論文読み勉強会とは
機械学習の分野は日進月歩で、日々沢山の論文が出てきます。最新の技術動向を知るためには日頃から論文を読む習慣をつける必要があります。また、沢山読むためには論文を速読するスキルも必要です。そこで、弊社来栖川電算ではみんなで論文を読んで発表する社内勉強会(論文読み勉強会)を始めました。論文読み勉強会では、はじめて読む論文を50分間のタイムアタックで読み、最後に1人1, 2分程度で分かったことを発表する形式で実施しています。
4月25日(木)の勉強会
この日の参加者は3人でした。各メンバーが読んだ論文とそのまとめを紹介します。
これから論文を読んで知識を付けていきたいと思っている参加者が1時間のタイムアタックで読んでまとめた内容なので誤った内容が含まれている可能性がありますのでご了承ください。
各論文の概要
- InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions[1]
- CNNベースの大規模な基盤モデルを提案
- Cross-view Transformers for real-time Map-view Semantic Segmentation[2]
- 複数のカメラからマップビューセマンティックセグメンテーションを行うためのアテンションベースモデル「クロスビュートランスフォーマー」を提案
- Video Diffusion Models[3]
- 画像生成の DDPM を動画生成に応用した
読んだ人:https://zenn.dev/masahiro_k
- 論文名
- InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions[1]
- 著者
- Wenhai Wang、Jifeng Dai、Zhe Chen、Zhenhang Huang、Zhiqi Li、Xizhou Zhu、Xiaowei Hu、Tong Lu、Lewei Lu、Hongsheng Li、Xiaogang Wang、Yu Qiao
- どんなもの?
- InternImagesという大規模なCNNベースの基盤モデルを提示した
- ImageNet, COCO, ADE20Kなどで有効性を検証して、先行研究のCNNやViTに勝った
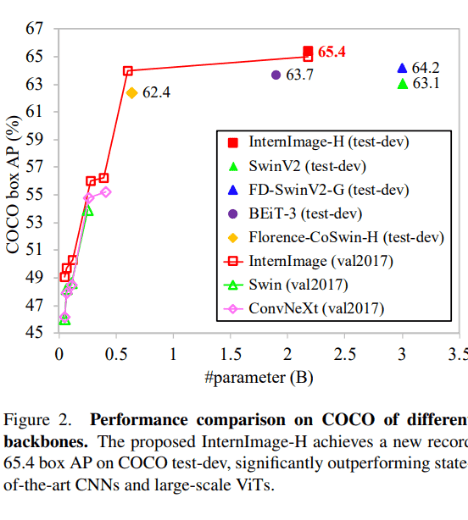
- 先行研究と比べてどこがすごい?
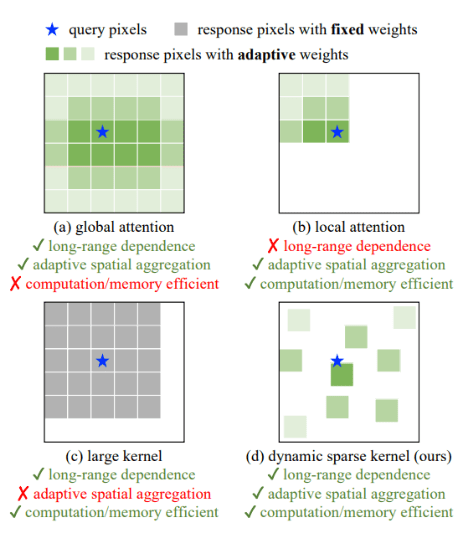
- 大規模な密なカーネルに着目した最近のCNNとは異なり、変形可能な畳み込みをコア演算子とする
- 検出、セグメンテーションなどの下流タスクに必要な大きなreceptive fieldを持つ
- 入力とタスク情報によって条件付けられた適応的な空間集約を持つ
- →従来のCNNの厳密な機能的バイアスを低減し、ViTのような膨大なデータから大規模パラメータで様々なパターンを学習できる
- 技術や手法のキモはどこ?
- 通常のConvolutionはmulti head sefl attentionのギャップ
- 長距離依存性
- 大きなreceptive fieldを持つモデルは、下流タスクでより良い性能を示すことが分かっている
- 3x3畳み込みを積み重ねたCNNの有効受容野は比較的小さく、深層CNNでもViTより長距離依存性を獲得しにくい
- 適応的な空間集約
- MHSA:入力によって重みが動的に条件つけされる
- 通常のCNN:静的な重みと2次元局所性、近傍構造、並進等価性など強い帰納的バイアスを持つ
- →ViTよりも収束が早く、学習データは少ないが、より一般的で頑健なパターンを学習することを制限している
- 上記のギャップを埋めるためにDCNv2を提案
- 長距離依存性
- 通常のConvolutionはmulti head sefl attentionのギャップ
- どうやって有効だと検証した?
- 画像分類、物体検出、インスタンス/セマンティックセグメンテーションなどのタスクでInternImage, 主要なCNN, ViTを分析した
- 画像分類
-
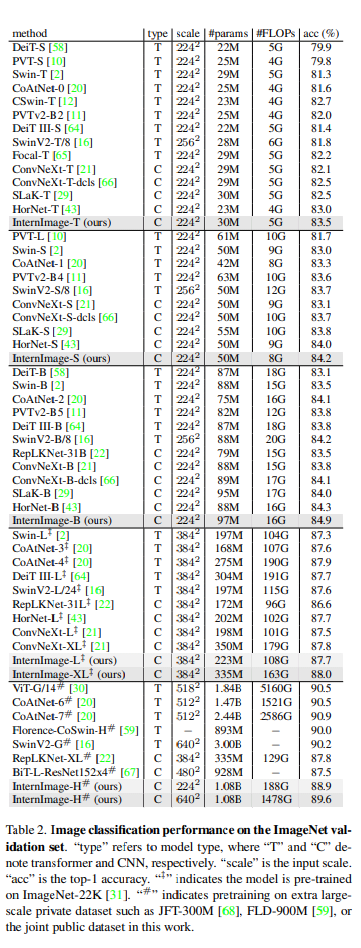
- パラメータ数と計算コストが同程度であれば、InternImageは既存のCNNベースモデルと同等かそれ以上
- InterImage S/Bは同等のサイズのViTベースの手法にも勝った
- XL, HはViTのSOTAには負けるが1%くらいの差しかない
- これは大規模なアクセス不能なぷらいべーとでーたと共同公開データの不一致に起因している可能性がある
-
- 物体検出
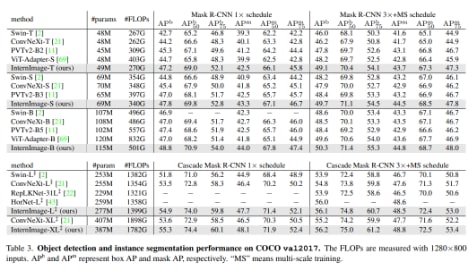
-
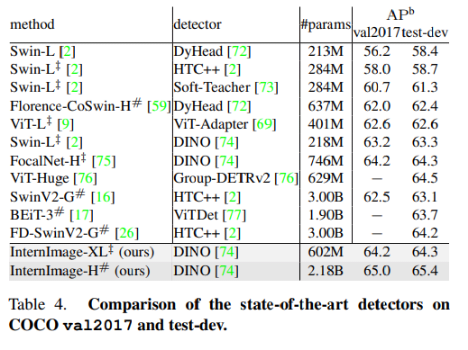
- 提案手法が一番良い結果
- セマンティックセグメンテーション
-
- 提案手法が一番良い結果
-
- アブレーション
-
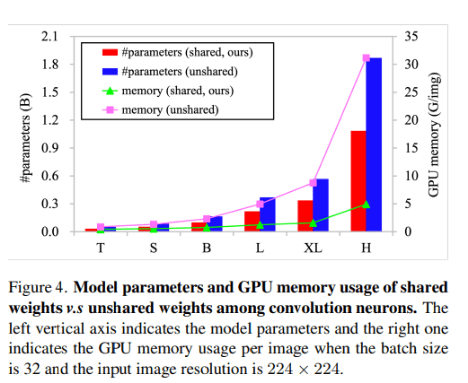
- convolution間の共有重み(提案手法)と非共有重みのメモリサイズ、パラメータ数を比較。提案手法ではパラメータ数減らしてGPU使用量減らせた
-
読んだ人:https://zenn.dev/wakodai
- 論文名
- Cross-view Transformers for real-time Map-view Semantic Segmentation[2]
- 著者
- Brady Zhou, Philipp Krähenbühl
- UT Austin
- CVPR 2022
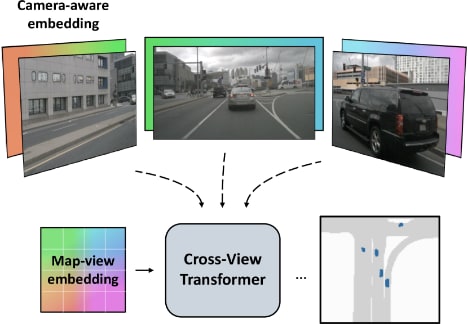
- どんなもの?
- 先行研究と比べてどこがすごい?
- 著者が主張する良いところ
- モデルがシンプル
- 推論速度が非常に速い(35FPS)
- contribution
- クロスビュートランスフォーマーにより、異なるビュー間での効率的な特徴の統合とセマンティックセグメンテーションの向上を実現
- 著者が主張する良いところ
- 技術や手法のキモはどこ?
- クロスビューアテンションメカニズム
- カメラビューとマップビュー間での意味情報の効率的な統合
- 複数のカメラビューからマップビューセマンティックセグメンテーションをする
- 画像エンコーダはマルチスケール特徴表現を生成
- マップビュー座標の位置エンコーディング をクエリとして、カメラビュー特徴をキー、位置エンコーディングをバリュー
- カメラ認識位置エンコーディングをキーとして異なるカメラビュー間での意味情報のマッピングと統合を可能にする
- マップビュー位置エンコーディングにより、地理的な情報をモデルに組み込み、位置情報に基づいたセグメンテーションを実現
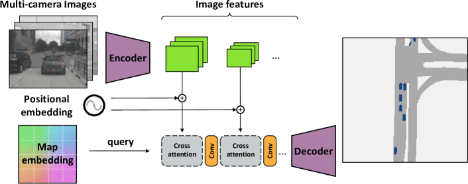
- クロスビューアテンションメカニズム
- どうやって有効だと検証した?
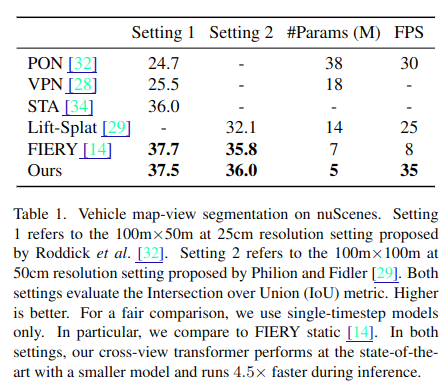
- nuScenes の Vehicle map-view segmentation で評価
- ↓右がセグメンテーション結果、右から2番目が正解

(Cさん)
- 論文名
- Video Diffusion Models
- Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, David J. Fleet[3]
- Google の人たち
- 2022年なので新しくはない
- Video Diffusion Models
- どんなもの?
- Diffusion Model を E2E で適用して動画を生成することに成功した初めての例 (多分)
- 先行研究と比べてどこがすごい?
- 著者が主張する良いところ
- これまで動画生成には VAE や GAN が主流だった。
- Diffusion Model を利用したものもほぼ同時期に出たが、こちらは RNN を組み合わせる方式
- フレームをまとめて Diffusion Model で扱う手法は本論文が初めて
- contribution
- 以降の動画生成系の基礎になっている
- 著者が主張する良いところ
- 技術や手法のキモはどこ?
- モデル
- 画像の Diffusion Model では U-Net を使う。これを動画用に拡張し、3D UNet を構成する
- 入力は (B, T, H, W, C) で T は固定長
- まずは空間方向だけ3x3で畳み込む。その後空間方向の attention を取る。その後時間方向の attention を取る
- 生成方法
- まず最初の16フレームを生成する
- 次に、作った16フレームを条件として次のNフレームを作る
- または、作った16フレームの間を補完するようにしてNフレームを作る
- どちらも1つのモデルで実現できる (数式でいろいろ書いてある)
- ついでに低解像度から高解像度へのアップサンプリングも行える
- 後者のほうが良いらしい
- モデル
- どうやって有効だと検証した?
- 次に読むべき論文は?
- VDM が拡散モデルによる動画生成の基礎になっているのでこれの被参照論文を読むと良さそう
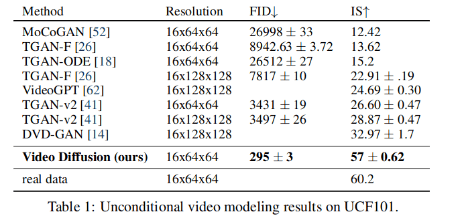
感想
今回僕はInternImageの論文を読みました。ViTが主流になっていますが、工夫次第でCNNでも良い精度が出せることが分かりました。CNNをViTと比較したときにどういう長所・短所がありどうすれば短所を補えるか、まだ十分理解できていない部分もあるので、続きを読んで理解を深めたいと思います。
また、これまでの論文読み勉強会では実験結果のところを読むのに時間をかけすぎて、手法を読む時間がなくなることが多々ありました。今回は実験結果のところを読む時間を少なめにして手法のところを読む時間を増やしてみたので、これまでよりも技術や手法の所を多めに書くことが出来ました。
参考文献
[1] InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
[2] Cross-view Transformers for real-time Map-view Semantic Segmentation
[3] Video Diffusion Models

名古屋のAI企業「来栖川電算」です。LLM・機械学習の仕事をしています。 リモート中心の環境で、尖ったエンジニアがそれぞれの強みを活かして挑戦する会社です。 公式HP→ kurusugawa.jp/ |採用情報→ kurusugawa.jp/jobs/
Discussion