・自然言語・音声に関する機械学習の研究開発やMLOpsを行っています。もし、機械学習に関して、ご相談があれば、@kwashizzzのアカウントまでDMしてください!
これまでの、機械学習記事のまとめです。
本記事では、文章生成のモデルの生成テキストの不自然さや、望ましくない単語の繰り返しを抑える手法として、A Contrastive Framework for Neural Text Generationで提案されたSimCTG(a SIMple Contrastive framework for neural Text Generation)を紹介します。
また、論文の実装コードを参考にし、Encoder-Decoder形式の文章生成モデルであるT5にSimCTGを適用してみたので、実装方法を紹介します。
※ 論文の実装コードには、GPT-2に適用した実装があるので、GPT-2を使いたい人は、こちらを参考にしてください。
22/5/31 - 推論処理をhugging faceのgenerateメソッドlikeの処理に修正しました。(推論速度が改善しています。)
なぜSimCTGが必要なのか?
昨今のDecoderを持つモデルでは、入力文+過去に生成した単語列から次の単語列を予測するAuto-Regressiveな生成が行われています。この際に、計算量の関係から、Gready SearchやBeam Searchなどが用いられています。
参考: テキスト生成における decoding テクニック: Greedy search, Beam search, Top-K, Top-p
しかし、これらの探索手法を用いた場合、同じ単語を繰り返すなどの問題が発生します。そこで、huggingfaceの文章生成関数genereteでは、no_repeat_ngram_sizeやrepetition_penaltyという引数があり、このパラメータによって繰り返しを抑えることができますが、パラメータによっては、同じ単語列が全く出なくなり不自然な生成になってしまうことがあります。
下図(論文中Fig.1)の(a)は、GPT-2によって生成された各トークンにおける特徴ベクトル(Transformer最終層)のコサイン類似度行列です。見ての通り、文中のトークン間の類似度が0.95以上になっており、互いの特徴ベクトルが近いことがわかります。これは、異なるステップで繰り返しトークンを生成してしまう原因の一つと考えられます。論文中では、このように特徴ベクトルが偏っていることを異方性と言っています。
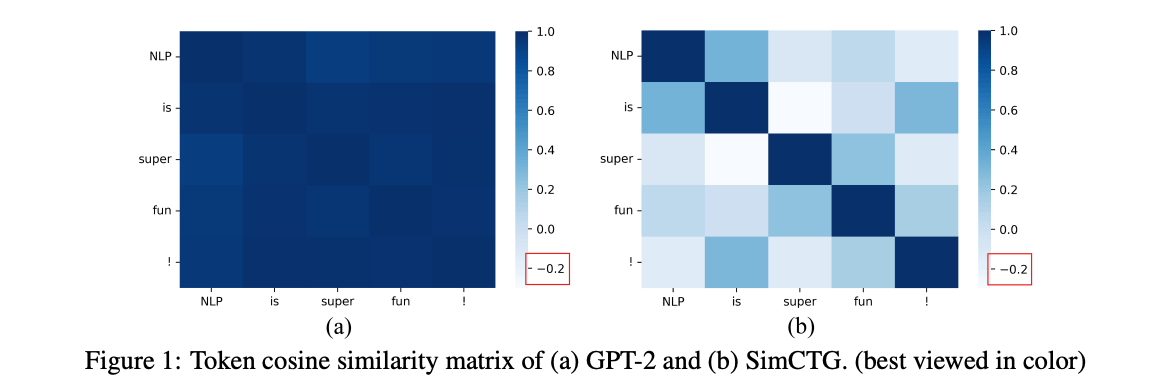
理想的には、生成されたトークンの特徴ベクトル間を識別可能にするため、上図(b)のようにトークン間の類似度が低くなるようにすべきと考えられます。つまり、各トークンの特徴ベクトルは偏らないようにする必要があります。(等方性にすべき。)
そこで、最尤推定(MLE)で言語モデルを学習し最も可能性の高いシーケンスをデコードしていくという従来手法に対して、識別可能で等方的な特徴ベクトルの学習を促すSimCTG損失を提案し、加えて、SimCTGによる学習を補完する新しい復号化手法であるContrastive Search (対照探索)が提案されています。
SimCTG
SimCTGは、最尤推定の損失(クロスエントロピー損失)と対照損失(Constrastive Loss)からなります。
単語列を
次に対照損失
マージン
で計算できます。
上記の損失を用いてSimCTG損失は、
となります。
このSimCTG損失を用いて学習することで、同じトークンの特徴ベクトルは近くになり、異なるトークン間の特徴ベクトルは遠くなります。
Contrastive Search
対照損失を用いたSimCTGで学習したモデルを用いて次の単語を予測する場合、一つ前までの単語列とは異なる単語である可能性が高いです。その知識を取り入れ、従来手法と同様に確率の高い単語を探索することに加え、一つ前までの単語列と類似度が低い単語を探索するContrastive Searchが提案されています。
予測確率が高い
で行われます。
結果
論文のTable.1を見てください。論文通りの結果だと、SimCTGに、Contrastive Searchを使った際、最強です。
個人的に使用して見たところ、普通の学習により作成したT5のモデルと比較し、logitsのTop1と2に開きがありました。
T5におけるSimCTGの学習の実装
今回は、【日本語モデル付き】2021年に自然言語処理をする人にお勧めしたい事前学習済みモデルで提供されているT5の転移学習例のコードをベースに拡張させていただきました。コードのニュース記事のタイトル生成(一種の文章要約)のリンクからGoogle Colabでの訓練コードが見れます。また、本記事では、簡単のため、修正したSimCTGの重要な部分のみ記載します。
まず、類似度計算の部分です。ここでは、T5のデコーダの最終層を特徴ベクトルとして使用しています。バッチ, 単語列数, 特徴ベクトルからなる行列なので、各単語ごとの特徴ベクトルの類似度を計算し、バッチ数×単語列数×単語列数の類似度行列を出力します。
def t5_cosine_simirality(outputs):
last_hidden_state = outputs.decoder_hidden_states[-1] # torch.Size([3, 64, 768])
norm_rep = last_hidden_state / last_hidden_state.norm(dim=2, keepdim=True)
cosine_scores = torch.matmul(norm_rep, norm_rep.transpose(1,2)) # torch.Size([3, 64, 64])
return cosine_scores
事前学習済モデルの類似度行列は、以下のようになっています。(長いので最初の5行5列部分のみです。)
実際、対角部分以外の類似度も高いことが見て取れます。
[0.9999, 0.9807, 0.9654, 0.9587, 0.9528,
[0.9807, 0.9999, 0.9805, 0.9755, 0.9687,
[0.9654, 0.9805, 0.9999, 0.9816, 0.9712,
[0.9587, 0.9755, 0.9816, 0.9999, 0.9878,
[0.9528, 0.9687, 0.9712, 0.9878, 0.9999,
次に、対照損失の部分です。これは、論文のコードと同じです。論文コードのスターをポッチっと押しましょう!
def compute_contrastive_loss(score_matrix, margin):
'''
margin: predefined margin to push similarity score away
score_matrix: bsz x seqlen x seqlen; cosine similarity matrix
input_ids: bsz x seqlen
'''
bsz, seqlen, _ = score_matrix.size()
gold_score = torch.diagonal(score_matrix, offset=0, dim1=1, dim2=2) #対角成分を取り出す bsz x seqlen
gold_score = torch.unsqueeze(gold_score, -1)
assert gold_score.size() == torch.Size([bsz, seqlen, 1])
difference_matrix = gold_score - score_matrix
assert difference_matrix.size() == torch.Size([bsz, seqlen, seqlen])
loss_matrix = margin - difference_matrix # bsz x seqlen x seqlen
loss_matrix = torch.nn.functional.relu(loss_matrix)
cl_loss = torch.mean(loss_matrix)
return cl_loss
次に学習する部分です。参考にさせていただいた転移学習コードはPytorch Lightningを使用しているので、そのモデル部分の拡張です。
T5の隠れ層を出力するために、output_hidden_states=True を設定しています。_step部分で損失を追加で計算しています。
class T5FineTuner(pl.LightningModule):
def __init__(self, hparams):
super().__init__()
# 最新版のplでは、hparamsのupdate方法が変更された。
self.save_hyperparameters(hparams)
# 事前学習済みモデルの読み込み
self.model = T5ForConditionalGeneration.from_pretrained(hparams.model_name_or_path)
# トークナイザーの読み込み
self.tokenizer = T5Tokenizer.from_pretrained(hparams.tokenizer_name_or_path, is_fast=True)
def forward(self, input_ids, attention_mask=None, decoder_input_ids=None,
decoder_attention_mask=None, labels=None):
"""順伝搬"""
return self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
labels=labels,
output_hidden_states=True # decoderの隠れ層を出力するためTrueに設定。
)
def _step(self, batch):
"""ロス計算"""
labels = batch["target_ids"]
labels[labels[:, :] == self.tokenizer.pad_token_id] = -100
outputs = self(
input_ids=batch["source_ids"],
attention_mask=batch["source_mask"],
decoder_attention_mask=batch['target_mask'],
labels=labels,
)
mle_loss = outputs.loss
cosine_scores = t5_cosine_simirality(outputs) # 類似度計算
margin = 0.5 # margin
cl_loss = compute_contrastive_loss(cosine_scores, margin) # 対照損失計算
loss = mle_loss + cl_loss # SimCTG 損失
loss = loss.mean()
return loss
上記の変更を行なったコードで学習した結果、以下の類似度のようになりました。(同様に、長いので最初の5行5列部分のみです。)
対角成分の類似度が高く、異なるトークン間の類似度である対角成分以外は、類似度が小さくなっていることがわかります。
[0.9999, 0.2982, -0.5032, -0.3650, -0.5413,
[0.2982, 0.9999, 0.2020, 0.2578, 0.2829,
[-0.5032, 0.2020, 0.9999, 0.6498, 0.6361,
[-0.3650, 0.2578, 0.6498, 1.0, 0.6117, 0.7059,
[-0.5413, 0.2829, 0.6361, 0.6117, 0.9999
T5におけるContrastive Searchの実装
まず、推論の大まかな流れです。論文の実装で重要な部分は、前の単語列から次の単語を予測するContrastiveDecodingOneStepFastという関数ですが、githubに記載されている関数で推論すると推論速度が遅いため、huggingfaceのgenerateメソッドに合わせた形式で作成した、T5SimCTGGenerateクラスを実装しています。
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
decoding_len = 512 # 文章の最大長さ
beam_width = 3 # 実装では、ビームサーチの結果にContrastive Searchを行なっていた。
alpha = 0.5 # (1 - a) * 確率最大 + a * 類似度
model = T5SimCTGGenerate(T5_MODEL_DIR, max_length=decoding_len, num_beams=beam_width, simctg_alpha=alpha) # T5_MODEL_DIRに学習したモデルの重みなどが入っていると仮定
text_list = [
"text1 ......"
]
output = model(text_list)
print(output)
次に、T5SimCTGGenerateの実装です。エンコーダの推論結果を保持したまま、それと一つ前のデコーダの出力を利用して、デコーダによる推論を行っています。また、GPU使用していた際に、メモリーエラーになっていたので、その対処を入れています。論文実装はこの部分になります。
class T5SimCTGGenerate:
def __init__(self, model_dir, gpu_id=0, max_length=512, num_beams=3, simctg_alpha=0.5):
self.is_cuda = torch.cuda.is_available()
if gpu_id > -1:
self.device = torch.device(f'cuda:{gpu_id}') if self.is_cuda else torch.device('cpu')
else:
self.device = torch.device('cpu')
self.max_length = max_length
self.num_beams = num_beams
self.simctg_alpha = simctg_alpha
# トークナイザーとモデルの読み込み
self.tokenizer = T5Tokenizer.from_pretrained(model_dir, is_fast=True)
self.model = T5ForConditionalGeneration.from_pretrained(model_dir)
for param in self.model.parameters():
param.grad = None
self.model.to(self.device)
self.model.eval()
self.eos_token_tensor = torch.as_tensor(self.tokenizer.eos_token_id, dtype=torch.long, device=self.device)
def __call__(self, text_list):
"""
テキストのリストをバッチ化+トクナイザーによるエンコード後、T5による推論を行い、結果をトークナイザーでデコードする。
"""
batch_input_ids, batch_attention_mask = self.__create_batch(text_list) # バッチ化+エンコード
generated = self.forward(batch_input_ids, batch_attention_mask) # t5の推論
return [self.tokenizer.decode(t, skip_special_tokens=True, clean_up_tokenization_spaces=False) for t in generated]
@torch.no_grad()
def forward(self, batch_input_ids, batch_attention_mask):
self.model.eval()
batch_size, _ = batch_input_ids.size()
no_pad_length = 1
for bid in range(batch_size):
_no_pad_length = torch.sum(batch_input_ids[bid] != self.tokenizer.pad_token_id).item()
no_pad_length = max(no_pad_length, _no_pad_length)
# 生成結果を保存する配列
generated = torch.zeros((batch_size, self.max_length), device=self.device, dtype=torch.long) #[[] for _ in range(batch_size)] # バッチごとの生成文格納するリストです。
is_eos = [False for _ in range(batch_size)] # バッチごとの文章生成終了(EOS)判定リストです。
past_key_values = None
last_hidden_states = None
logits = None
batch_input_ids = batch_input_ids.to(self.device)
batch_attention_mask = batch_attention_mask.to(self.device)
selected_batch_indexes = torch.LongTensor([bs for bs in range(batch_size)]).to(self.device)
_selected_idx = torch.zeros((batch_size), dtype=torch.long).to(self.device)
_next_ids = torch.zeros((batch_size), dtype=torch.long).to(self.device)
model_kwargs = {}
model_kwargs["use_cache"] = True
_kewargs = ['decoder_input_ids', 'past_key_values', 'head_mask', 'decoder_head_mask', 'cross_attn_head_mask']
for _kewarg in _kewargs:
model_kwargs[_kewarg] = None
# エンコーダの事前計算
# 2. prepare encoder args and encoder kwargs from model kwargs
irrelevant_prefix = ["decoder_", "cross_attn", "use_cache"]
encoder_kwargs = {
argument: value
for argument, value in model_kwargs.items()
if not any(argument.startswith(p) for p in irrelevant_prefix)
}
encoder_kwargs["return_dict"] = True
encoder_kwargs["input_ids"] = batch_input_ids
encoder_kwargs["attention_mask"] = batch_attention_mask
model_kwargs["encoder_outputs"] = self.model.encoder(**encoder_kwargs)
# デコーダによる処理部分
for _, step in enumerate(range(self.max_length)):
if step == 0:
# T5では、最初のステップのみpad tokenをデコーダの入力とする。
with torch.no_grad():
decoder_inputs = torch.as_tensor([[self.tokenizer.pad_token_id] for _ in range(batch_size)], device=self.device) # pad_token_idで埋めた配列が最初の入力となる
model_kwargs["attention_mask"] = self.model._prepare_attention_mask_for_generation(
batch_input_ids, self.tokenizer.pad_token_id, self.tokenizer.eos_token_id
)
# モデルの入力形成は、huggingfaceのT5実装のものを使用
model_inputs = self.model.prepare_inputs_for_generation(decoder_inputs, **model_kwargs)
output = self.model(
**model_inputs,
output_hidden_states=True,
output_attentions=False,
return_dict=True
)
last_hidden_states = output.decoder_hidden_states[-1] #.cpu() # [B, S, E]
# バッチ数 => バッチ数xビーム数に変更
model_kwargs["past"] = enlarge_past_key_values( output.past_key_values, self.num_beams)
logit_for_next_step = output.logits[:, -1, :] #.cpu() # [B, V]
expanded_return_idx = (
torch.arange(decoder_inputs.shape[0]).view(-1, 1).repeat(1, self.num_beams).view(-1).to(decoder_inputs.device)
)
model_kwargs["attention_mask"] = model_kwargs["attention_mask"].index_select(0, expanded_return_idx)
model_kwargs["encoder_outputs"]["last_hidden_state"] = model_kwargs["encoder_outputs"].last_hidden_state.index_select(
0, expanded_return_idx.to(model_kwargs["encoder_outputs"].last_hidden_state.device)
)
_, seqlen, embed_dim = last_hidden_states.size() #.cpu() # [B, S, E]
next_probs = F.softmax(logit_for_next_step, dim=-1)
# 最大確率のk候補を取得
_, top_k_ids = torch.topk(logit_for_next_step, dim=-1, k=self.num_beams) # [B, V:38000くらい] -> [B, K:beam_width]
top_k_probs = torch.gather(next_probs, dim=1, index=top_k_ids) # 候補の確率を取得 [B, K]
# モデルの入力のpast_keyをバッチx候補のタプルに修正
model_inputs = self.model.prepare_inputs_for_generation(top_k_ids.contiguous().view(-1, 1), **model_kwargs)
# 次の単語を予測
with torch.inference_mode():
output = self.model(
**model_inputs,
output_hidden_states=True,
return_dict=True
)
model_kwargs["past"] = output.past_key_values
logits = output.logits[:, -1, :] #.cpu() # [B*K, V]
next_hidden = output.decoder_hidden_states[-1] #.cpu() # [B*K, 1, E]
context_hidden = last_hidden_states.unsqueeze(1).expand(-1, self.num_beams, -1, -1).reshape(batch_size*self.num_beams, seqlen, embed_dim) # [B*K, S, E]
# バッチごとの最大スコアの単語を選択
# 実際の式の部分を計算 (下の関数)
selected_idx = ranking_fast(
context_hidden,
next_hidden,
top_k_probs,
self.simctg_alpha,
self.num_beams,
) # [B]
for bs in range(batch_size):
_selected_idx[bs] = torch.add(selected_idx[bs], bs * self.num_beams)
_next_ids[:] = top_k_ids[selected_batch_indexes, selected_idx] #.unsqueeze(-1) # [B, 1]
next_hidden = next_hidden[_selected_idx, :]
last_hidden_states = torch.cat([last_hidden_states, next_hidden], dim=1) # [B, S, E]
logits = logits[_selected_idx, :]
logit_for_next_step = logits
for idx in range(batch_size): #バッチ数分
# EOSの場合スキップ
if is_eos[idx]:
continue
# EOSのチェック
if torch.eq(_next_ids[idx], self.eos_token_tensor).all():
is_eos[idx] = True
continue
generated[idx, step] = _next_ids[idx]
if False not in is_eos:
break
# 不要なものをGPUから除去
if self.device != torch.device("cpu"):
del batch_input_ids, batch_attention_mask, top_k_ids, top_k_probs, last_hidden_states, past_key_values, next_probs, _next_ids, _selected_idx, selected_idx, next_hidden, logits, output, context_hidden, model_kwargs
torch.cuda.empty_cache()
return generated
def preprocess(self, text):
# テキストの前処理
text = text.lower() # 本当は、テキストの正規化が必要
text_token = self.tokenizer.batch_encode_plus(
[text], max_length=self.max_length, truncation=True, padding="max_length", return_tensors="pt"
)
return text_token
def __create_batch(self, text_list):
# バッチの作成
batch_input_ids = []
batch_attention_mask = []
for text in text_list:
tokens = self.preprocess(text)
input_ids = tokens["input_ids"].squeeze()
attention_mask = tokens["attention_mask"].squeeze()
batch_input_ids.append(input_ids)
batch_attention_mask.append(attention_mask)
batch_input_ids = torch.stack(batch_input_ids)
batch_attention_mask = torch.stack(batch_attention_mask)
return batch_input_ids, batch_attention_mask
def enlarge_past_key_values(past_key_values, beam_width):
# モデルの入力のpast_keyをバッチx候補のタプルに修正
# from [B, num_head, seq_len, esz] to [B*K, num_head, seq_len, esz]
new_key_values = []
for layer in past_key_values:
items = []
for item in layer:
# item is the key and value matrix
bsz, num_head, seq_len, esz = item.size()
item = item.unsqueeze(1).expand(-1, beam_width, -1, -1, -1).reshape(bsz*beam_width, num_head, seq_len, esz) # [bsz*beam, num_head, seq_len, esz]
items.append(item)
new_key_values.append(items)
return new_key_values
def select_past_key_values(past_key_values, beam_width, selected_idx):
'''バッチx候補から最大スコアのpast_keyを選択
select_idx: [B]
'''
new_key_values = []
for layer in past_key_values:
items = []
for item in layer:
bsz_and_beam, num_head, seq_len, esz = item.size()
bsz = int(bsz_and_beam//beam_width)
item = torch.stack(torch.split(item, beam_width, dim=0)) # [B, K, num_head, seq_len, esz]
item = item[range(bsz), selected_idx, :, :, :] # [B, num_head, seq_len, esz]
items.append(item)
new_key_values.append(items)
return new_key_values
以上、T5のConsrastive Search実装になります。
まとめ
文章生成の改善手法を探していて、偶然見つけた論文ですが、簡単に実装でき、効果が高そうな手法な気がします。再現実験までやったわけではありませんが、今後、どんどん使っていきたい手法です。
個人的に、Contrastive Learningは、好きな分野で、画像系ですがSimSiamの記事を書いています。今後も、この分野には着目していきたいですね。
Discussion