RAGのTutorialやってみた part6
前回
前回はRAGの基本的な使用法について学びました。基本的な流れとして、
- ユーザーが質問(question)を入力する
- llmがquestionを要約して、retrieve用のクエリに変換する
- この際、section情報なども付与する
- クエリをretrieveに渡して追加情報をretrieveする
- generateにretrieveされた情報とユーザーの質問を渡して回答を生成する
という処理の流れでした。
今回
今回は、llm自身にretrieveをするかどうかの判断をしてもらうことを目的とします。
llmが自身が持っている情報だけで回答可能ならばretrieveしないで、可能でないならばretrieveするという判断をしてもらいます。そのためにはllmに「このようなツールが使用可能だよ、必要なら使用してね」というようにさせます。さらに、会話の文脈も考慮させるようにします。では、実際にコードを書いてみましょう
初期設定
まず前回通り初期設定をしましょう。この辺は前回解説したのでコードだけ書くに留めておきます。
import getpass
import os
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter API key for OpenAI: ")
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
import getpass
import os
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter API key for OpenAI: ")
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
os.environ["LANGCHAIN_TRACING_V2"] = "true"
if not os.environ.get("LANGCHAIN_API_KEY"):
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
ここまでは、環境変数の設定とインスタンス作成です。
次は、ドキュメントの読み込みをしましょう。
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from typing_extensions import List, TypedDict
# Load and chunk contents of the blog
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)
# Index chunks
_ = vector_store.add_documents(documents=all_splits)
これで初期設定は終わりです。
会話の文脈を考慮させる
from langgraph.graph import MessagesState, StateGraph
graph_builder = StateGraph(MessagesState)
このMessageStateというのが会話の文脈判断のキーになっているようです。
MessageStateの中身を見てみましょう。
クラスは以下のように定義されています。messageというプロパティを持っているので、ノード間でstateを受け渡すときは、{"message": [AnyMessage]}という形で返却する必要がありそう。messageは順にHuman -> AIMessage ...の様に追加されていきます。(1回のqueryに対して。後述しますが、過去の文脈を考慮したいときは、MemorySaverなどを使用する必要がある。)

AnyMessageはこのようになっています。

ここから推察するに、メッセージはいくつかに分類されており以下のようになっていると考えられます。
- AIMessage
- llmのモデルが出力するメッセージクラス
- HumanMessage
- 人間の質問などのメッセージ
- ChatMessage
- チャット内の流れを把握するためのメッセージ
- ユーザーがAIにAというお願いをしたら、チャットメッセージに「ユーザーがAというお願いをしました、agentが処理中です」のように、チャットには直接的に影響はしないが、会話の流れや現在の状況を保持するためのもの。
- SystemMessage
- チャットモデルの役割を予め決めておくメッセージ。
- 「あなたはユーザーのコーディング支援をするためのエージェントです」など
このMessageStateというの使用することで、チャットモデルとの会話履歴をstateに保持することが可能になり、チャットモデルが会話の文脈を考慮することが可能になります。また、MessageStateの内部実装をみると、add_messageというのがあると思いますが、これがメッセージ追加の役割を担っています。
tool-calling
今までretrieveのstepをワークフローに入れて、必ず実行するようにしていたのですが、このretrieveのstepを行うかどうかの判断をチャットモデルに委ねるためにtool-callingというのを使用します。
では実際にチャットモデルに渡す、toolを定義しましょう。
from langchain_core.tools import tool
@tool(response_format="content_and_artifact")
def retrieve(query: str):
"""Retrieve information related to a query."""
retrieved_docs = vector_store.similarity_search(query, k=2)
serialized = "\n\n".join(
(f"Source: {doc.metadata}\n" f"Content: {doc.page_content}")
for doc in retrieved_docs
)
return serialized, retrieved_docs
@toolというのデコレーターでこの関数を修飾します。このtoolというデコレータはretrieve関数をBaseToolを継承したToolというクラスのインスタンスに変更させる役割を持ちます。こうすることで、retrieve関数で書いた処理をToolクラスのインスタンスに渡すことができさらに、retrieveをToolクラスのインスタンスとして使用することが可能になります。(ユーザーは関数を定義して、toolというデコレータをつけるだけ済むということですね)
次にこのtoolデコレータについているresponse_format="content_and_artifact"ですが、retrieveが返却するものを決めている箇所です。contentとartifactを返却しないといけないようですね。コンテントというのは文字列でretrieveされたドキュメントを見やすい形にしたもの(serializeされた)。artifactというのは生のドキュメント群のことで、後続の処理でこのドキュメント群を使用したいときに使用します。response_formatにはcontentとcontent_and_artifactの2種類しか(今のところ)ないです。
ノードを作っていく
今回使用するノードは以下のとおりです
-
response : ユーザーの入力からretrieveのための入力を作るorそのままresponseするノード
- ここではチャットモデルがretireveすると判断したら、retrieveはまだ実行せずに、retrieveするよ〜というメッセージを次のノードに受け渡すだけです。このメッセージがなければ、終了し、チャットモデルからのresponseを返す。
- execute retriever : retrieve stepを実行するノード
- generate : retrieveされたドキュメントとユーザークエリを元にresponseを作成するノード
まず、responseのノードです。
# Step 1: Generate an AIMessage that may include a tool-call to be sent.
def query_or_respond(state: MessagesState):
"""Generate tool call for retrieval or respond."""
llm_with_tools = llm.bind_tools([retrieve])
response = llm_with_tools.invoke(state["messages"])
# MessagesState appends messages to state instead of overwriting
return {"messages": [response]}
llm.bind_toolsメソッドはリストでBaseToolインスタンスを受け取れるようですね。以下のように引数の方が定義されていました。
Sequence[Dict[str, Any] | Type | ((...) -> Any) | BaseTool]
このようにtoolとbindされたllm_with_toolsはinvokeの際に、受け取ったtoolを使用するかどうか判断し、それに応じてresponseの中身を変えます。実際にtoolを使用する場合とそうでない場合のresponseがどう異なっているのか比較してみました。
チャットモデルがtoolを使用すると判断した時のresponseの中身(他にも情報はありますが、みづらくなるので削除しています。)
content='' additional_kwargs={'tool_calls': [{'id': 'call_YDYP58ca69TXZCPCv0OHLn4c', 'function': {'arguments': '{"query":"Task Decomposition"}', 'name': 'retrieve'}, 'type': 'function'}], 'refusal': None}}
toolを使用しないとき
content='Hello! How can I assist you today?' additional_kwargs={'refusal': None} }
と、このような違いがあるようです。toolを使用するときは additional_kwargs に tool_callsというkeyが追加されてそこに、llm_with_toolsが使用すると判断したツール群(リスト形式)の情報が入ります。重要なのは、受け取った引数argumentsと対応するツールのnameでしょう。最終的に、このresponseを{"message": [response]}この形式で返却します。
次のノードは、ツールを使用するとなった時にそれを実行するノードです。
# Step 2: Execute the retrieval.
tools = ToolNode([retrieve])
とこれだけです。使用するツールのリスト形式でToolNodeに渡してtoolsというノードを作成します。このように書かないといけないのでしょう。
最後にgenrateのノードです。
# Step 3: Generate a response using the retrieved content.
def generate(state: MessagesState):
"""Generate answer."""
# Get generated ToolMessages
recent_tool_messages = []
for message in reversed(state["messages"]): # ここまでは[HumanMessageとToolMessage]が入っている。
if message.type == "tool": # messageはHumanMessageかAIMessageかToolMessgeとかのどれかで、typeがtoolなら、ツールのmessageだけを抽出
recent_tool_messages.append(message)
else:
break
tool_messages = recent_tool_messages[::-1] # 順番を登録したツール順に
# Format into prompt
docs_content = "\n\n".join(doc.content for doc in tool_messages)
system_message_content = (
"You are an assistant for question-answering tasks. "
"Use the following pieces of retrieved context to answer "
"the question. If you don't know the answer, say that you "
"don't know. Use three sentences maximum and keep the "
"answer concise."
"\n\n"
f"{docs_content}"
) # generateする際のSystemMessageのpromptを作る、どの様なsystem promptとするかは各自で決められる。
conversation_messages = [
message
for message in state["messages"]
if message.type in ("human", "system")
or (message.type == "ai" and not message.tool_calls) # toolのmessageは除く
] # aiとhumanとsystemのMessageを会話順に取得,なぜsystemを取得しているのかは疑問
# SystemMessageを先頭に、会話の流れを作り、これをgenerateに渡すプロンプトとする。
prompt = [SystemMessage(system_message_content)] + conversation_messages
# Run
response = llm.invoke(prompt)
return {"messages": [response]} # ノードを定義する関数はこのようにして返却する必要がある。MessageStateはmessageをプロパティに持つ
細かい解説はコード上に記述してあります。ここでは、tool nodeから受け取ったstateを使用して、文章を生成しています。
ノードをエッジ(辺)で結びつける
最後に先ほど作成したノードを結びつけて処理の流れを構築する必要があります。
これまで想定していた流れはこの様になっています。
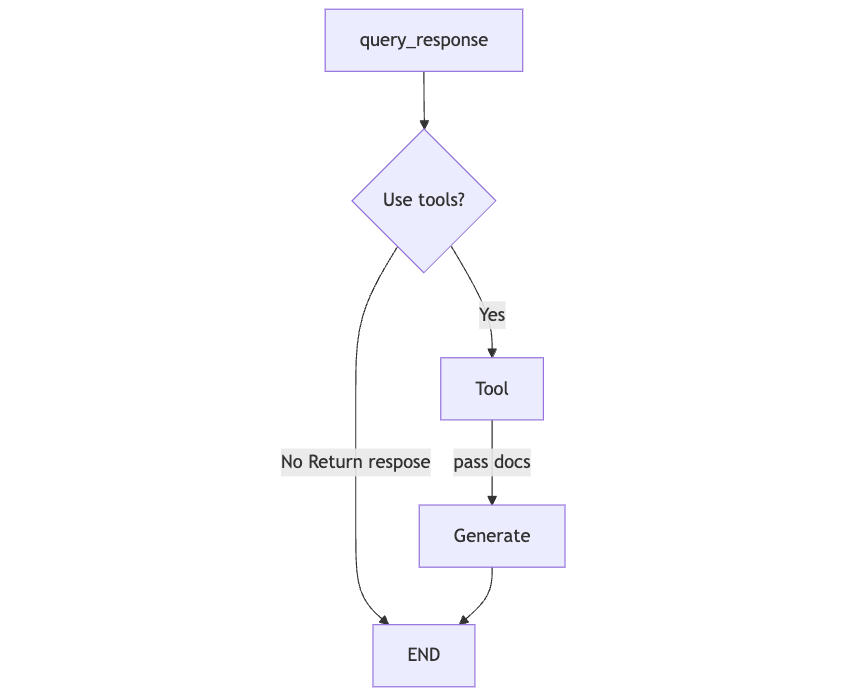
この矢印を構成する必要があります。でh、実際に構築していきましょう。
とはいえ、これだけです。
from langgraph.graph import END
from langgraph.prebuilt import ToolNode, tools_condition
graph_builder.add_node(query_or_respond)
graph_builder.add_node(tools)
graph_builder.add_node(generate)
graph_builder.set_entry_point("query_or_respond")
graph_builder.add_conditional_edges(
"query_or_respond",
tools_condition,
{END: END, "tools": "tools"},
)
graph_builder.add_edge("tools", "generate")
graph_builder.add_edge("generate", END)
graph = graph_builder.compile()
一つ一つ見ていきます。
graph_builder.add_node(query_or_respond)
graph_builder.add_node(tools)
graph_builder.add_node(generate)
graph_builderは前に記述してあったものですgraph_builder = StateGraph(MessagesState)
ここではadd_nodeという先ほど作成したnodeをgraphに登録する処理をしています。なので、まだエッジは作成されていません。
次です
graph_builder.set_entry_point("query_or_respond")
graph_builder.add_conditional_edges(
"query_or_respond",
tools_condition,
{END: END, "tools": "tools"},
)
graph_builder.add_edge("tools", "generate")
graph_builder.add_edge("generate", END)
ここではエントリーノードをset_entry_pointで決めます。文字列はノード名と同じにする必要があります。
次のadd_conditional_edgesはquery_respondとtoolsかENDを繋ぐエッジです。この間にtools_condition関数を挟むことで条件分岐させます。この関数は、state(MessageState)を受け取って、stateの最新のmessageに"tool_call"が含まれているなら"tools"という文字列を返す関数です。(先ほどのretrieveを使用するかしないかの処理で、このtool_callがありましたね)この返却値が"tools": "tools"のkeyに一致したら、valueのtoolsノードへ向かい、そうでなかったら、ENDへという処理です。
tool_conditionの内部実装はシンプルで、以下の様になっています。
def tools_condition(
state: Union[list[AnyMessage], dict[str, Any], BaseModel],
messages_key: str = "messages",
) -> Literal["tools", "__end__"]:
if isinstance(state, list):
ai_message = state[-1]
elif isinstance(state, dict) and (messages := state.get(messages_key, [])):
ai_message = messages[-1]
elif messages := getattr(state, messages_key, []):
ai_message = messages[-1]
else:
raise ValueError(f"No messages found in input state to tool_edge: {state}")
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "tools"
return "__end__"
そのほかのエッジの繋ぎこみはadd_edgeメソッド先ほどの図の様にノード同士を繋ぎます。
ここはシンプルです。
これエッジの作成は終了です。
コンパイル
最後に、過去の会話履歴を保持して文脈判断をチャットモデルにしてもらうようにMemorySaverを導入します。これは会話の合間にチェックポイントをつけておいて保存しているらしいです。会話にthread_idを持たせて会話を識別しています。
from langgraph.checkpoint.memory import MemorySaver
memory = MemorySaver()
graph = graph_builder.compile(checkpointer=memory)
# Specify an ID for the thread
config = {"configurable": {"thread_id": "abc123"}}
会話
実際に会話をしてみましょう
input_message = "What is the process of breaking down a complicated task into smaller tasks?"
for step in graph.stream(
{"messages": [{"role": "user", "content": input_message}]},
stream_mode="values",
config=config,
):
step["messages"][-1].pretty_print()
input_messageを変更して会話をしても、文脈を読み取ってくれます。もし、memoryがないと、会話の文脈は判断せず、各ユーザーからの質問に対してチャットモデルが返答するだけになるので、文脈を考慮させたいときはこのmemoryというのをおさえておく必要がありそうです。
まとめ
今回はチャットモデルにretrieveさせるかどうをtoolを渡して判断させるということを行いました。これは、次回説明するagentにも大きく関わってくるので、toolの使い方のイメージを掴んでおくことは重要です。toolは今回のretrieveだけでなく自作のtoolなども作ることができるので、オリジナルのRAGやAgentを作ってみるのも大変面白いと思います。次回はAgentについて深く踏み込んでいく予定なので ヨロ🤓 オヒ
Discussion