


論文読み勉強会とは
機械学習の分野は日進月歩で、日々沢山の論文が出てきます。最新の技術動向を知るためには日頃から論文を読む習慣をつける必要があります。また、沢山読むためには論文を速読するスキルも必要です。そこで、弊社来栖川電算ではみんなで論文を読んで発表する社内勉強会(論文読み勉強会)を始めました。論文読み勉強会では、はじめて読む論文を50分間のタイムアタックで読み、最後に1人1, 2分程度で分かったことを発表する形式で実施しています。
3月14日(木)の勉強会
この日の参加者は3人でした。各メンバーが読んだ論文とそのまとめを紹介します。
これから論文を読んで知識を付けていきたいと思っている参加者が1時間のタイムアタックで読んでまとめた内容なので誤った内容が含まれている可能性がありますのでご了承ください。
各論文の概要
- YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information[1]
- 2024年2月に出た最新のyolo系物体検出手法
- WorldDreamer: Towards General World Models for Video Generation via Predicting Masked Tokens[2]
- 映像生成のためのワールドモデル
- Is Cosine-Similarity of Embeddings Really About Similarity?[3]
- コサイン類似度が(経験的に)良い場合と悪い場合とあるが、それをちゃんと確認する研究
勉強会の議事録
読んだ人:https://zenn.dev/masahiro_k
- 論文名
- YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information[1]
- 著者:Chien-Yao Wang, I-Hau Yeh, Hong-Yuan Mark Liao
- どんなもの?
- 2024年2月に出たyolo系論文
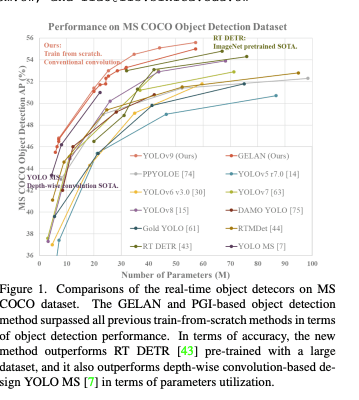
- 2024年2月に出たyolo系論文
- 先行研究と比べてどこがすごい?
- ディープラーニングのネットワークは、特徴抽出や空間変換を行いながら入力データが層を通過する過程で大量の情報が失われる
- これに対処するためにPGI(Programmable Gradient Information)という概念を導入し、新しい軽量ネットワークアーキテクチャである GELAN(Generalized Efficient Layer Aggregation Network)を提案
- 上記を採用する事で、MS COCOでSOTAより良い結果になった
- 技術や手法のキモはどこ?

- 先行研究(ELAN)ではconvが入っていた部分に任意のblockを入れられる
- どうやって有効だと検証した?
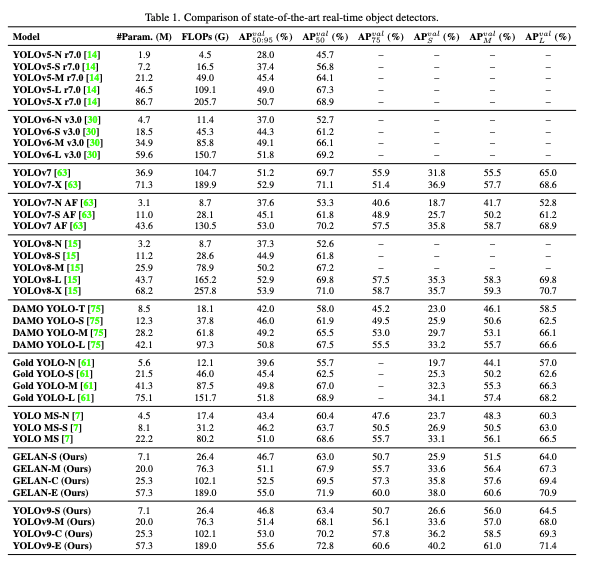
- ConvをCSPに置き換えることでパラメータ数削減と精度改善ができた
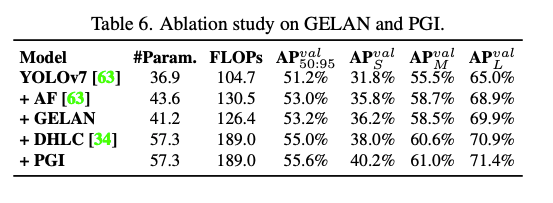
- yolov7にGELAN, PGIを追加する事でモデル性能が改善した

- ConvをCSPに置き換えることでパラメータ数削減と精度改善ができた
読んだ人:https://zenn.dev/wakodai
- 論文名
- WorldDreamer: Towards General World Models for Video Generation via Predicting Masked Tokens[2]
- 著者:Xiaofeng Wang, Zheng Zhu, Guan Huang, Boyuan Wang, Xinze Chen1 Jiwen Lu
- GigaAI
- Tsinghua University
- どんなもの?
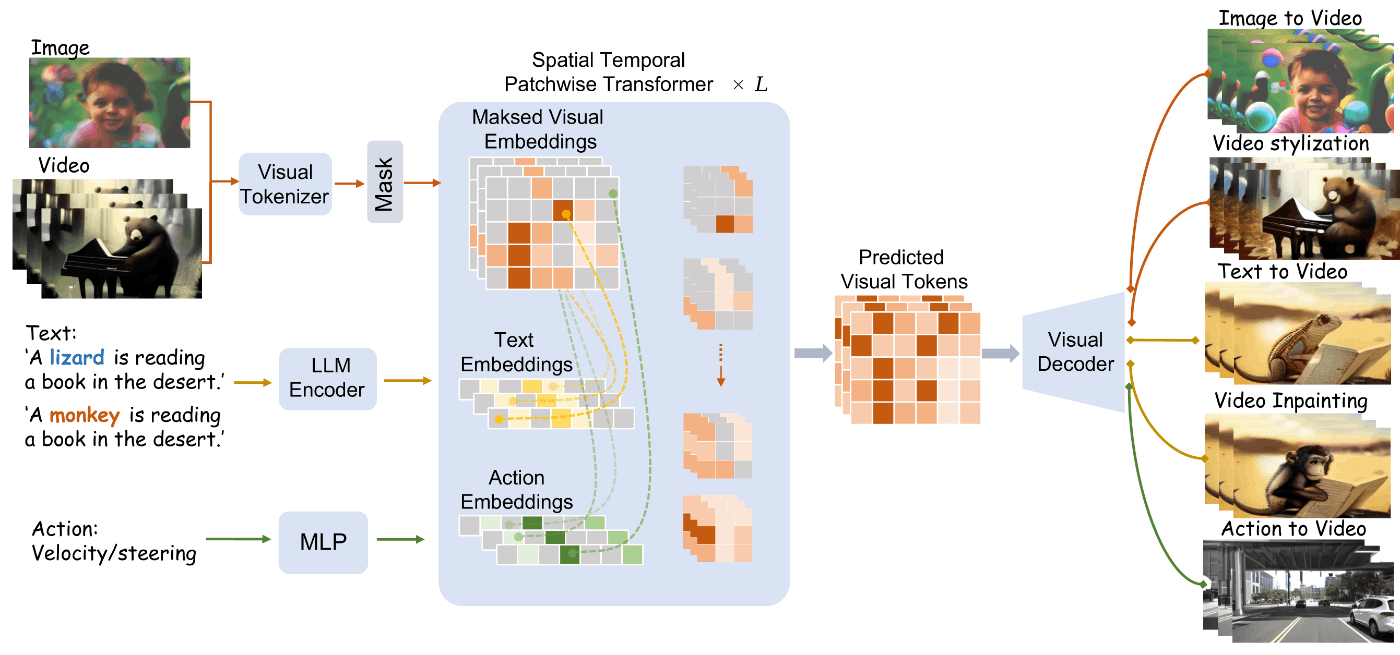
- 一般的な世界の動的環境の複雑さを捉えるため、視覚入力を離散トークンにマッピングし、マスクされたトークンを予測することで、ビデオ生成の能力を大幅に向上させる、先駆的な世界モデル
- 現在、映像生成モデルは主に2つのカテゴリーに分類される。本手法は前者
- Transformer ベース(本手法、GAIA-1)
- 拡散ベース
- 先行研究と比べてどこがすごい?
- 著者が主張する良いところ
- より幅広い一般世界の理解に焦点を当てている
- 以前読んだ GAIA-1[31] は自動運転に特化している
- より幅広い一般世界の理解に焦点を当てている
- contribution
- 映像生成のための最初の一般世界モデルであり、一般世界の動きと物理を学習する
- Spatial Temporal Patchwise Transformer (STPT)を提案し、時間-空間窓内の局所的なパッチへの注意の集中を高める。これにより、視覚信号ダイナミクスの学習が容易になり、学習プロセスが迅速化される。
- 広範な実験を実施し、様々なタスクを実行する汎用性を示した
- 著者が主張する良いところ
- 技術や手法のキモはどこ?
- 視覚信号に埋め込まれた動きと物理の複雑なダイナミクスを効果的にモデル化するために、マスクされた視覚トークンを予測する
- 具体的には VQGAN [15]を使って画像を個別のトークンにエンコードする。次に、これらのトークンの一部をランダムにマスクし、マスクされていないトークンを利用してマスクされたトークンを予測する
- WorldDreamerはTransformerアーキテクチャ上に構築されている
- ビデオ信号に内在する空間的・時間的優先度に関して、STPT(Spatial Temporal Patchwise Transformer)を提案し、時間的・空間的ウィンドウ内の局所的なパッチに注意を集中させることを可能にし、視覚信号ダイナミクスの学習を促進し、学習プロセスの収束を加速する
- 注意機構を空間的・時間的パッチ内に限定
- ~詳しく読みきれず~
- クロスアテンションを通じて言語信号と行動信号を統合し、世界モデル内での相互作用のためのマルチモーダルなプロンプトを構築する

- 視覚信号に埋め込まれた動きと物理の複雑なダイナミクスを効果的にモデル化するために、マスクされた視覚トークンを予測する
- どうやって有効だと検証した?

- 次に読むべき論文は?
- 画像生成による運転シーン(画像、動画)の生成を読んだので、物標位置や挙動の生成についての研究が気になる
読んだ人:https://zenn.dev/asobod11138
- 論文名
- Is Cosine-Similarity of Embeddings Really About Similarity?
- Harald Steck, Chaitanya Ekanadham, Nathan Kallus[3]
- Netflix Inc,
- journal: ACM Web Conference 2024 (WWW 2024 Companion)
- どんなもの?
- コサイン類似度
- 2つのベクトルがどのくらい似ているかを表す尺度。2つのベクトルの角度のcosine
- 機械学習でよく使われる一般的な尺度
- 経験的に、コサイン類似度が良い場合と悪い場合があるが、それに関してちゃんと確認する研究
- コサイン類似度を使って成功したと報告する論文は無数にあるが、その一方で、学習された埋め込みベクトルの内積など、他のアプローチほど機能しない事もいくつか報告されている
- 正規化線形モデルから分析的に考察して、コサイン類似度がどのようにして意味のない「類似性」を生み出すのかを研究
- 線形モデルを超えた場合の議論(線形モデルを超えた→非線形モデル?:ディープなモデル)
- deepなモデルを学習する際には様々な正則化の組み合わせが使用される
- これらは、得られた結果にコサイン類似度を使う際に、暗黙的かつ意図しない影響を及ぼす
- そのため、結果が不透明になり、きまぐれなものになってしまう。
- コサイン類似度やその代替案を盲目的に使用しないように警告
-
コサイン類似度がきまぐれな挙動をする根本的理由
- コサイン類似度そのものではなく、内積が明確で一意であるにもかかわらず、学習された埋め込みベクトルは任意のコサイン類似度を出力できる自由度がある
- →コサイン類似度で類似度を測るということが、手法と正規化のテクニックに強く依存しているので、いくつかの状況では意味のない結果となってしまう
- コサイン類似度
- 先行研究と比べてどこがすごい?
- 一般的に広く使われているコサイン類似度について考え直したという観点がもう凄い
- コサイン類似度という尺度そのものは問題ないし、一意にベクトルの類似度が測れるように見える(https://zenn.dev/asobod11138 の感想)
- 一方で、学習結果のベクトルに自由度があってコサイン類似度と合わない
- コサイン類似度という尺度が悪いかもしれないという考えは思いもよらなかった
- 技術や手法のキモはどこ?
- 広く一般的に使われれているコサイン類似度の不安定さに着目して考え直した点
- 分析的に研究するために、正規化線形モデルに落とし込んで分析しやすい状態からはじめた点
- どうやって有効だと検証した?
- 正規化線形モデルで解析的に分析
- シミュレーションデータで学習して、コサイン類似度がどの程度上手くタスクをこなせるか分析

- 訓練時にre-scalingを適切に選択しても、得られるコサイン類似度が大きく異なることを示す
- 議論はある?
- 線形モデルでの学習という状況での分析に限られているが、deepなモデルでも同様な結果でコサイン類似度に悩まされると予想
- 線形モデルでの問題ほど大きな問題でなくても、たくさんの正規化の集まりなので、その結果より不透明なコサイン類似度の影響が出てくる
感想
僕が読んだYOLOv9の論文の感想です。仕事で物体検出を扱うことが多いので、最新のYOLOがどんな工夫をしているのか勉強しようと思って読みました。
入力画像を初期重みで作ったモデルに画像を入力したときの特徴マップを可視化すると、PlainNetやResnetでは下図([1]から引用)の(b),(c)のように元画像の情報がほとんど失われますが、CSPNetやこの論文で提案するGELANでは(d),(e)のように元画像の情報がかなり残るそうです。

精度だけでなく、特徴マップを可視化した時点でここまではっきり差が出るのは面白いと思いました。
これからも執筆者交代しながら論文読み勉強会の内容を紹介していきます。
参考文献
[1] YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
[2] WorldDreamer: Towards General World Models for Video Generation via Predicting Masked Tokens
[3] Is Cosine-Similarity of Embeddings Really About Similarity?

名古屋のAI企業「来栖川電算」の公式publicationです。AI・ML を用いた認識技術・制御技術の研究開発を主軸に事業を展開しています。 公式HP→ kurusugawa.jp/ , 採用情報→ kurusugawa.jp/jobs/
Discussion