


論文読み勉強会とは
機械学習の分野は日進月歩で、日々沢山の論文が出てきます。最新の技術動向を知るためには日頃から論文を読む習慣をつける必要があります。また、沢山読むためには論文を速読するスキルも必要です。そこで、弊社来栖川電算ではみんなで論文を読んで発表する社内勉強会(論文読み勉強会)を始めました。論文読み勉強会では、はじめて読む論文を50分間のタイムアタックで読み、最後に1人1, 2分程度で分かったことを発表する形式で実施しています。
2月1日(木)の勉強会
この日の参加者は3人でした。各メンバーが読んだ論文とそのまとめを紹介します。
これから論文を読んで知識を付けていきたいと思っている参加者が1時間のタイムアタックで読んでまとめた内容なので誤った内容が含まれている可能性がありますのでご了承ください。
各論文の概要
- Data-Centric Evolution in Autonomous Driving: A Comprehensive Survey of Big Data System, Data Mining, and Closed-Loop Technologies[1]
- 自動運転技術における、データセットの進化、クローズドループ技術の進化を、データセントリック・生成AIを中心に包括的に調査した論文
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift[2]
- 学習効率を改善するためにBatchNormalization(バッチごとの正規化)を提案
- Multiple Hypothesis Tracking Revisited[3]
- 昔のトラッキング手法を再検討したら良さげだった話
勉強会の議事録
Wさん
論文名
- Data-Centric Evolution in Autonomous Driving: A Comprehensive Survey of Big Data System, Data Mining, and Closed-Loop Technologies[1]
どんなもの?
- 自動運転技術におけるデータ中心の進化に関する包括的な調査論文
- 自動運転データセットの分類、クローズドループ技術に関して詳細に論じている
先行研究と比べてどこがすごい?
- 自動運転におけるデータ駆動型技術の体系的なレビューを提供し、データセット、データマイニング、クローズドループ技術など、様々な側面から総合的に分析した
技術や手法のキモはどこ?
- データセットの変遷
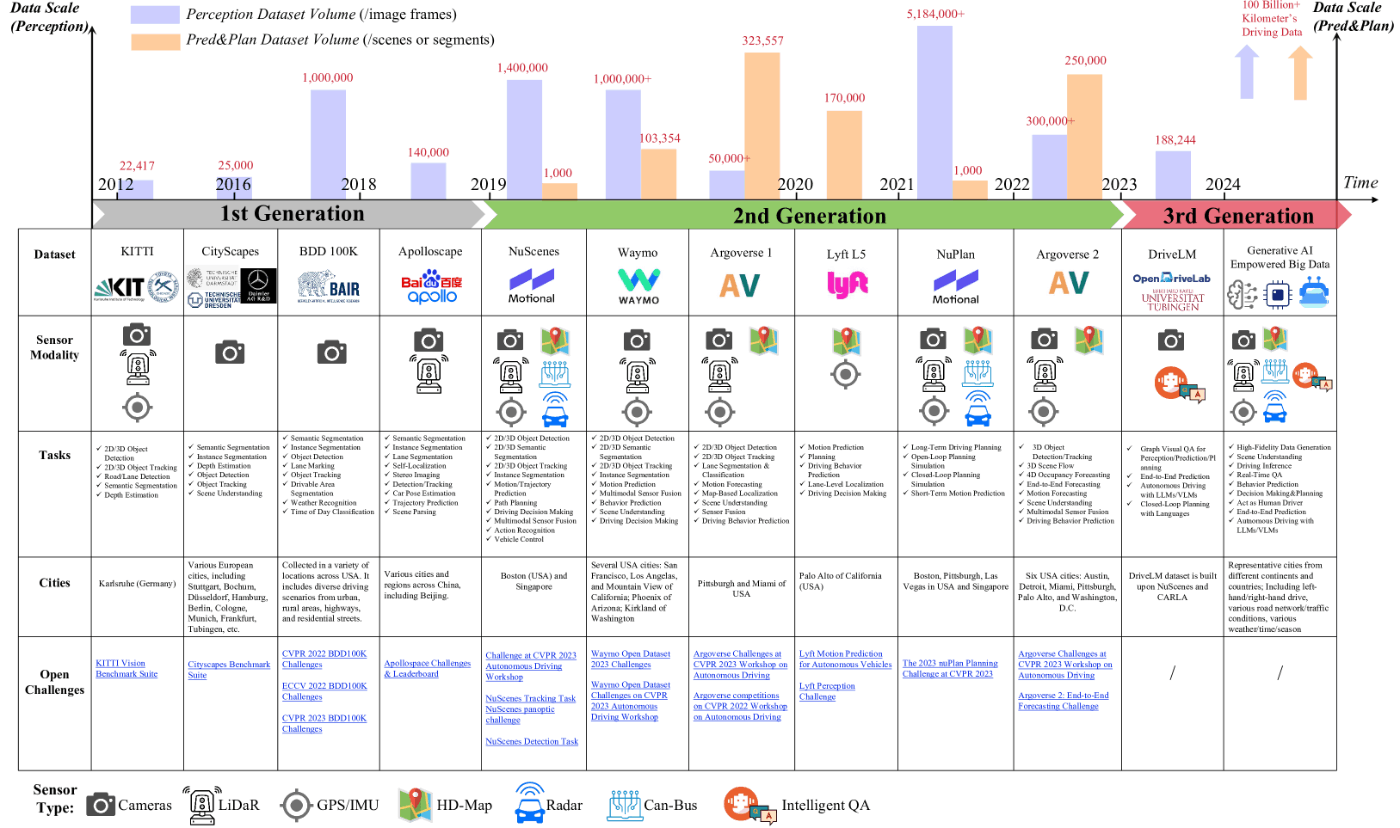 第* 一世代
第* 一世代
- KITTI など。主に認識向け。
- 第二世代
- カメラ、高精度地図、LIDAR、RADAR、GPS、IMUなど統合。運転環境のモデリング、意思決定プロセスに不可欠
- 第三世代
- Generative AI技術によって強化された第3世代のデータセットは、データLong-Tail Distribution問題、Out-of-Distribution(OOD)検出、Corner Case Analysisなど、ますます複雑化する自律走行の課題に取り組む業界のコミットメントを強調している。
- Long-Tail Distribution問題:レアケースの事象に関する
- Out-of-Distribution(OOD)検出:自動運転システムが訓練中に見たことのないデータや状況に遭遇した場合にこれを識別する能力
- Corner Case Analysis:自動運転システムが遭遇するかもしれない極めて特異で予測困難な状況を特定し、分析すること
- アノテーション
- 初期のデータセットは通常手動ラベリング手法を採用していたが、最近のNuPlan、Argoverse 2、DriveLMはADビッグデータの自動ラベリング技術を採用している。伝統的な手動アノテーションから自動ラベリングへの転換は、将来のデータ中心の自律走行における大きなトレンドであると考える。
- Generative AI技術によって強化された第3世代のデータセットは、データLong-Tail Distribution問題、Out-of-Distribution(OOD)検出、Corner Case Analysisなど、ますます複雑化する自律走行の課題に取り組む業界のコミットメントを強調している。
- クローズドループ型データドリブン自動運転訓練
- ソフトウェアとアルゴリズムで定義された自律走行の時代から、ビッグデータ駆動型とインテリジェントモデル協調型の自律走行という新たな感動的な時代へとシフトしつつある
- ADアルゴリズムのトレーニングと実世界での応用/展開のギャップを埋めることを目的
- 人間の運転や路上テストから収集されたデータセットで受動的にトレーニングされるため、実環境と相互作用する
- 従来は静的データセットでやっていたので実環境の合わない問題があった
- 課題
- 大半は一般的な運転シナリオ/通常運転シナリオ
- コーナーケースや異常運転シナリオのデータはほとんど取得できない
- 自動ラベリング方法探求のさらなる努力が必要で
- 第三に、特定のシナリオにおけるADモデルの性能不足の問題を緩和するために、シーンデータマイニングとシーン理解が重視されるべき
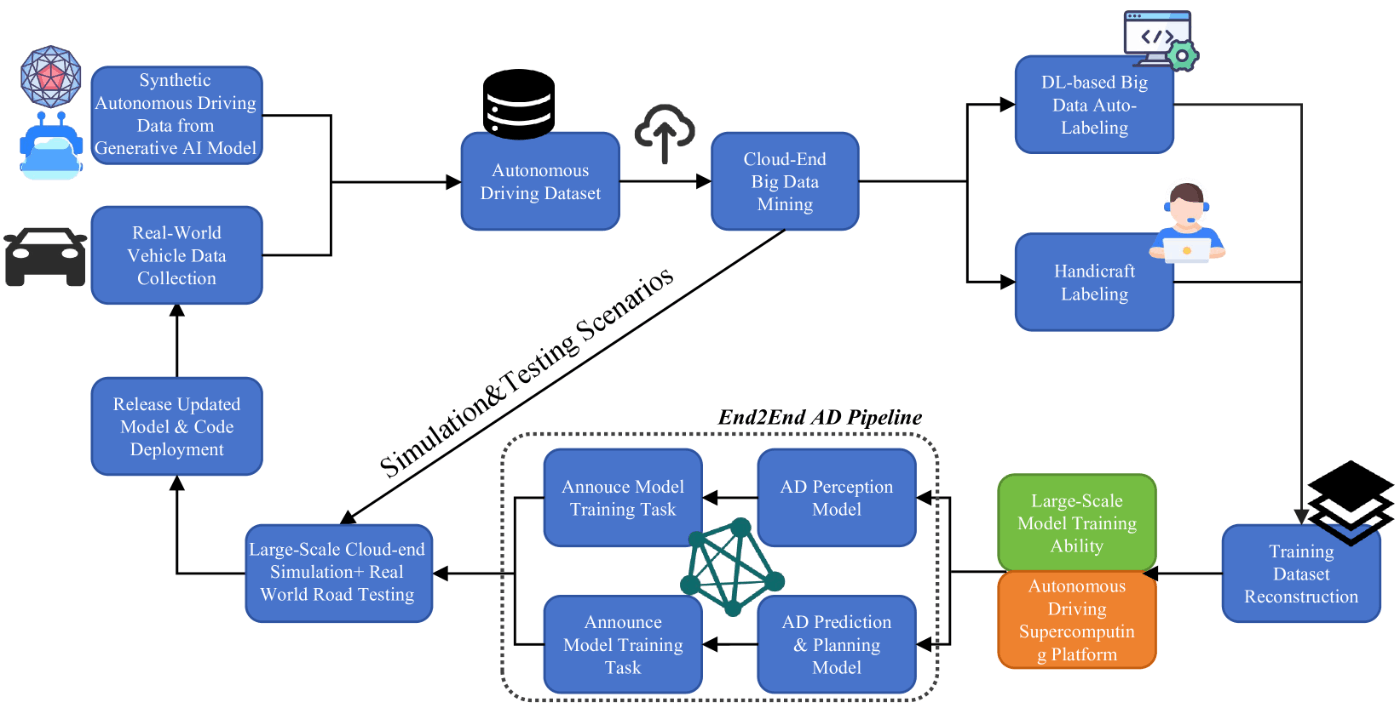
- 自律走行アルゴリズムの研究開発段階とOTAアップグレード段階(実世界展開後)の両方でデータ・クローズ・ループを実現
Kさん
論文名
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift[2]
背景
- Deep Neural Networksの訓練時に前のレイヤーのパラメータが変化すると(内部共変量シフト)
- →学習率を低くする、パラメータ初期化を慎重に行うなどの対策が必要
- 内部共変量シフト・・・学習中のネットワークパラメータ変化によるネットワーク活性化の分布の変化
- 各層の入力xの分布が白色化(平均0、無相関、分散が1)されていると収束が早いことが知られている
- 学習ステップごと、あるいは最適化アルゴリズムのパラメータを活性化値に依存して変更する手法もあったが、
どんなもの?
- モデルアーキテクチャに正規化を組み込んで、上記の問題を解消することを提案
先行研究と比べてどこがすごい?
- 学習が早くなり、精度も良くなる
- Dropoutの代わりにもなる
技術や手法のキモはどこ?
- 各層の入力を白色化すると計算量が多くなり微分可能でない場合もあるので、ミニバッチごとの正規化を採用
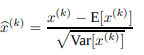
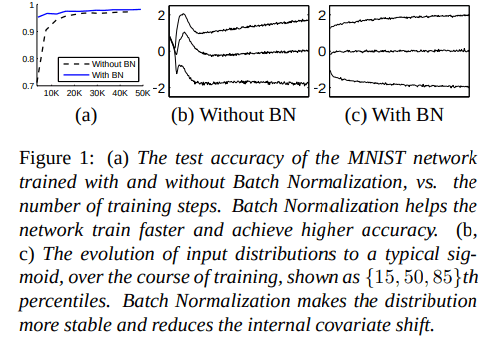
どうやって有効だと検証した?
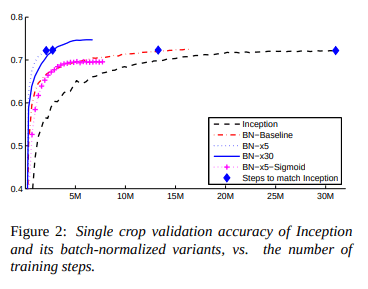
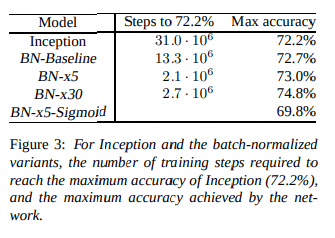
- MNISTにBatch Normalizationを適用した場合の例
- Batch Normalizationを導入するとシグモイドへの入力分布が安定していて、早く収束する
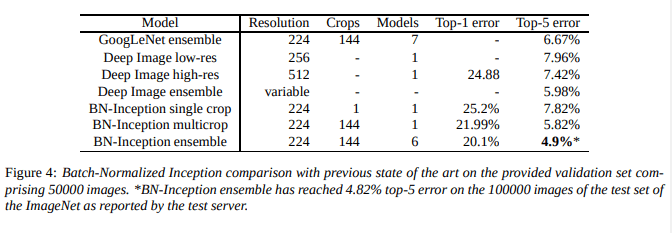
- LSVRC2012データセット
- ImageNetでの精度。Batch normalizationを適用することで良い結果となった
Mさん
論文名
- Multiple Hypothesis Tracking Revisited[3]
どんなもの?
- 古典的なトラッキングの手法Multiple Hypotheses Tracking(MHT)のtracking-by-detectionの枠組みでの再検討
- 90年代の古典的なMHTの実装が、SOTAな手法に基本的なベンチマークで近いパフォーマンスが出ることを示した
- MHTは、1979年にReidらによって提案、rader target trackingにはよく使われている
- 90年代はdetectionの性能の問題で、visual-trackingの良い手法としてあまり取り上げられてなかった
- I. J. Cox and S. L. Hingorani. An efficient implementation of Reid’s multiple hypothesis tracking algorithm and its evaluation for the purpose of visual tracking. PAMI, 1996.
- 2015年近くになって、検出性能の向上で、再びこの手法に焦点を当てるとvisual-trackingのタスクのとても良いことを示した
- 実際に90年代に実装されたものを使って、SOTAに匹敵する性能を出している
- MHTの高次の情報を活用する強みを活かすために、各トラック仮説をオンライン学習してトラッキングに活用
- 最小二乗正則化の枠組みでこのモデルが効果的に学習できることをします
- 各トラック仮説に対して少しの追加処理のみ
- PETSやMOT challengeのようなtracking-by-detectionデータセットでSOTA
- SOTAと言っても、2015年の論文であることに注意
先行研究と比べてどこがすごい?
- 昔は微妙だった手法に再び焦点を当てて、良い手法であることを示し直したこと
- →MHTは、従来visual-trackingに使われているフレームワークと比べて良い
- MHTは高次の情報を活用できるが、従来使われているフレームワークでは簡単に組み込むことができない
- 近年のCNNなどを活用して、より良いトラッキング手法を提案している
- MHTが高次の情報を使えることを活用して、CNNによる外観の長期的なモデリングを組み込む
技術や手法のキモはどこ?
- MHTがすごい
- MHTそのものがすごい感じだが、1時間の枠だとその中身を理解できなかった(´;ω;`)
- MHTが高次の情報を活用できることを活かして、CNNによるオンラインモデリングをトラッキングに活用
どうやって有効だと検証した?
- MOT challenge, PETS2009で実験
議論はある?
- 90年代の実装がSOTAに匹敵した!すごい!
感想
今回の論文読み会は10回目でした。私が担当したMultiple Hypothesis Tracking Revisited[3]の感想です。
職務上、物体追跡技術(トラッキング)を扱うことがあり、カルマンフィルタやパーティクルフィルタなど、広く知られているフィルタリング以外にどんな手法があるかと探しているときに見つけた論文です。古くから提案されているものの、当時はトラッキングの前段階に必要な認識技術の低さによって、あまり注目されていなかった手法でした。しかし、ディープラーニングの進化によって認識技術が格段に高まり、その上で本手法に焦点を再び当てるととても良い手法であると再認識されたものでした。
最近の論文の選び方の傾向として、1,2年以内に書かれた最新の論文ばかり着目しがちですが、昔の手法を見返して再考することで現代では再評価される手法もあると気づかされました。
論文読み会続けていて感じる魅力は、みんなで集まり、約1時間という短い時間で集中的に学び合える点にあります。論文に没頭すると、気づけば数時間が経過してしまうこともありますが、論文読み会のように時間を定めて取り組むことで、効率的に知識を深めることができます。さらに、みんなで行う取り組みは、一人では続かない努力も継続させやすいなと感じます。
これからも執筆者交代しながら論文読み勉強会の内容を紹介していきます。
参考文献
[1]
Data-Centric Evolution in Autonomous Driving: A Comprehensive Survey of Big Data System, Data Mining, and Closed-Loop Technologies, Lincan Li, Wei Shao, Wei Dong, Yijun Tian, Qiming Zhang, Kaixiang Yang, Wenjie Zhang, arXiv:2401.12888, 2024.
[2]
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, Sergey Ioffe, Christian Szegedy, ICML'15: Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume37, pp448-456, 06 July 2015.
[3]
Multiple Hypothesis Tracking Revisited, Chanho Kim et al., IEEE International Conference on Computer Vision (ICCV), 2015.

名古屋のAI企業「来栖川電算」の公式publicationです。AI・ML を用いた認識技術・制御技術の研究開発を主軸に事業を展開しています。 公式HP→ kurusugawa.jp/ , 採用情報→ kurusugawa.jp/jobs/
Discussion