LLM×強化学習の新しいパラダイム: Agentic RLの研究紹介
はじめに
本記事では、LLM研究で注目を集めるエージェント型強化学習(Agentic Reinforcement Learning、Agentic RL)のサーベイ論文
「The Landscape of Agentic Reinforcement Learning for LLMs: A Survey」[1]を読み、私なりの理解と要点を整理して紹介します。500件以上の文献を引用するボリュームのある論文ですが、ここでは重要だと感じたトピックに絞って取り上げます。Agentic RLに興味がある方や、LLMに対する強化学習の最新動向を知りたい方の参考になれば幸いです。
本記事の前提
- PPOやGRPOといったRLアルゴリズムの解説は他の多くの記事で既に説明されているため、本記事では割愛します。
- DeepSeek-R1[2]の研究を前提とする箇所がいくつかあります。未読の方は原著論文や解説記事の参照をおすすめします。私は以下のブログに大変お世話になりました。
3行でまとめ
- Agentic RLとは、LLMを学習可能な方策として扱い、環境と対話しながら長期的な目標を達成するエージェントとしての能力を強化学習で向上させる枠組みである
- エージェント性能向上の手段としてプロンプトエンジニアリングや教師ありファインチューニング(SFT)に加え、RLが重要な役割を果たしている
- エージェントのコア能力である6つの能力(推論、ツール使用、記憶、計画、自己改善、知覚)をRLで改善している
LLM×強化学習の動向
Agentic RLの話に入る前に、まずはLLMに対してRLがどのように適用されてきたかを簡単に振り返ります。
選好チューニング
ChatGPT(2022年11月)以降、LLM対話システムが急速に普及しました。LLMはWeb大規模コーパスで事前学習し、人間の指示に従って応答する振る舞いを獲得するために教師あり学習による指示チューニングを行います。ただしこれだけでは人間の好みから外れたり倫理的に不適切な応答が生じることがあるためRLを用いて応答を人間の好みに近づける選好チューニングが行われてきました。代表例が人間のフィードバックによる強化学習(RLHF)で、人間フィードバックで学習した報酬モデルを用いて応答に報酬を与え最適化します。その他AIフィードバックを用いるRLAIFや、報酬モデル/RLを使わず選好を直接学ぶDPO[3]もあります。本記事では、こうした選好チューニング手法を総称してPreference-Based Reinforcement Fine-Tuning(PBRFT)と呼び、本論文では従来のRLと位置付けます。
推論能力の向上
初期のLLMへのRL適用は選好チューニングが主でしたが、2024年9月にOpenAIから初の推論モデルであるOpenAI o1が発表されました。RLにより長考して答えを導く能力を高めたことが、システムカード[4]で報告されています。具体的な手法は公開されていませんでしたが、2025年1月に登場したDeepSeek-R1は、価値評価モデルを不要とするGRPOというRLアルゴリズムや、答えが一意に定まる問題に対して検証可能なルールベース報酬を用い、報酬モデルを取り除いて学習コストを下げるなどの具体策とともに、RLがLLMの推論・汎化能力を飛躍的に向上させることを示しました。これを機に、従来の「アライメント目的」から「能力向上目的」へとRLの適用が広がり、この流れが本記事の主題であるAgentic RLへとつながっています。
ツール利用性能の向上
2025年2月に発表されたChatGPTのDeep Research(Web検索を用いてレポートを作成する機能)にも、RLが適用されていると報告されています。[5]
またOpenAI o1の後継であるo3モデルでは、推論能力に加えて、いつ・どのようにツールを使用するのが良いかといったツール利用性能についても、RLによって性能が向上していることが報告されています。[6]
このようにLLMに対するRLの適用は選好チューニングからLLMの推論能力の向上、そしてエージェントとしてのツール利用性能の向上へと広がりを見せています。これらの歴史的背景を踏まえた上で本題であるAgentic RLについて紹介します。
Agentic RLとは
まずは本論文におけるAgentic RLの定義を引用します。

Agentic RLとは、LLMを、単発の出力整合性やベンチマーク性能の最適化を目的とした静的な条件付き生成モデルとして扱うのではなく、逐次的な意思決定ループの中に埋め込まれた「学習可能な方策」として捉えるパラダイムを指します。この枠組みでは、RLによってモデルに計画立案・推論・ツール利用・記憶保持・自己省察などの自律的なエージェント的能力を与えることで、部分的に観測可能で動的な環境において、長期的な認知的・対話的行動が自発的に現れることを可能にします。
つまり、Agentic RLとはLLMを自律的に行動するエージェントとして捉え、環境と対話しながら長期的な目標を達成するエージェントとしての能力をRLで向上させる枠組みといえます。
もう少し理解を深めるために従来のPBRFTとの違いを見ていきます。
PBRFTとAgentic RLの比較
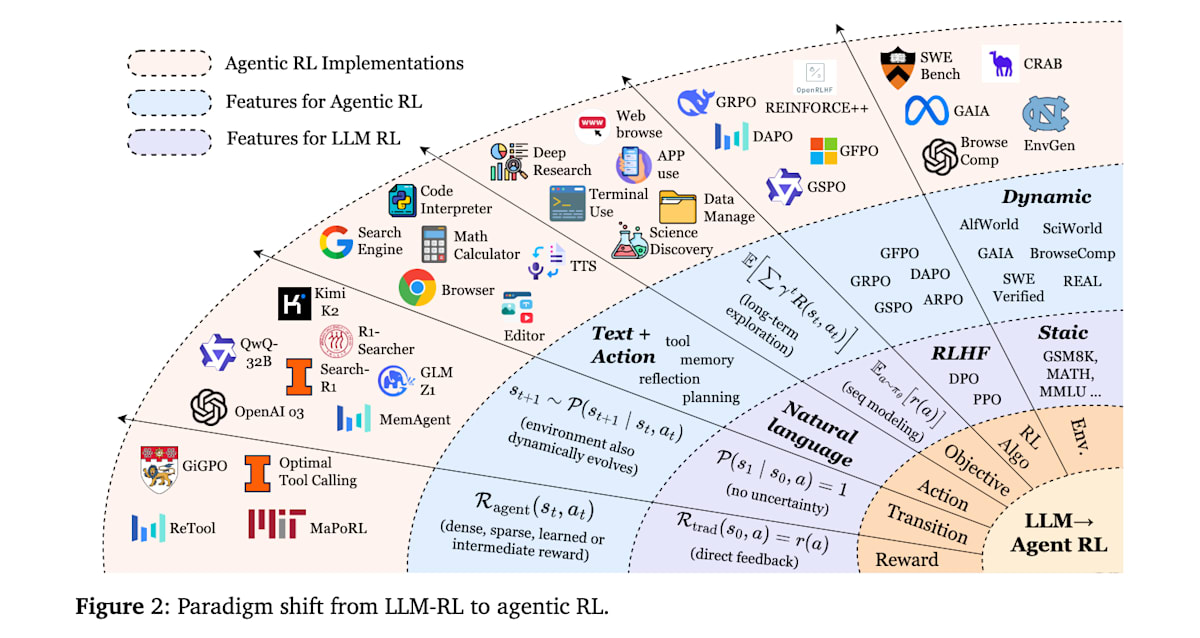
RLはマルコフ決定過程というフレームワークに基づいて定式化されるため、その観点で従来のRLとして位置付けられているPBRFTとAgentic RLの両者を比較したものが以下の表です。

状態 (State)
従来のPBRFTではエピソードの初期状態
例えばResearchエージェントの場合、Web検索を行い外部から得られる情報が観測に相当します。Agentic RLにおいては、状態=コンテキストと考えても良いかもしれません。
行動 (Action)
従来のPBRFTの行動はテキスト出力のみです。一方、Agentic RLでは行動空間がテキスト生成 (
例えばGUIを操作するエージェントの場合、テキスト生成は人間や他のエージェントへのメッセージ、あるいは連鎖思考(Chain-of-Thought、CoT)の生成に該当し、環境操作はクリックやスクロール、フォーム入力などのGUI操作に相当します。
遷移関数 (Transition)
従来のPBRFTでは1回の行動(テキスト生成)と同時にエピソード終了となるため状態遷移はありません。一方、Agentic RLでは確率的な遷移関数
報酬 (Reward)
従来のPBRFTでは1回の出力に対して良さを評価するスカラー報酬
目的関数 (Objective)
従来のPBRFTの目的関数
どちらのアプローチもLLMの性能を向上させるためにRLを活用しますが、その根底にある仮定、タスク構造、および意思決定の粒度において根本的に異なります。下の図はPBRFTからAgentic RLへの各要素でのパラダイムシフトを示しています。
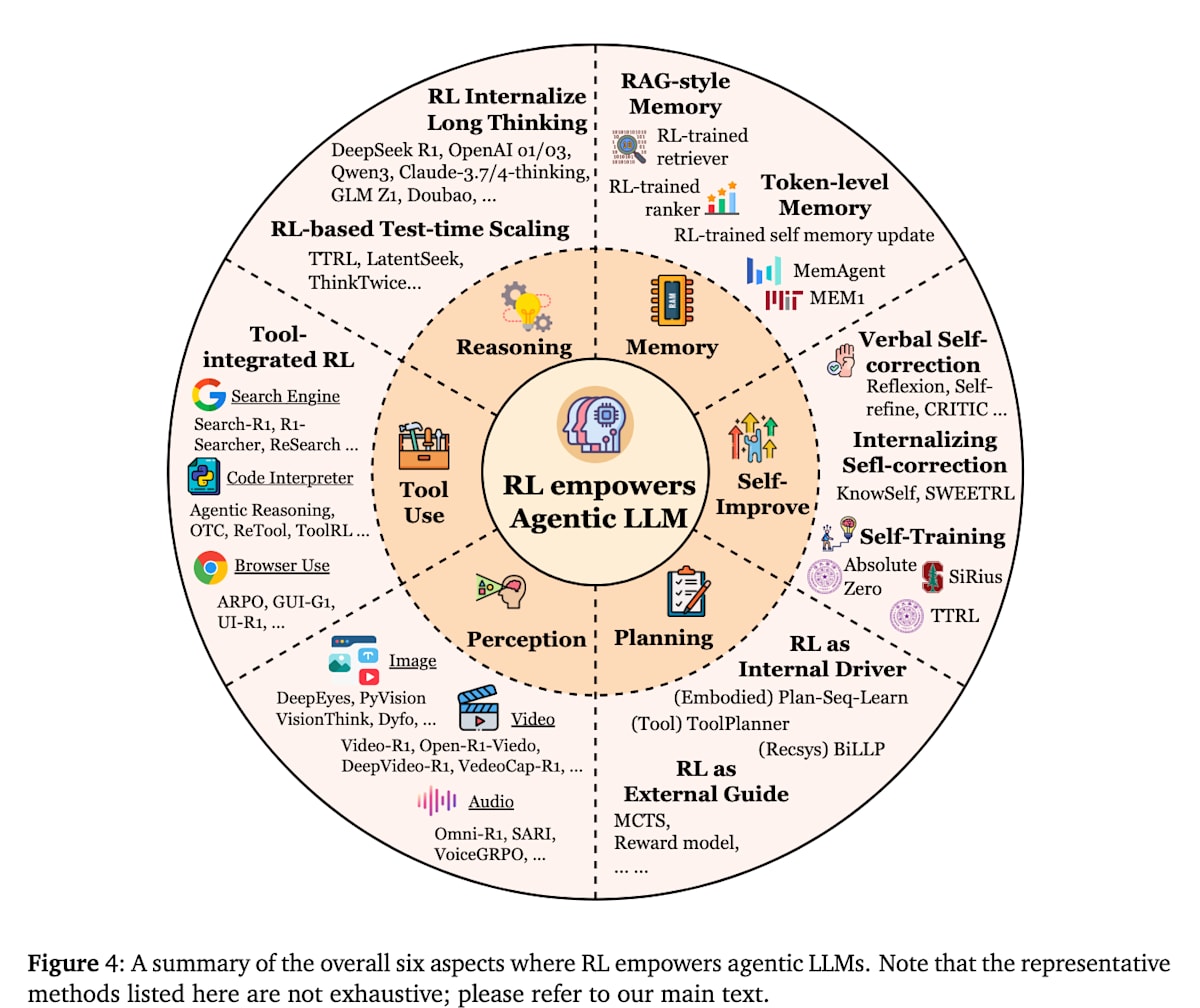
エージェントのコア能力とRLによる最適化
Agentic RLにおいて鍵となるのは、LLMエージェントにどのような能力を持たせそれらをRLで最適化するかということです。この論文ではコア能力として以下の6つの能力が挙げられています。ここではそれぞれ能力を高めるためにRLがどのように活用されているかを紹介していきます。
- Reasoning(推論)
- Tool Use(ツール使用)
- Memory(記憶)
- Planning(計画)
- Self-Improvement(自己改善)
- Perception(知覚)
推論(Reasoning)
推論(Reasoning)は、与えられた情報から論理的に結論を導くプロセスです。従来のLLMにおいてもChain-of-Thought(CoT)プロンプティングなどの技術によって推論する能力を持ちますが、最近はRLを用いてLLMの推論能力を向上させる研究が進展しています。その流れを決定的に加速させたのがDeepSeek-R1です。価値関数モデルを不要とするGRPOの採用や、一意解タスクに対するルールベース報酬による効率化など、具体的なアプローチを通じて推論強化の効果を広く知らしめました。ただし実装はクローズドなままだったため、再現性のある比較検証や発展的な研究を進める上でのハードルが残っていました。そこで登場したのがDAPO[7]です。DeepSeek-R1と肩を並べる性能を半分の学習ステップで達成しつつ、アルゴリズム・コード・データセット一式を完全オープンソース化し、推論モデルのRL研究を実装レベルで再現・拡張できる環境を提供した点が大きな貢献と言えます。
推論モデルの研究は推論能力のさらなる向上という方向性のほかに、考えすぎ(overthinking)の問題への対処も求められています。これは必要以上に長く考えすぎることでユーザへの応答に時間を要してしまう問題や長考することで逆に精度が悪化する問題につながります。
Qwen3[8]は複雑な多段階推論を行うための「思考モード(thinking mode)」と、迅速な応答のための「非思考モード(non-thinking mode)」を単一のモデルで実現するためにRLと教師ありファインチューニング(SFT)を組み合わせて以下の4stage学習を行っています。面白いのは、thinking modeの学習によってthinking budget(思考予算)と呼ばれるユーザーが推論に割り当てる計算リソースをトークン数で指定できる仕組みを自然に獲得している点です。
- stage1. Long-CoT Cold Start (SFT): 基本的な推論パターンをモデルにSFTで学習する
- stage2. Reasoning RL: 高度で複雑な推論タスク(数学やコーディングなど)性能をRLで改善する
- stage3. Thinking Mode Fusion (SFT): ユーザーからの /think や /no_think といった指示追従をSFTで学習する
- stage4. General RL: 一般的なタスク(指示追従、フォーマット遵守、エージェント能力など)に対して、ユーザーの好みに合うようにモデルの応答を調整する
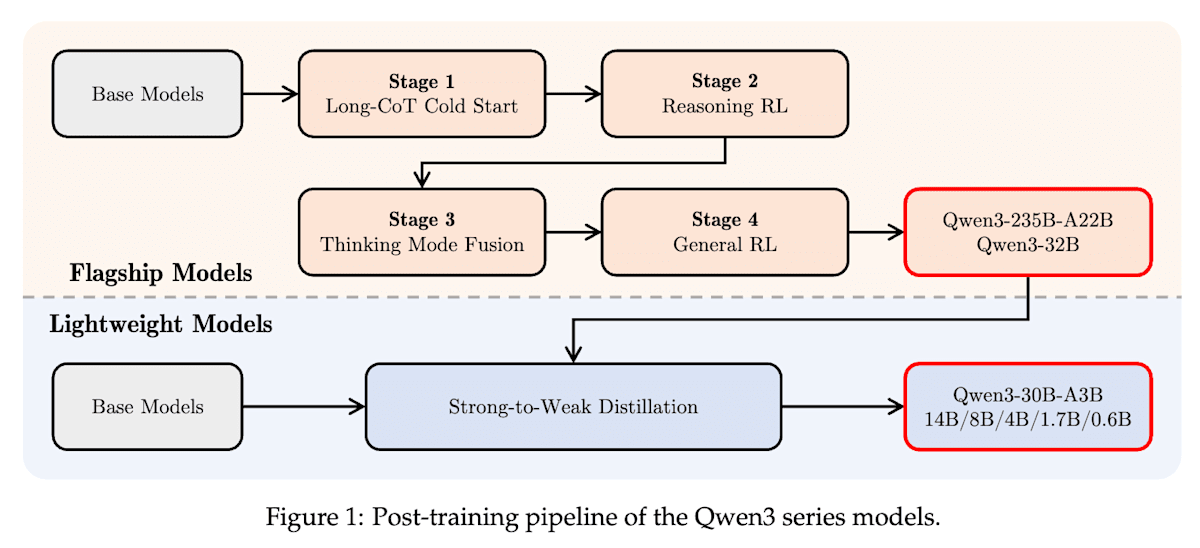
Qwen3 Technical Report (https://arxiv.org/abs/2505.09388)
またstage2のReasoning RLでは学習を安定させるために以下の基準を満たすようにデータセットを設計しています。特に2つ目と3つ目からReasoning RLにおいて難易度設定が重要そうな印象を受けます。
- コールドスタート段階で使用されていないこと
- コールドスタートモデルにとって学習可能であること
- 可能な限り挑戦的であること
- 広範なサブドメインをカバーしていること
ツール使用(Tool Use)
ツール使用は、エージェントが外部の情報源やAPI、計算資源などを呼び出して活用する能力です。検索エンジンでの情報取得や電卓・コード実行、他のモデルへのクエリなど、タスク達成に必要なあらゆる外部ツールとのインタラクションを含みます。RLによりエージェントは 「どのタイミングで、どのツールを、どう使うか」 を試行錯誤から学び取れるようになります。発展の流れは大きく3段階あります。
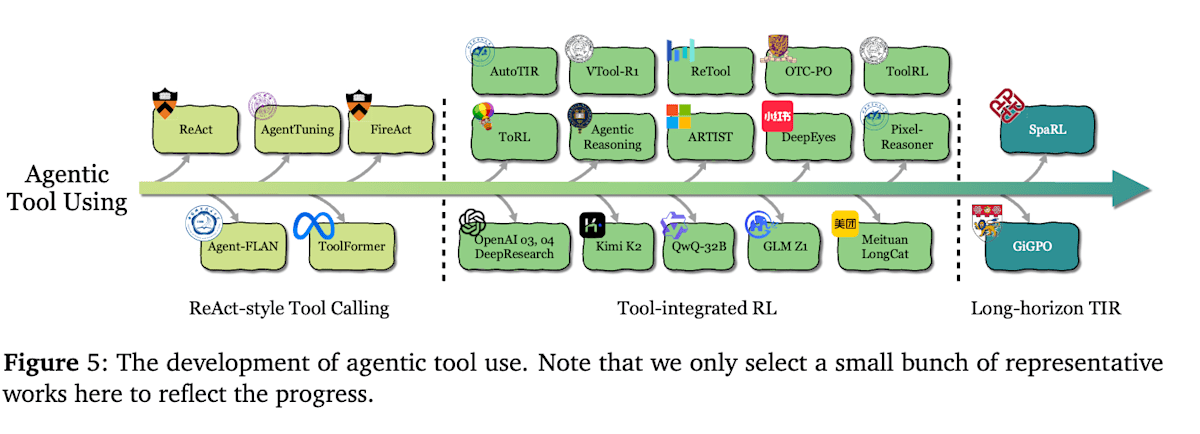
ReAct形式のツール利用
エージェントのツール利用について、初期はReAct[9]と呼ばれるプロンプトベースの手法や、Toolformer[10]と呼ばれるツール利用プロセスをSFTで模倣学習しツール利用能力を獲得する手法が試みられました。しかし、模倣学習の場合教わっていない未知のツールへの汎化は難しく柔軟性に欠けます。また、ツール利用履歴データを用意するコストもあることから、RLを用いてアウトカムベースでツール利用戦略を学習する試みが始まりました。
ツール統合型RL (Tool-Integrated RL)
次の段階では、ツール使用をLLMの認知ループに深く組み込み、複数ターンにわたってツールを使いこなすエージェントシステムが登場しました。どの局面でどのツールを呼ぶか、得た情報をどう活用するかを報酬に基づきRLで学習します。
例えばReTool[11]では複雑な数学的問題タスクに対してDeepSeek-R1のようにテキストベースのRLを行うのではなく、Pythonのコードインタプリタをツールとして活用する能力をRLによって学習することで正解率を向上させています。この研究ではSFTで基本的なツール利用能力を学習後にRLで最終的な回答に対する正解報酬によってツール利用戦略を学習しました。
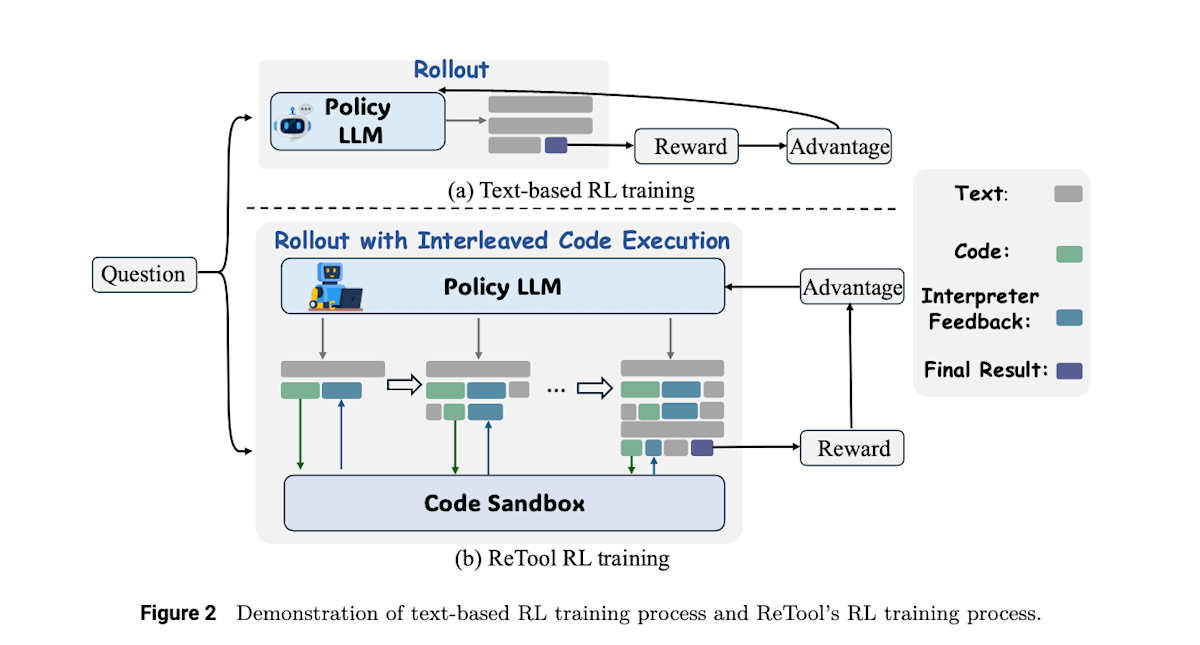
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs (https://arxiv.org/abs/2504.11536)
ほぼ同時期に発表されたARTIST[12]も似たようなアプローチをとっていますが、ARTISTは数学的タスクだけでなく、BFCL v3やτ-benchといったマルチステップのFunction Callingが必要となるベンチマークでの評価を行っています。これらのタスクに対して推論・ツール利用を繰り返し行いながらタスクに対する最終的な回答を生成し、最終回答の正解報酬に加えて、ツール呼び出し成功報酬によって、いつどのツールを使うのが良いかをRLで学習しています。
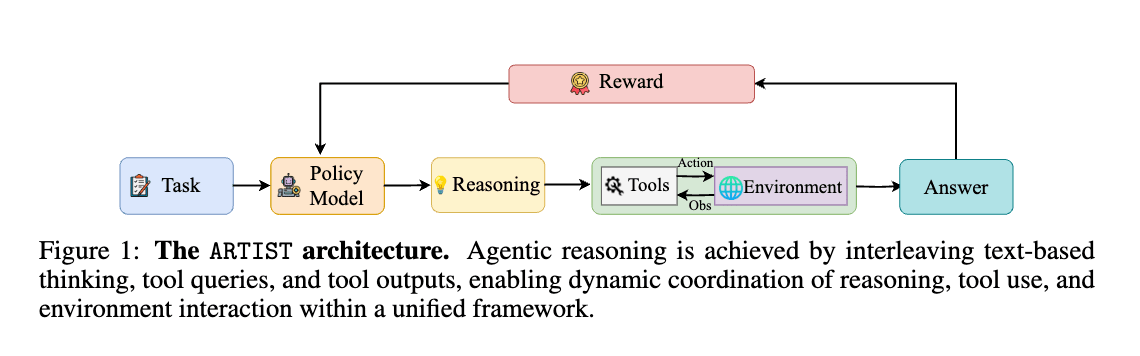
Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning (https://arxiv.org/abs/2505.01441)
上記で示したようなRLを利用したツール統合型推論は、研究領域だけでなくChatGPTのDeep ResearchやOpenAI o3のような商用システムのファインチューニングにも採用されていると言われています。(適用方法の詳細は不明)
長期的・マルチステップのツール使用
今後の研究の方向性として、長期的なステップでのツール連携や、複数のツールの組み合わせによる複雑なタスク解決が挙げられています。
DeepSeekが発表したGRPOは、数学の問題のような1問1答型のタスクに対して有効なRLアルゴリズムですが、一連の行動すべてをまとめて評価するため、マルチステップのタスクに対しては個々のステップの良し悪しを判断するのが難しいという課題があります。
GiGPO[13]ではこの問題に対処するために、エピソードレベルとステップレベルの2つのグループ構造でadvantage(行動の良し悪しの基準)を計算するGroup-in-Group Policy Optimization(GiGPO)という手法を採用しています。
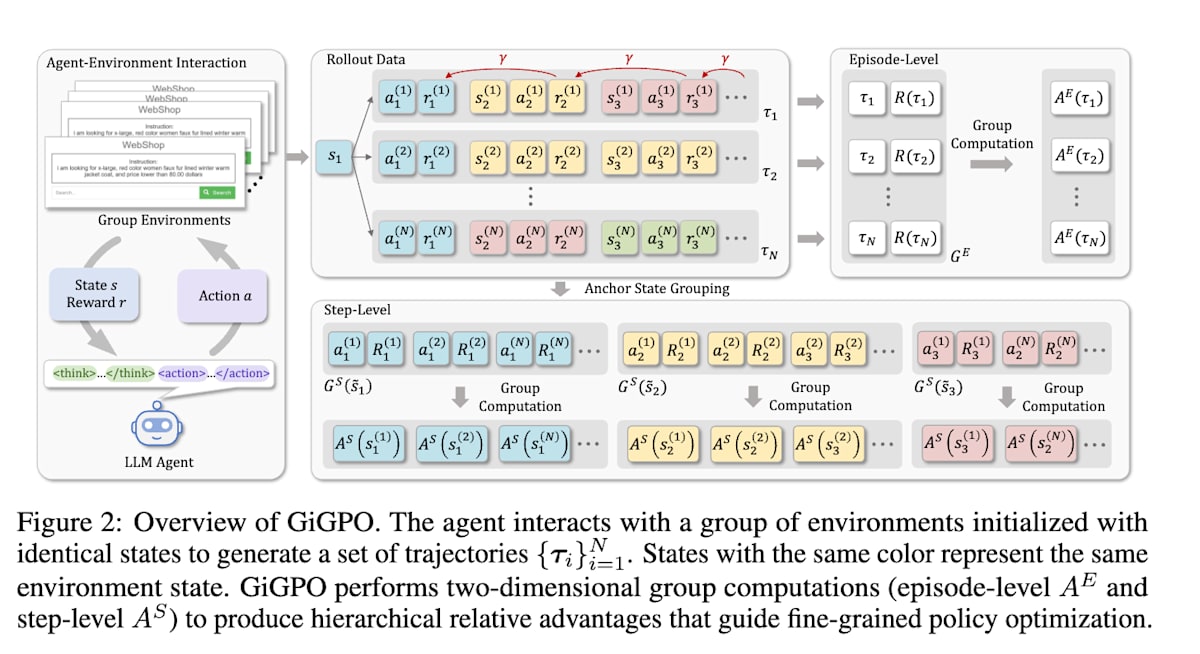
Group-in-Group Policy Optimization for LLM Agent Training (https://arxiv.org/abs/2505.10978)
メモリ(長期・短期記憶)
メモリはエージェントが過去に得た情報や経験を保持・再利用する能力です。LLM自身のコンテキストウィンドウは有限であるため、エージェントとして長期間活動するには外部記憶(ナレッジベースや対話履歴)を活用する必要があります。この課題に対し、従来はRetrieval-Augmented Generation(RAG)による検索・参照や、会話履歴を毎回プロンプトに詰め込むウィンドウ拡張などが用いられてきました。しかし、静的な検索戦略や手動で設計されたメモリ更新では、タスクに最適な情報検索・忘却ができない場合があります。Agentic RLでは、どの情報を記憶し、何を思い出すべきかをRLで学習させます。
RAG形式のメモリ
RAG形式の検索メカニズムをRLで最適化するアプローチとして、Tan et al.(2025)[14]が提案したReflective Memory Management(RMM)における後方リフレクション(Retrospective Reflection)が挙げられます。この手法は、従来のRAGが持つ「検索方法が固定的で、対話の文脈に応じて最適化されない」という課題に対処するものです。手順としては以下のとおりです。
- Retrieverによって検索された記憶の候補をRerankerが絞り込む
- LLMがその記憶を用いて応答を生成する際、実際にどの記憶を引用したかを自己評価する
- 引用された記憶には正の報酬(+1)、されなかった記憶には負の報酬(-1)を与えてRerankerのパラメータを更新する
この一連の処理をオンラインRLにより、対話を通じて「LLMが本当に必要とする記憶」をより的確に選択できるようRerankerを継続的に学習しています。
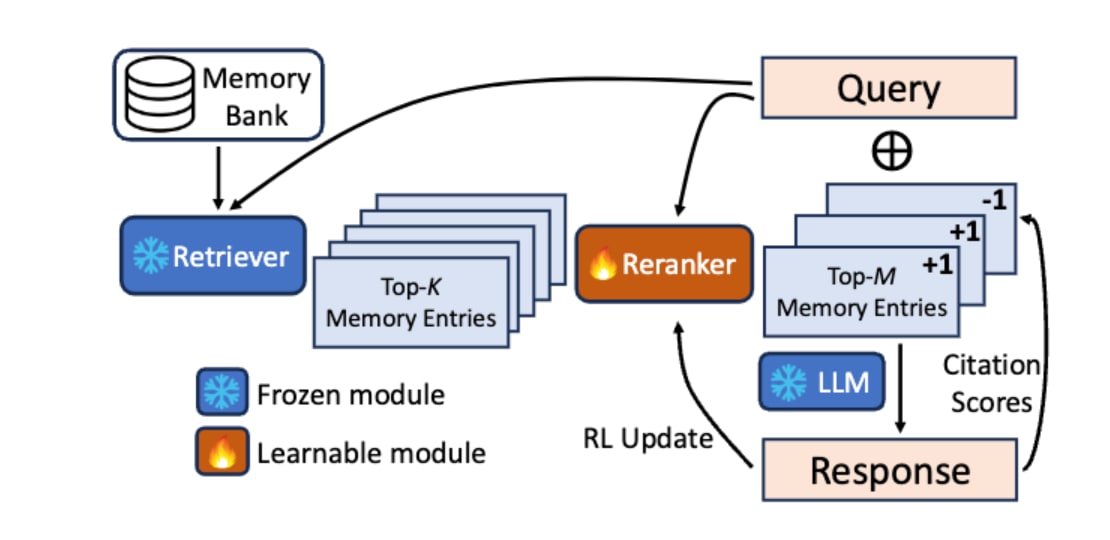
In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents (https://arxiv.org/abs/2503.08026)
上記はRAGの検索メカニズムの改善にRLを利用した例でしたが、Memory-R1[15]はエージェントが外部メモリを管理するためにもRLを利用します。Memory-R1は「Memory Manager」と「Answer Agent」という2つのエージェントを導入しています。Memory Managerは、メモリのエントリを「追加(ADD)」「更新(UPDATE)」「削除(DELETE)」「何もしない(NOOP)」といったメモリ操作を学習し、Answer Agentは、取得したメモリの中から最も関連性の高いものを選択して回答を生成します。両エージェントの学習にはRLが用いられていますが特に注目すべきはMemory Managerの学習方法です。Memory Managerは自身の行動そのものに対しての報酬は与えられず、Answer Agentが正しい回答を生成できたか?という最終的なアウトカムに対して報酬が与えられ最適なメモリ操作戦略を学習します。自身の行動が他のエージェントの行動に影響を与えてその結果に基づき学習が行われるというのはRLならではで面白い研究だなと思いました。
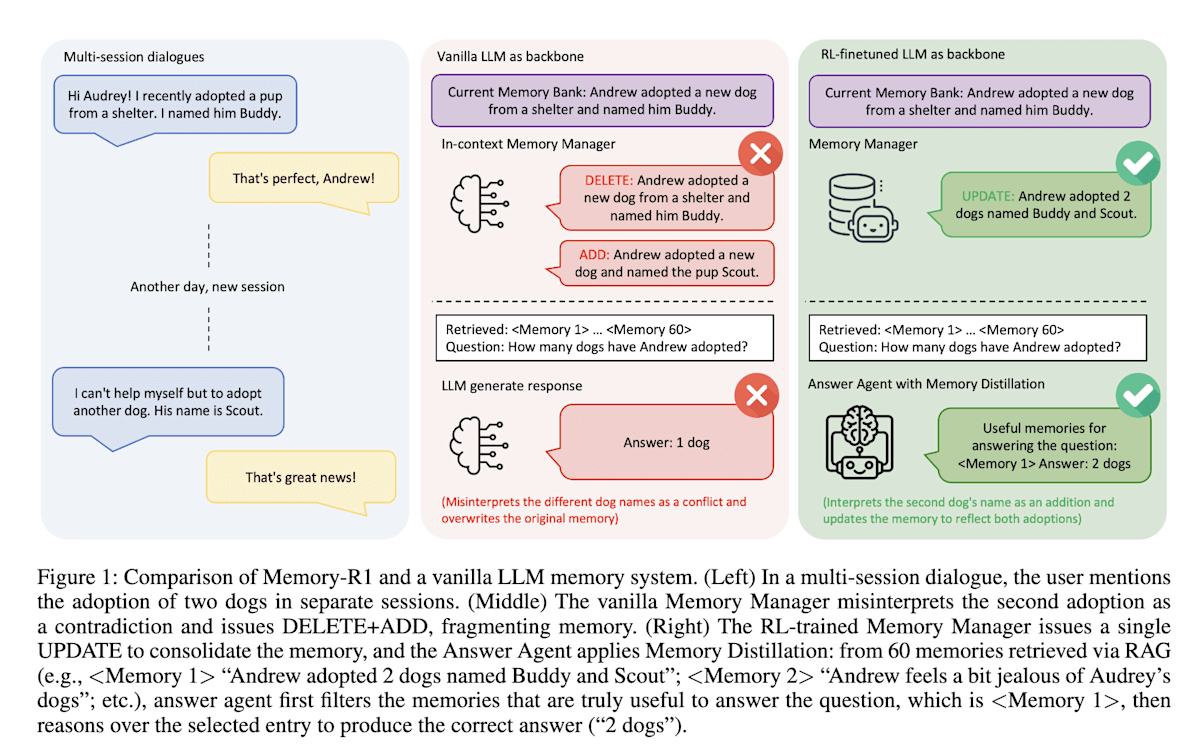
Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning (https://arxiv.org/abs/2508.19828)
Token-levelメモリ
こちらはRAGのように外部メモリを利用せず、LLM自身が学習可能なメモリを備えるアプローチです。
MemAgent[16]はLLMが非常に長いテキスト(数百万トークン)を扱えるようにすることを目的としています。人間が長い文章を読む際にメモを取るように、MemAgentはテキストをチャンクに分割して順に読み込み、固定長の「メモリ」に必要な情報を書き込みながら内容を理解していきます。このメモリ管理(限られたコンテキスト長に何を記憶させるか)を最終的なタスクの成功報酬に基づきRLで最適化します。MemAgentの仕組み自体も有用ですが、RLありMemAgentがRLなしMemAgentよりも性能が向上する結果となっておりRLの有用性が示されています。
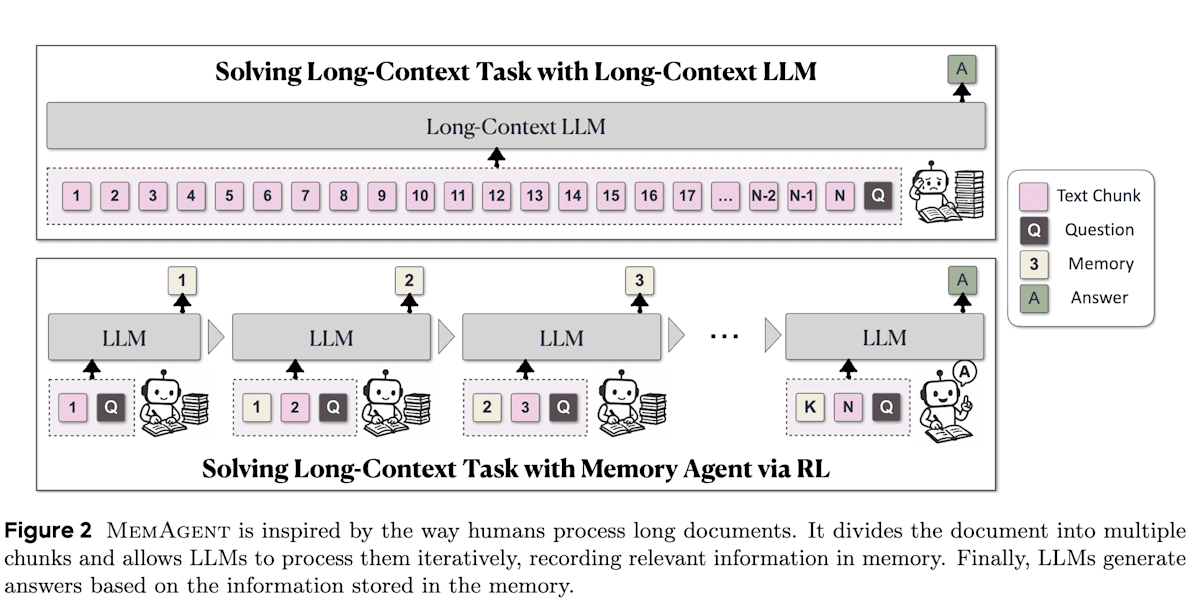
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent (https://arxiv.org/abs/2507.02259)
プランニング(計画)
プランニングとは、ゴールを達成するための行動系列を計画する能力のことです。人間の問題解決でも核心となるスキルであり、LLMエージェントにとっても 「いつ・何を・どの順序で行うか」 を決定する重要な役割を果たします。初期のLLMエージェントでは、与えられたタスクをいきなり解答させるのではなく、例えばReActのようにLLM自身にCoTと行動候補を逐次生成させるプロンプト手法が試みられました。しかしプロンプト工夫やFew-shot例に基づくこれらの静的プランニングでは、新しい状況への適応や試行錯誤による戦略改善は困難でした。 RLはこの問題に対し、プランニング戦略を経験から学習させるというアプローチを提供します。
RAP[17]ではモンテカルロ木探索(Monte Carlo Tree Search、MCTS)による探索を通じてCoT以上のプランニングを実現しています。従来のCoTは直線的な思考過程を生成していましたが、RAPはLLMを世界モデルとして扱い、MCTSを用いてツリーベースの思考過程(状態)を生成し、報酬が最も高くなるような推論過程のパスを先読み探索により選択することで、推論時間は増えるものの、より堅牢なプランニングを実現しています。各推論ステップの報酬(評価値)には、行動の尤もらしさ、状態の信頼度、自己評価、ゴールまでの近さのような複数の指標が採用されています。こちらはファインチューニングを行わないためRLを用いているわけではありませんが、興味深いので紹介しておきます。
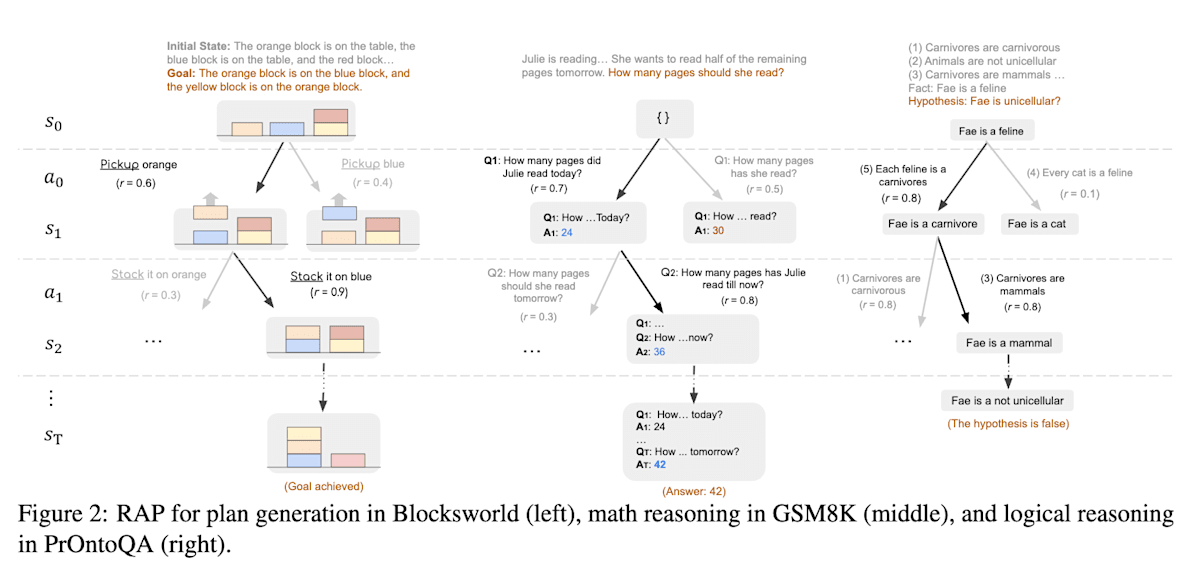
Reasoning with Language Model is Planning with World Model (https://arxiv.org/abs/2305.14992)
自己改善・自己反省(Self-Improvement / Reflection)
自己改善(Self-Improvement)とは、エージェントが自身の出力や行動を振り返り、誤りを訂正したり戦略を洗練したりする能力です。LLMは自己反省や自己検証のプロンプトを与えることで回答精度を上げることも可能ですが、Agentic RLではこれをエージェントの内部ループに組み込み、学習によって最適化します。
KnownSelf[18]は、エージェントがタスクを実行する際、現在の状況を自ら振り返り「このタスクは簡単だからすぐできる(Fast thinking)」「少し難しいから、一度立ち止まって考え直そう(Slow thinking)」「自分の能力では無理だから、外部の知識を使おう(Knowledgeable thinking)」といったように、自身の状態に応じて思考プロセスや知識の利用を自律的に切り替えることを可能にします。
具体的には、エージェントが生成した行動を3つの思考パターンにルールベースで分類してSFTで学習後、2つの応答ペアのデータセットを用意し、DPOによる選好チューニングを行います。このプロセスによって、ALFWorldという家庭内でエージェントが物体を操作するタスクやWebShopというWebサイトで指示どおり商品を購入するタスクで性能向上を示しています。
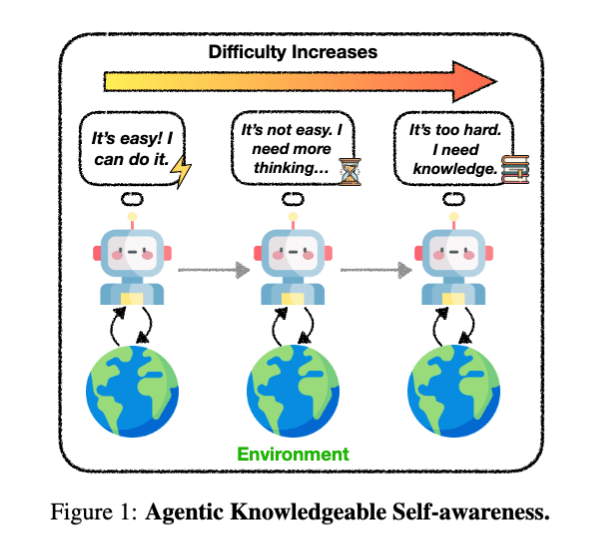
Agentic Knowledgeable Self-awareness (https://arxiv.org/abs/2504.03553)
自己反省とは少し方向性が変わりますが、人間の介入なしでエージェント自身で学習を行う自己改善の研究も進展しています。
Absolute Zero[19]は人間が作成したタスクやラベルを一切使用せずLLMが自律的に自己改善を行うフレームワークです。このフレームワークではLLMが問題の提案を行うProposerと問題の解決を行うSolverの2つの役割を担います。SolverではProposerが生成した問題に正答した場合にのみ報酬1を得ます。一方、Proposerは
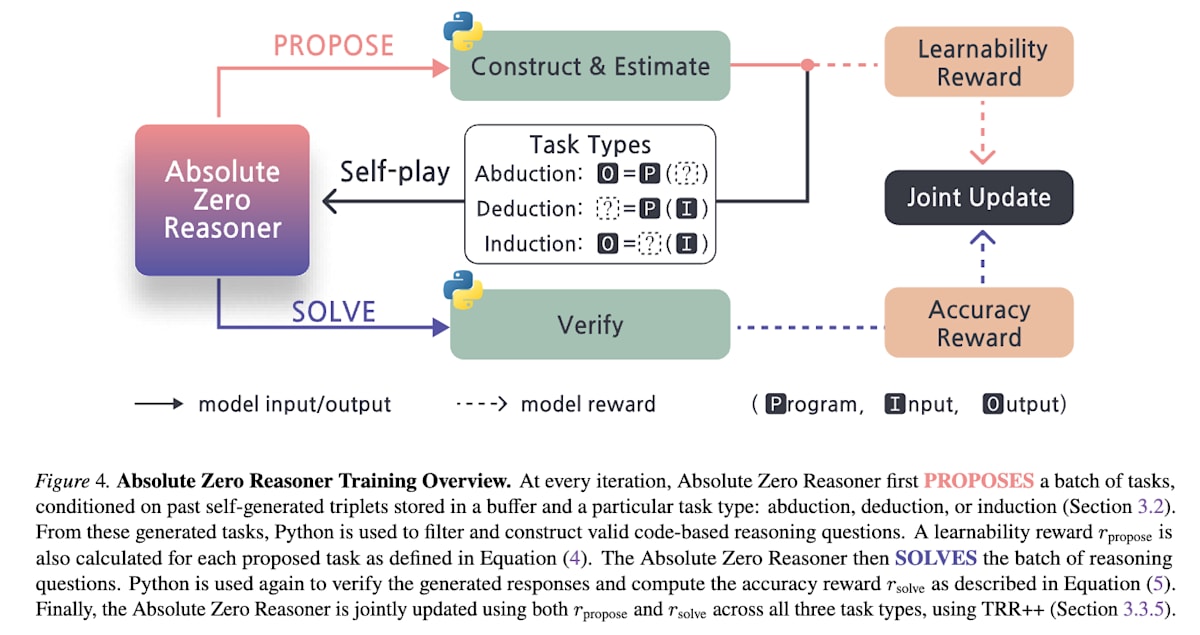
Absolute Zero: Reinforced Self-play Reasoning with Zero Data (https://arxiv.org/abs/2505.03335)
TTRL[20]は正解ラベルのないデータを使って推論時(テスト時)に自己進化による性能向上を図るものです。具体的には、LLM自身が生成した複数の回答の中から多数決で最大投票の予測を正解とみなして擬似正解データを作成し、擬似正解ラベルと予測が一致しているかを報酬としてRLを行うことで、人間のラベリングなしにモデルの推論能力を向上させています。これだけ見ると、単に選ばれやすい回答をより選ばれやすくなる(つまり確率分布を尖らせる)ようにファインチューニングしているだけのようにも思えますが、実験では数学のある特定のタスクでTTRLしたモデルで、異なる数学タスクに対しても性能が向上することが示されており、汎化性能の向上が確認されたようです。
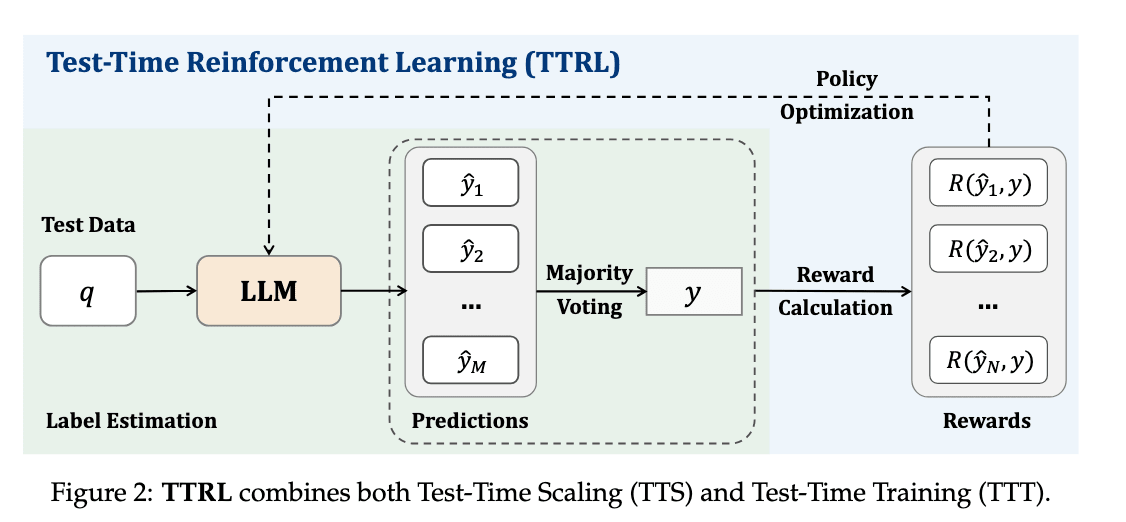
TTRL: Test-Time Reinforcement Learning (https://arxiv.org/abs/2504.16084)
知覚(Perception)
知覚(Perception)は、エージェントがテキスト以外のモダリティ(画像、音声、実世界のセンサデータなど)を理解・認識する能力です。LLMの推論を強化するRLの成功に触発され、これらの成果をマルチモーダル学習へ応用する取り組みが進められています。
Vision-R1[21]は、画像とテキストを同時に理解するマルチモーダル大規模言語モデル(Multimodal Large Language Model、MLLM)を用いて、特に数学の図形問題のような複雑な視覚的推論タスクにおいて人間のような深い思考プロセスを再現することを目指しています。DeepSeek-R1のようにRLを用いて数学問題に対する推論能力を向上させるアプローチですが、単純にRLを適用するのではなく、「DeepSeek-R1の模倣学習」と「段階的思考抑制トレーニング」という2段階の学習を組み合わせているのが特徴です。
- 1段階目: MLLMを用いて視覚情報を詳細なテキスト記述に変換させるModality Bridgingを実施し、そのテキストをDeepSeek-R1に渡すことで詳細なCoTを出力させます。DeepSeek-R1のCoTを正解ラベルとしてMLLMを模倣学習することで、視覚情報に基づくCoTを安定的に生成できるようにします。
- 2段階目: 1段階目終了時点ではCoTが長くなると性能が低下する傾向があることから、2段階目では思考の長さを制限し段階的に増やしながら、RLで視覚情報を含めた推論能力向上を行う段階的思考抑制トレーニングを実施します。
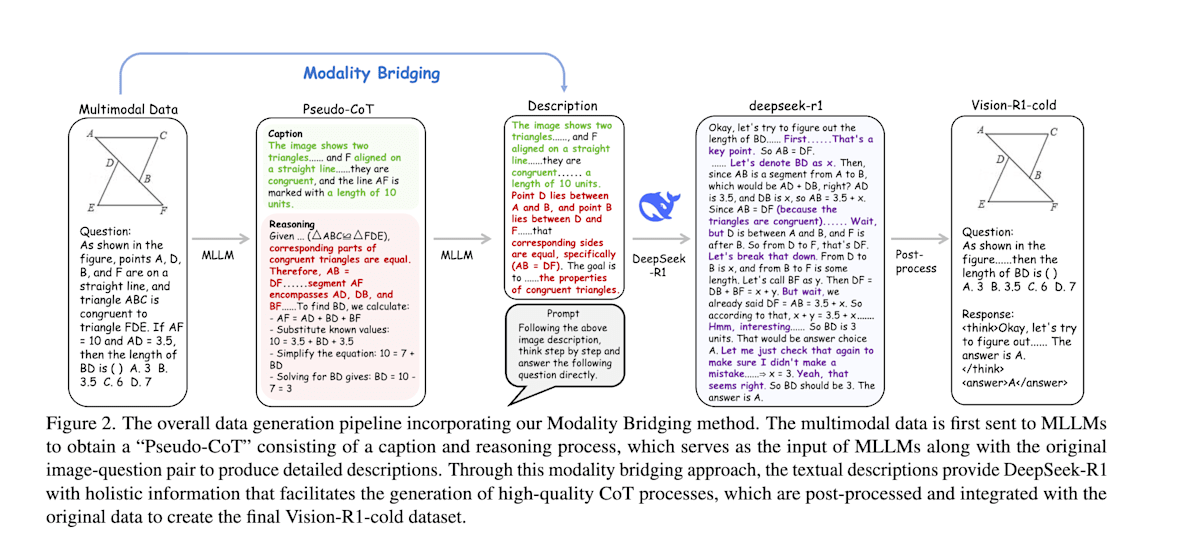
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models (https://arxiv.org/abs/2503.06749)
OPENTHINKIMG[22]は、視覚ツールを使って視覚的問題を解くための学習にRLを利用しています。
具体的には、画像とテキストをVLMに入力し、グラフの数値を読み取るOCRツール、画像の一部を拡大するズームツールといった視覚的なツールをVLMが操作しながら視覚的問題を解きます。モデルは環境内でツールを自由に使い、ツールの利用結果を視覚情報としてインプットしながら、最終的なタスクの正解・不正解という報酬を最大化するように方策を更新していきます。特に、ツールの視覚的な出力をモデルの次の判断材料として直接利用する点が重要で、これにより、モデルは自らの行動が視覚的にどのような結果をもたらすかを理解しながら、より賢いツール選択ができるようになります。
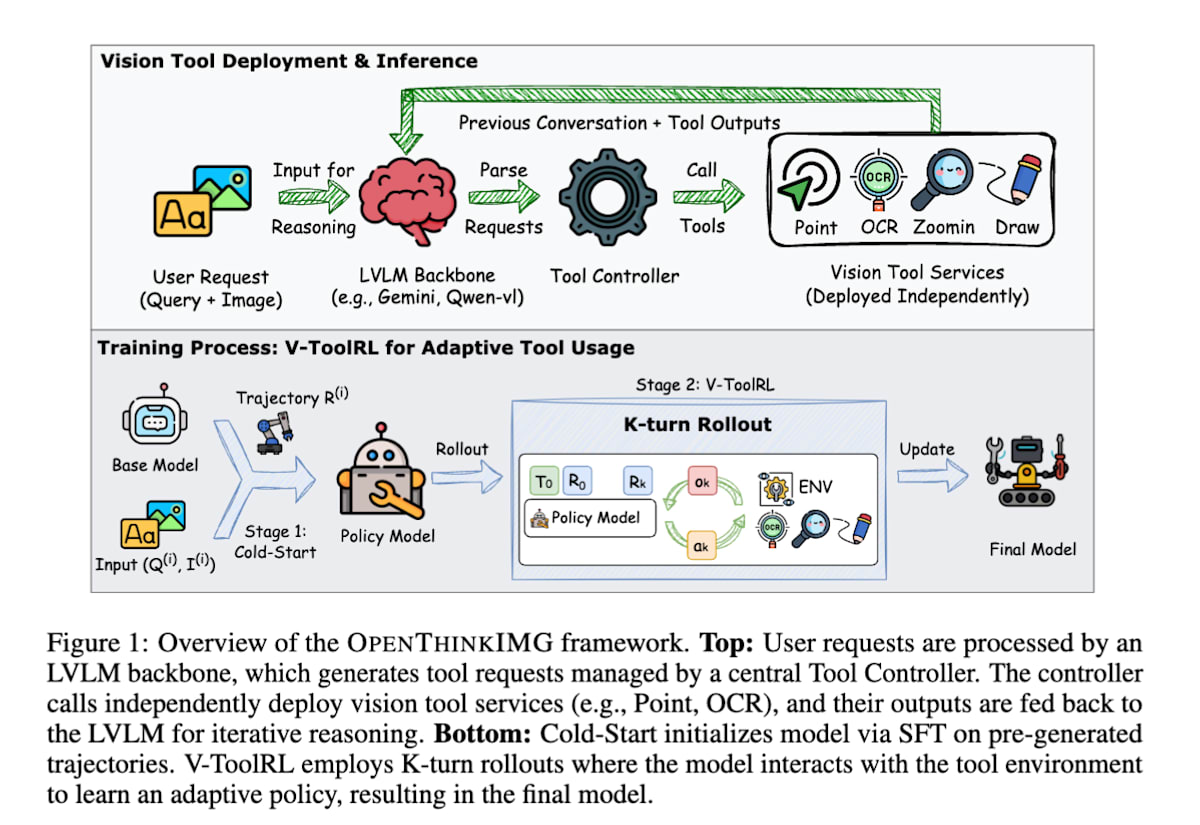
OPENTHINKIMG: Learning to Think with Images via Visual Tool Reinforcement Learning (https://arxiv.org/abs/2505.08617)
Visual Planning[23]では、人間が頭の中で地図を思い浮かべたり、家具の配置をシミュレーションしたりするように、モデルが言語ではなく画像によってタスクの計画を立てることを目指しています。モデルは現在の画像状態から次の画像状態を複数候補生成し、前の状態と現在の状態との差分から行動(ナビゲーションの場合、上下左右の移動方向が行動に該当)をルールベースで算出します。このステップを繰り返し、ゴールに近づく場合に報酬を与えることで、ゴールまでの行動計画を画像ベースで学習します。
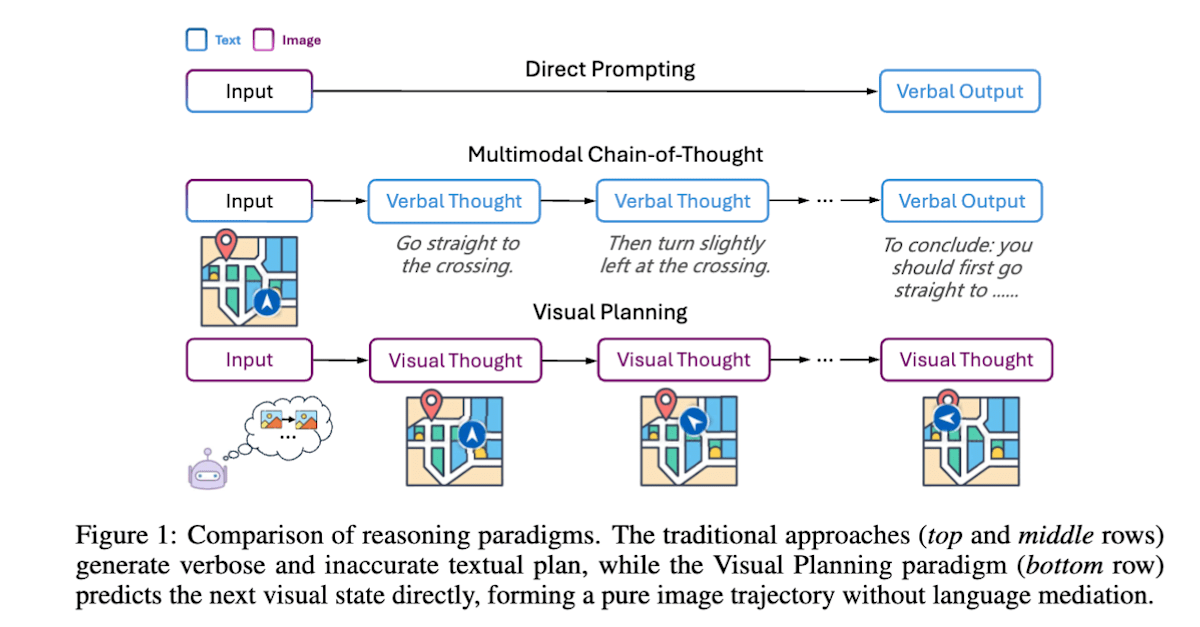
Visual Planning: Let’s Think Only with Images (https://arxiv.org/abs/2505.11409)
主な応用分野と代表的な手法
Agentic RLはさまざまなタスク領域で応用が始まっており、この論文では以下の応用分野が挙げられています。本節では、各エージェント領域においてRLがどのように活用されているか、代表的な手法・研究例を紹介します。
- 検索・調査エージェント
- コードエージェント
- 数学エージェント
- GUIエージェント
- マルチエージェント
- その他(Vision, 身体性)
検索・調査エージェント
検索・調査エージェントは、外部の知識ベースやWeb検索エンジンを活用して、ユーザーの質問や調査依頼に対して正確かつ包括的な回答を提供することを目的としています。
LLMに検索能力を付与する方法としてRAGが広く用いられていますが、検索と推論を交互に行うような複雑なマルチターンタスクに対しては学習を行わないプロンプトベースの手法では限界があることから、検索クエリの生成、検索、推論をend2endで直接最適化するためにRLを利用する研究が進展しています。
主要な研究の一つは、RAGの基盤を活用しつつWeb検索APIを利用して、クエリ生成と多段階の推論をRLで最適化するアプローチです。
search-R1[24]は<think>(思考), <search>(検索クエリ),<information>(検索結果), <answer>(回答)という4つの特殊トークンを導入し、思考と検索を複数ターン繰り返し最終回答をするプロセスをPPOやGRPOといったRLアルゴリズムで学習します。思考、検索クエリ、回答をそれぞれ行動として扱い、最終的な回答が正解かどうかを報酬として与えることで検索と推論の両方の能力を向上させています。また<information>(検索結果)に対しては損失計算を行わないようにすることで検索結果そのものを学習することを避け、結果として学習が安定し性能向上に貢献しているようです。
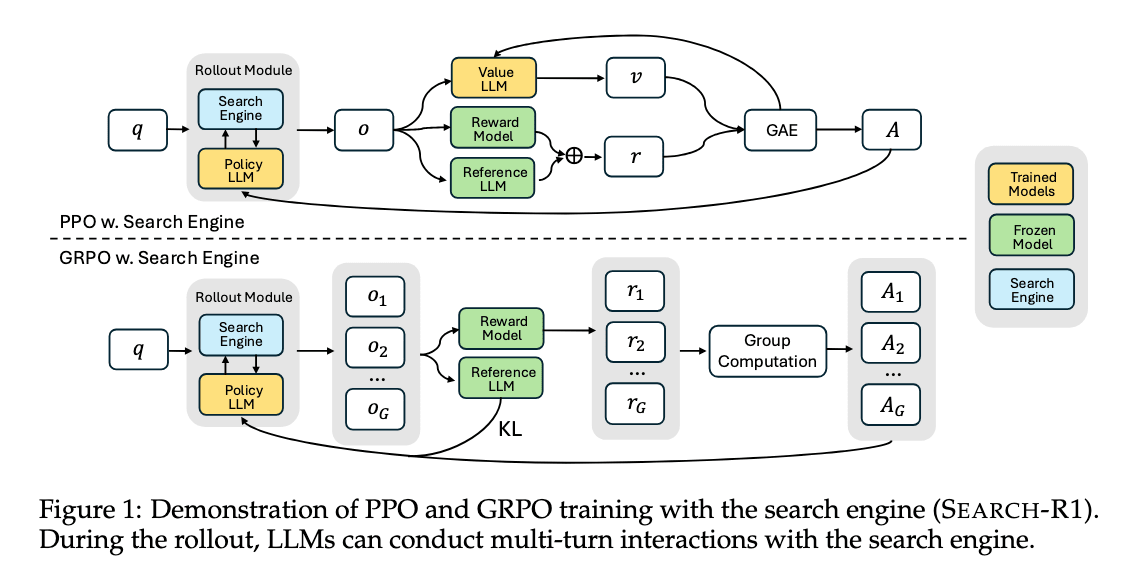
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning (https://arxiv.org/abs/2503.09516)
search-R1の課題として、検索ターン数を大きくすると1つの学習により多くの時間を要するため、学習効率の観点からエージェントの検索ターン数を10回以下に制限する必要がありました。
ASearcher[25]はsearch-R1を発展させたもので、複数の検索タスクを並行処理する際に、エージェントの行動とモデルの学習を完全に分離した非同期な学習システムとすることで学習効率を改善し結果として最大128ターンという長時間の探索をエージェントに学習させることが可能になりました。
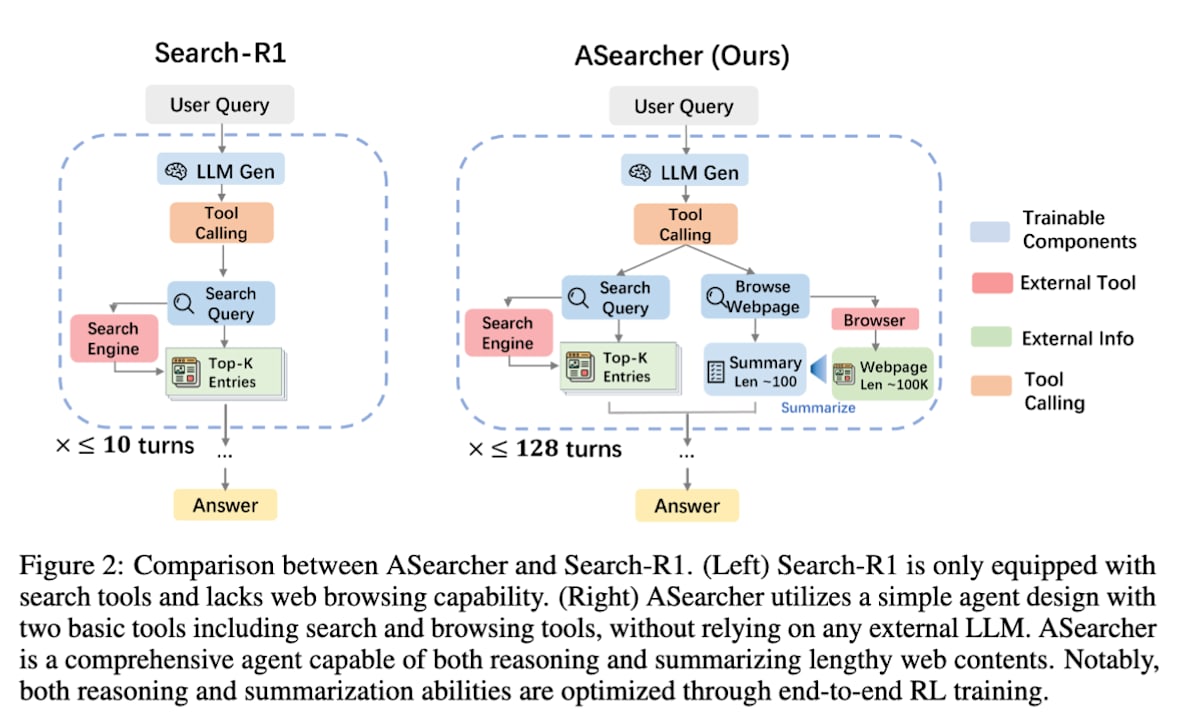
Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL (https://arxiv.org/abs/2508.07976)
上記のように外部のWeb検索APIを利用する方法は、Web上のドキュメント品質がノイズとなり学習が不安定になり得ること、学習に必要となるAPI利用コストが高いという2つの課題があります。
ZeroSearch[26]は、外部の検索エンジンを効果的に利用する能力を学習させる点では上記の手法と同様ですが、最大の特徴は学習中に実際の検索エンジン(Googleなど)を一切使わない点にあります。search-R1の図とZeroSearchの図を比較するとエージェントの行動収集を行うRollout ModuleにおいてSearchEngineがSimulationLLMに置き換わっていることが確認できます。このように学習対象とは別のLLMを使って検索エンジンの挙動を模倣し、その模倣された環境の中でLLMの検索と推論能力を学習します。結果としてZeroSearchは実際の検索エンジンで学習させたモデルと同等あるいはそれ以上の性能を圧倒的に低いコストで達成できることを示しています。LLMで検索エンジンを模倣できるかという点はちょっと疑問なのでこれでうまくいくのが不思議な感じはしますが、面白い研究だなと思いました。
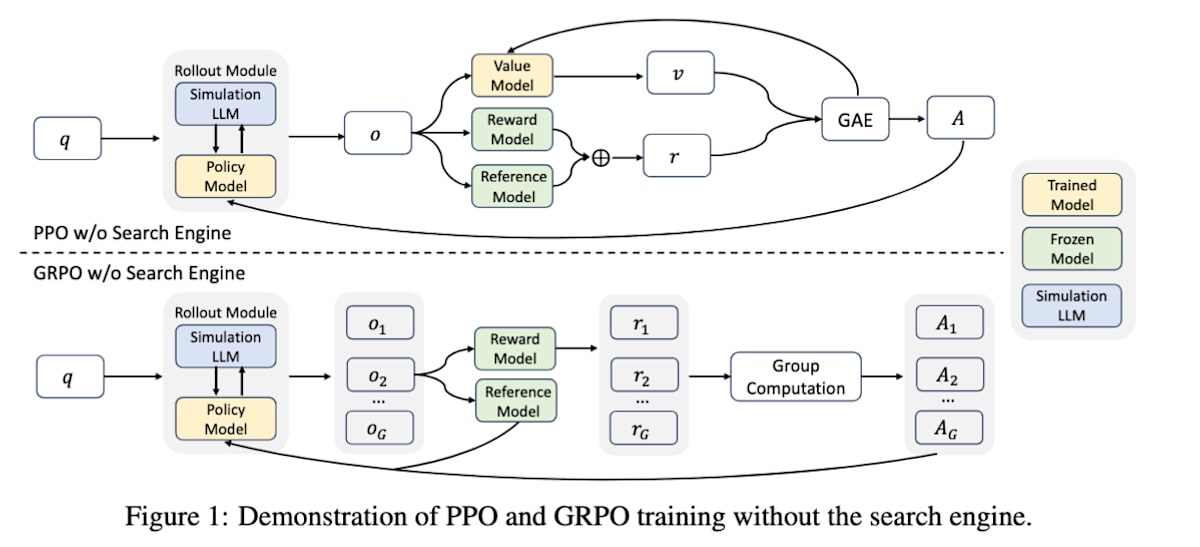
ZEROSEARCH: Incentivize the Search Capability of LLMs without Searching (https://arxiv.org/abs/2505.04588)
コードエージェント
コードエージェントはOpenAIのCodexやAnthropicのClaude Codeのような、コーディングタスクに特化したエージェントです。本論文においてコードエージェントのタスクは、単一ターンでのコード生成、複数ターンでのコード改良、ソフトウェアエンジニアリングの自動化の3つに大別されています。この記事では、特に難易度の高いソフトウェアエンジニアリングを自律的に行うエージェントの研究を見ていきます。
ソフトウェアエンジニアリングはコードの読み込み・修正・追加に加えて、外部ツール(コンパイラ、リンター、バージョン管理、シェル)の利用やテストによる結果の検証など、複雑で長期的なステップを伴うタスクです。このようなシナリオではエージェント的な能力が必要となり、RLを用いてエージェントの能力を向上させる研究が進展しています。
SWE-RL[27]では、GitHubの460万件の公開レポジトリを対象に、イシュー、プルリクエスト、レビューコメントを時系列で収集してRL用の学習データセットを構築しています。
本研究の重要な点は、複雑なシミュレーターや実行環境を必要とせず、エージェントが生成した修正コード difflib.SequenceMatcherという文字列の差分から類似度を計算するクラスを使って報酬を計算している点です。これにより、膨大なデータに対して軽量かつスケーラブルなRLが可能となっています。
またSWE-RLはソフトウェアのバグ修正という特定のタスクのみで訓練されたにもかかわらず、その過程で獲得した推論能力が、数学、一般的なコーディング、言語理解といった全く異なるドメインのタスクにおいても性能向上をもたらすことを示しました。
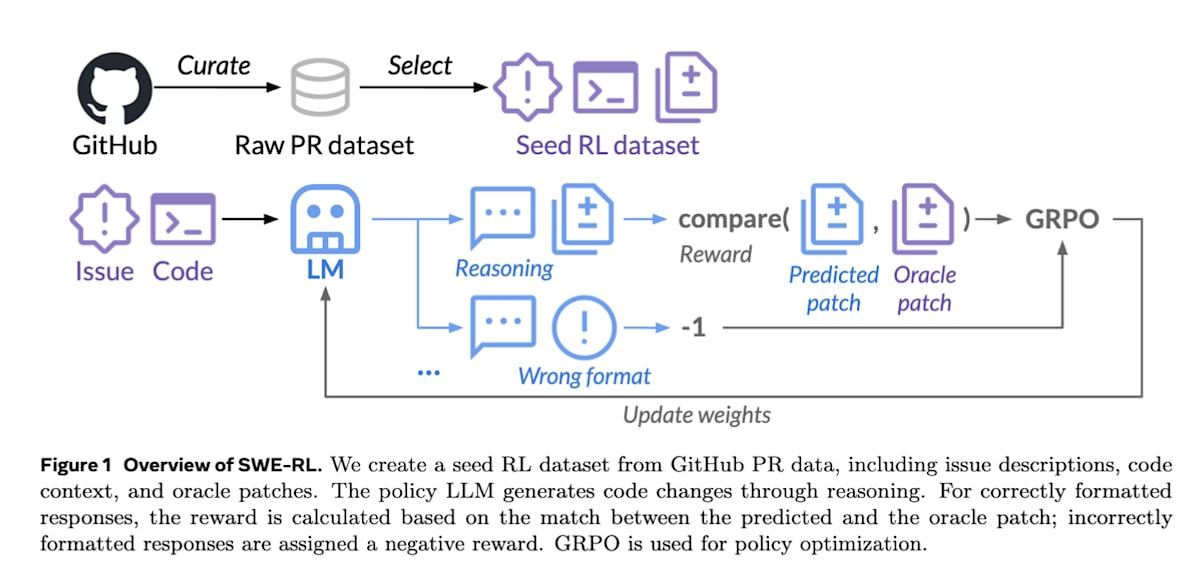
SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution (https://arxiv.org/abs/2502.18449)
SWE-RLがコード実行環境を必要としないのに対し、実際にコードを実行する環境を利用してRLを行う研究もあります。
Qwen3 Coder[28]はコード実行環境を用意しテスト結果やエラー情報などのような検証可能な報酬を利用してコーディング能力向上のためのRLを行なっています。コード実行環境についてもアリババクラウドを活用し2万個の独立した環境を並列実行可能となるようにシステムを構築することで大規模な強化学習を実現しています。結果としてソフトウェアエンジニアリングタスクを扱うSWE-Bench Verifiedにおいてオープンソースモデル中で最高水準の性能を達成しています。
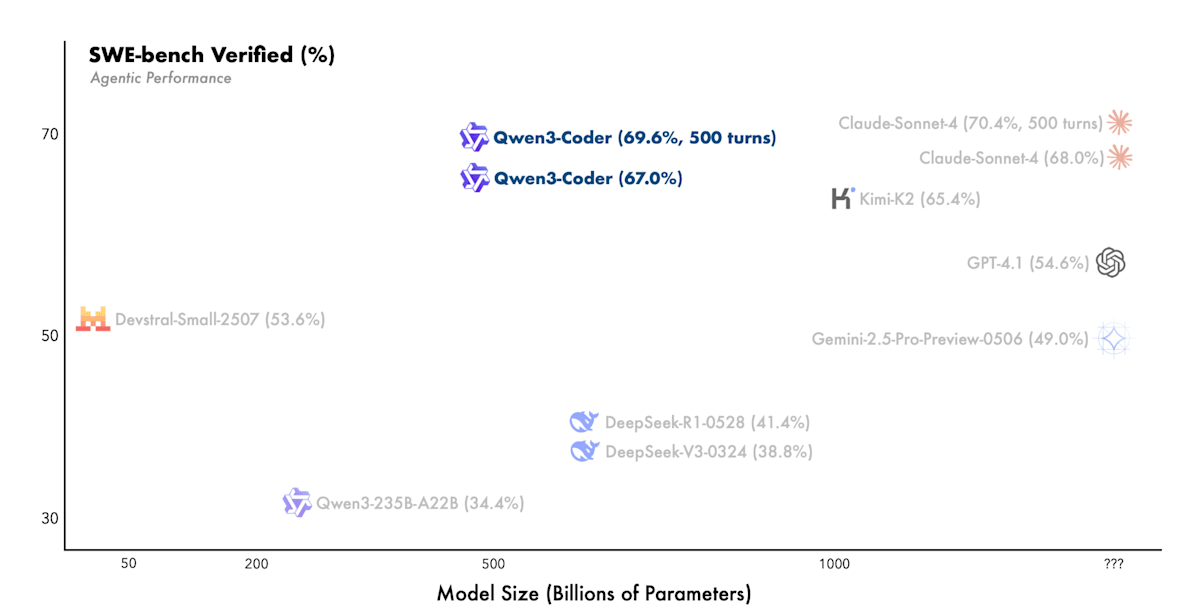
Qwen3-Coder: Agentic Coding in the World (https://qwen.ai/blog?id=d927d7d2e59d059045ce758ded34f98c0186d2d7&from=research.research-list
数学エージェント
数学的推論は、その記号的な抽象性、論理的な一貫性、そして長期にわたる演繹が求められるという性質から、LLMエージェントの推論能力を評価する上で極めて重要な基準と考えられています。エージェントのコア能力で紹介した研究でも数学的なタスクに対する性能を見ているものが数多くあります。
rStar2-Agent[29]は、難しい数学的タスクに対して、推論データによるSFTなしの純粋なAgentic RLアプローチによって、14Bパラメータで671BのDeepSeek-R1-Zeroを上回る性能と学習効率を達成しています。この研究では、ツール利用の節で紹介したReToolのようにPythonの実行環境をツールとして用いたツール統合型推論を行っている点と、複数回ロールアウトで生成した回答候補から最終的に正解しており推論過程で利用したツール呼び出しのエラーが少ない質の高い成功例を優先的にサンプリングして学習するResample on Correct(RoC)と呼ばれるテクニックを導入している点が特徴です。
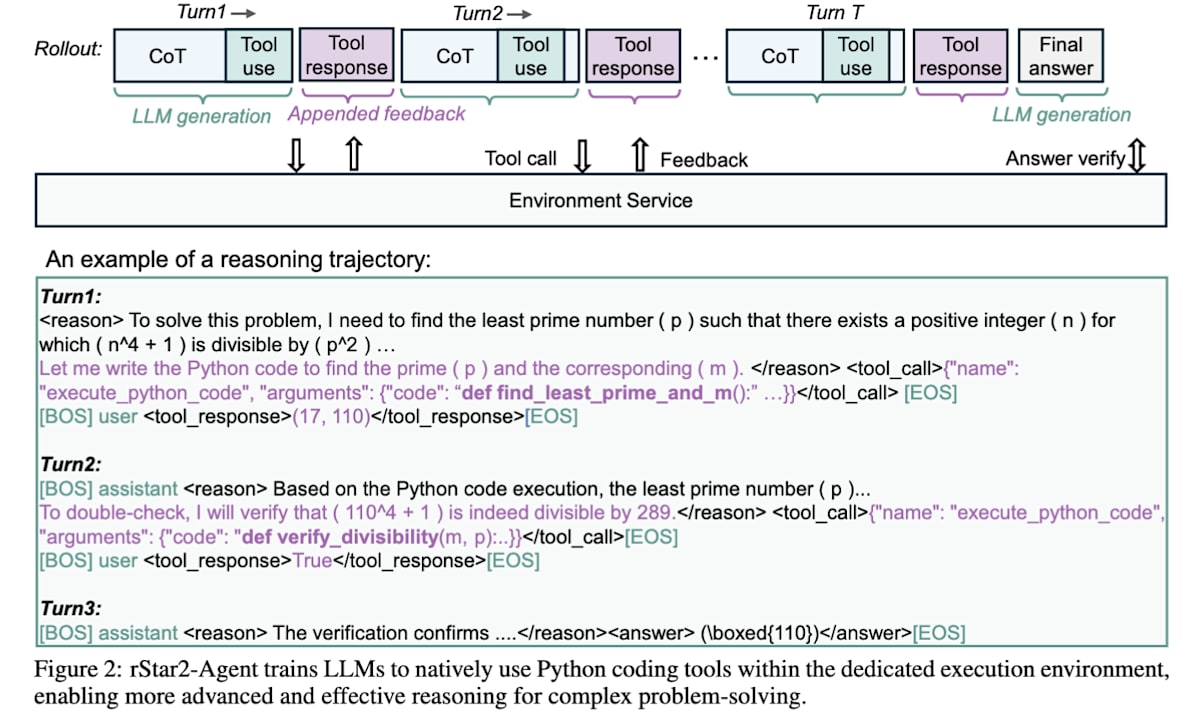
rStar2-Agent: Agentic Reasoning Technical Report (https://arxiv.org/abs/2508.20722)
1Shot-RLVR[30]では数学的推論能力を向上させるために、たった1つの訓練例を用いたRLが有効であったことを実証しています。具体的には、ベースモデルのQwen2.5-Math-1.5Bに対して1つの訓練例を適用するだけで、MATH500ベンチマークで36.0%から73.6%へと大幅な性能向上を達成し、6つの主要な数学的推論ベンチマークの平均で17.6%から35.7%に改善したことを示しています。これは、数千の例を含むデータセットを用いた場合と同等またはそれ以上の性能であることを示唆しており、少量のデータでLLMの推論能力を効果的に活性化できることを強調しています。
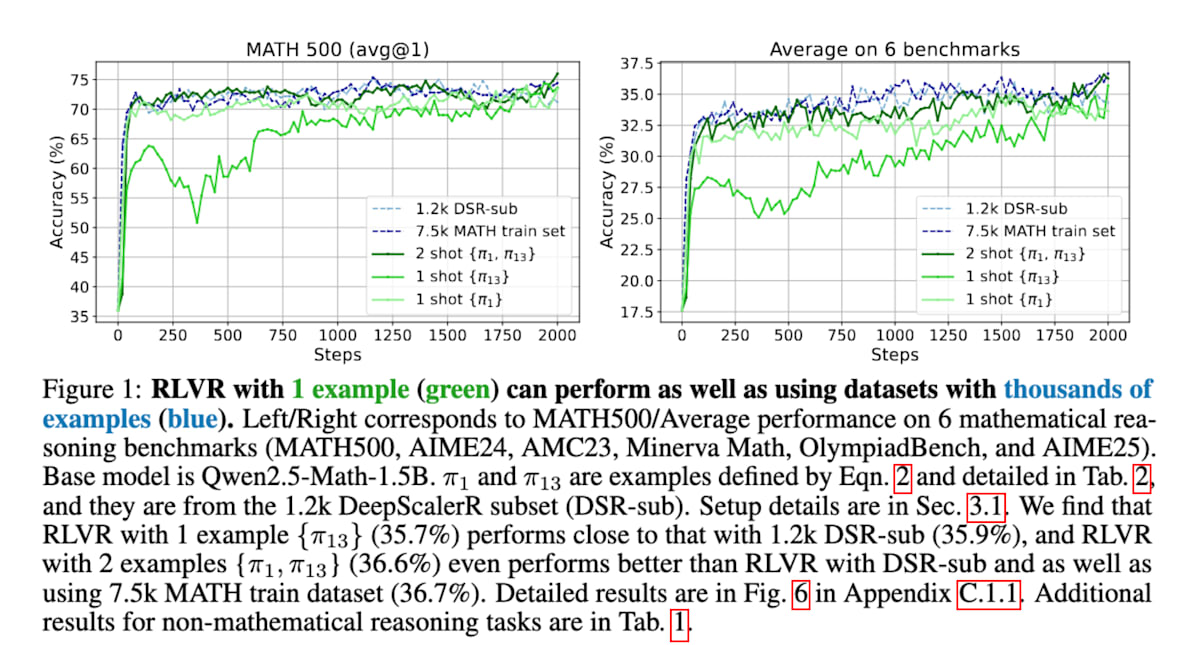
Reinforcement Learning for Reasoning in Large Language Models with One Training Example (https://arxiv.org/abs/2504.20571)
GUIエージェント
GUIエージェントはWebブラウザ操作やアプリケーション操作といったタスクを自律的に行うエージェントです。研究初期はVision-Language Model(VLM)を用いてスクリーンショットとプロンプトを入力として単一ステップのGUI操作を行う方法が提案されました。その後、人間のGUI操作実績をもとに画面(状態)とGUI操作(行動)との軌跡データを用いてGUI操作を模倣学習する方法が試みられました。しかし、模倣学習をするにあたり人間によるGUI操作記録のデータセットが乏しいという課題がありました。このような背景から、アウトカムベースで学習可能なRLを用いる研究が進展しています。
UI-TARS[31]は、人間のようにGUIのスクリーンショット画像情報のみからOS、Web、モバイルアプリなど、あらゆるGUI環境で統一的に動作する高い汎用性を実現しています。エージェントを多数の仮想マシン上で実際に動作させ、新しい操作データ(軌跡)を自動で収集し、収集したデータの中から失敗した操作とそれを修正した正しい操作のペアを特定し、DPO(Direct Preference Optimization)という手法を用いて「失敗から学ぶ」ようにモデルをチューニングします。
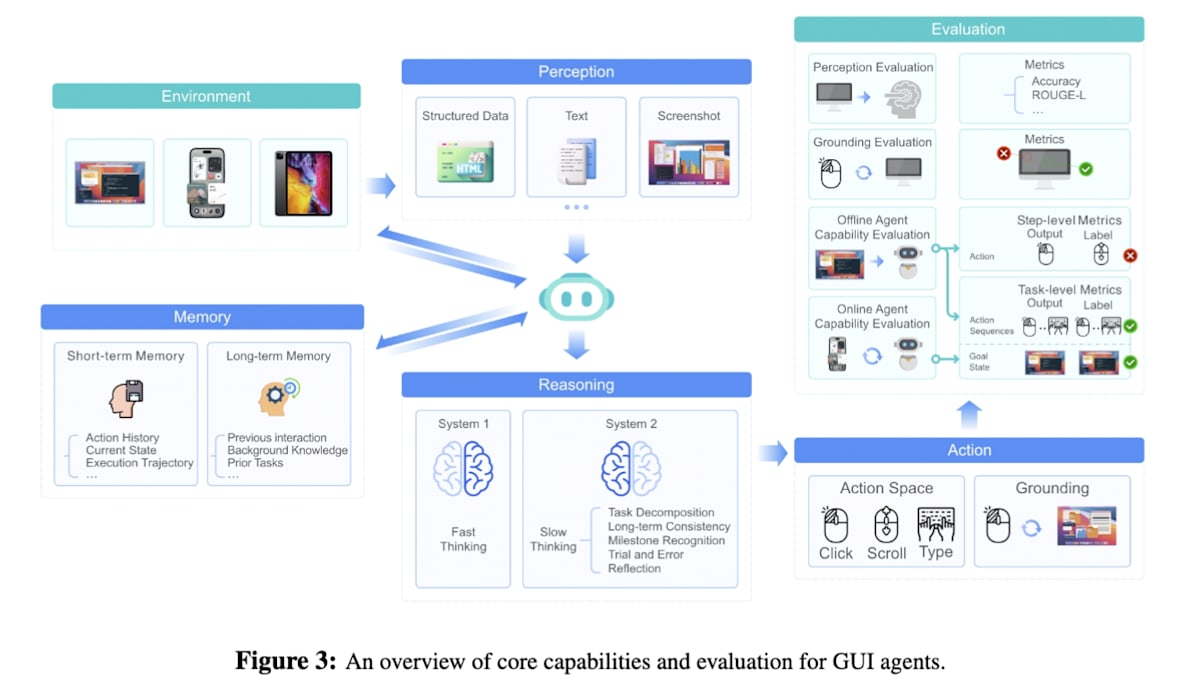
UI-TARS: Pioneering Automated GUI Interaction with Native Agents (https://arxiv.org/abs/2501.12326)
身体性を持つエージェント
身体性エージェント(Embodied Agents)は、ロボットのように物理的な環境でマルチモーダルな情報をもとに物理的な行動を実行するエージェントです。Vision-Language Action(VLA)モデルを用いて模倣学習による事前学習を行い、事前学習済みモデルをインタラクティブなエージェントに組み込み、環境と相互作用させてRLすることで多様な実世界環境におけるモデルの汎化能力を高めるアプローチが一般的に取られています。VLAフレームワークにおけるRLは、複雑な環境での空間的推論と移動を重視するナビゲーションエージェントと、多様で動的な制約下で物理オブジェクトの精密な制御に焦点を当てるマニピュレーションエージェントの2つに大別されます。
-
ナビゲーションエージェント
ナビゲーションエージェントにとって、計画(プランニング)が中心的な能力となります。VLAモデルの将来の行動系列を予測し最適化する能力を強化するためにRLが用いられます。一般的な戦略は、事前学習済みのVLAモデルと同じように1ステップごとの移動行動に対して報酬を与えてエージェントを訓練することです。
VLN-R1[32]は、RGBのビデオ映像を入力として、前進する、回転するといった離散行動を出力するモデルをSFTとRLで学習しています。モデルは一度に6ステップ分の行動軌跡を出力し、時間減衰報酬と呼ばれる、より直前の行動に高い報酬を与えるという独自の報酬設計を利用しています。
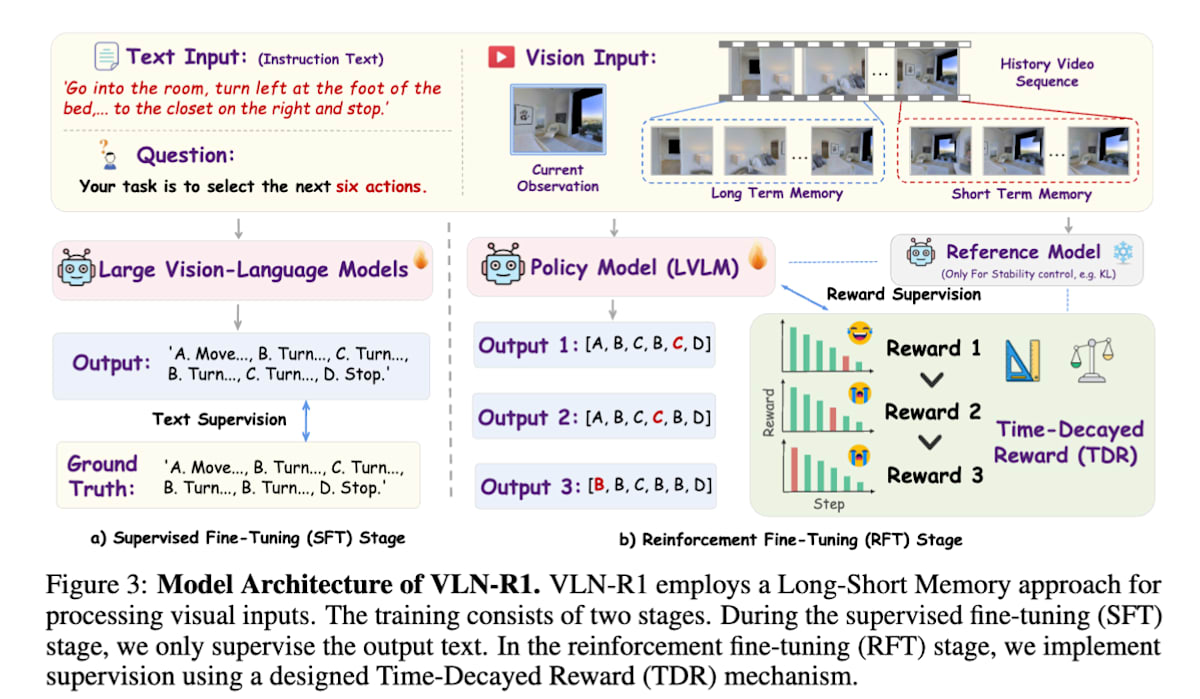
VLN-R1: Vision-Language Navigation via Reinforcement Fine-Tuning (https://arxiv.org/abs/2506.17221) -
マニピュレーションエージェント
マニピュレーションエージェントは主にロボットアームが関わるタスクで利用されます。RLはVLAモデルの指示追従能力と軌跡予測能力を強化するために、特にタスクや環境を越えた汎化性能を向上させる目的で用いられます。
VLA-RL[33]はロボットの一連の動作生成を人間とAIの対話のように捉え直しています。各タイムステップで、ロボットは「現在の視覚情報(画像)」と「人間からの指示(テキスト)」を入力として受け取り、次に行うべき行動を言語トークンとして出力します。これにより強力な言語モデルの構造をRLに直接応用することが可能になっています。
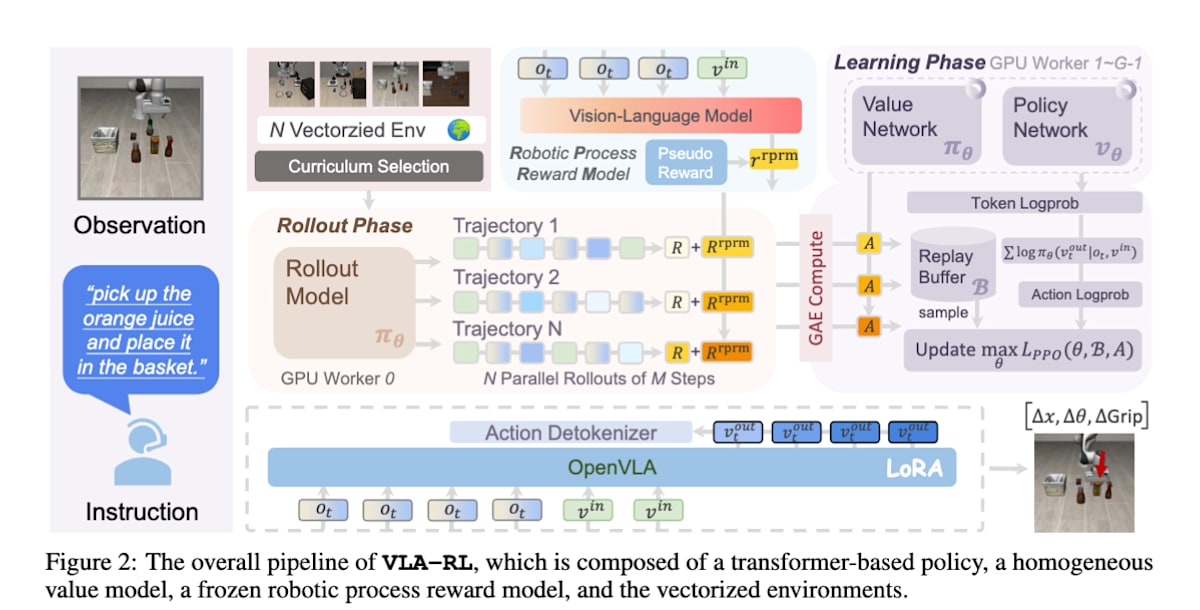
VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning (https://arxiv.org/abs/2505.18719)
おわりに
Agentic RLは2025年に入ってから急速に研究が進展しておりこの記事で紹介した研究も多くは2025年に発表されたものです。AIエージェントの更なる性能向上に今回紹介したAgentic RLが今後どのように関わっていくかを非常に楽しみにしています。なかなかのボリュームとなってしまいましたが、最後までお読みいただきありがとうございました。
-
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey ↩︎
-
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning ↩︎
-
Direct Preference Optimization: Your Language Model is Secretly a Reward Model ↩︎
-
DAPO: An Open-Source LLM Reinforcement Learning System at Scale ↩︎
-
ReAct: Synergizing Reasoning and Acting in Language Models ↩︎
-
Toolformer: Language Models Can Teach Themselves to Use Tools ↩︎
-
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs ↩︎
-
Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning ↩︎
-
Group-in-Group Policy Optimization for LLM Agent Training ↩︎
-
In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents ↩︎
-
Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning ↩︎
-
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent ↩︎
-
Reasoning with Language Model is Planning with World Model ↩︎
-
Absolute Zero: Reinforced Self-play Reasoning with Zero Data ↩︎
-
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models ↩︎
-
OPENTHINKIMG: Learning to Think with Images via Visual Tool Reinforcement Learning ↩︎
-
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning ↩︎
-
Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL ↩︎
-
ZEROSEARCH: Incentivize the Search Capability of LLMs without Searching ↩︎
-
SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution ↩︎
-
Reinforcement Learning for Reasoning in Large Language Models with One Training Example ↩︎
-
UI-TARS: Pioneering Automated GUI Interaction with Native Agents ↩︎
-
VLN-R1: Vision-Language Navigation via Reinforcement Fine-Tuning ↩︎
-
VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning ↩︎
Discussion