


論文読み勉強会とは
機械学習の分野は日進月歩で、日々沢山の論文が出てきます。最新の技術動向を知るためには日頃から論文を読む習慣をつける必要があります。また、沢山読むためには論文を速読するスキルも必要です。そこで、弊社来栖川電算ではみんなで論文を読んで発表する社内勉強会(論文読み勉強会)を始めました。論文読み勉強会では、はじめて読む論文を50分間のタイムアタックで読み、最後に1人1, 2分程度で分かったことを発表する形式で実施しています。
1月18日(木)の勉強会
この日の参加者は3人でした。各メンバーが読んだ論文とそのまとめを紹介します。
これから論文を読んで知識を付けていきたいと思っている参加者が1時間のタイムアタックで読んでまとめた内容なので誤った内容が含まれている可能性がありますのでご了承ください。
各論文の概要
- EfficientNetV2: Smaller Models and Faster Training
- 従来モデルよりも学習速度とパラメータ効率に優れたCNNモデルであるEfficientnetv2を提案。
- Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
- 二手(bimanual)モバイル操作タスクを模倣学習 (Imitation Learning) する低コストで全身テレオペレーション可能なシステム。安価なハードウェアで複雑なタスクを実行可能。
- BotanicGarden: A high-quality and large-scale robot navigation dataset in challenging natural environments
- ロボティクス用の大規模な植物園のデータセットを作成(データセット論文)。
勉強会の議事録
Kさん(この記事の執筆者)
EfficientNetV2: Smaller Models and Faster Training
https://arxiv.org/abs/2104.00298
- どんなもの?
- 従来モデルよりも学習速度とパラメータ効率に優れたCNNモデルであるEfficientnetv2を提案

- 先行研究と比べてどこがすごい?
- 先行研究の手法やEfficientNet(V1)と比較して、11倍高速に学習して6.8倍小型化した
- 技術や手法の肝は?
- EfficientNet(V1)の良いところ(パラメータ効率やFLOPs効率)維持したまま学習速度を改善することを目指す
- EfficientNet(V1)の問題点
- 画像サイズが大きい場合にバッチサイズ小さくする必要があり、学習速度が大幅に低下する
- 訓練時のみ小さい画像にして、バッチサイズ増やすことでこの問題を改善できるが、学習後に層を細かく調整するのが微妙

- (efficientnetに使われている)depthwise convolutionはFLOPsやパラメータは少ないが、最新のアクセラレータを十分に活用出来ないことが多い
- depthwise convolutionではなく通常の3*3convolutionに置き換えた方が早いことが最近の研究で分かっている
- Efficientnetで一部をそちらに置き換えたら高速化できたが、全てを置き換えると逆に遅くなった→どの組み合わせが効率的か探索する必要がある

- 各ステージを均等にスケールアップすることは最適ではない
- 画像サイズが大きい場合にバッチサイズ小さくする必要があり、学習速度が大幅に低下する
- 学習用NAS
- 精度、パラメータ効率、訓練効率を共同で最適化(訓練も考慮しているのがポイント)
- Efficientnetをバックボーンとする
- 畳み込みの種類(MBConv, FusedMBConv), 層数, カーネルサイズ, expansion ratioがパラメータ
- 探索空間が小さいので、強化学習やランダム探索で探索できる
- 具体的にはA・S^w・P^vを最適化する(w=-0.07, v=-0.05は経験的に決定されたもの
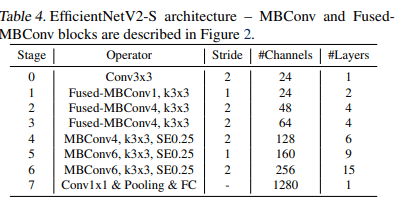
- 精度、パラメータ効率、訓練効率を共同で最適化(訓練も考慮しているのがポイント)
- スケーリング
- 画像サイズに応じた正則化
- EfficientNet(V1)の良いところ(パラメータ効率やFLOPs効率)維持したまま学習速度を改善することを目指す
- どうやって有効だと検証した?

Wさん
- 論文名
- Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
(低コストの全身遠隔操作によるバイマニュアルモバイルマニピュレーションの学習)- bimanual mobile manipulation: 2手(両手)かつ移動できる操作
- https://mobile-aloha.github.io/
- https://arxiv.org/abs/2401.02117
- Thu, 4 Jan 2024
- 著者
- Zipeng Fu, Tony Z. Zhao, Chelsea Finn
- Stanford University
- Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
- どんなもの?
- 二手(bimanual)モバイル操作タスクを模倣学習 (Imitation Learning) する低コストで全身テレオペレーション可能なシステム。安価なハードウェアで複雑なタスクを実行可能。
- ハードウェアとソフトウェアの両側面での取り組み
- ハード:移動可能かつ全身遠隔操作で拡張し、複雑な移動操作タスクの高品質なデモンストレーションを収集することを可能とした
- ソフト:静的なロボットのデータと、模倣学習の共同訓練を可能にした
- $32,000 以下でできた
- OSS にした
- 技術や手法のキモはどこ?
- 移動と両手操作を組み合わせたタスクに対応(従来は固定が多かった)
- 人間の操作によるデータ収集を基にした模倣学習と、静的データ(?)の共同トレーニング
- どうやって有効だと検証した?
- 実世界での複数のタスクを通じてシステムの性能を検証。
- グラスを持ち上げてこぼれたワインを拭く
- エビのソテーを作る
- など 7 タスク
- https://mobile-aloha.github.io/
- 実世界での複数のタスクを通じてシステムの性能を検証。
- 議論はある?
- もっと小さくしたい
- アームの自由度増やしたい
- 単一タスクの Imitation learning しかできない
- 自律的に自己改善できない
- 模倣させるオペレータに専門性がいる(だれでも先生になれない)
- 次に読むべき論文は?
- むしろこっちが学習アルゴリズムの詳細を論じていた...
- https://arxiv.org/abs/2304.13705
- https://tonyzhaozh.github.io/aloha/
- Action Chunking with Transformers (ACT)
- 標準的な行動クローニングのような単一の行動ではなく、一連の行動(「行動チャンク」)を予測することである。ACT方針(図:右)は、条件付きVAE(CVAE)のデコーダ、すなわち生成モデルとして学習される。これは複数の視点、関節位置、およびスタイル変数から画像を合成する。
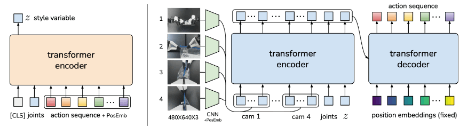
- 図4:トランスフォーマーによるアクション・チャンキング(ACT)のアーキテクチャ。ACTはエンコーダとデコーダを持つ条件付きVAE(CVAE)として学習する。左:CVAEのエンコーダは行動シーケンスと関節観測をスタイル変数zに圧縮する。エンコーダはテスト時には破棄される。右: ACTのデコーダまたはポリシーは、多視点からの画像、関節位置、zを変換エンコーダで合成
Mさん
- 論文
- BotanicGarden: A high-quality and large-scale robot navigation dataset in challenging natural environments
- https://arxiv.org/abs/2306.14137
- 著者:Yuanzhi Liu et al. (Shanghai Jiao Tong University, China)
- どんなもの?
- ロボティクスに関するデータセット論文
- SLAMやlocaliazationのpublicなデータセットは近年増えてきたが、
- GNSSが使えない、単調なテクスチャ、構造化されてないシナリオのようなチャレンジングで大規模なデータセットがない
- 実世界への応用を考えると、このようなチャレンジングな環境でロバストに動作することが必要
- →大規模な植物園のデータセットを作成
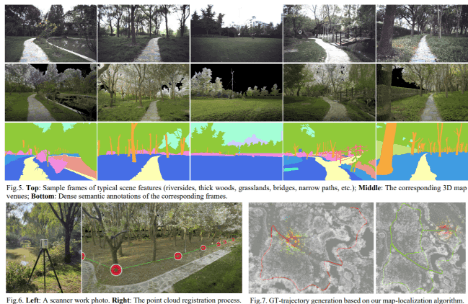
- 鬱蒼としている森林、川沿い、狭い道、橋、草原などを含む
-


- 様々なセンサを正確にキャリブレーションして使った
- ステレオカメラ、IMU, 2つのLiDARなど
- 全地形対応車輪ロボット(?)を使う。オドメトリを提供
- 32の長い&短いシークエンスを撮影
- 合計230万の画像を収集
- 高いクオリティのデータセットを提供、ロボットナビゲーション、センサフュージョンに貢献
- ロボティクスに関するデータセット論文
- 先行研究と比べてどこがすごい?
- これまでのデータセットではあまり見られなかった環境の大規模なデータセットを作成
- ステレオカメラ。3D LiDAR, IMUなどを高精度にキャリブレーション
- ハードウェアレベルでの同期をとって、この分野ではトップレベルの高いクオリティで同期が取れている
- このような環境を対象にした、質の高い様々なground truthを提供するデータセットはほかにない
- 高精度な3Dmap, 軌跡のground truthを提供
- 経験豊かなアノテータによるdenseなsemantic labelを提供
- 他のロボティクス関連のデータセットと比較して、かなり良い情報を提供している

- 使っているセンサ↓≒提供している情報
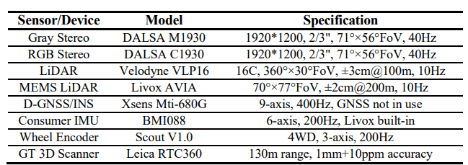
- 技術や手法のキモはどこ?
- チャレンジングな環境を対象に、とにかく高精度に様々なground truthを提供していること(感想)
- 各センサーのキャリブレーションを頑張っていること
- 読み込めてない
- チャレンジングな環境を対象に、とにかく高精度に様々なground truthを提供していること(感想)
- どうやって有効だと検証した?
- いくつかの手法をこのデータセットを使って評価
- このデータセットが様々なナビゲーションのフレームワークをサポートしている
- stereoを使う手法、LiDAR only, LiDAR-Inertial, visual-LiDAR-inertial fusion, visual-inertial...
- 他のデータセットと比較してチャレンジングなことを対象にしていることを確認
- KITTIと比べて5~10倍のエラー値 → より難しい環境を対象にしているということになる
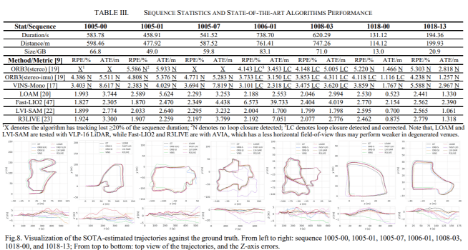
- このデータセットが様々なナビゲーションのフレームワークをサポートしている
- いくつかの手法をこのデータセットを使って評価
- 議論はある?
- GNSSが使えない環境を対象 → GNSSのデータはとらない?
感想
今回の論文読み会は8回目でした。僕がEfficientNetV2の論文を読んでまとめた感想を書きます。
慣れてきて最初よりは読み取れることが増えてきましたが、まだ全然時間が足りませんでした。特に技術や手法のキモのところは時間内では全然読みきれませんでした…。
EfficientNetV2ではネットワーク構造を決めるときにも経験則ではなく強化学習で探索しているというのは面白いと思いました。
これからも執筆者交代しながら論文読み勉強会の内容を紹介していきます。

名古屋のAI企業「来栖川電算」の公式publicationです。AI・ML を用いた認識技術・制御技術の研究開発を主軸に事業を展開しています。 公式HP→ kurusugawa.jp/ , 採用情報→ kurusugawa.jp/jobs/
Discussion